大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1. ebpf概述
1.1 ebpf发展历史
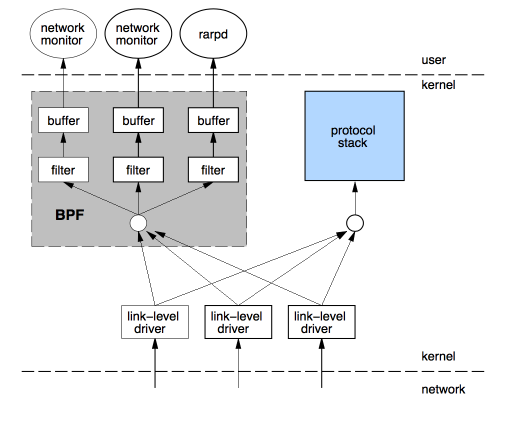

BPF,及伯克利包过滤器Berkeley Packet Filter,最初构想提出于 1992 年,其目的是为了提供一种过滤包的方法,并且要避免从内核空间到用户空间的无用的数据包复制行为。它最初是由从用户空间注入到内核的一个简单的字节码构成,它在那个位置利用一个校验器进行检查 —— 以避免内核崩溃或者安全问题 —— 并附着到一个套接字上,接着在每个接收到的包上运行。几年后它被移植到 Linux 上,并且应用于一小部分应用程序上(例如,tcpdump)。其简化的语言以及存在于内核中的即时编译器(JIT),使 BPF 成为一个性能卓越的工具。
在 2013 年,Alexei Starovoitov 对 BPF 进行彻底地改造,并增加了新的功能,改善了它的性能。这个新版本被命名为 eBPF (意思是 “extended BPF”),与此同时,将以前的 BPF 变成 cBPF(意思是 “classic” BPF)。新版本出现了如映射和尾调用tail call这样的新特性,并且 JIT 编译器也被重写了。新的语言比 cBPF 更接近于原生机器语言。并且,在内核中创建了新的附着点。
1.2 ebpf诞生的目的
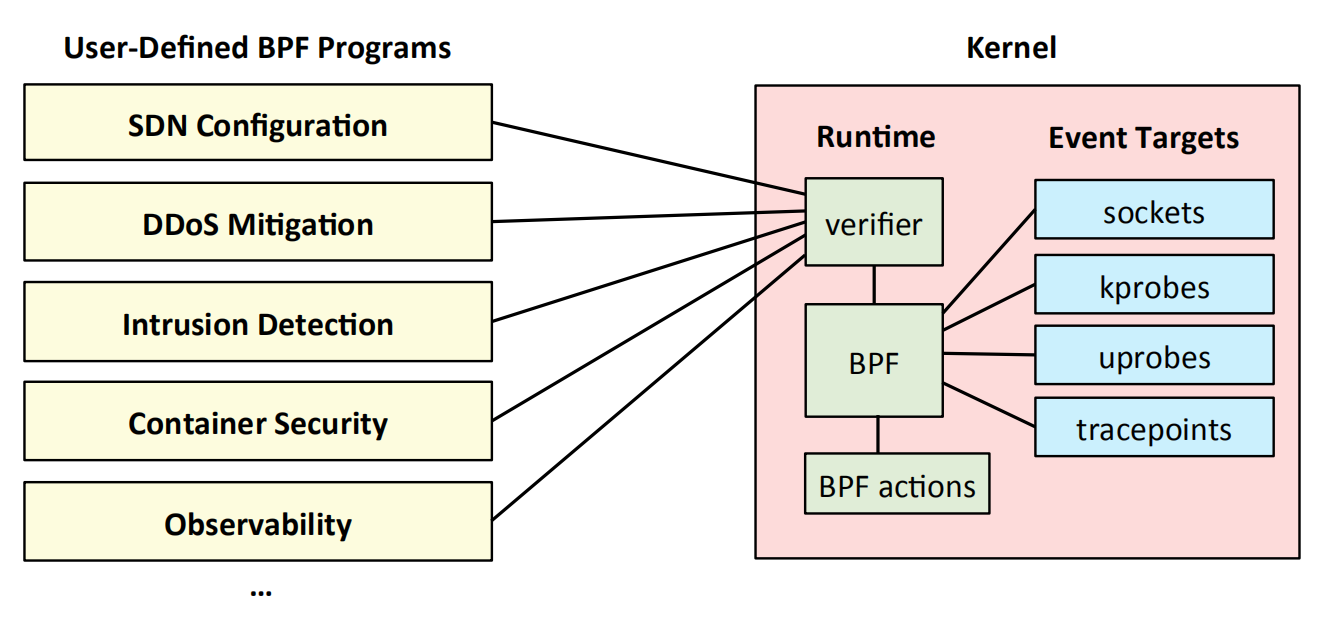
用Linux Kernel Module来做一个类比说明eBPF诞生的目的。
Kernel Module的主要目的就是让用户可以通过这种机制,实现对内核的“赋能”,动态添加一些内核本身不支持的功能,比如硬件的驱动能力,新的文件系统或是系统调用。当然也可以融合到现有的内核处理流程中,比如在netfilter的某个hook点中添加包处理方法等。
Kernel Module的优点:
- 动态添加/删除,无需重新编译内核
- 减小内核体积
缺点:
- 一旦出现BUG可能导致内核直接崩溃
- 增加内核攻击面,影响内核安全
eBPF要做的事情也非常类似,但它想要克服Kernel Module的缺点,即确保执行的代码绝对安全。
为了达到这一目的,eBPF在内核中实现了一个虚拟机执行用户的指令。与Kernel Module直接在真实的物理硬件上执行用户的指令不同,eBPF提供给用户一个虚拟的RISC处理器,以及一组相关的指令。用户可以直接用这组指令编写程序。同时,程序在下发到该虚拟机之前也会经过eBPF的检查,比如会不会进入无限循环,会不会访问不合法的内存地址等等。只有在通过检查之后才可以进入执行的环节。
对eBPF来说,和Kernle Module一样,也是通过特定的Hook点监听内核中的特定事件,进而执行用户定义的处理。这些Hook点包括:
- 静态tracepoint
