大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
在上一篇博客里我介绍了如何利用keras对一个给定的数据集来完成多分类任务。
100%的分类准确度验证了分类模型的可行性和数据集的准确度。
在这篇博客当中我将利用一个稍加修改的数据集来完成回归任务。
数据集大小仍然是247*900,不同的是数据集的第247位变成了湿度特征的真实湿度值。
用来表示湿度的样本是我们自己配置的,所以真实的湿度都是有理可循的,不是为了突出不同类别而捏造的。
或者百度网盘:
链接:https://pan.baidu.com/s/1R0Ok5lB_RaI2cVHychZuxQ
提取码:9nwi
复制这段内容后打开百度网盘手机App,操作更方便哦
不同于分类算法得到的决策面,回归算法得到的是一个最优拟合线,这个线条可以最好的接近数据集中得各个点。
首先依旧是数据集的导入和划分:
# 载入数据
df = pd.read_csv(r"C:\Users\316CJW\Desktop\毕设代码\室内_10_50_9.csv")
X = np.expand_dims(df.values[:, 0:246].astype(float), axis=2)#增加一维轴
Y = df.values[:, 246]
# 划分训练集,测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5, random_state=0)这里我便不做细说了,想要了解的同学可以看一下上一篇博客。
接着是网络模型的搭建:
# 定义一个神经网络
model = Sequential()
model.add(Conv1D(16, 3,input_shape=(246,1), activation='relu'))
model.add(Conv1D(16, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(64, 3, activation='relu'))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(64, 3, activation='relu'))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Flatten())
model.add(Dense(1, activation='linear'))
plot_model(model, to_file='./model_linear.png', show_shapes=True)
print(model.summary())
model.compile(optimizer='adam', loss='mean_squared_error', metrics=[coeff_determination])为了完成回归任务,神经网络的输出层需要被设置为一个结点,它表示输出每一条湿度信息的预测结果。
model.add(Dense(1, activation='linear'))我们使用均方误差(Mean Squared Error,MSE)做输出层的损失函数,MSE经常被用做来比较模型预测值与真实值的偏差,在我们的任务中,通过不断减小损失函数的值,进而让整个网络尽可能地去拟合它真实的湿度值。
整个网络模型的示意图如下:
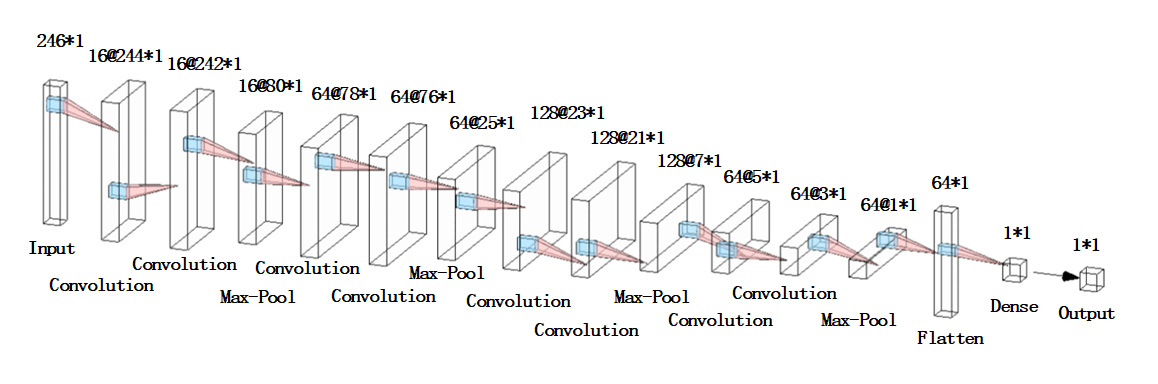

经过多次调参之后,我们选用8层Conv1D来提取特征,每两层Conv1D后添加一层MaxPooling1D来保留主要特征,减少计算量。每层卷积层使用线性整流函数(Rectified Linear Unit, ReLU)作为激活函数。最后一层深度层输出湿度预测值,在MSE损失函数的逼近下,湿度的预测值会愈来愈趋向于真实值。
为了可以更准确的回归数据的真实湿度值,使用的网络层数明显比分类时要更深。
为了评估网络模型训练和测试过程的准确度,我们需要自定义度量函数:
