大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
aarch32 linux4.14
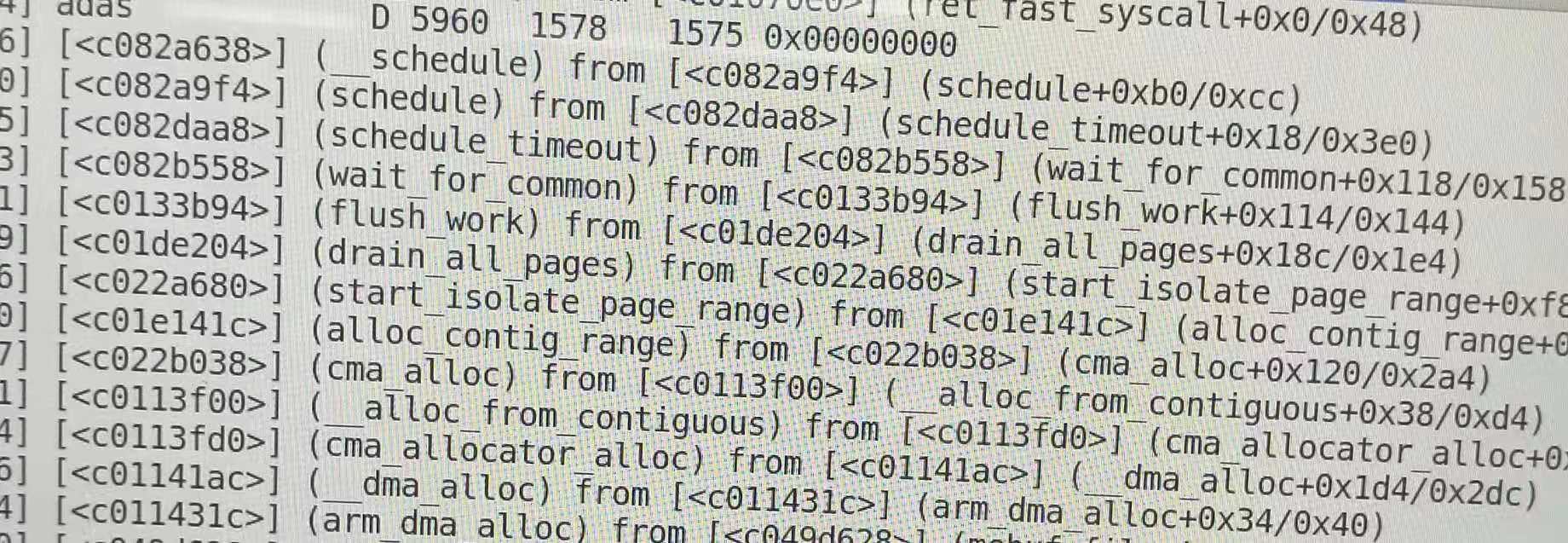
最近遇到一个kworker问题,callstack如下,线程adas的陷入kernel space后会schedule_work调用一个while(1)的worker,kill adas后重新启动adas后adas线程会在调用dma_alloc_coherent的时候block住

以前的经验一直kworker为轻量的线程和可睡眠的中断下半部,对kworker认识不足
阅读Documentation/core-api/workqueue.rst和kworker源码kernel/workqueue.c
Why cmwq?
In the original wq implementation, a multi threaded (MT) wq had one worker thread per CPU and a single threaded (ST) wq had one worker thread system-wide. A single MT wq needed to keep around the same number of workers as the number of CPUs. The kernel grew a lot of MT wq users over the years and with the number of CPU cores continuously rising, some systems saturated the default 32k PID space just booting up.
Although MT wq wasted a lot of resource, the level of concurrency provided was unsatisfactory. The limitation was common to both ST and MT wq albeit less severe on MT. Each wq maintained its own separate worker pool. An MT wq could provide only one execution context per CPU while an ST wq one for the whole system. Work items had to compete for those very limited execution contexts leading to various problems including proneness to deadlocks around the single execution context.
