大家好,又见面了,我是你们的朋友全栈君。
1.感知机与多层感知机
1.1 门
与门:实现逻辑“乘”运算 y=AB
与门真值表
| A | B | y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
非门:实现逻辑非,一对一输出
非门真值表
| A | y |
|---|---|
| 0 | 1 |
| 1 | 0 |
或门:实现逻辑“和”运算 y=A+B
或门真值表
| A | B | y |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 1 |
与非门:先与后非
与非门真值表
| A | B | y |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
1.2 感知机
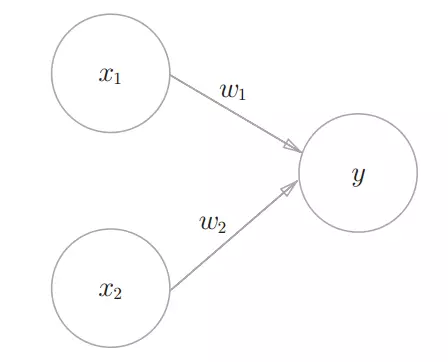

感知机接受多个输入信号,输出一个信号,x1,x2是输入信号,y是输出信号,w1,w2是权重,输出y=x1w1+x2w2,当这个总和超过了某个界限值时,才会输出1。这也被称为“神经元被激活”。这里将这个界限值称为阈值,用θ表示
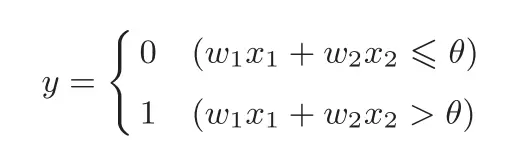
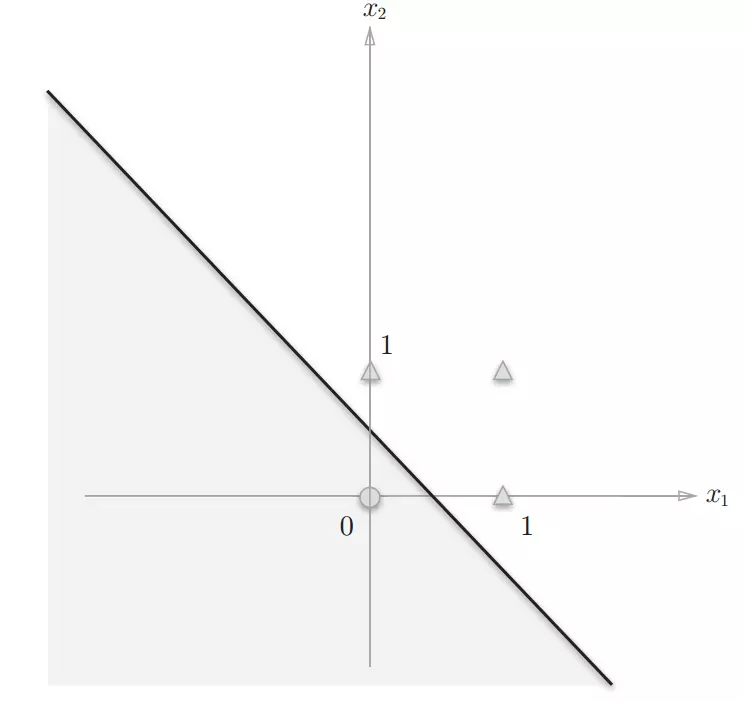
感知机的局限性在于它只能表示由一条直分割的空间,异或门的曲线无法用感知机表示
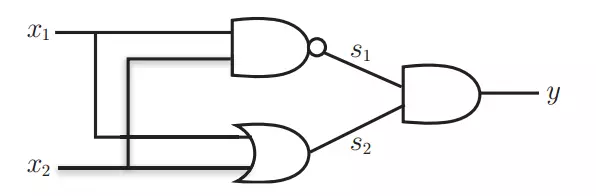
异或门无法用直线分割,可以用曲线分割开
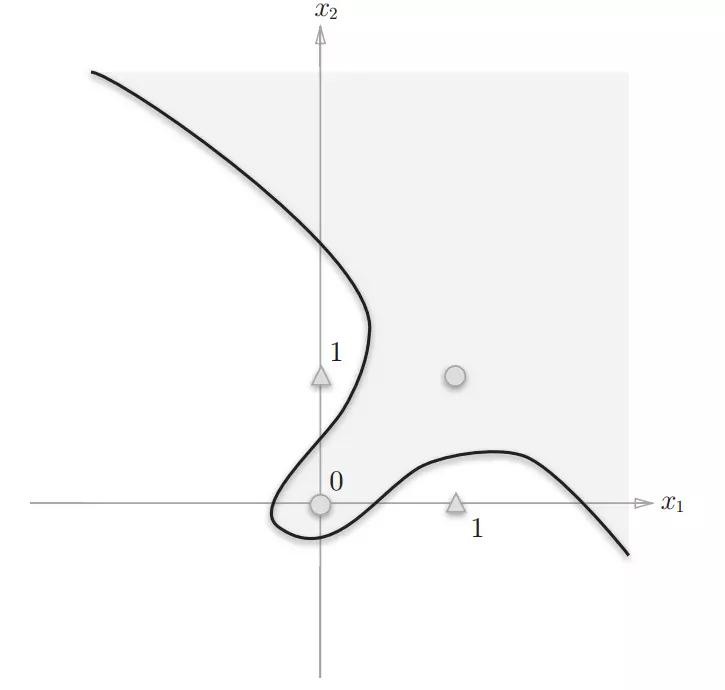
数字电路中异或门可以通过
组合与门,与非门,或门实现异或门,组合真值表如下:
| x1 | x2 | s1(x1,x2与非门) | s2(x1,x2或门) | y(s1,s2与门) |
|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 |
| 1 | 1 | 0 | 1 | 0 |
下面用感知机的方法表示:
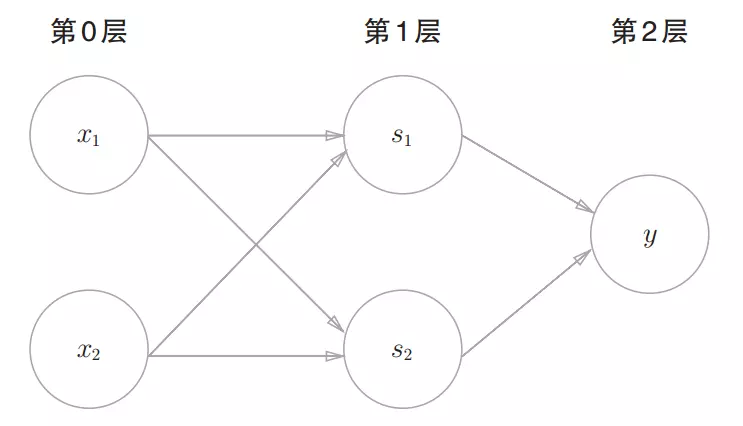
上图中有s1和s2 两层感知机,叠加了多层的感知机也称为多层感知机。
常见的多层感知机(神经网络)的图:
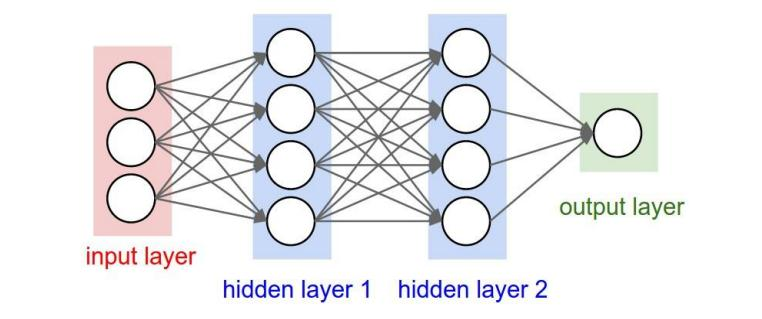
单层感知机与多层感知机的区别:
<1>. 多层感知机在输入层与输出层之间多了一层隐藏层
<2>. 每层神经元与下一层神经元全互连