- 动态内核态探针(Dynamic Kernel probes)
- 动态用户态探针(Dynamic User Probes)
- 其他hook点
针对主要是监控、跟踪使用的eBPF应用来说,主要通过这种方式取得内核运行时的一些参数和统计信息。例如,系统调用的参数值、返回值,通过eBPF map将得到的信息送给用户态程序,进而在用户态完成后处理流程。
另外一类应用则直接在一些内核处理流程中加入自己的处理逻辑,例如XDP,就是在网卡驱动和内核协议栈之间插入了eBPF扩展的网包过滤、转发功能。
2. ebpf深入理解
参考:全面介绍eBPF
eBPF 是一个在内核中运行的虚拟机,它可以去运行用户。在用户态实现的这种 eBPF 的代码,在内核以本地代码的形式和速度去执行,它可以跟内核的 Trace 系统相结合,给我们提供了几乎无限的可观测性。
eBPF 的基本原理——它所有的接口都是通过 BPF 系统调用来跟内核进行交互,eBPF 程序通过 LVM 和 Cline 进行编译,产生 eBPF 的字节码,通过 BPF 系统调用,加载到内核,验证代码的安全性,从而通过 JIT 实时的转化成 Native 的 X86 的指令。
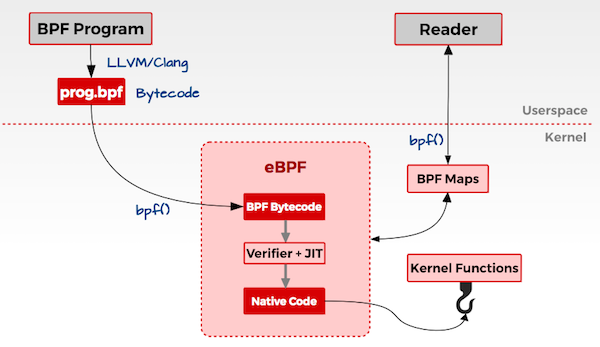
2.1 eBPF内核验证程序
允许用户空间代码在内核中运行存在固有的安全性和稳定性风险。因此,在加载每个eBPF程序之前,会对它们进行大量检查。
第一个测试确保eBPF程序终止,并且不包含任何可能导致内核锁定的循环。这是通过对程序的控制流程图(CFG)进行深度优先搜索来检查的。严格禁止无法到达的指令;包含无法访问的指令的任何程序都将无法加载。
第二阶段涉及更多内容,并且要求验证程序一次模拟一次eBPF程序的执行。在执行每条指令之前和之后都要检查虚拟机状态,以确保寄存器和堆栈状态有效。禁止跳越边界,访问超范围数据也是如此。
最后,验证者使用eBPF程序类型来限制可以从eBPF程序调用哪些内核功能以及可以访问哪些数据结构。例如,某些程序类型被允许直接访问网络数据包数据。
2.2 bpf()系统调用
我们可以通过bpf()系统调用加载程序:
/* cmd:BPF_PROG_LOAD bpf_attr:允许数据可以在内核和用户空间传输 size:bpf_attr的长度 */
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
2.3 eBPF程序类型
BPF_PROG_LOAD的BPF程序类型决定了四件事:
- 可以在何处附加程序
- 可以调用验证程序的内核内辅助函数
- 是否可以直接访问网络数据包
- 以及作为第一个传递的对象的类型该程序的参数。
实际上,程序类型本质上定义了一个API,内核支持的当前eBPF程序类型集为:
BPF_PROG_TYPE_SOCKET_FILTER:网络数据包过滤器