The tension between the provided level of concurrency and resource usage also forced its users to make unnecessary tradeoffs like libata choosing to use ST wq for polling PIOs and accepting an unnecessary limitation that no two polling PIOs can progress at the same time. As MT wq don’t provide much better concurrency, users which require higher level of concurrency, like async or fscache, had to implement their own thread pool.
Concurrency Managed Workqueue (cmwq) is a reimplementation of wq with focus on the following goals.
-
Maintain compatibility with the original workqueue API.
-
Use per-CPU unified worker pools shared by all wq to provide flexible level of concurrency on demand without wasting a lot of resource.
-
Automatically regulate worker pool and level of concurrency so
-
that the API users don’t need to worry about such details.
–>阅读后需要解决的疑问有下,一一的从源码中找到答案
1. 如何初始化(percpu)kworker
2. kworker如何调度
3.高优先级的workqueue是如何保证高优先级的
4. schedule_work成功和失败对于kworker调度的影响
5. flush_work都做了什么事情
———————————————————————————————————————————————————————–
1. kworker组织结构和初始化
kworker的初始化分两步,从start_kernel中的如下注释可知两步过程分别完成的内容
/* Allow workqueue creation and work item queueing/cancelling
* early. Work item execution depends on kthreads and starts after
* workqueue_init().
*//**
* workqueue_init_early – early init for workqueue subsystem
* This is the first half of two-staged workqueue subsystem initialization
* and invoked as soon as the bare basics – memory allocation, cpumasks and
* idr are up. It sets up all the data structures and system workqueues
* and allows early boot code to create workqueues and queue/cancel work
* items. Actual work item execution starts only after kthreads can be
* created and scheduled right before early initcalls.
*/
stage 1:start_kernel –> workqueue_init_early
stage 2:start_kernel –> arch_call_rest_init –> rest_init –> kernel_init –> kernel_init_freeable –> workqueue_init
struct worker_pool {
spinlock_t lock; /* the pool lock */
int cpu; /* I: the associated cpu */
int node; /* I: the associated node ID */
int id; /* I: pool ID */
unsigned int flags; /* X: flags */
unsigned long watchdog_ts; /* L: watchdog timestamp */
struct list_head worklist; /* L: list of pending works */
int nr_workers; /* L: total number of workers */
}从stage1 的源码能看出工作池共NR_STD_WORKER_POOLS×n 个n代表cpu数量,NR_STD_WORKER_POOLS为2(两种子类型普通优先级队列(NICE=0),高优先级队列(NICE=-20))。在初始化workqueue的过程中会将workerqueue与work pool绑定,alloc_and_link_pwqs函数
/*
* System-wide workqueues which are always present.
*
* system_wq is the one used by schedule[_delayed]_work[_on]().
* Multi-CPU multi-threaded. There are users which expect relatively
* short queue flush time. Don't queue works which can run for too
* long.
*
* system_highpri_wq is similar to system_wq but for work items which
* require WQ_HIGHPRI.
*
* system_long_wq is similar to system_wq but may host long running
* works. Queue flushing might take relatively long.
*
* system_unbound_wq is unbound workqueue. Workers are not bound to
* any specific CPU, not concurrency managed, and all queued works are
* executed immediately as long as max_active limit is not reached and
* resources are available.
*
* system_freezable_wq is equivalent to system_wq except that it's
* freezable.
*
* *_power_efficient_wq are inclined towards saving power and converted
* into WQ_UNBOUND variants if 'wq_power_efficient' is enabled; otherwise,
* they are same as their non-power-efficient counterparts - e.g.
* system_power_efficient_wq is identical to system_wq if
* 'wq_power_efficient' is disabled. See WQ_POWER_EFFICIENT for more info.