<3>. 隐藏层也有激活功能的神经元
2. Tensorflow实现多层感知机
tensorflow训练神经网络的4个步骤
step1:定义计算公式
隐藏层权重初始化,激活函数的选择
step2:定义损失函数 及选择优化器
损失函数有平方误差,交叉信息熵等,选择优化器,学习率
step3:训练模型
训练轮数,batch的数量,batch的大小,dropout的keep_prob的设置
step4:用测试集对模型进行准确率评测
如果有keep_prob则设为1即用全部特征进行预测,用tf.equal判断预测正确的样本,tf.cast将[True,False]转为0,1,tf.reduce_mean计算均值
实现代码:
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist= input_data.read_data_sets("MNIST_DATA/",one_hot=True)
sess = tf.InteractiveSession()
''' 下面给隐含层的参数设置Variable进行初始化 in_units:输入节点数 h1_units:隐含层的输出节点数(设为300) W1,b1:隐含层权重与偏置 将权重初始化为截断的正太分布,标准差为0.1(偏置全为0),tf.truncated_normal([in_units,h1_units],stddev=0.1) 因为模型使用的激活函数是ReLU,所以需要使用正态分布给参数加一点噪声来打破完全对称,并且避免0梯度 W2,b2:输出层权重和偏置(全部设为0) '''
in_units = 784
h1_units =300
W1 = tf.Variable(tf.truncated_normal([in_units,h1_units],stddev=0.1))
b1 = tf.Variable(tf.zeros([h1_units]))
W2 = tf.Variable(tf.zeros([h1_units,10]))
b2 = tf.Variable(tf.zeros([10]))
''' 定义输入x的placeholder,在训练和预测时,Dropout的比率Keep_prob是不一样的,通常在训练时小于1,而预测时等于1,所以把Dropout的比率作为计算图的输入,并定义为一个placeholder '''
x = tf.placeholder(tf.float32,[None,in_units])
keep_prob = tf.placeholder(tf.float32)
