大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
论文:https://arxiv.org/pdf/1608.06993.pdf
参考文献:
DenseNet算法详解_AI之路-CSDN博客_densenet
DenseNet解读_年轻即出发,-CSDN博客_densenet
与残差网络的区别:
残差网络是加上跳转链接,非线性映射关系:
X(t)=H(X(t-1))+X(t-1)
An advantage of ResNets is that the gradient can flow directly through the identity function from later layers to the earlier layers. However, the identity function and the output of H are combined by summation, which may impede the information flow in the network.
ResNets的一个优点是,梯度可以直接通过恒等函数从后面的层流向前面的层。但是,恒等函数和H的输出是累加的,这可能会阻碍网络中的信息流。
为了改善不同层之间信息流的的问题,DenseNet采用直接将所有输入连接到输出层。
与残差网络不同的是不用相加而是连接,输入直接传入到输出如图1,非线性映射关系:
X(t)=H([X0,X1,X2,…,X(t-1)])
网络模型:
稠密连接主要由两部分组成:dense block稠密块+transition layer 过渡块
稠密块:定义了输入输出之间的连接关系
过渡层:控制通道数
如图是生长率为4的5层稠密块,这张图对我吸引力也是相当大。主要思想是特征重复利用,又在通道数增多的问题上加入Bottleneck Layers和 transition Layers控制通道数量在4K
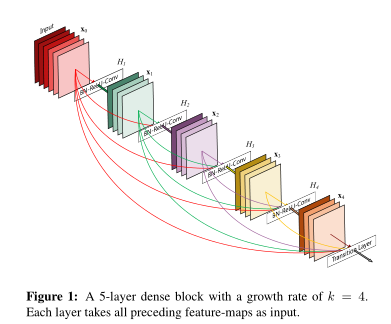

生长率(Growth rate)为4表示每个稠密层输出feature map维度是4,第L层有k0+k(L-1)层输入feature-maps,其中k0是输入层通道数。在定义时一般是全局变量。
5层稠密块表示5个BN+ReLU+Conv(3*3)Layer
为了确保layers之间的最大信息流,将所有的layers直接连接起来。
为了保持前馈特性,每个层的输入是所有前面层映射输出,也将自己的特征映射结果作为后面层的输入。
稠密块后接着过渡层,过渡层就是1*1卷积核,通道数4k,k是生长率。
过渡层解决的问题:
每一个DenseBlock模块的输出维度是很大的,假设一个L层的Dense Block模块,假设其中已经加入了Bottleneck 单元,那么输出的维度为,第1层的维度+第2层的维度+第3层的维度+******第L层的维度,加了Bottleneck单元后每层的输出维度为4K,那么最终Dense Block模块的输出维度为4K*L。随着层数L的增加,最终输出的feature map的维度也是一个很大的数。为了解决这个问题,在transition layer模块中加入了1*1卷积做降维。
池化层:
当特征大小改变时,连接操作不再适用。然而卷积层常在下采样提取特征时改变特征大小。池化层用在
解决使用稠密块后带来通道数剧增,使用过多稠密块模型过于复杂的问题。
class Transition(nn.Module):
def __init__(self, nChannels, nOutChannels):
super(Transition, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, nOutChannels, kernel_size=1,
bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = F.avg_pool2d(out, 2)
return out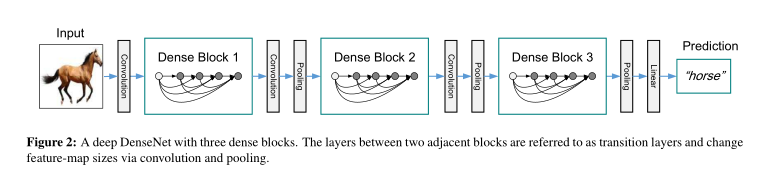
图2则是一个三个稠密块的稠密连接网络。每层之间有过渡层改变通道数大小,最后一层没有过渡层。
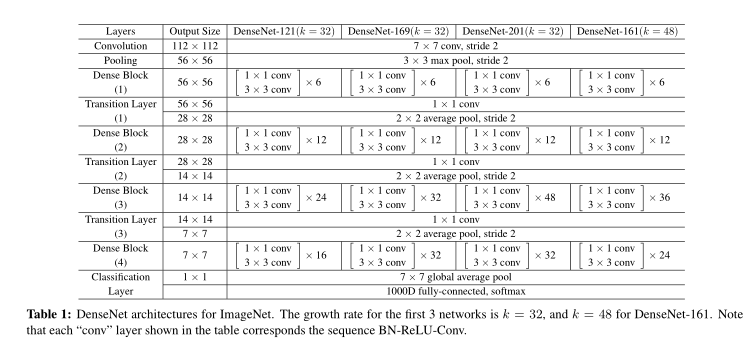
表1是DenseNet网络结构
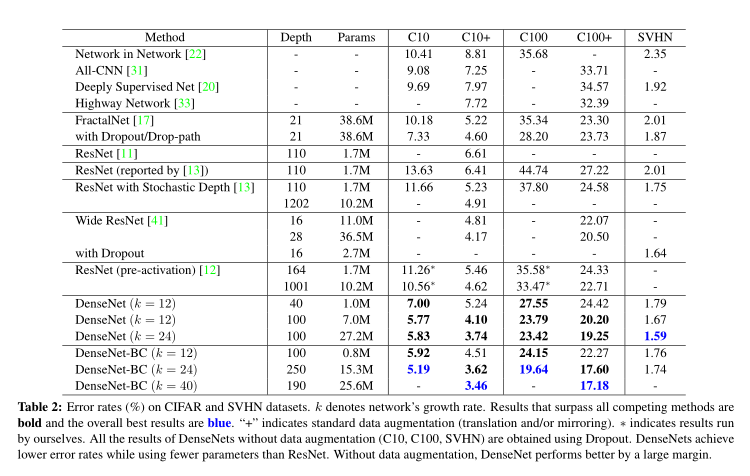
表2是在CIFAR和SVHN上的对比实验。k越大网络参数越大,效果越好。k较小时,在过渡层是存在信息丢失问题
文章同时提出了DenseNet,DenseNet-B,DenseNet-BC三种结构,具体区别如下:
DenseNet:
Dense Block模块:BN+Relu+Conv(3*3)+dropout
transition layer模块:BN+Relu+Conv(1*1)(filternum:m)+dropout+Pooling(2*2)
DenseNet-B:
Dense Block模块:BN+Relu+Conv(1*1)(filternum:4K)+dropout+BN+Relu+Conv(3*3)+dropout