*/
static LIST_HEAD(workqueues); /* PR: list of all workqueues */
int __init workqueue_init_early(void)
{
system_wq = alloc_workqueue("events", 0, 0);
system_highpri_wq = alloc_workqueue("events_highpri", WQ_HIGHPRI, 0);
system_long_wq = alloc_workqueue("events_long", 0, 0);
system_unbound_wq = alloc_workqueue("events_unbound", WQ_UNBOUND,
WQ_UNBOUND_MAX_ACTIVE);
system_freezable_wq = alloc_workqueue("events_freezable",
WQ_FREEZABLE, 0);
system_power_efficient_wq = alloc_workqueue("events_power_efficient",
WQ_POWER_EFFICIENT, 0);
system_freezable_power_efficient_wq = alloc_workqueue("events_freezable_power_efficient",
WQ_FREEZABLE | WQ_POWER_EFFICIENT,
0);
}
struct workqueue_struct *__alloc_workqueue_key(const char *fmt,
unsigned int flags,
int max_active,
struct lock_class_key *key,
const char *lock_name, ...)
{
list_add_tail_rcu(&wq->list, &workqueues);
if (alloc_and_link_pwqs(wq) < 0)
goto err_free_wq;
}
static int alloc_and_link_pwqs(struct workqueue_struct *wq)
{
bool highpri = wq->flags & WQ_HIGHPRI;
int cpu, ret;
if (!(wq->flags & WQ_UNBOUND)) {
for_each_possible_cpu(cpu) {
struct pool_workqueue *pwq =
per_cpu_ptr(wq->cpu_pwqs, cpu);
struct worker_pool *cpu_pools =
per_cpu(cpu_worker_pools, cpu);
init_pwq(pwq, wq, &cpu_pools[highpri]);
link_pwq(pwq);
}
return 0;
} else if (wq->flags & __WQ_ORDERED) {
ret = apply_workqueue_attrs(wq, ordered_wq_attrs[highpri]);
/* there should only be single pwq for ordering guarantee */
WARN(!ret && (wq->pwqs.next != &wq->dfl_pwq->pwqs_node ||
wq->pwqs.prev != &wq->dfl_pwq->pwqs_node),
"ordering guarantee broken for workqueue %s\n", wq->name);
return ret;
} else {
return apply_workqueue_attrs(wq, unbound_std_wq_attrs[highpri]);
}
}
/sys/devices/virtual/workqueue/writeback # ps |grep kworker
3 root 0:00 [kworker/0:0]
4 root 0:00 [kworker/0:0H]
5 root 0:00 [kworker/u4:0]
16 root 0:00 [kworker/1:0]
17 root 0:00 [kworker/1:0H]
20 root 0:00 [kworker/u4:1]
32 root 0:02 [kworker/0:1]
33 root 0:02 [kworker/1:1]
204 root 0:00 [kworker/u4:2]
1339 root 0:02 [kworker/0:2]
1425 root 0:01 [kworker/0:3]
1519 root 0:00 [kworker/1:2]
1524 root 0:00 [kworker/0:4]
1723 root 0:00 grep kworker
/sys/devices/virtual/workqueue/writeback # cat /sys/devices/virtual/workqueue/writeback/
cpumask max_active nice numa per_cpu pool_ids power/ subsystem/ uevent
/sys/devices/virtual/workqueue/writeback # cat /sys/devices/virtual/workqueue/writeback/pool_ids
0:4
/sys/devices/virtual/workqueue/writeback # cat /sys/devices/virtual/workqueue/writeback/nice
0
结构体pool_workqueue
/*
* The per-pool workqueue. While queued, the lower WORK_STRUCT_FLAG_BITS
* of work_struct->data are used for flags and the remaining high bits
* point to the pwq; thus, pwqs need to be aligned at two's power of the
* number of flag bits.
*/
struct pool_workqueue {
struct worker_pool *pool; /* I: the associated pool */
struct workqueue_struct *wq; /* I: the owning workqueue */
int work_color; /* L: current color */
int flush_color; /* L: flushing color */
int refcnt; /* L: reference count */
int nr_in_flight[WORK_NR_COLORS];
/* L: nr of in_flight works */
int nr_active; /* L: nr of active works */
int max_active; /* L: max active works */
struct list_head delayed_works; /* L: delayed works */
struct list_head pwqs_node; /* WR: node on wq->pwqs */
struct list_head mayday_node; /* MD: node on wq->maydays */
/*
* Release of unbound pwq is punted to system_wq. See put_pwq()
* and pwq_unbound_release_workfn() for details. pool_workqueue
* itself is also sched-RCU protected so that the first pwq can be
* determined without grabbing wq->mutex.