BPF_PROG_TYPE_KPROBE:确定是否应触发kprobe
BPF_PROG_TYPE_SCHED_CLS:网络流量控制分类器
BPF_PROG_TYPE_SCHED_ACT:网络流量控制操作
BPF_PROG_TYPE_TRACEPOINT:确定是否应触发跟踪点
BPF_PROG_TYPE_XDP:从设备驱动程序接收路径运行的网络数据包筛选器
BPF_PROG_TYPE_PERF_EVENT:确定是否应该触发性能事件处理程序
BPF_PROG_TYPE_CGROUP_SKB:用于控制组的网络数据包过滤器
BPF_PROG_TYPE_CGROUP_SOCK:用于控制组的网络数据包筛选器,允许修改套接字选项
BPF_PROG_TYPE_LWT_ *:用于轻型隧道的网络数据包过滤器
BPF_PROG_TYPE_SOCK_OPS:用于设置套接字参数的程序
BPF_PROG_TYPE_SK_SKB:网络数据包过滤器,用于在套接字之间转发数据包
BPF_PROG_CGROUP_DEVICE:确定是否应该允许设备操作
2.4 eBPF数据结构
eBPF程序的主要数据结构是eBPF map,一种key-value数据结构。Maps通过bpf()系统调用创建和操作。
有不同类型的Map:
BPF_MAP_TYPE_HASH:哈希表
BPF_MAP_TYPE_ARRAY:数组映射,已针对快速查找速度进行了优化,通常用于计数器
BPF_MAP_TYPE_PROG_ARRAY:对应eBPF程序的文件描述符数组;用于实现跳转表和子程序以处理特定的数据包协议
BPF_MAP_TYPE_PERCPU_ARRAY:每个CPU的阵列,用于实现延迟的直方图
BPF_MAP_TYPE_PERF_EVENT_ARRAY:存储指向struct perf_event的指针,用于读取和存储perf事件计数器
BPF_MAP_TYPE_CGROUP_ARRAY:存储指向控制组的指针
BPF_MAP_TYPE_PERCPU_HASH:每个CPU的哈希表
BPF_MAP_TYPE_LRU_HASH:仅保留最近使用项目的哈希表
BPF_MAP_TYPE_LRU_PERCPU_HASH:每个CPU的哈希表,仅保留最近使用的项目
BPF_MAP_TYPE_LPM_TRIE:最长前缀匹配树,适用于将IP地址匹配到某个范围
BPF_MAP_TYPE_STACK_TRACE:存储堆栈跟踪
BPF_MAP_TYPE_ARRAY_OF_MAPS:地图中地图数据结构
BPF_MAP_TYPE_HASH_OF_MAPS:地图中地图数据结构
BPF_MAP_TYPE_DEVICE_MAP:用于存储和查找网络设备引用
BPF_MAP_TYPE_SOCKET_MAP:存储和查找套接字,并允许使用BPF辅助函数进行套接字重定向
可以使用bpf_map_lookup_elem()和 bpf_map_update_elem()函数从eBPF或用户空间程序访问所有Map.
