大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
前言
在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如最近的GoogLenet,VGG-19,Incepetion等模型。CNN史上的一个里程碑事件是ResNet模型的出现,ResNet可以训练出更深的CNN模型,从而实现更高的准确度。ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。今天我们要介绍的是 DenseNet(Densely connected convolutional networks) 模型,它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。本篇文章首先介绍DenseNet的原理以及网路架构,然后讲解DenseNet在Pytorch上的实现。
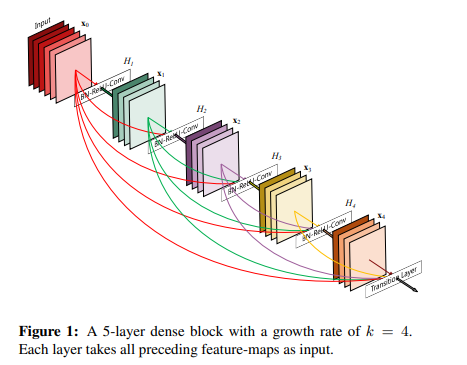

设计理念
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个 L L L 层的网络,DenseNet共包含 L ( L + 1 ) 2 \frac{L(L+1)}{2} 2L(L+1)个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
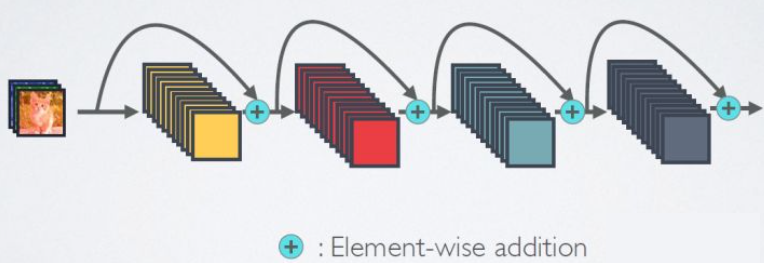
ResNet网络的短路连接机制(其中+代表的是元素级相加操作)
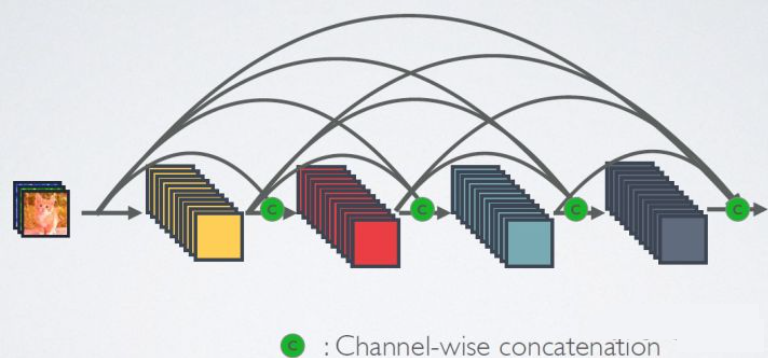
DenseNet网络的密集连接机制(其中c代表的是channel级连接操作)
如果用公式表示的话,传统的网络在 l l l层的输出为:
x l = H l ( x l − 1 ) x_l = H_l(x_{l-1}) xl=Hl(xl−1)
而对于ResNet,增加了来自上一层输入的identity函数:
x l = H l ( x l − 1 ) + x l − 1 x_l = H_l(x_{l-1})+x_{l-1} xl=Hl(xl−1)+xl−1
在DenseNet中,会连接前面所有层作为输入:
x l = H l ( [ x 0 , x 1 , . . . , x l − 1 ] ) x_l = H_l([x_0,x_1,…,x_{l-1}]) xl=Hl([x0,x1,...,xl−1])
其中,上面的 H l ( ⋅ ) H_l(·) Hl(⋅)代表是非线性转化函数(non-liear transformation),它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。注意这里 l l l层与 l − 1 l-1 l−1层之间可能实际上包含多个卷积层。
DenseNet的前向过程如图所示,可以更直观地理解其密集连接方式,比如 h 3 h_3 h3 的输入不仅包括来自 h 2 h_2 h2的 x 2 x_2 x2,还包括前面两层的 x 1 x_1 x1和 x 2 x_2 x2 ,它们是在channel维度上连接在一起的。
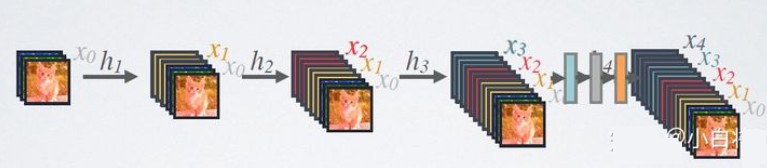
DenseNet的前向过程
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图4给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition连接在一起。

