大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
- 在同一个工程项目中,全局变量可通用,如果要A类要用的B类的全局变量num,则这样声明,extern int num,然后就可以使用了,调用其他文件函数也是extern void func();
- #define MAX 10, 这个常量,可以使用在arr(MAX),#undef MAX则会取消这个宏
- enum Season{ };注意大括号后面的分号不可少,各成员用逗号隔开
- 普通局部变量没有初始化的话,默认赋值为随机值
- 保存字符串三种方式:一.char string[20]=”hello” 二.char* str=”hello” 三.char* str=(char*)malloc(10*sizeof(char)),第二种不常用
- 第三种字符串初始化的,可以用strcpy,scanf来初始化
- 一个函数中,定义static int num =100,这个局部静态变量num只会初始化一次,也就是不管你调用它多少次,都只会在第一次调用时赋值100,后面在调用的时候,num值是多少就是多少,不会重新赋值为100的
- 函数的返回值前用static修饰的函数为内部函数,它也是只能在当前的.c文件的使用
- char arr[]=”abc”,这个数组表示字符串,其实这个数组有4个元素,最后一个元素是\0,它表示的是字符串的结束标记
- “c:\test\32” 这里面的\32也是个转义,32是个八进制数,转化为十进制就是26,然后26对应的ASII码值的为右剪头,同理,\x61,代表是十六进制61,转化十进制就为97
- 以0开头为8进制,045,021,以0b开头为2进制,0b11101101。以0x开头为16进制,0x21458adf。%#o\n代表输出的八进制数带有前缀0,%#x\n代表输出十六进制数带有前缀0
- 输出地址的方式:%p。输出long类型的:%ld,输出double类型的:%lf,
- “%05d /n”代表输出不够时前面补0,d后面还有空格,所以它输出6个字符,%-5d/n”代表输出左对齐,%.2f/n”输出保留小数两位
- -5的二进制为11111011,过程为:原码10000101,反码11111010,补码11111011
- %lu 为 32 位无符号整数,
- 整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。
- const 定义的是变量不是常量,只是这个变量的值不允许改变是常变量!带有类型。编译运行的时候起作用存在类型检查。编译器通常不为普通const常量分配存储空间,而是将它们保存在符号表中,这使得它成为一个编译期间的常量,没有了存储与读内存的操作,使得它的效率也很高。
-
#definde N 2+3 double a; a = (float)N/(float)2; 这段代码最后输出3.5而不是2.5,因为#define是宏定义,它定义的是不带类型的常数,只进行简单的字符替换。在预编译的时候起作用,不存在类型检查,所以它运行的是2+3/2,结果是3.5,而不是运行5/2,想要是2.5,则应该定义#define N (2+3)
- static定义的变量只能在当前 c 程序文件中使用,在另一个 c 代码里面 , 即使使用 extern 关键词也不能访问这个static变量。
- int a[]={1,2}, a、(a+1)代表的是地址, (a+1) 就代表的是 a[0+1] 的地址。还有,数组名a一般都是代表首个元素的地址,但是有两种例外,第一,sizeof(a)这里的数组名代表整个数组,而不首元素,第二,&a,这里的数组名代表的是整个数组,取的也是整个数组的地址
- 注意,int* p=&a,&a+1和p+1是不一样的,前者会走一个数组的长度,后者只走了一个元素的长度,同时,printf(*p和*a)都可以打印出首元素,直接p[2]就可以取值
- 同样,int (*p)[5]=&a,*p+1和p+1也是不一样的,前者是走了一个元素长度,后者会走一个数组的长度,也就是此时p代表整个数组地址,而*p只是代表首个元素的地址
- 指针是一个变量,可以进行数值运算。数组名不是变量,不可以进行数值运算。
- struct Book b1{char name[ 20] int num };可以写b1.num=12,不能直接b1.name=”xx”,要写成strcpy(b1.name,”xxx”),因为num是变量,而name是数组名,同时要引入[string.h],
- struct Book* p=&b1,则可以printf(“%s”,p->name),也可以printf(“%s”,(*p).name)
- struct Stu{char name[ 20] int num} s1,s2,s3;这个是创建了三个Stu对象,而且还是全局变量,此时给这三个初始化时,在后面={“a”,12,”b”,13,”c”,14}
- typedef struct Student{char name[ 20] int num}Stu;就是给这个类取别名,以后可以直接Stu来创建对象
- int num =getchar();这个方法相当于scanner in,而且一次只读一个字符,putchar(num)相当于system.out, (num=getchar()) !=EOF,此时不能直接输入EOF,因为它会一个个字母来认,按ctl+z可以相当于输入EOF
- scanf(“%d”,&a);注意它里面人传的是地址
- scanf后面如果跟着getchar(),会出现getchar()获得10的情况,那是因为,执行scanf()时,假设你输入123后,要按回车,scanf才会收到且收到的123,而输入缓冲区其实是123\n,所以123被读走了,后面getchar()看到缓冲区还有\n就直接读走了,就不等待后面的输入了,此时可以在两个中间多加个getchar()把\n读走,所以可以用while((ch=getchar())!=EOF)
- scanf()只会读取空格前面的字符,如果想读取空格后面的,可以用gets(xxx),它代表读取一行
- system(“cls”);执行清空屏幕,是<stdlib.h>里有,Sleep(10)是<windows.h>里的
- 比较两个字符串是否相等,不要用==,应该用strcmp(“xxx”,”xxx”),相等的话返回0
- 变量最好定义在代码的最开始位置,不然可能会报错
- strlen()参数放的是地址,碰到“\0”时才算数完个数,不然就会是个随机数,char arr[]=”adsf”,strlen(arr)会报错,因为里面是一个数组指针,也就是char (*p)[5]=&arr,而strlen(const char*)不匹配,返回的是无符号整数
- typedef int INT,给int这个关键字重新起名,后面用INT就代表int,比如typedef long time_t,这个time_t其实就是long类型,
- srand((unsigned int)time(NULL))和rand()要一起使用,不然生成的随机数有问题,有srand(参数),里面参数是time(time_t *time),代表生成当前时间毫秒数,它是不停在变化,而srand(参数)它就是要一个会随时变化的参数,所以用time(),srand(xx)就是随机数生成器,只要调用一次就行,所以可以放在循环外面
- printf();
goto stand;
rand();
stand:
printf(); 上面代码是goto的用法,一般不用,在嵌套for循环里面的最后一个for循环可以用,用来跳到第一for循环,相当于JAVA中的break某个for循环 - char arr1[]=”bit”; char arr2[]=”#####”; strcpy(arr2,arr1);printf(“%s”,arr2);这代码运行时会把源字符串的所有字符包括”\0″也复制到arr2里去,arr2会变成”bit\0###”,但是在输出的时候只输出”bit”,那是因为printf遇到”\0″后就代表字符串已经结束,就不会打印后面的内容了
- strncpy(dest,src,n)这个是复制n个字节到dest中,而且它不会复制’/0′,如果n大于src的长度,那么后面用0补满
-
char str[] = "almost every programmer should know memset!"; memset (str,'-',6); scanr("%s",str); 结果会输出----- every programmer should know memset! - 函数swap(arr[]),当把arr这个数组传入swap函数时,不能用sizeof(arr)/sizeof(arr[0])这个来计算数组长度,因为此时的实参arr其实是代表arr[0]的地址,所以sizeof(arr)里的arr相当于一个指针,其大小要么是4KB,要么是8KB
- 引用自己定义的库用的是#include “add.h”,引用非自定义的库才是<>
- 函数的声明一定要放在头文件里
- 在自定义的头文件里,比如add.h,开关加上#ifndef __ADD_H__ #define __ADD_H__这两行,在末尾在加上#endif ,这个为了避免同一个项目中反复引入同一个头文件,ifnodef意思就是如果这个头文件未被定义,如果其它人已经引入这个.h,那么这个ifnodef会是假,就不会引入了,同时,#pragma once跟它的效果一样
- printf(“%d”,num),如果在这句代码前一行加上#ifdef DEBUG,后一行加上#endif,代表如果宏定义了DEBUG,那么这句代码就会编译,否则就不编译,也就是可以选择性编译
- #if defined(DEBUG) 代码xxxx #endif ,这个跟上面一样,反过来就是#if !defined(DEBUG)
- 还有#if 表达式或数字 #elif 表达式或数字 #else 表达式或数字 #endif 也是一样选择性编译,表达式或数字不为0的,就编译,if的成立,elif和else的就直接不会编译,一般用于多行的注释