2.5 如何用C编写eBPF程序
利用高级语言书写 BPF 逻辑并经由编译器生成出伪代码来并不是什么新鲜的尝试,比如 libpcap 就是在代码中内嵌了一个小型编译器来分析 tcpdump 传入的 filter expression 从而生成 BPF 伪码的。只不过长久以来该功能一直没有能被独立出来或者做大做强,究其原因,主要还是由于传统的 BPF 所辖领域狭窄,过滤机制也不甚复杂,就算是做的出来,估计也不堪大用。
然而到了 eBPF 的时代,情况终于发生了变化:现行的伪指令集较之过去已经复杂太多,再用纯汇编的开发方式已经不合时宜,于是,自然而然的,利用 C 一类的高级语言书写 BPF 伪代码的呼声便逐渐高涨了起来。
目前,支持生成 BPF 伪代码的编译器只有 llvm 一家,即使是通篇使用 gcc 编译的 Linux 内核,samples 目录下的 bpf 范例也要借用 llvm 来编译完成。
2.6 BCC(BPF Compiler Collection)
虽然现在可以用 C 来实现 BPF,但编译出来的却仍然是 ELF 文件,开发者需要手动析出真正可以注入内核的代码。这部分工作多少有些麻烦,如果可以有一个通用的方案一步到位的生成出 BPF 代码就好了。
于是就有人设计了 BPF Compiler Collection(BCC),BCC 是一个 python 库,但是其中有很大一部分的实现是基于 C 和 C++的,python 只不过实现了对 BCC 应用层接口的封装而已。
使用 BCC 进行 BPF 的开发仍然需要开发者自行利用 C 来设计 BPF 程序——但也仅此而已,余下的工作,包括编译、解析 ELF、加载 BPF 代码块以及创建 map 等等基本可以由 BCC 一力承担,无需多劳开发者费心。
3. ebpf应用
利用ebpf已经涌现了一大批应用。

下面是一些bpf program type

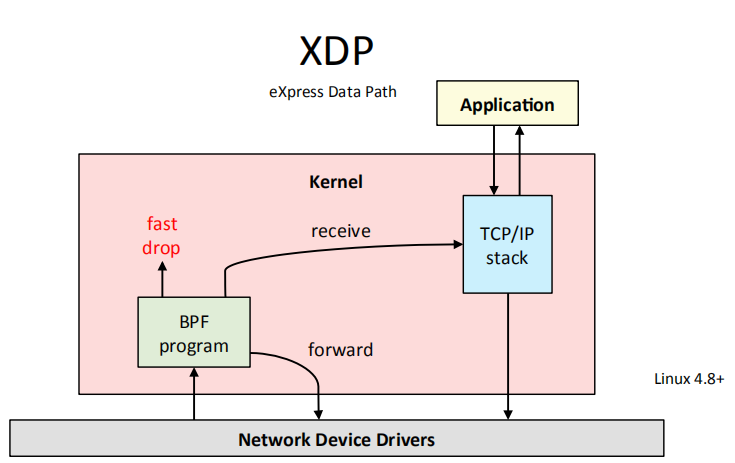
3.1 XDP
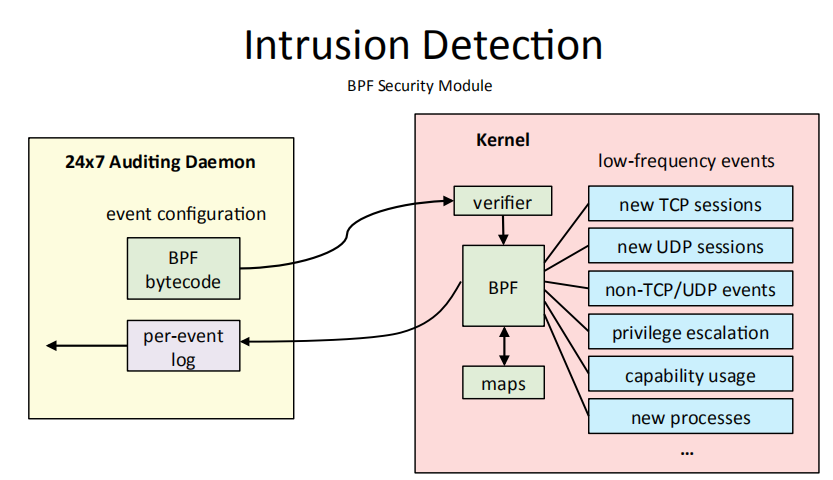
3.2 IDS
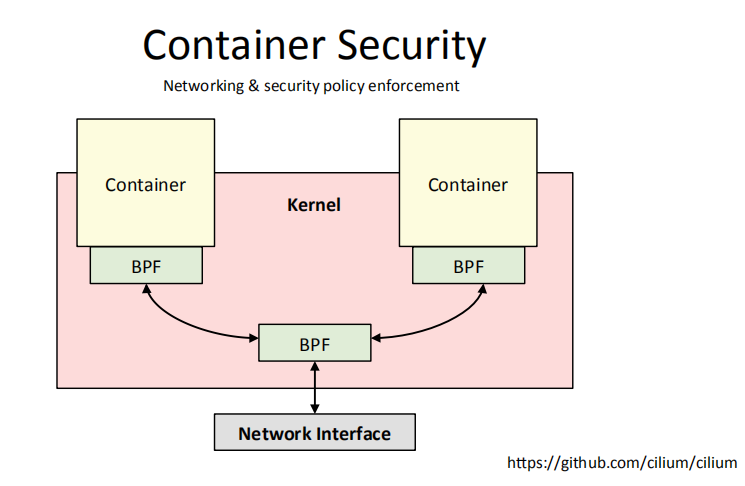
3.3 容器安全
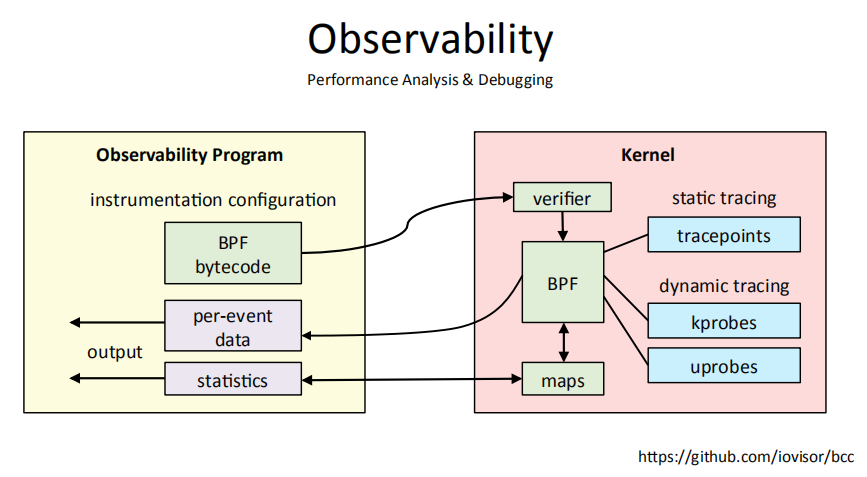
3.4 调试
4. bpftrace
bpftrace是Linux中基于eBPF的高级追踪语言,使用LLVM作为后端来编译eBPF字节码脚本,并使用BCC与Linux BPF系统交互。
它允许开发者用简洁的DSL(Domain Specific Language)编写eBPF程序,并将它们保存为脚本,开发者可以执行这些脚本,而不必在内核中手动编译和加载它们。
bpftrace在实现内核行为追踪时使用的探针主要包括内核动态探针(Kprobes)和内核静态探针(Tracepoints)两种,这些探针延续了以往常见的动态追踪工具所使用的内核探针设计。
4.1 内核动态探针-Kprobes
eBPF支持的内核探针(Kernel probes)功能,允许开发者在几乎所有的内核指令中以最小的开销设置动态的标记或中断。当内核运行到某个标记的时候,就会执行附加到这个探测点上的代码,然后恢复正常的流程。对内核行为的追踪探测,可以获取内核中发生任何事件的信息,比如系统中打开的文件、正在执行的二进制文件、系统中发生的TCP连接等。