*/
struct work_struct unbound_release_work;
struct rcu_head rcu;
} __aligned(1 << WORK_STRUCT_FLAG_BITS);/**
* workqueue_init - bring workqueue subsystem fully online
*
* This is the latter half of two-staged workqueue subsystem initialization
* and invoked as soon as kthreads can be created and scheduled.
* Workqueues have been created and work items queued on them, but there
* are no kworkers executing the work items yet. Populate the worker pools
* with the initial workers and enable future kworker creations.
*/
int __init workqueue_init(void)
{
/* create the initial workers */
for_each_online_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
pool->flags &= ~POOL_DISASSOCIATED;
BUG_ON(!create_worker(pool));
}
}
hash_for_each(unbound_pool_hash, bkt, pool, hash_node)
BUG_ON(!create_worker(pool));
}从stage1 和stage2 源码可以看出默认每个cpu有两个worker pool一个高优先级一个低优先级的pool,每个work pool有workueue list和worker list,工作池包含多个工作队列和多个工作者,并且会初始化系统默认的7个工作队列,并将这些队列加入到全局的workerqueues链表中。stage2 中creat_worker 中会创建percpu的kworker/*:[*H]和unbound的kworker/u*:*,ps可以看到这些命名的线程,命名规则参考kernel document kernel-per-CPU-kthreads.txt /* kworker/%u:%d%s (cpu, id, priority) H代表高优先级 u代表unbound*/ 。这个阶段会初始化2个percpu pool 对应的工作者线程和1个unbound pool 对应的工作者线程(只有cpu0),其他cpu bootup的时候会创建2个percpu pool对应的kworker。
/**
* create_worker - create a new workqueue worker
* @pool: pool the new worker will belong to
*
* Create and start a new worker which is attached to @pool.
*
* CONTEXT:
* Might sleep. Does GFP_KERNEL allocations.
*
* Return:
* Pointer to the newly created worker.
*/
static struct worker *create_worker(struct worker_pool *pool)
{
worker = alloc_worker(pool->node);
if (!worker)
goto fail;
worker->pool = pool;
worker->id = id;
if (pool->cpu >= 0)
snprintf(id_buf, sizeof(id_buf), "%d:%d%s", pool->cpu, id,
pool->attrs->nice < 0 ? "H" : "");
else
snprintf(id_buf, sizeof(id_buf), "u%d:%d", pool->id, id);
worker->task = kthread_create_on_node(worker_thread, worker, pool->node,
"kworker/%s", id_buf);
if (IS_ERR(worker->task))
goto fail;
set_user_nice(worker->task, pool->attrs->nice);
kthread_bind_mask(worker->task, pool->attrs->cpumask);
/* successful, attach the worker to the pool */
worker_attach_to_pool(worker, pool);
/* start the newly created worker */
spin_lock_irq(&pool->lock);
worker->pool->nr_workers++;
worker_enter_idle(worker);
wake_up_process(worker->task);
}从添加的log来看工作者线程的创建过程如下,大部分的kworker都是由其他kworker manage_workers创建的,percpu的kworker只会创建绑定对应cpu的kworker,unbound的kworker可以在不同的cpu上创建kworker。manage_workers 的策略是如果有工作要执行且worker pool中的nr_idle为空要创建一个新的kworker,如果已经进入idle的worker 超过(IDLE_WORKER_TIMEOUT)的时间没有再次被wakeup,就会被destroy_worker
/**
* manage_workers - manage worker pool
* @worker: self
*
* Assume the manager role and manage the worker pool @worker belongs
* to. At any given time, there can be only zero or one manager per
* pool. The exclusion is handled automatically by this function.