决定系数R2(coefficient ofdetermination)常常在线性回归中被用来表征有多少百分比的因变量波动被回归线描述。如果R2 =1则表示模型完美地预测了目标变量。
表达式:R2=SSR/SST=1-SSE/SST
其中:SST=SSR+SSE,SST(total sum of squares)为总平方和,SSR(regression sum of squares)为回归平方和,SSE(error sum of squares) 为残差平方和。
# 自定义度量函数
def coeff_determination(y_true, y_pred):
SS_res = K.sum(K.square( y_true-y_pred ))
SS_tot = K.sum(K.square( y_true - K.mean(y_true) ) )
return ( 1 - SS_res/(SS_tot + K.epsilon()) )并把它运用到编译中来:
model.compile(optimizer='adam', loss='mean_squared_error', metrics=[coeff_determination])下面贴出整个运行过程的完整代码:
# -*- coding: utf8 -*-
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.utils import np_utils,plot_model
from sklearn.model_selection import cross_val_score,train_test_split
from keras.layers import Dense, Dropout,Flatten,Conv1D,MaxPooling1D
from keras.models import model_from_json
import matplotlib.pyplot as plt
from keras import backend as K
# 载入数据
df = pd.read_csv(r"C:\Users\Desktop\数据集-用做回归.csv")
X = np.expand_dims(df.values[:, 0:246].astype(float), axis=2)#增加一维轴
Y = df.values[:, 246]
# 划分训练集,测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5, random_state=0)
# 自定义度量函数
def coeff_determination(y_true, y_pred):
SS_res = K.sum(K.square( y_true-y_pred ))
SS_tot = K.sum(K.square( y_true - K.mean(y_true) ) )
return ( 1 - SS_res/(SS_tot + K.epsilon()) )
# 定义一个神经网络
model = Sequential()
model.add(Conv1D(16, 3,input_shape=(246,1), activation='relu'))
model.add(Conv1D(16, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(64, 3, activation='relu'))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(64, 3, activation='relu'))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Flatten())
model.add(Dense(1, activation='linear'))
plot_model(model, to_file='./model_linear.png', show_shapes=True)
print(model.summary())