- sizeof()和 strlen()区别,在同是计算“abc”时,前者是4,后者是3,因为前者把”\0″也算,后者是到”\0″就打住
- 冒泡排序:就是相邻的两两比较大小,到最后那个数最大或最小,如果在第一轮并未发现交换,说明它就是有序的了,那么后面几轮就无需比较了,可以定个flag=1,如果第一轮有交换了,就flag=0,然后第一轮结束后,如果flag==1,直接break,这样可以省时
- a^b^b,这里的^是代表异或,这个表达式结果为a
- sizeof(s=(a+5)),注意,sizeof()里面不会进行真实的运算,也就是执行完后,原来的s是多少就是多少
- int arr[5]={0}; int* p=&arr[0]; *p++=0;最后一句代码意思是,先把p地址指向的内容改成0,也就是arr[0]=0,然后在p++,地址就指向了arr[1]了,而*–p=0;则是先 – -p,也就是指针向前挪一步,然后赋值0
- 规定,一个指针指向某个数组时,它可以与数组最后一个元素的后一个指针进行比较,但是不能与第一个元素的前一个指针进行比较
- int i= -1, i > sizeof(i)这个条件为真,因为sizeof()返回的是无符号数,而负数要和它比较,会把负数转成无符号数,而-1转成无符号数是个很大数,所以为真
- b=++c,c++,++a,a++;这个表达式中,因为赋值=的优先级大于逗号,所以为先算b=++c,然后在算后面几个
- 计算一个二进制有几个1,可以把>>1然后在&1,如果结果是1,就count++,然后继续>>
-
while(n){ n=n&(n-1); count++; }//这个是另一种算有几个1的方法 - for(int i =0,i<10,i++)这个是C++的语法,C的语法应该是int i=0; for(i =0,i<10,i++)
-
//这里形参加const意思是*src不能改变,如果while(*src++=*dec++)就会报错,防止你复制 //的方向反了 char* my_strcpy(char* dec, const char* src){ char* ret =dest; assert(dec != NULL);//如果成立,会抛异常,要引入assert.h头文件 assert(src != NULL); while(*dec++=*src++){ ; } return ret; }//模拟strcpy() - const int num = 10;
const int*p=&num // int* const p = &num
放在指针变量的*左边时,修饰的是*p,也就是说:不能通过来改变*p(num)的值
放在指针变量的*右边时,修饰的是指针变量p本身,p不能被改变了 - 为什么内存里存的都是二进制的补码?因为CPU里面只有加法器,而我们加减法都要,比如1-1在CPU是算1+(-1),如果直接原码来算,会是-2.如果是补码算,刚好是0
- char a=-1;这个表达式,右边-1默认是4个字节类型,所以原码会是100…0001,补码是111..1111,因为char类型的一个字节,所以会截取一个字节,即1111,此时在printf(“%d”,a),因为要以%d打印,所以会把1111转换成int类型,而且char类型默认为有符号,最高位为符号位,其他28位跟最高位一样,补成1111…1111,就打印出-1了,如果char a =1,一样的这个1默认也是4个字节。
- 如果是unsigned char a=-1,那么在printf时,最高位不是符号位,就会补成0000…1111了
- 10000000就是-128,有符号char范围是-128~ 127,所以char 128和char -128输出无符号数结果是一样的,因为128=127+1,char类型最大值是127,+1就是-128了
- char数组里面要是有0,其实就相当于有’0′,因为char放的是ACII码值,而‘\0’的ACII码值就是0
- float在内存中存储公式,(-1)^s*M*2^E,正数时,s为0,负数s为1,1=<M=<2,E就是二进制高位的那个次幂,5用float表示,0101,(-1)^0*1.01*2^2,-5用float表示,0101,(-1)^1*1.01*2^2,
- 对于32位浮点数,最高位为s,接着8位为指数E,最后23位为M,对于64位浮点数,最高位为s,接着11位为指数E,最后52位为M,
- pow(a,b)代表的是a的b次方
- float a=5.5,这个就是101.1,101后面的0.1代表2^(-1),换算过去就是0.5,如果是0.01,代表2^(-2),依此类推,所以最后是(-1)^0*1.011*2^2,在内存中存法:E会加上127,M会去掉小数点前整数1,最后就是0100 0000 1011 0000 0000
- char* p=”afdsfds”;这里的p存的是首字母a的地址,而不是这个字符串,这里的字符串存放在常量区,所以*p=”v”是报错的,因为p指向的是字符常量,不可更改,p=”guess”是可以的,因为它是p重新指向另一个字符串,”printf(“%s\n”,p)可以打印出这个字符
- char* p1=”sdfsdfsd”; char* p2=”sdfsdfsd”; if(p1==p2)这个if条件为真,这里的p1其实是首字符s的地址o
- char * name[3]={“dsf”,”sdfsd”,”rtert”}遍历这个指针数组会得到三个字符串
- int (*p)[10]=&arr,这里的p就是数组指针
- int (*arr[10])[5],这个先拆成arr[10]和int (* )[5],把arr[10]当成一个整体p,那么就和int (*p )[5]一样了,arr[10]就是一个数组指针,这个数组有5个int元素,所以是arr是一个10个元素的数组,每个元素是一个数组指针,每个元素指向的数组有5个int元素
- int arr[3][5]={0}; void test(int (*arr)[5]){}; 调用时就test(arr);
- int arr[3][5],这里arr代表首元素地址,也就是第一行的地址,*arr就是解引用第一行,也就是拿到第一行的首元素地址,*arr+1是第一行第二个元素的地址,如果$(arr[0])这个第一行数组取地址,那么它加1代表的是下一行数组
- void test(int** p){}; int* arr[10]; 可以这样调用test(arr),
- int add(int x,int y){}; 如何这个函数指针,int (*p)(int,int)=add,调用的时候就是(*p)(2,3),也可以直接(p)(2,3),也就是*可有可无
- int (*p)[10]这个数组指针,p是变量名,去掉它后int (*)[10]就是类型,其他的也可以用这个方式来确定类型,比如(*(void (*)())0)(),这里的void (*)()就可看成void (*p)()去掉变量名p之后,它就表示它是函数指针类型,然后把0强转成这个类型,0就变成一个地址了,(*(void (*)())0)()就是(*地址)(),这个就是通过函数指针来调用函数了
- void(* singal(int,void(*)(int)) )(int)这句代码这么来理解,函数名为signal,两个参数Int和函数指针,返回类型为void(*)(int)也就是说返回类型也是函数指针,按理来说,这个应该写成void(*)(int) singal(int,void(*)(int)),比如int add(int,int),但是返回类型是函数指针时,必须那样写,此时可以这样,typedef void (*fun) (int) ,注意这里不要写成typedef void(*)(int) fun,然后在写 fun singal(int,fun)
- int (*parr[4])(int,int)={Add,Sub,Div,Mul}这个是函数指针数组,当几个函数的返回类型和参数都一样时,此时就可以用函数指针数组,减少代码量