使用DenseBlock+Transition的DenseNet网络
网络结构
如前所示,DenseNet的网络结构主要由DenseBlock和Transition组成,如图所示。下面具体介绍网络的具体实现细节。

在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 H ( ⋅ ) H(·) H(⋅)采用的是BN+ReLU+3×3 Conv的结构,如图所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出 k k k个特征图,即得到的特征图的channel数为 k k k,或者说采用 k k k个卷积核。 k k k 在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的 k k k(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为 k 0 k_0 k0,那么 l l l层输入的channel数为 k 0 + k ( l − 1 ) k_0 + k(l-1) k0+k(l−1),因此随着层数增加,尽管 k k k 设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有 k k k个特征是自己独有的。
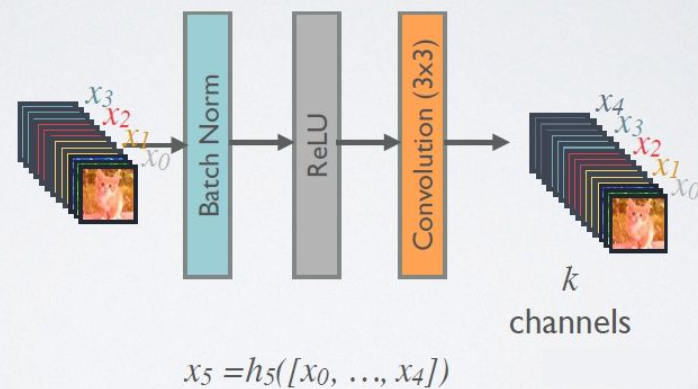
DenseBlock中的非线性转换结构
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1×1 Conv,如图所示,即BN+ReLU+1×1 Conv+BN+ReLU+3×3 Conv,称为DenseNet-B结构。其中1×1 Conv得到 4 k 4k 4k 个特征图它起到的作用是降低特征数量,从而提升计算效率。