*
* The caller can safely start processing works on false return. On
* true return, it's guaranteed that need_to_create_worker() is false
* and may_start_working() is true.
*
* CONTEXT:
* spin_lock_irq(pool->lock) which may be released and regrabbed
* multiple times. Does GFP_KERNEL allocations.
*
* Return:
* %false if the pool doesn't need management and the caller can safely
* start processing works, %true if management function was performed and
* the conditions that the caller verified before calling the function may
* no longer be true.
*/
static bool manage_workers(struct worker *worker)
{
struct worker_pool *pool = worker->pool;
if (pool->flags & POOL_MANAGER_ACTIVE)
return false;
pool->flags |= POOL_MANAGER_ACTIVE;
pool->manager = worker;
maybe_create_worker(pool);
pool->manager = NULL;
pool->flags &= ~POOL_MANAGER_ACTIVE;
wake_up(&wq_manager_wait);
return true;
}[ 0.003251] create kworker 0:0
[ 0.003266] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 0.003275] Hardware name: Xilinx Zynq Platform
[ 0.003314] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 0.003340] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 0.003365] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 0.003389] [<c0133394>] (create_worker) from [<c0c0a7a0>] (workqueue_init+0xf0/0x184)
[ 0.003413] [<c0c0a7a0>] (workqueue_init) from [<c0c00d50>] (kernel_init_freeable+0xbc/0x23c)
[ 0.003439] [<c0c00d50>] (kernel_init_freeable) from [<c0829eec>] (kernel_init+0x8/0x108)
[ 0.003464] [<c0829eec>] (kernel_init) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 0.010395] create kworker 0:0H
[ 0.010412] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 0.010421] Hardware name: Xilinx Zynq Platform
[ 0.010447] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 0.010470] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 0.010491] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 0.010510] [<c0133394>] (create_worker) from [<c0c0a7a0>] (workqueue_init+0xf0/0x184)
[ 0.010531] [<c0c0a7a0>] (workqueue_init) from [<c0c00d50>] (kernel_init_freeable+0xbc/0x23c)
[ 0.010554] [<c0c00d50>] (kernel_init_freeable) from [<c0829eec>] (kernel_init+0x8/0x108)
[ 0.010575] [<c0829eec>] (kernel_init) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 0.020375] create kworker u4:0
[ 0.020390] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 0.020399] Hardware name: Xilinx Zynq Platform
[ 0.020425] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 0.020445] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 0.020466] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 0.020486] [<c0133394>] (create_worker) from [<c0c0a7fc>] (workqueue_init+0x14c/0x184)
[ 0.020505] [<c0c0a7fc>] (workqueue_init) from [<c0c00d50>] (kernel_init_freeable+0xbc/0x23c)
[ 0.020528] [<c0c00d50>] (kernel_init_freeable) from [<c0829eec>] (kernel_init+0x8/0x108)
[ 0.020549] [<c0829eec>] (kernel_init) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 0.040413] Setting up static identity map for 0x100000 - 0x100060
[ 0.060358] Hierarchical SRCU implementation.
[ 0.100358] smp: Bringing up secondary CPUs ...