- 函数指针多数是在将一个函数作用参数传给另一个函数时使用,这个函数就叫回调函数
- 大多数情况下,指针数组都是用来存多个字符串
- 数组指针常用来给二维数组传参
- 一维数组传参,void fun(int *p), 二维数组传参,void fun (int (*p)[4]),指针数组传参,void fun(char **p)

- 上面这代码,没注释前结果会是p=null,注释后才会正常输出hello world
- int (*parr[4])(int,int); int (*(*pparr)[4])(int,int)=&parr,这个就是函数指针数组的指针
- void * 可以接收任意类型的地址,但是void类型指针不能进行解应用,也不能进行+-运算
- 比较两个string,用strcmp(str1,str2),也是返回-1,0,1,strcat(str1,str2)这个函数是把str2追加到str1后面,strcat(str1,str1)会报错,要用strncat(str1,str1), 追加的时候要保证str1这个数组空间够大,比如char str1[]=”asd”,此时str1的空间大小为3,所以追加的时候最char str1[20]=”asd”这样来设计。 strstr(str1,str2)这个函数是找str2是否是str1的子串
- strcmp是把两个字符串一个一个字符对比,只要某一个字符比较出来大小就返回
- strchr(p,num),在字符串中查找是否有ASCII码值为num的字符且是第一个的,strrchr(p,num)是找出最后一个ASCII码为num的字符,
- 库函数qsort(arr_Point,arr_length,per_element_size,int (*cmp)(const void *c1,const void* c2)).使用时,我先自己写个相应的cmp()函数
- 任何类型的指针都可以给void*类型指针赋值
- 当某个函数参数可能传入各种类型时,此时这个参数可以定义为void *p类型,然后在调用时,比如传入int* p,在函数内部写代码时强转(int*)p,
- sizeof(某某地址)的结果都是4或者8,而且sizeof()里面的参数不会进行真实的运算,比如int a[3][4],sizeof(a[3])时,虽然看起来像空指针,但是它的结果还是16,就因为它里面没有实际运算
- int a[3][2]={(0,1)(2,3)(4,5)},这个涉及逗号表达式,只取最后一个逗号后面的数,也就是分别是1,3,5,实际这个二维数组1,3,5后面三个元素默认为0,对于*(a+1)这样理解,a+1是第二行的地址,在解应用就是拿到第二行数组,相当于a[1],而a[1]是数组名,所以它代表的是第二行数组的首元素的地址,故*(a+1)也代表的是第二行数组的首元素的地址
- 两个地址相减,比如000c-0008,结果看起来是4,其实不是,结果还是除以这个类型的大小,比如int大小是4,最后结果为1才是对的
- int *p=&arr,后面的p[-1]相当于*(p-1)
- char str[]=”hello bit”, char* str=”hello bit”,前者是创建数组,不是字符常量,后者才是常量,所以创建两个一样的前者,比值是不等的,创建两个一样的后者 则相等