model.compile(optimizer='adam', loss='mean_squared_error', metrics=[coeff_determination])
# 训练模型
model.fit(X_train,Y_train, validation_data=(X_test, Y_test),epochs=40, batch_size=10)
# # 将其模型转换为json
# model_json = model.to_json()
# with open(r"C:\Users\Desktop\model.json",'w')as json_file:
# json_file.write(model_json)# 权重不在json中,只保存网络结构
# model.save_weights('model.h5')
#
# # 加载模型用做预测
# json_file = open(r"C:\Users\Desktop\model.json", "r")
# loaded_model_json = json_file.read()
# json_file.close()
# loaded_model = model_from_json(loaded_model_json)
# loaded_model.load_weights("model.h5")
# print("loaded model from disk")
# scores = model.evaluate(X_test,Y_test,verbose=0)
# print('%s: %.2f%%' % (model.metrics_names[1], scores[1]*100))
# 准确率
scores = model.evaluate(X_test,Y_test,verbose=0)
print('%s: %.2f%%' % (model.metrics_names[1], scores[1]*100))
# 预测值散点图
predicted = model.predict(X_test)
plt.scatter(Y_test,predicted)
x=np.linspace(0,0.3,100)
y=x
plt.plot(x,y,color='red',linewidth=1.0,linestyle='--',label='line')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.legend(["y = x","湿度预测值"])
plt.title("预测值与真实值的偏离程度")
plt.xlabel('真实湿度值')
plt.ylabel('湿度预测值')
plt.savefig('test_xx.png', dpi=200, bbox_inches='tight', transparent=False)
plt.show()
# 计算误差
result =abs(np.mean(predicted - Y_test))
print("The mean error of linear regression:")
print(result)在评估实验结果时,我是输出了决定系数的值以及回归湿度和真实湿度的平均偏差:
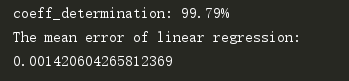
可以看出99%的点找到了他们应该去的归宿,即被回归线所扫瞄到。
平均误差在0.0014,可以说是一个很好的结果。
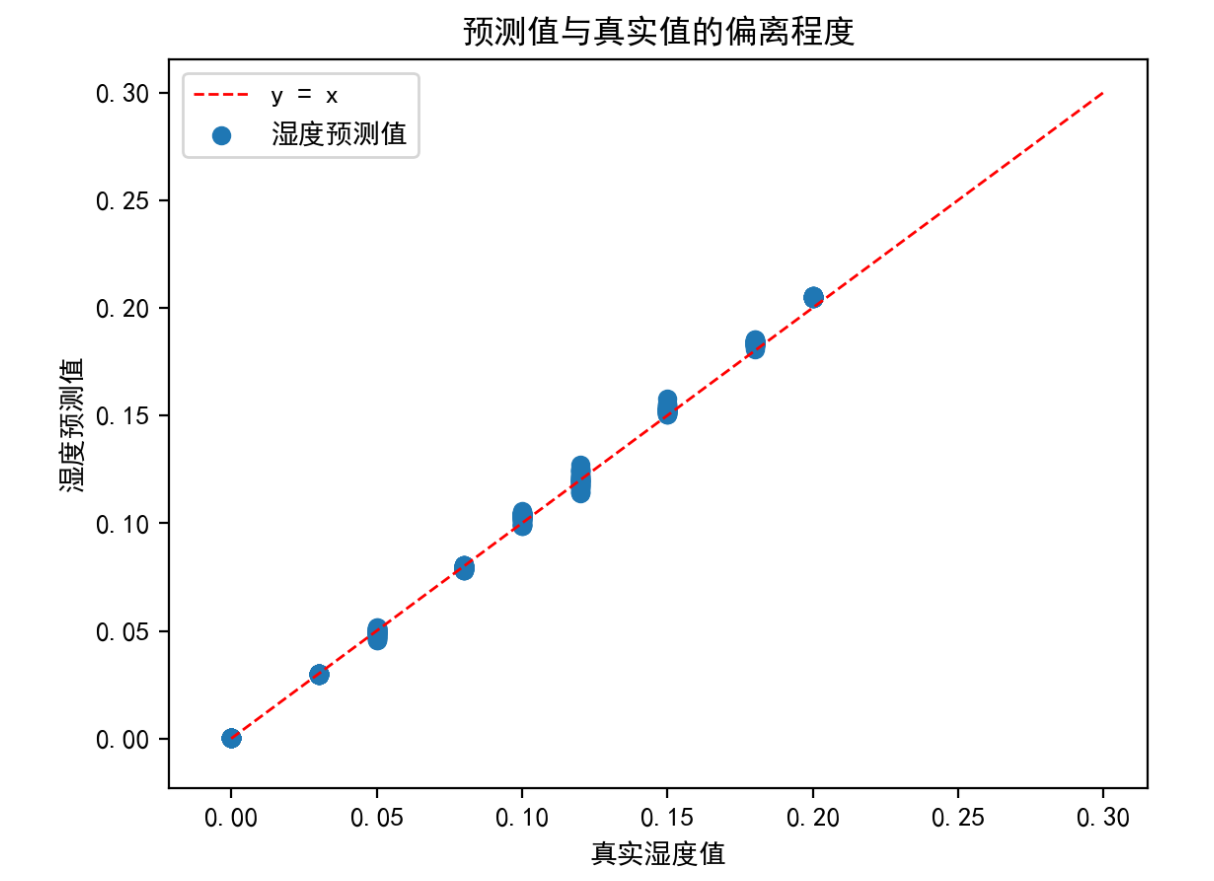
另一方面,我以真实湿度为x轴,预测湿度为y轴绘制了预测数据的散点图。
从图中可以看出预测数据较好的逼近了真实湿度值。
其实神经网络这套方法都比较相似,机器的计算代替了很多人为的推理和演算。
希望可以和大家多多交流,共同进步(●’◡’●)!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190533.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
