大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
目录
根据现有的研究成果来看,声源定位(Sound Source Localization, SSL)存在以下几种方法:基于最大输出功率的可控波束成形的定位方法、基于高分辨谱估计的定位方法和基于到达时延差(Time Difference of Arrival,TDOA)估计的定位方法,以及基于机器学习的方法。其中基于时延估计的定位方法计算量小,实时性好,实用性强等特点,我们就先介绍这种较为简单的声源定位算法。基于TDOA的方法一般分为两步,首先计算声源信号到达麦克风阵列的时间差(时延估计),然后通过麦克风阵列的几何形状建立声源定位模型并求解从而获得位置信息(定位估计)。
1. TDOA简介
首先介绍下TDOA的概念,如图所示,假设我们在空间中有一个声源(记为s(t),其在空间的位置为S)两个麦克风(记为m1和m2,它们在空间的位置分别为M1和M2,接收到的信号为x1(t)和x2(t)


那么麦克风m1和m2收到的信号分别为:
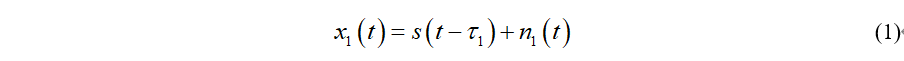
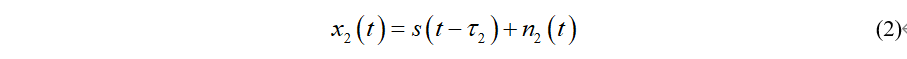
其中τ1和τ2分别是声源到达两个麦克风的延迟时间,n1(t)和n2(t)为加性噪声。那么声源信号到达两个麦克风的TDOA为
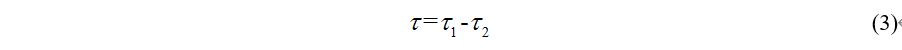
τ1和τ2可以通过下式计算
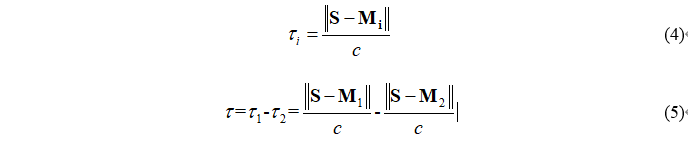
其中c是声速。一般情况下,我们选择一个麦克风的信号作为参考信号,例如我们把M2作为参考信号,那么τ2=0。在麦克风阵列几何形状已知的情况下,声源定位问题变为对时延的估计问题。
2. 时延估计
时延估计常用的有很多种比如使用广义互相关函数(Generalized Cross Correlation, GCC)估计时延,或者使用倒谱分析进行时延估计等,这里介绍常用的基于广义互相关函数时延估计方法。