- 上面的代码,想要输出hello kitty,就得改成void fun (char **p),然后调用时fun(&p)
- unsign int x=3,unsign int y=6,此时x-y=-3,这个-3是大于0的,就因为x和y是无符号整数,
- int x=-8,unsign int y=7,此时x+y>0为真,因为两数相加,有一个是无符号数,两个都会转成无符号数后在相加,而-8转成无符号数是很大的数字
- while(*dest++ =* src++){ ; } 这段代码先执行*dest =* src,然后在dest++和 src++,同时判断dest是否等于0,不为0就继续循环
- if(“afds” ==”lkjfg”)注意这里的字符串比较的是两个首字母的地址
- char * ret=NULL,;char* p=”@.”;for(ret=strtok(arr,p);ret!=NULL;ret=strtok(NULL,p),这个是strtok的用法
- strerror(数字),这个函数的作用是把错误码翻译出来,比如strerror(0)表示no error,通常这样使用,strerror(errorno),这个参数是errorno.h里面的,出错的时候,会自动给errorno赋值,比如FILE* pf=fopen(“test.txt”,”rw”),这个函数是打开某个文件,如果返回空指针,就是打开失败,相应的就会给errorno传一个错误码,”wb”表示以二进制形式写入,fclose(pf),r+,w+代表以可读可写来打开文件
- fclose();成功返回0,失败返回EOF
- perror(“hehe”)这个和strerror()相比更简单,直接返回hehe:错误码
- a追加
- fwrite(@Stu,sizeof(Stu),1,pf)往pf文件里写入几个字节,写1次,fread(@num,4,1,pf)
- fread()返回的是读取到块数,不足一块的不算。读到2点几块,就返回2
- 在使用fwrite之后fread时,注意偏移量在在文末,会导致啥也没读到,可以用rewind(pf)让指针回到最开始的位置
- memcpy(arr1,arr2,需要拷贝的字节大小),所有在内存的里的都可以拷贝,针对同一数组内的重叠拷贝,可以用memmove(arr1+2,arr1+4,20)
- memcmp(arr1,arr2,8)这个函数是两个数组元素一个个字节比较,参数8是要比较的字节大小
- memset(arr,1,10),这个函数是把arr数组的元素更改10个字节,每个字节改成1
- 结构体所占内存大小计算:第一个成员变量在内存的位置就是结构体的初始位置,第二个成员变量以及后面的变量的内存位置由对齐数来决定,而对齐数是由编译器默认的大小和成员变量 的大小二者选其中小的那一个,比如VS编译器默认是8,int类型变量大小是4,那么这个变量的对齐数就是4,整个结构体的大小应该是成员变量最大对齐数的整数倍。
- 比如一个结构体有三个成员变量,char name,int age, char add,那么这个结构体的大小计算过程:第一个char占了一个字节,第二个int对齐数4,所以其内存位置从第4个字节开始算,第一二成员变量之间空出了三个字节的内存,第三个char就占一个字节,然后整个结构体要是最大对齐数的整数倍,也就是12,所以这个结构体的大小是1+3+4+1=9=4*3=12
- 如果结构体struct People 里的成员变量是个结构体struct Stu s,那么这个变量s要对齐到其最大对齐数的整数倍位置上
- 结构体指针变量要在内存里开辟空间后才能使用,比如pstu=(struct stu*)malloc(sizeof(struct stu))
- 在代码前加上#pragma pack(4),就能把编译器的默认对齐数改成4,在代码后面加上#pragma pack()则会取消更改默认对齐数
- 联合体,Union的大小为最大成员变量的大小,如果最大成员的大小不是最大对齐数的整数倍,就把最大成员补齐到最大对齐数的整数倍
- 共用体起作用的成员是最后一次存放的成员,如果一个新成员存入进去就会覆盖到原来的值,只要初始化第一个成员就行
- offsetof(struct s,name)这个返回name这个成员变量的偏移量,它不是函数,是宏
- init(struct Stu s)和init(struct Stu* ps)这两种传参方式,第二种好点,因为第一种传的参数所占内存大,第二种因为传的是地址,所以才占4个字节或者8个字节
//这是位段,跟结构体很像,只是它里面的变量一般是int,unsigned int,signed int,char, //而且变量的类型要一致 struct S{ int a:2; //后面的数字表示变量占的内存,单位是比特位 int b:5; int c:10; int d:30; }; //上面位段S占的内存大小为8 Byte,位段一般4字节或1字节的开辟内存空间,因为是int类型,所以就4个字节开辟,也就是32位,而S总共是47位,所以要8个字节 //如果加上int e:0; int f:3;多出两个成员,e这个成员存在的意义就是让下一个位段f从另一个存储单元开始 - 不能对位段成员取地址,也不能跨单元字节存储,
- 动态内存分配就是在堆区开辟空间,有malloc,free,calloc,realloc
- int* p=(int*)malloc(10*sizeof(int))申请10个整形内存,记得检查返回值,用完free(p)释放内存,并且p=NULL,一般用memset初始化
- char* str=(char*)malloc(10*sizeof(char)),后面可用str[0]这样来赋值,如果此时str=”hello”,相当于str保存了一个字符常量的首地址,为它动态开辟的内存就找不到了,也就泄露了
- free(p),只能free动态内存,如果中间出现了p++,那么free(p)就会出问题,因为free()需要释放完整的动态内存,p++后,p这个动态内存已经不完整了,也就是p变化了就free不了了
- int* p=(int*)calloc(10,sizeof(int)),申请10个整形内存,同时初始化每个内存为0
- realloc(p,40)是调整动态内存空间的大小,调整p内存大小到40,此时不要p=realloc(),最好重新定义int* p2=realloc(),因为追加的时候可能原内存后面空间不够,会重新开辟一个新的空间,确认开辟的不是NULL后,重新把值赋给p
- fgetc(pf), fputc(‘a’,pf), fgets(buf,1024,pf), fputs(buf,pf), fscanf(pf,”%d%f%s”,&(Stu.age),&(Stu.scor),&(Stu.arr)), fprintf(pf,”%d%f%s”,Stu.age,Stu.score,Stu.arr), sscanf(buf,”%d%f%s”,&(Stu.age),&(Stu.score),&(Stu.arr)), sprintf

- 上面代码分别输出5678,1234,agcd
- fgets碰到换行府(同时也会把它读进去)或者文末时停止读取,或者读取size-1个字节(因为最后要加\0,所以是size-1)停止,读取完毕后会在末尾加上\0作为字符串的结尾
- fgets(buf,1024,stdin),fputs(buf,stdout)两个相当于gets(buf)和puts(buf)
- fgetc()返回EOF时,fgets()返回NULL时代表文件读取结束,fread()返回的个数比实际要读的个数小,那么就代表读取结束,而fgetc()取失败结束t和到文件末尾结束都会返回EOF
- stdin标准输入,如键盘输入,stdout标准输出,如控制台,int ch=fgetc(stdin),fputc(ch,stdout),这两个
- stdin,stdout,stderr这三个指针是C语言中自带,直接使用,无需定义
-