内核动态探针可以分为两种:kprobes 和 kretprobes。二者的区别在于,根据探针执行周期的不同阶段,来确定插入eBPF程序的位置。kprobes类型的探针用于跟踪内核函数调用,是一种功能强大的探针类型,让我们可以追踪成千上万的内核函数。由于它们用来跟踪底层内核的,开发者需要熟悉内核源代码,理解这些探针的参数、返回值的意义。
Kprobes通常在内核函数执行前插入eBPF程序,而kretprobes则在内核函数执行完毕返回之后,插入相应的eBPF程序。比如,tcp_connect() 是一个内核函数,当有TCP连接发生时,将调用该函数,那么如果对tcp_connect()使用kprobes探针,则对应的eBPF程序会在tcp_connect() 被调用时执行,而如果是使用kretprobes探针,则eBPF程序会在tcp_connect() 执行返回时执行。后文会举例说明如何使用Kprobes探针。
尽管Kprobes允许在执行任何内核功能之前插入eBPF程序。但是,它是一种“不稳定”的探针类型,开发者在使用Kprobes时,需要知道想要追踪的函数签名(Function Signature)。而Kprobes当前没有稳定的应用程序二进制接口(ABI),这意味着它们可能在内核不同的版本之间发生变化。如果内核版本不同,内核函数名、参数、返回值等可能会变化。如果尝试将相同的探针附加到具有两个不同内核版本的系统上,则相同的代码可能会停止工作。
因此,开发者需要确保使用Kprobe的eBPF程序与正在使用的特定内核版本是兼容的。
例如,我们可以通过bpftrace的以下命令,列出当前版本内核所支持Kprobes探针列表。
root@u18-181:/tmp# bpftrace -l 'kprobe:tcp*'kprobe:tcp_mmapkprobe:tcp_get_info_chrono_statskprobe:tcp_init_sockkprobe:tcp_splice_data_recvkprobe:tcp_pushkprobe:tcp_send_msskprobe:tcp_cleanup_rbufkprobe:tcp_set_rcvlowatkprobe:tcp_recv_timestampkprobe:tcp_enter_memory_pressure
4.2 内核静态探针-Tracepoints
Tracepoints是在内核代码中所做的一种静态标记,是开发者在内核源代码中散落的一些hook,开发者可以依托这些hook实现相应的追踪代码插入。
开发者在/sys/kernel/debug/tracing/events/目录下,可以查看当前版本的内核支持的所有Tracepoints,在每一个具体Tracepoint目录下,都会有一系列对其进行配置说明的文件,比如可以通过enable中的值,来设置该Tracepoint探针的开关等。与Kprobes相比,他们的主要区别在于,Tracepoints是内核开发人员已经在内核代码中提前埋好的,这也是为什么称它们为静态探针的原因。而kprobes更多的是跟踪内核函数的进入和返回,因此将其称为动态的探针。但是内核函数会随着内核的发展而出现或者消失,因此kprobes对内核版本有着相对较强的依赖性,前文也有提到,针对某个内核版本实现的追踪代码,对于其它版本的内核,很有可能就不工作了。