transition layer模块:BN+Relu+Conv(1*1)(filternum:m)+dropout+Pooling(2*2)
DenseNet-BC:
Dense Block模块:BN+Relu+Conv(1*1)(filternum:4K)+dropout+BN+Relu+Conv(3*3)+dropout
transition layer模块:BN+Relu+Conv(1*1)(filternum:θm,其中0<θ<1,文章取θ=0.5) +dropout +Pooling(2*2)
其中,DenseNet-B在原始DenseNet的基础上,加入Bottleneck layers, 主要是在Dense Block模块中加入了1*1卷积,使得将每一个layer输入的feature map都降为到4k的维度,大大的减少了计算量。
解决在Dense Block模块中每一层layer输入的feature maps随着层数增加而增大,则需要加入Bottleneck 模块,降维feature maps到4k维
DenseNet-BC在DenseNet-B的基础上,在transitionlayer模块中加入了压缩率θ参数,论文中将θ设置为0.5,这样通过1*1卷积,将上一个Dense Block模块的输出feature map维度减少一半。
优缺点:
解决梯度消失的问题
以下是介绍梯度消失、梯度弥散问题的博客:
详解机器学习中的梯度消失、爆炸原因及其解决方法_Double_V的博客-CSDN博客
机器学习总结(二):梯度消失和梯度爆炸_以梦为马,不负韶华-CSDN博客
解决方案是:尽量缩短前层和后层之间的连接。 (they contain shorter connections between layers close to the input and those close to the output)
(梯度消失经常出现,一是在深层网络中,二是采用了不合适的损失函数,比如sigmoid
梯度爆炸一般出现在深层网络和权值初始化值太大的情况下
解决方案:
残差网络Highway Networks通过旁路信息将上一层信息直接传递给下一层。
随机深度网络,随机dropping layers
分型网络,多条短路径相连接)
我认为梯度消失问题是网络太深,梯度值在网络传递过程中会越来越小或越来越大,传递至输入时损失梯度变化过大,所以反馈信息有误。当每个损失计算都直接与输入相连时则不会出现损失梯度在传递过程中信息值变化过大。
加强特征传播
每一层都可以直接从损失函数和原始输入信号中获取梯度,从而实现隐含的深度监控
鼓励特征重用
前向传递中每经过一层传递信息都将改变,ResNet利用相加保留了这部分信息。随着近几年研究表明许多层贡献很小,可以在训练中随机删去某些层。这使得ResNet有些像RNN,但是ResNet的参数很大,因为每层都需要自己的权重。
DenseNet明确区分了添加到网络中的信息(改变的信息)和被保护的信息(重用的信息)。
DenseNet层是非常窄的(例如,每层12个过滤器),只在网络的集合知识中添加一小部分feature-maps,并保持其余的feature-maps不变,最终的分类器根据网络中的所有feature-maps做出决策。
大幅度减少参数数量
网络比较窄,参数少,其feature maps=4k,k是生长率,一般比较小。
不需要学习冗余的特征映射。
有正则化,可以在小数据集上减少过拟合,文中解释为参数减少的原因。
Bottleneck Layers:
BN+Relu+Conv(1*1)(filternum:4K)+dropout(代码中无)+BN+Relu+Conv(3*3)+dropout(代码中无)
class Bottleneck(nn.Module):
def __init__(self, nChannels, growthRate):
super(Bottleneck, self).__init__()
interChannels = 4*growthRate
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, interChannels, kernel_size=1,
bias=False)
self.bn2 = nn.BatchNorm2d(interChannels)
self.conv2 = nn.Conv2d(interChannels, growthRate, kernel_size=3,
padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat((x, out), 1)
return out普通Dense Block :
BN+Relu+Conv(3*3)+dropout(代码中无)
class SingleLayer(nn.Module):
def __init__(self, nChannels, growthRate):
super(SingleLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, growthRate, kernel_size=3,
padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = torch.cat((x, out), 1)