- 程序默认打开的三个流,stdin,stdout,stderr,都是FILE*类型
- fseek(pf,2,SEEK_CUR)比当前文件指针位置偏移2个字节读取,SEEK_END从文末位置,SEEK_SET从文件起始位置,用于二进制文件
- ftell(pf)文件当前指针位置相对于文件起始位置的偏移量,rewind(pf)是让文件指针回到起始位置,
- feof()判断文件读取是因为读取失败结束的,还是到文件末尾结束的,ferror(pf)代表是否出现读取错误
- test.c–>test.obj(目标文件)这个过程为编译过程,test.obj->test.c为链接过程,而编译过程又分为预编译(gcc -E test.c后生成test.i),编译(gcc -S test.i后生成test.s,也就是把C代码编译成汇编代码),汇编(gcc -c test.s后生成test.o也就是把汇编代码编译成二进制指令)三个过程
- Linux环境里,gcc test.c为生成a.out,此时./a.out既可执行
- #define SQUARE(X) X*X SQUARE(5)的结果就会输出25
- #define PRINT(X) printf(“the value”#X”is %d\n”,X)这样定义宏,后面调用PRINT(X)时#X就会正常替换成它的值 了
- #define MALLOC(num,type) (type*)malloc(num*sizeof(type))这个是定义一个malloc宏
- printf(” %d\n”,Class##84)这个预编译后就会变成printf(” %d\n”,Class84),就是##会合并
- __FILE__是当前C文件的绝对路径,__LINE__是当前代码的行位置,__DATE__,__TIME__,
- 如果在代码中出现arr[SZ]这种而且SZ未定义的话,可以在命令行gcc test.c -D SZ=100定义SZ的值
- long类型在32位系统占4个字节,在64位系统占8个字节,float 4个字节,double 8个字节
- register int num,代表这个是寄存器变量,只能修饰字符型和整型的,不能修饰浮点型,同时它不能修饰数组变量,它修饰的变量不能取地址
- 函数名就是函数的首地址
- NULL本质上就是把0强转成void *类型
- int main(int argc,char* argv[])这是的argc是命令行传入的参数个数, argv是指针数组,用来保存命令行传入的每一个参数
- int atoi(const char* ptr) &long atol(const char* ptr)& double atof(const char* ptr),把数字型字符串转换成相应的int,long,double类型
- const int a=100,如果a是全局变量,则直接修改或者通过&a地址来修改都不行,但是如果a是局部变量,则直接修改不行,却可以通过int* p=&a;*p=100来修改,因为const修饰的全局变量是放在常量区,常量区的是不能被修改的,而局部变量是在栈区的
- 行缓冲:在标准io函数库中,往标准输出(屏幕)输出的时候是行缓冲,也就是缓冲区碰到换行符时才刷新缓冲区,如果不主动刷新缓冲区,是无法对文件进行读写操作
- 刷新缓冲区方法:一:加换行符 二:程度正常结束 三:用fflush()函数,比如标准输出fflush(stdout) 四:当缓冲区满的时候自动会刷新
- 默认行缓冲的大小为1024个字节
- printf(“xxx\n”)其实这个函数碰到换行符来会输出,所以有\n
- 全缓冲:往普通文件里进行读写
- EOF是在stdio.h中定义的符号常量,值为-1
- char buf[], char* buff都可以表示字符串,所以碰到函数参数为指针时,可以传buf
c++
- c语言中用的是stdio.h,而c++中用的是<iostream>
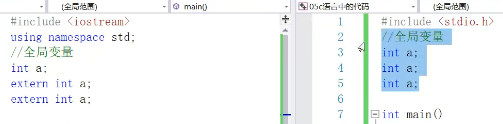
- 上面左边是c++,右边是c语言,右边编译没问题,是因为在c中那三个变量a,有一个是定义变量,另外两个是声明,c会自动给它加上extern,所以可以编通过,而在c++中,必须自己加上另外两个extern,不然编译不通过
- using namespace std相当于JAVA中的import某个类,叫做声明命令空间,之后才能用cout
- cout <<“hello world” <<endl
- ::num,这里的::代表的作用,单单::代表调用全局变量num,iA::num代表调用A作用域的num变量
- 命令空间namespace可以重名,比如可以有两个namespace B,同时B里面还可以嵌套C
- 在namespace A里面声明函数,在外部定义时要A::func().否则就和A里面所声明的函数无关
- namespace{ } 这个命令空间没有名字,就代表里面所有成员都被编译器加上static,也就是只能在当前c文件使用
- namespace A_name=A,这个是给A命令空间取个新名字A_name
- 如果想一直使用namespace A下面的num变量,可以使用前using A::num或者using namespace A,就可直接使用,否则需要每次A::num
- c++中使用结构体时,关键字struct可以不写,C中必须写
- c++中可以直接bool flag=true,C中则要引入stdbool.h头文件才能用
- a<b ? a : b 这个三目运算在c++中返回的是变量a,而在C中返回的是变量a的值,也就是常量,所以(a<b ? a : b )=100在c++中可以通过,在C中无法通过
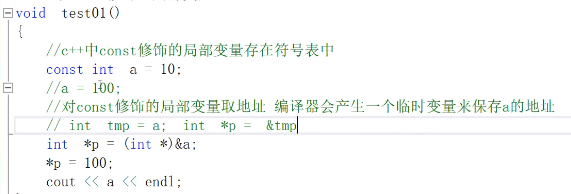
- 上面的输出结果还是10,&a是const int*类型,所以要强转成int*
- 上图中改成const int a=b,那么此时a不在符号表中,而在栈区,所以a结果会为100 ,const修饰的局部变量为自定义变量时也是存在栈区,比如struct stu
- c++中,在一个c文件中定义const int num =10,那么在另一个c文件中,extern const int num;会报错,因为C++里,const修饰的变量属于内部链接,此时改成extern const int num=10后在另一个C文件就可以使用了,而在C语言中没这个问题。
- int a=100, int & b=a,这个是引用,b是a的引用,而且之后b不能在给其他变量做引用了,相当于给a取个别名,
- int arr[5]={0,0,0}, int (&arra)[5]=arr,这个是给数组引用,第二种数组引用,typedef int ARR[5];ARR & arra=arr;第二种这样理解,int arr[5]拆分成int [5]和arr两部分,前者是变量arr的类型,后者是变量arr,那么typedef就相当于给int [5]这个类型取别名为ARR,就相当于arr此时的类型名为ARR
- 一个函数返回值为对象或者对象的引用,二者区别在于返回引用的话不用开辟空间
- 一个函数不能返回其局部变量的引用,就和不能返回局部变量的指针道理是一样的
- 函数引用:void swap(int &x,int &y);调用时候传入a,b,就可以实现a,b的swap,跟指针传参效果类似,void gem(int * &q),int* p=NULL;调用时传入p就行
- const int &b=a,这是一个常量引用,就是引用b指向的空间的内容不能被修改

- 引用:Type &ref=val,它在内部实现:Type* const ref=&val
- 在一个函数前加上inline,这个就是就是内联函数,它跟宏类似,比如inline int add(int a,int b),当add(5,3)*5时,它会先调用替换函数,并加上括号,最终(a+b)*5
- 宏函数在++a<b?++a:b这种情况时会出现替换缺陷,内联函数就不会

- 类的成员函数默认会在前面加上inline,也就是内联函数
- 设置函数的默认参数时,func (int a,int b),如果是func(int a=1,int b=1)或func(int a,int b=1),也就是一个参数设置成默认,那么其后面的参数也得默认,而且只能在声明函数或定义函数其中之一设置默认参数,不能同时
- 占位参数在重载后置++时候会用到
- 函数重载必须在同一个作用域
- #if __cplusplus extern “C” #endif
- C++定义类时,成员变量前在加上public: 因为类成员的默认权限是private:还有protected:是子类可以访问,在创建对象后,对象.成员属性是访问不了的 大括号后面在加上;
- 构造函数对应有个析构函数,~Person(){},它没有参数,不能重载,对象销毁之前会自动调用析构
- 无参构造时,Person p1,就行,不要加()
- Person p2(p1),这个创建对象会自动调用拷贝构造,Person(const Person &p),p1是旧对象,p2是就新对象,如果自定义了一个拷贝构造,就不会在调用默认的拷贝构造了
- 拷贝构造只是进行了简单的值拷贝,对于旧对象开辟的内存空间并没有进行拷贝
- 在构造函数前面加中explicit,代表不允许使用隐式构造函数,
- Person(10,”lucy”)这个是匿名对象,生命周期在当前行,Person(p1)这个不行,Person p=Person(p1)这个可以
- Person p=Person(10,”lucy”),显示构造,这个右边匿名且创建了对象,然后传给左边,左边只是接收了,实际它自己并没有创建对象
- Person p={10,”lucy”},Person p=p1,