互相关函数我们以前已经介绍过了,而广义互相关函数是为了减少噪声和混响在实际环境中的影响,在互功率谱域使用加权函数加权,然后经过IFFT运算后找到峰值估计时延,其流程如下图所示:
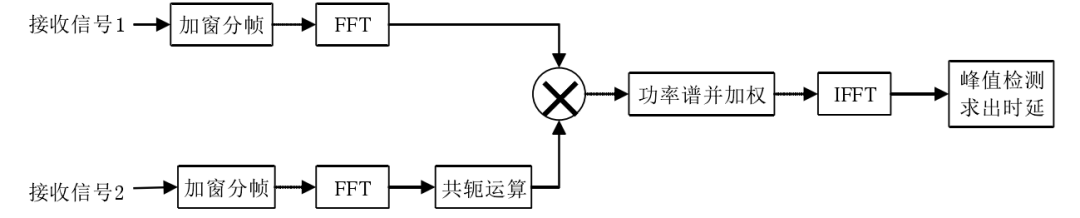
广义GCC计算公式为:
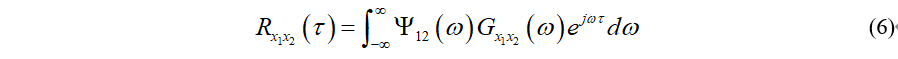
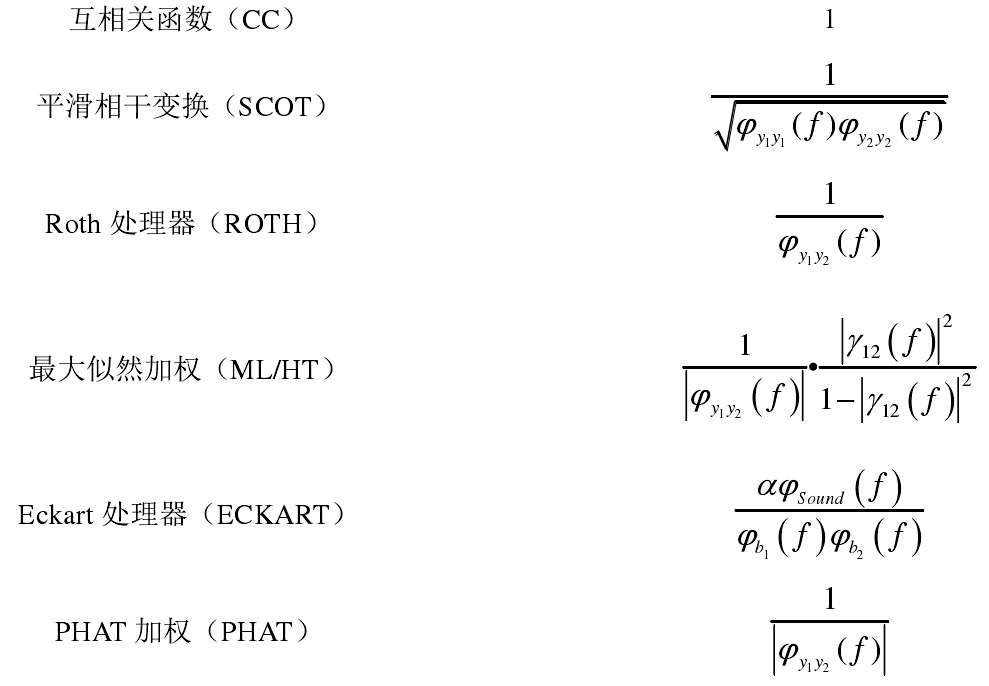
其中Ψ12为频域加权函数,常用的有如下几种
Gx1x2(ω)为互频谱,其计算公式为:
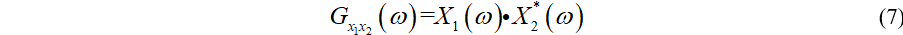
最后我们就可以通过式(8)估计语音信号到达两个麦克风的时延了。
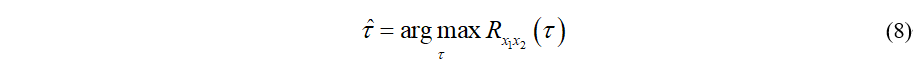
3. 定位估计
如果要确定出声源在二维平面内的位置坐标,都至少需要三个麦克风。对于两个麦克风的情况,我们只能计算到达角(Direction of Arrival, DOA)。在介绍如何定位估计前需要先区分下近场(near-field)和远场(far-field),假设声速波长为λ,麦克风之间的距离为d(有的地方称为孔径,aperture),那么声源与麦克风之间的距离r大于2d2/λ时,符合远场模型,反之则为近场模型。对于远场模型来说,声源到达麦克风阵列的波形视为平面波,如下图所示:
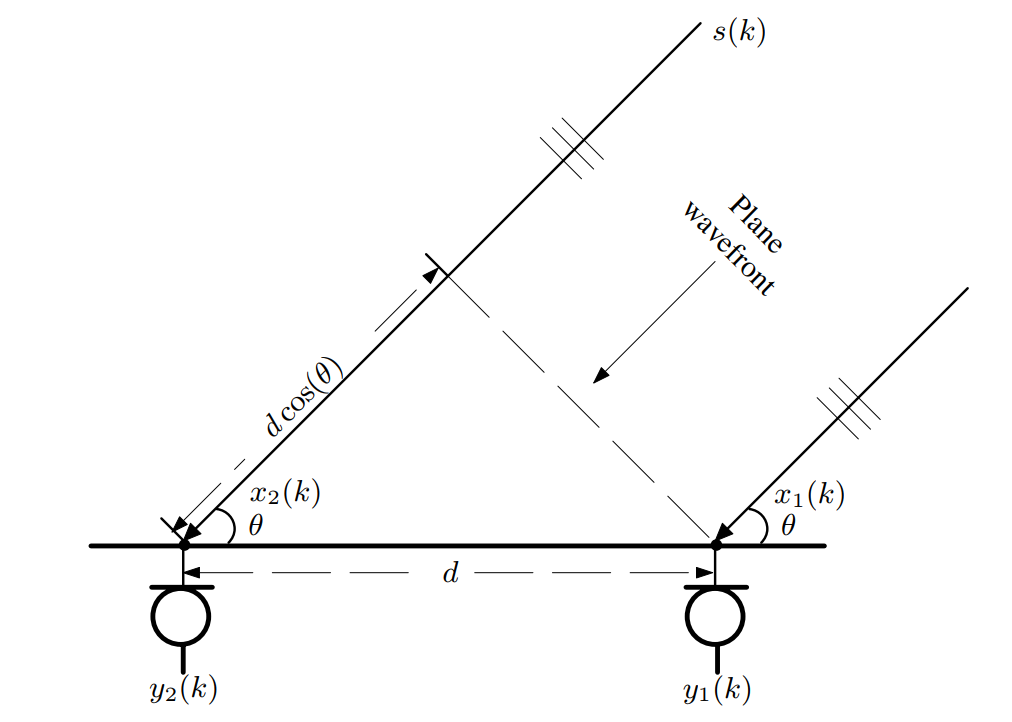
此时根据麦克风阵列的几何关系,我们有
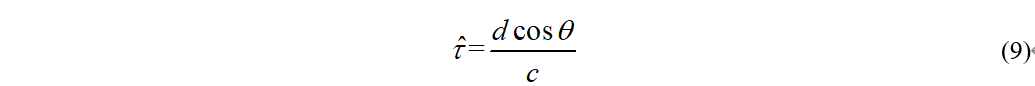
进而可以求出,声源相对麦克风阵列的角度
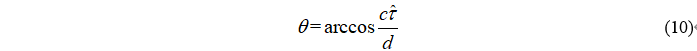
对于近场模型来说,声源到达麦克风阵列的波形视为球面波,如下图所示:
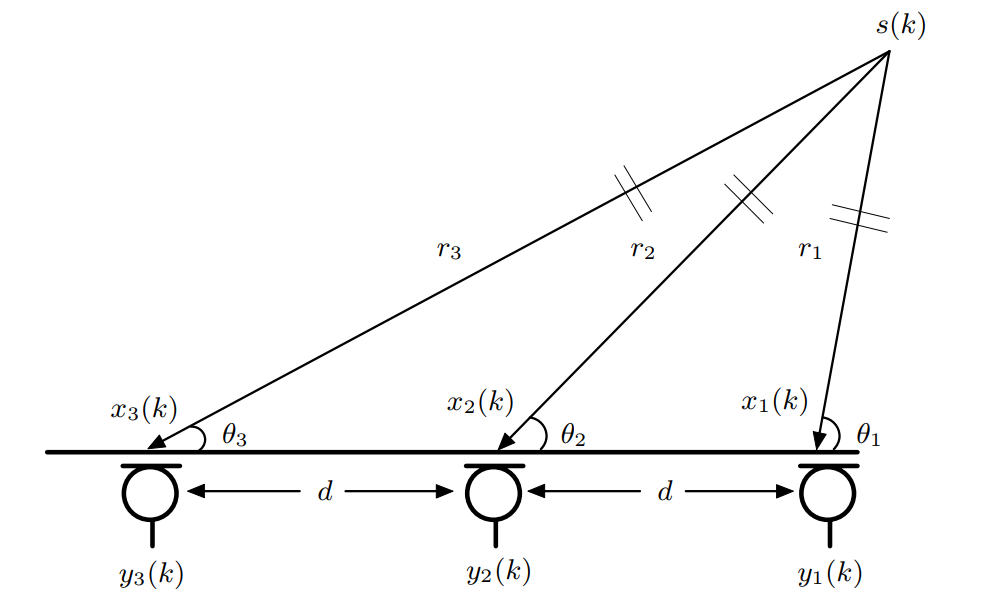
近场模型需要三个麦克风,我们假设τ12,τ13分别为第二和第三个麦克风与第一个麦克风的时延,那么