使用bottleneck层的DenseBlock结构
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1×1的卷积和2×2的AvgPooling,结构为BN+ReLU+1×1 Conv+2×2 AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为 m m m ,Transition层可以产生 θ m θm θm个特征(通过卷积层),其中 θ ∈ ( 0 , 1 ] θ∈(0,1] θ∈(0,1] 是压缩系数(compression rate)。当 θ = 1 θ=1 θ=1 时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用 θ = 0.5 θ = 0.5 θ=0.5。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
DenseNet共在三个图像分类数据集(CIFAR,SVHN和ImageNet)上进行测试。对于前两个数据集,其输入图片大小为 32 × 32 32×32 32×32 ,所使用的DenseNet在进入第一个DenseBlock之前,首先进行进行一次3×3卷积(stride=1),卷积核数为16(对于DenseNet-BC为 2 k 2k 2k)。DenseNet共包含三个DenseBlock,各个模块的特征图大小分别为 32 × 32 32×32 32×32, 16 × 16 16×16 16×16和 8 × 8 8×8 8×8,每个DenseBlock里面的层数相同。最后的DenseBlock之后是一个global AvgPooling层,然后送入一个softmax分类器。注意,在DenseNet中,所有的3×3卷积均采用padding=1的方式以保证特征图大小维持不变。对于基本的DenseNet,使用如下三种网络配置: { L = 40 , k = 12 } \{L=40,k=12\} {
L=40,k=12} , { L = 100 , k = 12 } \{L=100,k=12\} {
L=100,k=12}, { L = 40 , k = 24 } \{L=40,k=24\} {
L=40,k=24}。而对于DenseNet-BC结构,使用如下三种网络配置: { L = 100 , k = 12 } \{L=100,k=12\} {
L=100,k=12} , { L = 250 , k = 24 } \{L=250,k=24\} {
L=250,k=24}, { L = 190 , k = 40 } \{L=190,k=40\} {
L=190,k=40} 。这里的 L L L 指的是网络总层数(网络深度),一般情况下,我们只把带有训练参数的层算入其中,而像Pooling这样的无参数层不纳入统计中,此外BN层尽管包含参数但是也不单独统计,而是可以计入它所附属的卷积层。对于普通的 L = 40 , k = 12 L=40,k=12 L=40,k=12网络,除去第一个卷积层、2个Transition中卷积层以及最后的Linear层,共剩余36层,均分到三个DenseBlock可知每个DenseBlock包含12层。其它的网络配置同样可以算出各个DenseBlock所含层数。
对于ImageNet数据集,图片输入大小为 224 × 224 224×224 224×224 ,网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7×7卷积层(卷积核数为 2 k 2k 2k ),然后是一个stride=2的3×3 MaxPooling层,后面才进入DenseBlock。ImageNet数据集所采用的网络配置如表1所示:

ImageNet数据集上所采用的DenseNet结构
实验结果及讨论
这里给出DenseNet在CIFAR-100和ImageNet数据集上与ResNet的对比结果,如下图所示。从图1中可以看到,只有0.8M的DenseNet-100性能已经超越ResNet-1001,并且后者参数大小为10.2M。而从图2中可以看出,同等参数大小时,DenseNet也优于ResNet网络。其它实验结果见原论文。

在CIFAR-100数据集上ResNet vs DenseNet
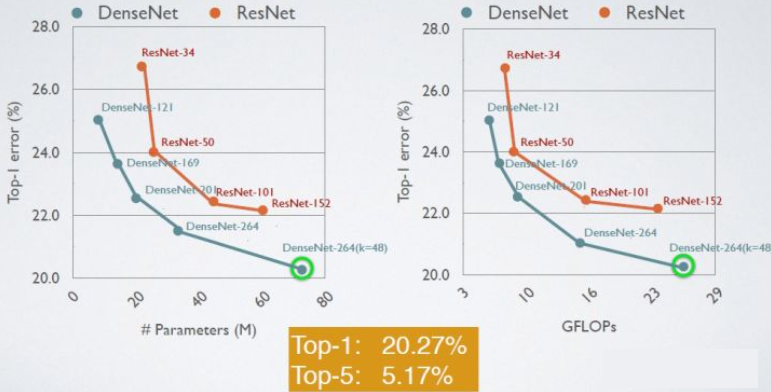
在ImageNet数据集上ResNet vs DenseNet
综合来看,DenseNet的优势主要体现在以下几个方面:
- 由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”;
- 参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
- 由于特征复用,最后的分类器使用了低级特征。
要注意的一点是,如果实现方式不当的话,DenseNet可能耗费很多GPU显存,一种高效的实现如图所示,更多细节可以见这篇论文Memory-Efficient Implementation of DenseNets。不过我们下面使用Pytorch框架可以自动实现这种优化。