- 上图代码若直接写有参构造的话,Phone phone会调用无参构造,而事实上Phone和Game并无无参构造,会报错,所以用初始化列表来实现,phone(pho_name)这个是定义,而Phone phone是声明
- Person(int age,int num):m_age(age),m_num(num){},这个是初始化列表,是有参构造的另一种写法
- 构造函数和析构函数顺序是相反的
- c++中malloc是不会调用构造函数,free不会调用析构函数
- Person* p=new Person,这个是动态创建对象,delete p释放p对象的内存空间
- Person* p=new Person[10],创建对象数组时,只能调用无参构造,delete []p
- int* p=new int[10],new数组返回的是数组首元素的地址,释放该空间时,要delete []p才是释放整个数组,如果delete p则只是释放首元素
- void* p=new Person, delete p;这个创建对象可以成功,但是delete时不会调用析构,因为p是void*类型,不是Person类型
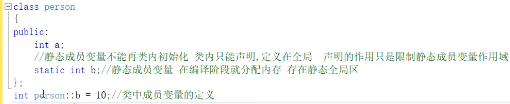
- 如果静态成员变量被const修饰,那么它就可以在类内初始化,
- 静态成员变量,没有实例化对象时,就可通过Person::age来猎取
- 一个类外全局函数或者另外一个类的成员函数,如果想访问类私有成员,可以设置这个函数为类的友元,步骤为在类里面开关写上friend void prin(Person &p)
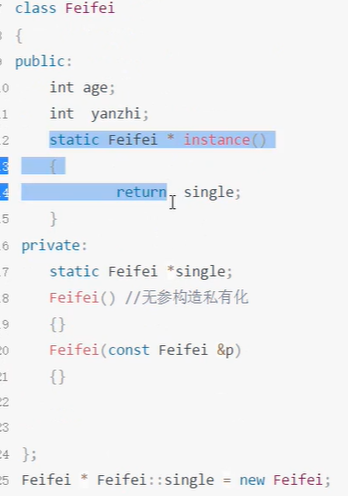
- 上图单例模式
- const 修饰的全局变量和静态成员变量保存在常量区,不可更改
- 一个空的类的大小是1个字节,静态成员变量(静态全局区),静态成员函数,普通成员函数(栈区)三者都不存在实例化的类对象中,所以它们三个不占用类的内存大小
- Person类里面的成员函数,Person add_Person(Person & p) const{ }最后加个const,代表它是常函数,就不能通过this->age=100这种修改成员变量的值了,因为这个const修饰的this指针,const Person* const this
- 全局函数:Person person_add(Person &p1,Person &p2),成员函数: Person person_add(Person &p2){Person p(this->age+p2.age); return p;},如果把这两个函数改成Person operator+(Person &p1,Person &p2),Person operator+(Person &p2),那么调用时候就可以用p3=p1+p2,这个就是运算符号的重载
- ostream& operator<<(ostream &cout,Person p){cout<<p.age; return cout; }运算符<<的重载,调用的时候就可以cout<<p<<endl,其中cout<<p是<<重载后结果会返回cout,然后在与endl结合
- 在对++进行重载时,前置++和后置++是不一样的,前置++是Myint & operator++(){this->num=this->num+1; return *this; },而且它是在类的内部,编译器在调用时会找这个函数p1.operator++(),后置++是Myint operator++(int){Myint temp=*this; this->num=this->num+1; return *temp; },编译器在调用时会找这个函数p1.operator++(int),而且后置++不是返回引用类型是因为不能返回局部变量的引用
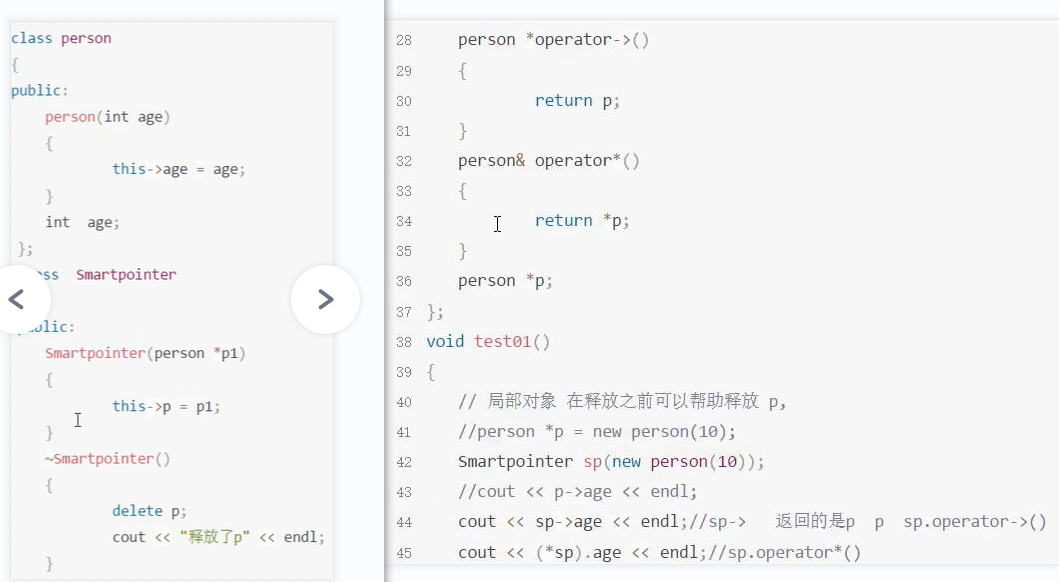
- 上图中的SmartPointer就是自定义的智能指针,sp是局部变量,函数结束后它就通过自身的析构来释放Person的堆空间,而且通过对->和*的重载后,sp就可以当成Person来使用了
- Person(int age,char* name){this->name=new char[strlen(name)+1]; strcpy(this->name,name) ;} 这段代码为何不直接this->name=name,是因为如果参数name所指向的空间被释放了,所以成员变量name自己开辟空间比较合适
- C++中,每个类默认都会有operator=()这个重载,在Person类的成员变量char *name;在对其初始化时,是给name开辟了内存,所以Person p1(10,”lucy”);Person p2;p2=p1;这个代码会报错,因为默认的Person & operator=(Person &p1)只是简单的this->name=p1.name,return *this,也就是p1成员name是开辟的内存,而在p2=p1之后,p2的成员name只是指向了p1.name的空间,其自身并未有空间,所以p1调用析构后,p1.name的内存就释放掉了,p2.name的指向就有问题了,
- 针对上述问题,我们重写一下Person类的operator=(Person &p1)函数,不用this->name=p1.name,而是this->name=new char[strlen(p1.name)+1]; strcpy(this->name,p1.name; return *this;
- Myadd类中,int add(int a,int b),在类里写个int operator()(int x,int y){return x+y},以后就可以直接Myadd()(3,4)或者Myadd ad; ad(3,4),这里的ad叫做函数对象
- in>>buf ;out<<str
- class Dog :public Animal 继承 ,这里的public相当于把父类中成员权限原封不动的弄到子类中,class Dog :protected Animal则是把父类中public成员变成protected后在一起弄到子类
- 子类不能访问父类的private成员
- Son(int age,string name,int id):Father(age,name){tihs->id=id ;}这个是子类的构造函数,因为创建子类对象时,会先创建父类,所以如果父类是有参构造,那么就要在子类的构造函数在带上父类的构造
- 如果子类有父类同时的成员函数,子类构造时,Son(int age,int age1):Father(age1),age(age){},Father(age1),age(age)分别经父类和子类的age赋值,后面那age(age)不写的话,就在子类构造里面写this->age=age也可以
- 父类和子类有同名static成员或者static函数,那么子类的static成员或static 函数有效
- 如果C类同时继承了A类B类,而且A,B类中都是成员int num,那么C使用时,c.A::num或者c.B::num,也就是加上父类的作用域
- 如果 父类和子类有同名的函数,那么只有子类的函数有效,父类的函数会被隐藏,同名的成员变量也同理
- A类同时继承了B,C类,而且B,C类中都有int num,那么后面A.B::num或者A.C::num才行
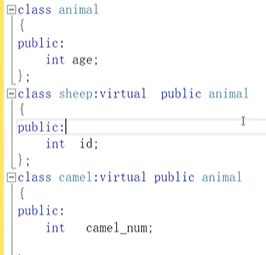
- 上面有camel 和sheep都继承了 animal,然后shenhou在多继承了camel和 sheep话,sh.age就会有歧义,sheep和camel的age都继承自animal,需要sh.sheep::age 或者sh.camel::age才行,此时在sheep和camel加上virtual也就是class sheep:virtual pulblic animal后就可以直接sh.age,因为编译器会自动选择animal的age,这些关系就是菱形继承,而加上virtual就是虚继承
- void de_work(Aniaml& ani){ani.speak(); }, Dog dog; do_work(dog),这个将会输出animal在speak,只有在Animal类的virtual void speak(){};然后才出输出dog在speak,这个就是虚函数
- Animal类的virtual void speak()=0,这个就是纯虚函数,其所在类就为抽象类,其子类也是抽象,当子类重写了这个纯虚函数,那么该子类就不再是抽象类了,抽象类不能被实例化
- Aniaml* ani=new Dog,ani.speak();delete ani;这个最后只会调用父类的析构,而不调用子类的析构,如果想要调用子类析构后再调用父类析构的话,就virtul ~Animal(){}
- 参数const int& num 和int& num可以作为重载的条件
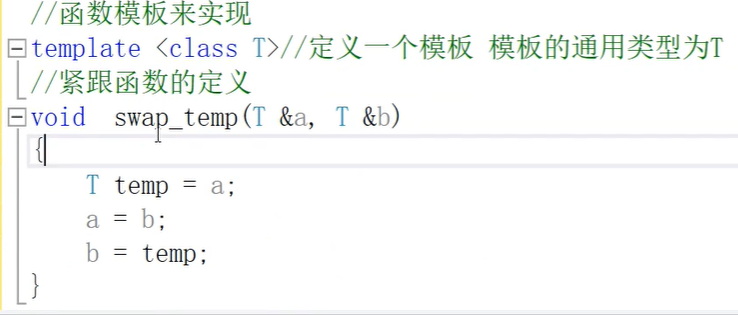
- 两个同名函数Myadd(int a,int b),Myadd(T a ,T b);前者是普通函数,后者是函数模板,如果是Myadd(3,4)会优先调用普通函数,因为不用推导,Myadd<>(3,4)就会调用模板函数,如果两个参数类型不一致,就会调用普通函数,因为它会自动 类型转换,而函数模板是不会进行自动类型转换,
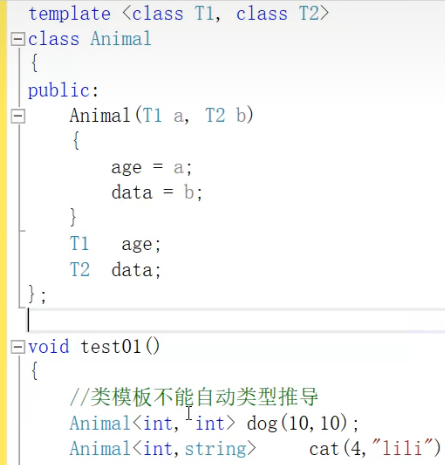