[ 0.150389] create kworker 1:0
[ 0.150407] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 0.150416] Hardware name: Xilinx Zynq Platform
[ 0.150449] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 0.150473] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 0.150497] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 0.150522] [<c0133394>] (create_worker) from [<c013744c>] (workqueue_prepare_cpu+0x50/0x70)
[ 0.150550] [<c013744c>] (workqueue_prepare_cpu) from [<c011e178>] (cpuhp_invoke_callback+0x17c/0x860)
[ 0.150572] [<c011e178>] (cpuhp_invoke_callback) from [<c011fb44>] (_cpu_up+0x110/0x188)
[ 0.150591] [<c011fb44>] (_cpu_up) from [<c011fc28>] (do_cpu_up+0x6c/0x88)
[ 0.150618] [<c011fc28>] (do_cpu_up) from [<c0c0ece8>] (smp_init+0xc8/0xec)
[ 0.150641] [<c0c0ece8>] (smp_init) from [<c0c00d6c>] (kernel_init_freeable+0xd8/0x23c)
[ 0.150667] [<c0c00d6c>] (kernel_init_freeable) from [<c0829eec>] (kernel_init+0x8/0x108)
[ 0.150691] [<c0829eec>] (kernel_init) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 0.160377] create kworker 1:0H
[ 0.160393] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 0.160402] Hardware name: Xilinx Zynq Platform
[ 0.160428] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 0.160450] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 0.160471] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 0.160493] [<c0133394>] (create_worker) from [<c013744c>] (workqueue_prepare_cpu+0x50/0x70)
[ 0.160517] [<c013744c>] (workqueue_prepare_cpu) from [<c011e178>] (cpuhp_invoke_callback+0x17c/0x860)
[ 0.160538] [<c011e178>] (cpuhp_invoke_callback) from [<c011fb44>] (_cpu_up+0x110/0x188)
[ 0.160557] [<c011fb44>] (_cpu_up) from [<c011fc28>] (do_cpu_up+0x6c/0x88)
[ 0.160579] [<c011fc28>] (do_cpu_up) from [<c0c0ece8>] (smp_init+0xc8/0xec)
[ 0.160600] [<c0c0ece8>] (smp_init) from [<c0c00d6c>] (kernel_init_freeable+0xd8/0x23c)
[ 0.160622] [<c0c00d6c>] (kernel_init_freeable) from [<c0829eec>] (kernel_init+0x8/0x108)
[ 0.160643] [<c0829eec>] (kernel_init) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 0.171170] CPU1: thread -1, cpu 1, socket 0, mpidr 80000001
[ 0.171304] smp: Brought up 1 node, 2 CPUs
[ 0.171323] SMP: Total of 2 processors activated (1333.33 BogoMIPS).
[ 0.171332] CPU: All CPU(s) started in SVC mode.
[ 0.172876] devtmpfs: initialized
[ 0.178183] random: get_random_u32 called from bucket_table_alloc+0x1c8/0x228 with crng_init=0
[ 0.178641] VFP support v0.3: implementor 41 architecture 3 part 30 variant 9 rev 4
[ 0.178840] create kworker u4:1
[ 0.178859] CPU: 0 PID: 5 Comm: kworker/u4:0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 0.178869] Hardware name: Xilinx Zynq Platform
[ 0.178912] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 0.178939] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 0.178965] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 0.178989] [<c0133394>] (create_worker) from [<c0135cc8>] (worker_thread+0x17c/0x3ec)
[ 0.179011] [<c0135cc8>] (worker_thread) from [<c013a228>] (kthread+0x130/0x150)
[ 0.179035] [<c013a228>] (kthread) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 0.179045] clocksource: jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 19112604462750000 ns
[ 0.179062] futex hash table entries: 512 (order: 3, 32768 bytes)
[ 0.180779] kworker/u4:0 (21) used greatest stack depth: 6736 bytes left
[ 0.199716] create kworker 0:1
[ 0.199719] create kworker 1:1
[ 0.199733] CPU: 1 PID: 16 Comm: kworker/1:0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 0.199740] Hardware name: Xilinx Zynq Platform
[ 0.199782] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 0.199810] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 0.199837] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 0.199861] [<c0133394>] (create_worker) from [<c0135cc8>] (worker_thread+0x17c/0x3ec)
[ 0.199883] [<c0135cc8>] (worker_thread) from [<c013a228>] (kthread+0x130/0x150)
