大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
关注公众号【江南一点雨】,专注于 Spring Boot+微服务以及前后端分离等全栈技术,定期视频教程分享,关注后回复 Java ,领取松哥为你精心准备的 Java 干货!


resultMap算是mybatis映射器中最复杂的一个节点了,能够配置的属性较多,我们在mybatis映射器配置细则这篇博客中已经简单介绍过resultMap的配置了,当时我们介绍了resultMap中的id和result节点,那么在resultMap中除了这两个之外,还有其他节点,今天我们就来详细说说resultMap中的这些节点。
如果小伙伴对mybatis尚不了解,建议先翻看博主前面几篇博客了解一下,否则本文你可能难以理解,老司机请略过。
#概览
先来看看resultMap中都有那些属性:
<resultMap>
<constructor>
<idArg/>
<arg/>
</constructor>
<id/>
<result/>
<association property=""/>
<collection property=""/>
<discriminator javaType="">
<case value=""></case>
</discriminator>
</resultMap>
我们看到,resultMap中一共有六种不同的节点,除了id和result我们在mybatis映射器配置细则这篇博客中已经介绍过了之外,还剩三种,剩下的四个本文我们就来一个一个看一下。
#constructor
constructor主要是用来配置构造方法,默认情况下mybatis会调用实体类的无参构造方法创建一个实体类,然后再给各个属性赋值,但是有的时候我们可能为实体类生成了有参的构造方法,并且也没有给该实体类生成无参的构造方法,这个时候如果不做特殊配置,resultMap在生成实体类的时候就会报错,因为它没有找到无参构造方法。这个时候mybatis会报如下错误:

那么解决方式很简单,就是在constructor节点中进行简单配置,假设我现在User实体类的构造方法如下:
public User(Long id, String username, String password, String address) {
this.id = id;
this.username = username;
this.password = password;
this.address = address;
}
那么我在resultMap中配置constructor节点,如下:
<resultMap id="userResultMap" type="org.sang.bean.User">
<constructor>
<idArg column="id" javaType="long"/>
<arg column="username" javaType="string"/>
<arg column="password" javaType="string"/>
<arg column="address" javaType="string"/>
</constructor>
</resultMap>
在constructor中指定相应的参数,这样resultMap在构造实体类的时候就会按照这里的指定的参数寻找相应的构造方法去完成了。
#association
association是mybatis支持级联的一部分,我们知道在级联中有一对一、一对多、多对多等关系,association主要是用来解决一对一关系的,假设我现在有两张表,一张表示省份,一张表示省份的别名,假设一个省只有一个别名(实际上有的省份有两个别名),我们来看一下如下两张表:
1.省份表:
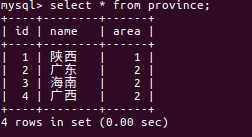
说明一下最后一个area字段表示该省是属于南方还是北方。
2.别名表:
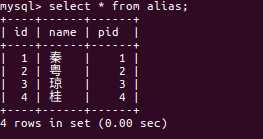
别名表中pid表示省份的id,假设我现在有一个实体类,Province,该类有两个属性,一个叫做name表示省份的名字,一个叫做alias表示省份的别名,那么我在查询的时候可以通过association来实现这种一对一级联,实现方式如下:
##创建Alias实体类
public class Alias {
private Long id;
private String name;
//省略getter/setter
}
##创建Province实体类
public class Province {
private Long id;
private String name;
private Alias alias;
//省略getter/setter
}
##创建AliasMapper
public interface AliasMapper {
Alias findAliasByPid(Long id);
}
这里就提供一个方法,根据省份的id找到省份的别名。
##创建aliasMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.sang.db.AliasMapper">
<select id="findAliasByPid" parameterType="long" resultType="org.sang.bean.Alias">
SELECT * FROM alias WHERE pid=#{id}
</select>
</mapper>
##创建ProvinceMapper
public interface ProvinceMapper {
List<Province> getProvince();
}
##创建provinceMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.sang.db.ProvinceMapper">
<resultMap id="provinceResultMapper" type="org.sang.bean.Province">