- show()的参数是个类模板,为了同时可以传入dog和cat,所有把函数也设成函数模板

- 上图是show()的第二种方式,也就是整个Animal<int,string> cat传给class T

- 上图中,父类Son是个类模板

- 上图是第二种父类Son是个类模板,其子类的创建方法,这种更灵活

- 上图中,Person模板类,在类内声明构造和成员函数,在类外定义构造的案例,类外定义成员函数,也加上template<class T1,class T2> void Person<T1,T2>::show(){},所以类模板在类内定义还是比较方便点
- 类模板的成员函数,在没有调用之前,它是不会生成的,也就是如果没有调用,那么它只声明不定义都可以,但是如果调用了,就必须定义了,也就是,类模板成员函数的创建时机是在调用的时候,没调用编译器就不会创建这个函数
- 类模板,main.cpp 引入Person.h后,Person.h不能只有Person类的声明,必须同时定义在.h里,不能定义在另外一个.cpp,不然main.cpp创建Person类时会出错

- 上图中的p.a和p.b为Person类的私有成员,如果想访问,就得将函数设成类的友元,friend void showPerson<>(Person<T1,T2> &p),函数名后面的<>要加,因为它是个函数模板
- 上行那个友元也可直接定义在Person类里面,也就是friend void showPerson(Person<T1,T2> &p){ 内容体 },也就是类外不用写,直接搬到Person类里,函数名后的<>就不用了
- int a=10,char b=2;a=static_cast<int>(b);这个静态转换和C中的强制转换是一样的
- static_cast<>只能用于内置的普通数据类型和具有继承关系的父子类之间类型的转换,普通类型的指针也不支持
- static_cast可以用于父类转子类或者子类转父类,而dynamic_cast只支持子类转父类,但在多态时,动态转换是可以父类转子类或者子类转父类
- 动态转换:dynamic_cast不能用于普通数据类型和没有继承关系的父子类之间类型的转换,
- int* a=NULL;const int* b=NULL; 这里a=static_cast(int*)(b)不可以,因为b是const int*类型,不属于普通类型,可以用a=const_cast(int*)(b) b=const_cast(const int*)(a),也就是const_cast是用来加const或者去除const
- reinterpret_cast用来普通数据类型的指针之间的转换,而且还支持普通类型和普通类型指针之间转换,比如char*转成int类型
- 某个函数里有throw 1或者throw ‘a’,那么在调用时,try后catch(int)或者catch(char),如果是throw 1,你却catch(char),就会出错
- 在多catch时,如果几个catch都没能匹配到相应的类型时,可以在最后一个catch(…),意思你匹配任何类型
- 在try到hrow之间定义的对象,会在throw之前释放掉