[ 0.199907] [<c013a228>] (kthread) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 0.199923] CPU: 0 PID: 3 Comm: kworker/0:0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 0.199933] Hardware name: Xilinx Zynq Platform
[ 0.199963] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 0.199985] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 0.200007] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 0.200029] [<c0133394>] (create_worker) from [<c0135cc8>] (worker_thread+0x17c/0x3ec)
[ 0.200049] [<c0135cc8>] (worker_thread) from [<c013a228>] (kthread+0x130/0x150)
[ 0.200070] [<c013a228>] (kthread) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 0.201987] cma: cma_alloc(): returned dfc92000
[ 0.240398] create kworker u4:2
[ 0.240421] CPU: 1 PID: 20 Comm: kworker/u4:1 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 0.240431] Hardware name: Xilinx Zynq Platform
[ 0.240483] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 0.240513] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 0.240542] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 0.240567] [<c0133394>] (create_worker) from [<c0135cc8>] (worker_thread+0x17c/0x3ec)
[ 0.240590] [<c0135cc8>] (worker_thread) from [<c013a228>] (kthread+0x130/0x150)
[ 0.240616] [<c013a228>] (kthread) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 0.286029] vgaarb: loaded
[ 0.286929] SCSI subsystem initialized
[ 1.604621] create kworker 0:2
[ 1.604640] CPU: 0 PID: 3 Comm: kworker/0:0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 1.604649] Hardware name: Xilinx Zynq Platform
[ 1.604694] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 1.604720] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 1.604746] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 1.604769] [<c0133394>] (create_worker) from [<c0135cc8>] (worker_thread+0x17c/0x3ec)
[ 1.604790] [<c0135cc8>] (worker_thread) from [<c013a228>] (kthread+0x130/0x150)
[ 1.604814] [<c013a228>] (kthread) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 5.126599] create kworker 0:3
[ 5.126616] CPU: 0 PID: 3 Comm: kworker/0:0 Not tainted 4.14.0-xilinx-00043-g75bc123-dirty #1
[ 5.126621] Hardware name: Xilinx Zynq Platform
[ 5.126662] [<c010f5fc>] (unwind_backtrace) from [<c010b334>] (show_stack+0x10/0x14)
[ 5.126685] [<c010b334>] (show_stack) from [<c0818818>] (dump_stack+0x80/0x9c)
[ 5.126706] [<c0818818>] (dump_stack) from [<c0133394>] (create_worker+0xb8/0x188)
[ 5.126726] [<c0133394>] (create_worker) from [<c0135cc8>] (worker_thread+0x17c/0x3ec)
[ 5.126743] [<c0135cc8>] (worker_thread) from [<c013a228>] (kthread+0x130/0x150)
[ 5.126763] [<c013a228>] (kthread) from [<c0107170>] (ret_from_fork+0x14/0x24)
[ 6.566896] macb e000b000.ethernet eth0: link up (100/Full)
除了系统默认的worker queue之外还可以自己创建worker queue,比如writeback workqueue 和内存信息统计的mm_percpu_wq
/* bdi_wq serves all asynchronous writeback tasks */
struct workqueue_struct *bdi_wq;
static int __init default_bdi_init(void)
{
int err;
bdi_wq = alloc_workqueue("writeback", WQ_MEM_RECLAIM | WQ_FREEZABLE |
WQ_UNBOUND | WQ_SYSFS, 0);
if (!bdi_wq)
return -ENOMEM;
err = bdi_init(&noop_backing_dev_info);
return err;
}
subsys_initcall(default_bdi_init);
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3 root 20 0 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H
5 root 20 0 0 0 0 I 0.0 0.0 0:00.51 kworker/u4:0
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq 2. kworker如何调度
工作队列的调度实际上就是kworker的调度,同级别工作池内的工作项的先后顺序是queue的先后顺序但manage workers机制会保证工作项的并发,这个机制下kworker的数量是在动态变化的,总要保证任何时候在一个kworke pool中要有一个预留的idle kworker,并且没有工作项的时候保证只有一个idle kworker,其他的都动态destroy掉以节省资源。
/**
* worker_thread - the worker thread function
* @__worker: self
*
* The worker thread function. All workers belong to a worker_pool -
* either a per-cpu one or dynamic unbound one. These workers process all
* work items regardless of their specific target workqueue. The only
* exception is work items which belong to workqueues with a rescuer which
* will be explained in rescuer_thread().