那么,相比Kprobes探针,我们更加喜欢用Tracepoints探针,因为Tracepoints有着更稳定的应用程序编程接口,而且在内核中保持着前向兼容,总是保证旧版本中的跟踪点将存在于新版本中。
然而,Tracepoints的不足之处在于,这些探针需要开发人员将它们添加到内核中,因此,它们可能不会覆盖内核的所有子系统,只能使用当前版本内核所支持的探测点。
例如,我们可以通过bpftrace的以下命令,列出当前版本内核所支持的Tracepoints探针列表。
root@u18-181:/tmp# bpftrace -l 'tracepoint:*'tracepoint:syscalls:sys_enter_sockettracepoint:syscalls:sys_enter_socketpairtracepoint:syscalls:sys_enter_bindtracepoint:syscalls:sys_enter_listentracepoint:syscalls:sys_enter_accept4tracepoint:syscalls:sys_enter_accepttracepoint:syscalls:sys_enter_connecttracepoint:syscalls:sys_enter_getsockname
4.3 bpftrace安装使用
bpftrace是建立在eBPF之上的一种编程语言,考虑到部分特性需满足Linux内核的支持,因此建议Linux的内核版本在4.9以上,部分功能在低版本内核中是不支持的,例如Tracepoints是从4.7开始支持,Uprobes从4.3开始支持,Kprobes从4.1开始支持。
bpftrace的一个方便之处在于,其既可以通过一个命令行,完成简单动态追踪,又可以按照其规定的语法结构,将追踪逻辑编辑成可执行的脚本。
命令行示例:
# Files opened by process
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
# Syscall count by program
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# Read bytes by process:
bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret/ { @[comm] = sum(args->ret); }'
脚本示例:
#!/usr/bin/env bpftrace
/*
* tcpaccept.bt Trace TCP accept()s
* For Linux, uses bpftrace and eBPF.
*
* USAGE: tcpaccept.bt
*
* This is a bpftrace version of the bcc tool of the same name.
*
* This uses dynamic tracing of the kernel inet_csk_accept() socket function
* (from tcp_prot.accept), and will need to be modified to match kernel changes.
* Copyright (c) 2018 Dale Hamel.
