大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用


sql注入报错注入原理详解
sql注入报错注入原理详解
前言
我相信很多小伙伴在玩sql注入报错注入时都会有一个疑问,为什么这么写就会报错?曾经我去查询的时候,也没有找到满意的答案,时隔几个月终于找到搞清楚原理,特此记录,也希望后来的小伙伴能够少走弯路
0x01
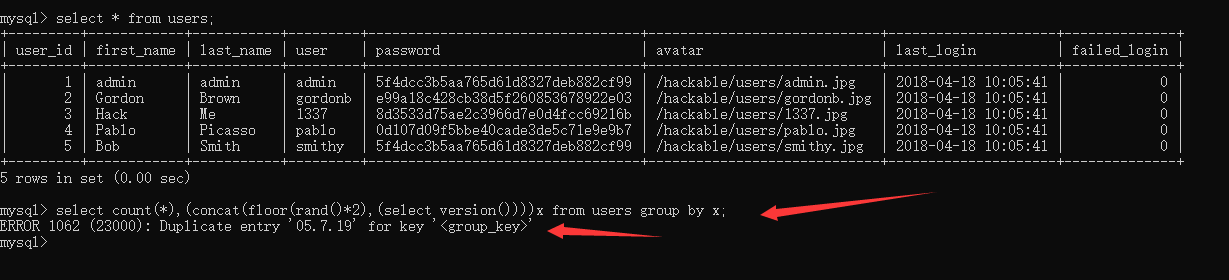
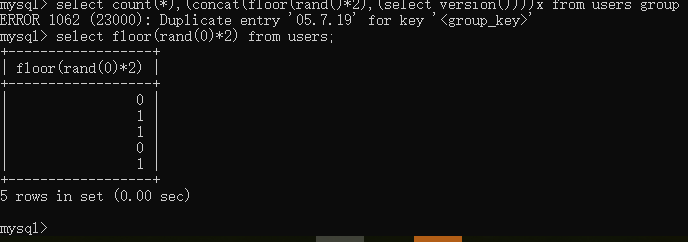
我们先来看一看现象,我这里有一个users表,里面有五条数据:
然后用我们的报错语句查询一下:

select count(*),(concat(floor(rand()*2),(select version())))x from users group by x
成功爆出了数据库的版本号。
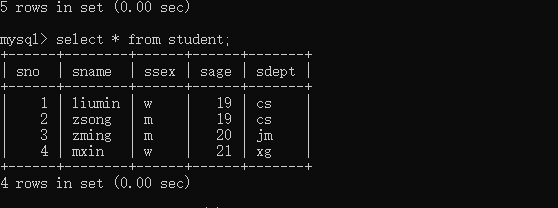
要理解这个错误产生的原因,我们首先要知道group by语句都做了什么。我们用一个studetn表来看一下:
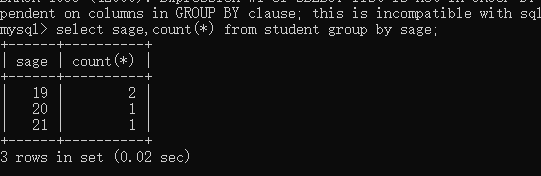
现在我们通过年龄对这个表中的数据进行下分组:
形成了一个新的表是吧?你其实应该能够想到group by 语句的执行流程了吧?最开始我们看到的这张sage-count()表应该时空的,但是在group by语句执行过程中,一行一行的去扫描原始表的sage字段,如果sage在sage-count()不存在,那么就将他插入,并置count()置1,如果sage在sage-count()表中已经存在,那么就在原来的count(*)基础上加1,就这样直到扫描完整个表,就得到我们看到的这个表了。
注:这里有特别重要的一点,group by后面的字段时虚拟表的主键,也就是说它是不能重复的,这是后面报错成功的关键点,其实前面的报错语句我们已经可以窥见点端倪了
####0x02
正如我前面所说的,报错的主要原因时虚拟表的主键重复了,那么我们就来看一下它到底是在哪里,什么时候重复的。这里rand()函数就登场了。
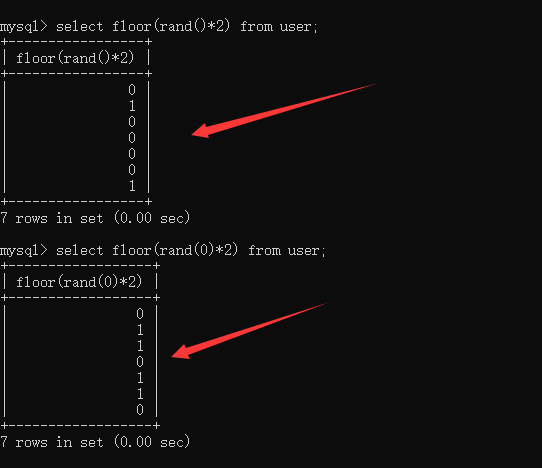
首先我们先来了解rand()函数的用法:
1.用来生成一个0~1的数
2.还可以给rand函数传一个参数作为rand()的种子,然后rand函数会依据这个种子进行随机生成。
那他们的区别是什么呢?我们来看一下,这两个语句的执行效果:
可以看到rand()生成的数据毫无规律,而rand(0)生成的数据则有规律可循,是:
0110 0110
注:如果你觉得数据不够,证明不了rand()的随机性,你可以自己多插入几条数据再查询试一下。