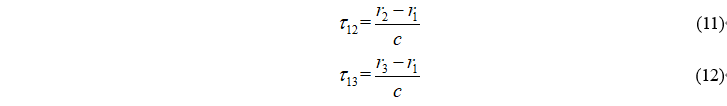
根据麦克风阵列的几何关系,我们得到
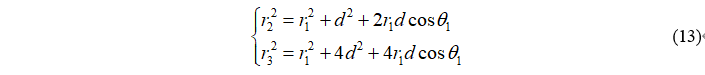
其中τ12,τ13通过时延估计得到,因此可以求解公式(11)到(13)的方程组,进而使用正弦定理可以得到θ2和θ3。
4. 声源定位
在麦克风孔径不大的情况下,一般都符合远场模型(不信读者可自己算一下),因此这里应用远场模型进行声源定位。声源位置在大约在45度角,麦克风之间的距离为0.15m,48 kHz的采样率,使用gcc-phat进行时延估计,结果如下图所示(代码和数据还是在公众号菜单More->Code里面)。

可以看到大体上方向还是被正确估计到,想必聪明的读者已经发现了声源定位的一些数据可以进行VAD结果的判定。这里的Demo比较简单,采用的是单源自由场模型,真实情况下需要考虑更多的问题,比如房间的混响,噪声,声源个数等问题。另外gcc-phat只能用于双麦克风阵列,如果你有多个麦克风,可以使用Spatial Linear Prediction Method 方法去利用麦克风之间的冗余信息获得更为精确的定位结果。此外波束成形(Beam forming, BF)和声源定位联系比较密切,因为时延和BF所要求的导向量等价,因此也有基于BF的声源定位算法。最后提一下机器学习/深度学习的定位方法,前面的流程还是不变,只是最后通过最大值估计时延的这一步换成了使用机器学习模型来估计时延,即模型输入为gcc-phat,输出结果为时延。然后根据这个时延进行声源定位。
参考文献:
[1]. https://www.canalu.tv/video/inria/time_difference_of_arrival_tdoa.33273
[2]. Springer, Micrphone Array Processing,2008
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190511.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