''' 定义模型结构: step1:首先需要一个隐含层,命名为hidden1,可以通过tf.nn.relu(tf.matmul(x,w1) + b1)实现一个激活函数为Relu的隐含层, 这个隐含层的计算公式就是y=relu(W1X+b1) step2:用tf.nn.dropout实现dropout功能,随机将一部分节点设为0, keep_prob:保留数据,即不设为0的比例,训练时小于1,可以制造随机性,预测时等于1,使用全部特征来预测样本 '''
hidden1 = tf.nn.relu(tf.matmul(x,W1) + b1)
hidden1_drop = tf.nn.dropout(hidden1,keep_prob)
y = tf.nn.softmax(tf.matmul(hidden1_drop,W2) + b2)
''' 定义损失函数和选择优化器 '''
y_=tf.placeholder(tf.float32,[None,10]) #10维,是哪个数字对应的索引就是1
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),reduction_indices=[1]))
train_step = tf.train.AdagradOptimizer(0.3).minimize(cross_entropy)
''' 开始训练 共300个batch,每个batch包含100个样本,训练时保留75%的节点 '''
tf.global_variables_initializer().run()
for i in range(300):
batch_xs,batch_ys=mnist.train.next_batch(100)
train_step.run({
x:batch_xs,y_:batch_ys,keep_prob:0.75})
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1)) #tf.argmax(y,1) y矩阵的每一行最大值的索引
accuracy= tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
print(accuracy.eval({
x:mnist.test.images,y_:mnist.test.labels,keep_prob:1.0}))
'''
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128186.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