* Licensed under the Apache License, Version 2.0 (the "License")
* 23-Nov-2018 Dale Hamel created this.
*/
#include <linux/socket.h>
#include <net/sock.h>
BEGIN
{
printf("Tracing TCP accepts. Hit Ctrl-C to end.\n");
printf("%-8s %-6s %-14s ", "TIME", "PID", "COMM");
printf("%-39s %-5s %-39s %-5s %s\n", "RADDR", "RPORT", "LADDR",
"LPORT", "BL");
}
kretprobe:inet_csk_accept
{
$sk = (struct sock *)retval;
$inet_family = $sk->__sk_common.skc_family;
if ($inet_family == AF_INET || $inet_family == AF_INET6) {
// initialize variable type:
$daddr = ntop(0);
$saddr = ntop(0);
if ($inet_family == AF_INET) {
$daddr = ntop($sk->__sk_common.skc_daddr);
$saddr = ntop($sk->__sk_common.skc_rcv_saddr);
} else {
$daddr = ntop(
$sk->__sk_common.skc_v6_daddr.in6_u.u6_addr8);
$saddr = ntop(
$sk->__sk_common.skc_v6_rcv_saddr.in6_u.u6_addr8);
}
$lport = $sk->__sk_common.skc_num;
$dport = $sk->__sk_common.skc_dport;
$qlen = $sk->sk_ack_backlog;
$qmax = $sk->sk_max_ack_backlog;
// Destination port is big endian, it must be flipped
$dport = ($dport >> 8) | (($dport << 8) & 0x00FF00);
time("%H:%M:%S ");
printf("%-6d %-14s ", pid, comm);
printf("%-39s %-5d %-39s %-5d ", $daddr, $dport, $saddr,
$lport);
printf("%d/%d\n", $qlen, $qmax);
}
}
参考
- 深入理解 BPF:一个阅读清单
- eBPF 简史
- 几句话说清楚20:eBPF的机制
- 看字节跳动容器化场景下,如何实现性能优化?
- 实现一个基于XDP/eBPF的学习型网桥
- https://github.com/iovisor/bpftrace
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190934.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