DenseNet的更高效实现方式
使用Pytorch实现DenseNet
这里我们采用Pytorch框架来实现DenseNet,目前它已经支持Windows系统。对于DenseNet,Pytorch在torchvision.models模块里给出了官方实现,这个DenseNet版本是用于ImageNet数据集的DenseNet-BC模型,下面简单介绍实现过程。
首先实现DenseBlock中的内部结构,这里是BN+ReLU+1×1 Conv+BN+ReLU+3×3 Conv结构,最后也加入dropout层以用于训练过程。
class _DenseLayer(nn.Sequential):
"""Basic unit of DenseBlock (using bottleneck layer) """
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(num_input_features, bn_size*growth_rate,
kernel_size=1, stride=1, bias=False))
self.add_module("norm2", nn.BatchNorm2d(bn_size*growth_rate))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
据此,实现DenseBlock模块,内部是密集连接方式(输入特征数线性增长):
class _DenseBlock(nn.Sequential):
"""DenseBlock"""
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,
drop_rate)
self.add_module("denselayer%d" % (i+1,), layer)
此外,我们实现Transition层,它主要是一个卷积层和一个池化层:
class _Transition(nn.Sequential):
"""Transition layer between two adjacent DenseBlock"""
def __init__(self, num_input_feature, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_feature))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))
最后我们实现DenseNet网络:
class DenseNet(nn.Module):
"DenseNet-BC model"
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64,
bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
""" :param growth_rate: (int) number of filters used in DenseLayer, `k` in the paper :param block_config: (list of 4 ints) number of layers in each DenseBlock :param num_init_features: (int) number of filters in the first Conv2d :param bn_size: (int) the factor using in the bottleneck layer :param compression_rate: (float) the compression rate used in Transition Layer :param drop_rate: (float) the drop rate after each DenseLayer :param num_classes: (int) number of classes for classification """
super(DenseNet, self).__init__()
# first Conv2d
self.features = nn.Sequential(OrderedDict([
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(3, stride=2, padding=1))
]))
# DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features += num_layers*growth_rate
if i != len(block_config) - 1:
transition = _Transition(num_features, int(num_features*compression_rate))
self.features.add_module("transition%d" % (i + 1), transition)
num_features = int(num_features * compression_rate)
# final bn+ReLU
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
self.features.add_module("relu5", nn.ReLU(inplace=True))
# classification layer
self.classifier = nn.Linear(num_features, num_classes)
# params initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
选择不同网络参数,就可以实现不同深度的DenseNet,这里实现DenseNet-121网络,而且Pytorch提供了预训练好的网络参数:
def densenet121(pretrained=False, **kwargs):
"""DenseNet121"""
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 24, 16),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet121'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
下面,我们使用预训练好的网络对图片进行测试,这里给出top-5预测值:
densenet = densenet121(pretrained=True)
densenet.eval()
img = Image.open("./images/cat.jpg")
trans_ops = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
images = trans_ops(img).view(-1, 3, 224, 224)
outputs = densenet(images)
_, predictions = outputs.topk(5, dim=1)
labels = list(map(lambda s: s.strip(), open("./data/imagenet/synset_words.txt").readlines()))
for idx in predictions.numpy()[0]:
print("Predicted labels:", labels[idx])

给出的预测结果为:
Predicted labels: n02123159 tiger cat
Predicted labels: n02123045 tabby, tabby cat
Predicted labels: n02127052 lynx, catamount
Predicted labels: n02124075 Egyptian cat
Predicted labels: n02119789 kit fox, Vulpes macrotis
注:完整代码见xiaohu2015/DeepLearning_tutorials
小结
这篇文章详细介绍了DenseNet的设计理念以及网络结构,并给出了如何使用Pytorch来实现。值得注意的是,DenseNet在ResNet基础上前进了一步,相比ResNet具有一定的优势,但是其却并没有像ResNet那么出名(吃显存问题?深度不能太大?)。期待未来有更好的网络模型出现吧!
参考文献
本文是搬运,作者写的太好了。DenseNet:比ResNet更优的CNN模型。推荐一波,之前ResNet也是看的他的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/188822.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