return outDense Net,3块Dense Block,如图2
class DenseNet(nn.Module):
def __init__(self, growthRate, depth, reduction, nClasses, bottleneck):
super(DenseNet, self).__init__()
nDenseBlocks = (depth-4) // 3
if bottleneck:
nDenseBlocks //= 2
nChannels = 2*growthRate
self.conv1 = nn.Conv2d(3, nChannels, kernel_size=3, padding=1,
bias=False)
self.dense1 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck)
nChannels += nDenseBlocks*growthRate
nOutChannels = int(math.floor(nChannels*reduction))
self.trans1 = Transition(nChannels, nOutChannels)
nChannels = nOutChannels
self.dense2 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck)
nChannels += nDenseBlocks*growthRate
nOutChannels = int(math.floor(nChannels*reduction))
self.trans2 = Transition(nChannels, nOutChannels)
nChannels = nOutChannels
self.dense3 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck)
nChannels += nDenseBlocks*growthRate
self.bn1 = nn.BatchNorm2d(nChannels)
self.fc = nn.Linear(nChannels, nClasses)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
def _make_dense(self, nChannels, growthRate, nDenseBlocks, bottleneck):
layers = []
for i in range(int(nDenseBlocks)):
if bottleneck:
layers.append(Bottleneck(nChannels, growthRate))
else:
layers.append(SingleLayer(nChannels, growthRate))
nChannels += growthRate
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.trans1(self.dense1(out))
out = self.trans2(self.dense2(out))
out = self.dense3(out)
out = torch.squeeze(F.avg_pool2d(F.relu(self.bn1(out)), 8))
out = F.log_softmax(self.fc(out))
return out过渡层:
BN+Relu+Conv(1*1)(filternum:m)+dropout(无)+Pooling(2*2)
class Transition(nn.Module):
def __init__(self, nChannels, nOutChannels):
super(Transition, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, nOutChannels, kernel_size=1,
bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = F.avg_pool2d(out, 2)
return out
代码:
https://github.com/liuzhuang13/DenseNet
GitHub – titu1994/DenseNet: DenseNet implementation in Keras
https://github.com/YixuanLi/densenet-tensorflow
参考文献:
5.12. 稠密连接网络(DenseNet) — 《动手学深度学习》 文档
DenseNet模型_毛财胜的专栏-CSDN博客_densenet201
DenseNet算法详解_AI之路-CSDN博客_densenet
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187797.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