0x03
现在我们弄清楚了group by语句的工作流程,以及rand()与rand(0)的区别,那么接下来就是重点了,mysql官方说,在执行group by语句的时候,group by语句后面的字段会被运算两次。
**第一次:**我们之前不是说了会把group by后面的字段值拿到虚拟表中去对比吗,在对比之前肯定要知道group by后面字段的值,所以第一次的运算就发生在这里。
**第二次:**现在假设我们下一次扫描的字段的值没有在虚拟表中出现,也就是group by后面的字段的值在虚拟表中还不存在,那么我们就需要把它插入到虚拟表中,这里在插入时会进行第二次运算,由于rand函数存在一定的随机性,所以第二次运算的结果可能与第一次运算的结果不一致,但是这个运算的结果可能在虚拟表中已经存在了,那么这时的插入必然导致错误!
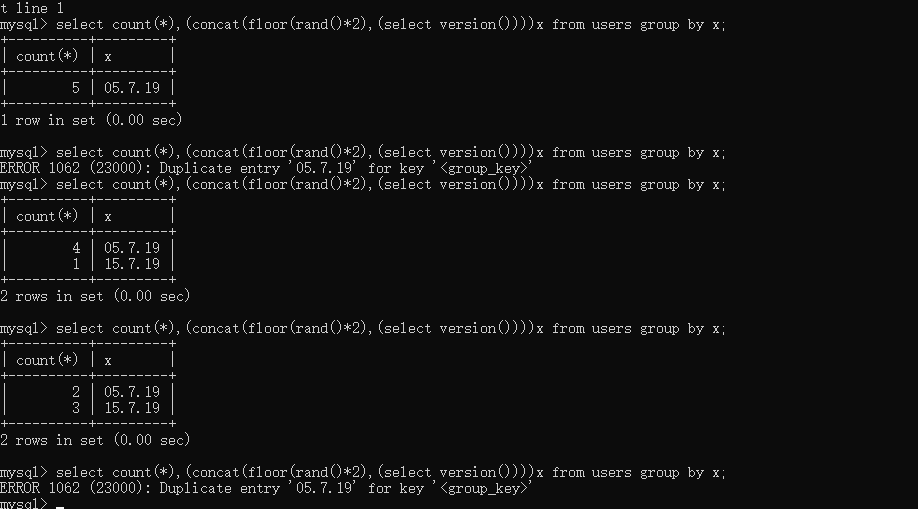
所以我们现在通过一个例子来验证我们的理论,拿出我们最开始的例子:
select count(*),(concat(floor(rand(0)*2),'@',(select version())))x from users group by x
声明:users表就是本文第一个表,表中有五条数据
注意我这里用的是rand(0),不是rand(),
rand(0)生成的有规律的序列:
我们跟着刚刚的思路走,最开始的虚拟表是空的,就像下面一样:
| count(*) | x |
|---|---|
当我扫描原始表的第一项时,第一次计算,floor(rand(0)*2)是0,然后和数据库的版本号(假设就是5.7.19)拼接,到虚拟表里去寻找x有没有x的值是x@5.7.19的数据项,结果显然是没有,那么接下来就将它插入到上表中,但是还记得吗,在插入之前会进行第二次计算,这时x的值就变成了1@5.7.19,所以虚拟表变成了下面这样:
| count(*) | x |
|---|---|
| 1 | 1@5.7.19 |
现在扫描原始表的第二项,第一次计算x==’1@5.7.19‘,已经存在,不需要进行第二次计算,直接插入,得到下表:
| count(*) | x |
|---|---|
| 2 | 1@5.7.19 |
扫描原始表的第三项,第一次计算x==‘0@5.7.19’,虚拟表中找不到,那么进行第二次计算,这时x==‘1@5.7.19’,然后插入,但是插入的时候问题就发生了,虚拟表中已经存在以1@5.7.19为主键的数据项了,插入失败,然后就报错了!
上面是使用rand(0)的情况,rand(0)是比较稳定的,所以每次执行都可以报错,但是如果使用rand()的话,因为它生成的序列是随机的嘛,所以并不是每次执行都会报错,下面是我的测试结果:
执行了五次,报错两次,所以是看运气。
总结
总之,报错注入,rand(0),floor(),group by缺一不可
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187359.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