-
Myexception p1; throw p1;这个代码在catch后,执行结束会有两个Myexception析构,因为创建的p1对象在throw之前就会释放掉,throw p1时,又将p1拷贝了一份到内存,然后到catch(Myexception & p)中后有了第二个析构,如果直接throw Myexception(),也就是匿名对象throw 匿名对象 Myexception,执行结束时就一个析构,而且它的生命周期不在当前行,而是在catch里
- c++提供的异常类exception的所有子类,都有一个.whtat()方法,可以输出错误内容
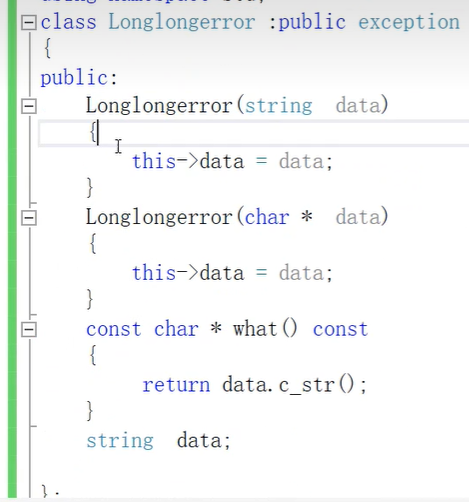
- 上图是自己定义的异常类,其中data.c_str是把data转成const char*类型
- STL, standard template library
- vector<int> ve; ve.push_back(2); vector容器的创建和插入元素,因为里面都要模板,所有<>
- vector<int>::iterator it=ve.begin()获得容器首元素的迭代器,vector<int>::iterator it_end=ve.end()获取末元素的下一个元素的迭代器,it本质是一个指针,所以*it就获得首元素的内容
- vector<int>::reverse_iterator it=ve.rbegin()获得容器末元素的迭代器,vector<int>::reverse_iterator it_end=ve.rend()获取首元素的前一个元素的迭代器,reverse_iterator也就是反向迭代器,it++是向前+,而不像正常的那样向后+
- ve.capacity获取容量,ve.pop_back()尾删
- #include <algorithm>,容器里提供了for_each(it_start,it_end,print),这个print是自己写的一个函数指针,void print(int a){ cout<<a<<endl ;} 因为for_each是通用的,所以要给它指定一个实现的函数,上面的for_each就是实现迭代打印出元素
- vector<vector<int>> 这个是容器里面嵌套着容器,里面嵌套的容器里的内容是int类型

- vector创建对象时,内容类型<int>都要带上,比如,vector<int> v1(ve.begin(),ve.end())




- ve.resize(num)这个是把容器的size变化,而其capacity并未变化
- sort(ve.begin(),ve.end());这个给容器内容排序,默认是从小到大排序,如果想要从大到小,那么可以写个函数,bool compare(int a,int b){return a>b; },sort(ve.begin(),ve.end(),compare);然后就是从大到小,如果return a<b,那就是从小到大了
- vector<int>(ve).swap(ve),这个函数的意义,vector<int>(ve)是创建一个匿名对象,并把ve的内容拷贝一份,swap之后,相当于原本指向ve的指针反过来指向这个匿名的空间,而这个匿名的指针则去指向原来的ve的空间,由于匿名对象的生命周期在当前行,所以过后这个匿名对象就被释放了,它所指向的原ve空间也就释放了,如果原ve的capacity有10000,但是size只有10,那么这么操作后,ve的capacity将会缩至10
- vector容器的容量不够时,它会自动扩充,但是它不是直接扩充,而是找到扩充之后的空间,然后把旧空间的内容拷贝过来,在释放掉旧空间,这时候就要注意旧空间时创建的迭代哭也失效了,要重装创建新的迭代器
- string str(5,’k’)这个是”kkkkk”字符串,也就是里面有5个k

- string str=”helloworld”; str[4]值就为0, str.at(4)和str[4]一样的效果,它们都是返回字符的引用,也就是char &



- str.substr(star_pos,num_of_sub)

- string str=”helloword”; char * s=NUlLL; s=const_cast<char*>(str.c_str())
- deque有个中控器,控制里面存储的一系列内存段的地址
- deque的四个构造,赋值,数据存取操作,删除操作和vector一样,大小操作和vector基本一样,就是它没有capacity和reserve()这两个


- 上图的insert参数pos是个iterator类型,不能传入int类型
- 评委给分,去掉最高分,去掉最低分,可以用deque,因为它有pop_back,pop_front
- for_each())函数第三个参数,Fn fn,最终执行fn(*First);我们定义一个Prnt类,内部重写了operator()(int a){cout<<a<<endl;},r所以最终for_each(First,End,Print())会输出a的值,其中Print()是匿名对象,相当于Print()(*First)
- 像这样的类,重写了operator(),然后可以像函数 一样调用, 就叫做函数对象,也叫仿函数
- 由于for_each函数里最后一句执行fn(*First),我们可以写个类,比如Print类,然后重写了operator(),每次调用for_each()第三个参数直接传匿名对象,就相当于Print()(*First)
- 函数对象(重载了operator())或者普通函数返回值为bool类型的叫做谓词
- vector<int> ::terator it =find_if(First,End,greater3),顶嘴greater3返回值为bool
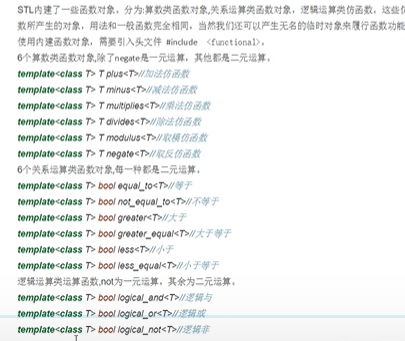
- 上图是STL内建函数对象,#include<functional>,就可以用,比如plus<int>(2,3)
- for_each(First,End,Print()),这里如果函数对象Print里的operator()里有两个参数的话,而Print()(*First)只支持一个参数,for_each本身只有三个参数,这里就可以用适配器如下:

- 这时就可以for_each(First,End,bind2nd(Print(),100)),这里a=1,num=100,如果是bind1st(Print(),100),则是a=100,num=1,也就是这两种参数位置对换了
- buf=”Get /aa.html” ; sscanf(buf,”Get /%s”,filename),执行后filename=”aa.html”
- 用 gets() 时有空格也可以直接输入,但是 gets() 有一个非常大的缺陷,即它不检查预留存储区是否能够容纳实际输入的数据,换句话说,如果输入的字符数目大于数组的长度,gets 无法检测到这个问题,就会发生内存越界,所以编程时建议使用 fgets()。
- 这一行没啥用
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/188312.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