*
* Return: 0
*/
static int worker_thread(void *__worker)
{
/* no more worker necessary? */
if (!need_more_worker(pool))
goto sleep;
do {
struct work_struct *work =
list_first_entry(&pool->worklist,
struct work_struct, entry);
pool->watchdog_ts = jiffies;
if (likely(!(*work_data_bits(work) & WORK_STRUCT_LINKED))) {
/* optimization path, not strictly necessary */
process_one_work(worker, work);
if (unlikely(!list_empty(&worker->scheduled)))
process_scheduled_works(worker);
} else {
move_linked_works(work, &worker->scheduled, NULL);
process_scheduled_works(worker);
}
} while (keep_working(pool));
}
/**
* process_one_work - process single work
* @worker: self
* @work: work to process
*
* Process @work. This function contains all the logics necessary to
* process a single work including synchronization against and
* interaction with other workers on the same cpu, queueing and
* flushing. As long as context requirement is met, any worker can
* call this function to process a work.
*
* CONTEXT:
* spin_lock_irq(pool->lock) which is released and regrabbed.
*/
static void process_one_work(struct worker *worker, struct work_struct *work)
__releases(&pool->lock)
__acquires(&pool->lock)
{
/* claim and dequeue */
debug_work_deactivate(work);
hash_add(pool->busy_hash, &worker->hentry, (unsigned long)work);
worker->current_work = work;
worker->current_func = work->func;
worker->current_pwq = pwq;
work_color = get_work_color(work);
list_del_init(&work->entry);
trace_workqueue_execute_start(work);
worker->current_func(work);
/*
* While we must be careful to not use "work" after this, the trace
* point will only record its address.
*/
trace_workqueue_execute_end(work);
}使用schedule_work可以将自己创建的工作项加入到系统的工作队列中,这个接口使用的是unbound的普通优先级队列,等待worker调用到自己,如果当前work pool没有正在运行的worker,则唤醒一个
schedule_work –> queue_work(system_wq,work) –> queue_work_on(WORK_CPU_UNBOUND, system_wq, work)–> insert_work–>wakeup_worker(pool)
/*
* queue_work - queue work on a workqueue
* @wq: workqueue to use
* @work: work to queue
* Returns %false if @work was already on a queue, %true otherwise.
*
* We queue the work to the CPU on which it was submitted, but if the CPU dies
* it can be processed by another CPU.
*/
/* not bound to any CPU, prefer the local CPU */
WORK_CPU_UNBOUND
/**
* queue_work_on - queue work on specific cpu
* @cpu: CPU number to execute work on
* @wq: workqueue to use
* @work: work to queue
*
* We queue the work to a specific CPU, the caller must ensure it
* can't go away.
*
* Return: %false if @work was already on a queue, %true otherwise.
*/
bool queue_work_on(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
{
bool ret = false;
unsigned long flags;
local_irq_save(flags);
if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) {
__queue_work(cpu, wq, work);
ret = true;
}
local_irq_restore(flags);
return ret;
}另外cpu bootup hotplug会对bound 和unbound 的workerqueue重新绑核
static struct cpuhp_step cpuhp_bp_states[] = {
[CPUHP_WORKQUEUE_PREP] = {
.name = "workqueue:prepare",
.startup.single = workqueue_prepare_cpu,
.teardown.single = NULL,
}
}
static struct cpuhp_step cpuhp_ap_states[] = {
[CPUHP_AP_WORKQUEUE_ONLINE] = {
.name = "workqueue:online",
.startup.single = workqueue_online_cpu,
.teardown.single = workqueue_offline_cpu,
}
}3.如何保证的高优先级的workqueue的优先级是高于低优先级的
使用高优先级的队列可以在源码中找到实例,创建一个高优先级队列然后queue work就行了
int __init watchdog_dev_init(void)
{
watchdog_wq = alloc_workqueue("watchdogd",
WQ_HIGHPRI | WQ_MEM_RECLAIM, 0);
……
}
queue_delayed_work(watchdog_wq, &wd_data->work, 0);4. schedule_work成功和失败对于kworker调度的影响
5. flush_work都做了什么事情
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/189672.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