<id column="id" property="id"/>
<association property="alias" column="id" select="org.sang.db.AliasMapper.findAliasByPid"/>
</resultMap>
<select id="getProvince" resultMap="provinceResultMapper">
SELECT * FROM province
</select>
</mapper>
小伙伴们注意这里的resultMap,我们在resultMap中指定了association节点,association节点中的select属性表示要执行的方法,该方法实际上指向了一条SQL语句(就是我们在aliasMapper.xml中配置的那条SQL语句),column表示给方法传入的参数的字段,我们这里要传入省份的id,所以column为id,property表示select查询的结果要赋值给谁,我们这里当然是赋值给Province的alias属性。
##在mybatis-conf.xml中配置mapper
<mappers>
<mapper resource="provinceMapper.xml"/>
<mapper resource="aliasMapper.xml"/>
</mappers>
##测试
@Test
public void test7() {
SqlSession sqlSession = null;
try {
sqlSession = DBUtils.openSqlSession();
ProvinceMapper pm = sqlSession.getMapper(ProvinceMapper.class);
List<Province> list = pm.getProvince();
for (Province province : list) {
System.out.println(province);
}
sqlSession.commit();
} catch (Exception e) {
e.printStackTrace();
sqlSession.rollback();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
测试结果:
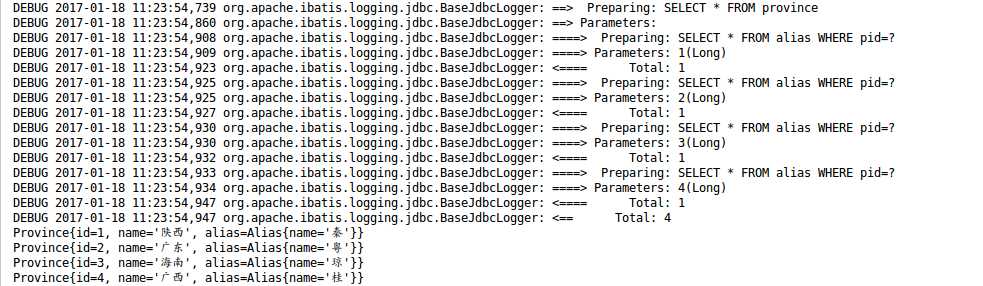
OK,这就是简单的一对一级联的使用。
#collection
collection是用来解决一对多级联的,还是上面那个例子,每个省份下面都会有很多城市,于是,我来创建一张城市表,如下:
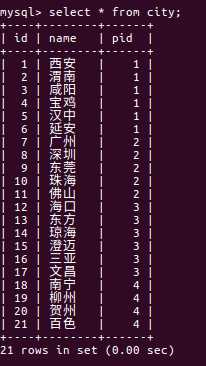
城市表中有一个pid字段,该字段表示这个城市是属于哪个省份的,OK,假设我现在Province实体类中多了一个属性叫做cities,这个cities属性的数据类型是一个List集合,这个集合中放的所有的数据就是这个省份的,我希望查询结束之后这个属性的值就会被自动填充,OK,那么在上面那个案例的基础上,我们来看看这个要怎么实现。
##为Province类添加属性
新的Province类变成下面这个样子:
public class Province {
private Long id;
private String name;
private Alias alias;
private List<City> cities;
//省略getter/setter
}
##创建City实体类
public class City {
private Long id;
private Long pid;
private String name;
//省略getter/setter
}
##创建CityMapper
public interface CityMapper {
List<City> findCityByPid(Long id);
}
CityMapper中就提供一个方法,那就是根据省份的id来查找到相应的城市。
##创建cityMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.sang.db.CityMapper">
<select id="findCityByPid" parameterType="long" resultType="org.sang.bean.City">
SELECT * FROM city WHERE pid=#{id}
</select>
</mapper>
##在mybatis-conf.xml中配置mapper
<mappers>
<mapper resource="provinceMapper.xml"/>
<mapper resource="aliasMapper.xml"/>
<mapper resource="cityMapper.xml"/>
</mappers>
##修改provinceMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.sang.db.ProvinceMapper">
<resultMap id="provinceResultMapper" type="org.sang.bean.Province">
<id column="id" property="id"/>
<association property="alias" column="id" select="org.sang.db.AliasMapper.findAliasByPid"/>
<collection property="cities" column="id" select="org.sang.db.CityMapper.findCityByPid"/>
</resultMap>
<select id="getProvince" resultMap="provinceResultMapper">
SELECT * FROM province
</select>
</mapper>
多了一个collection节点,节点中属性的含义和association都是一样的,我这里不再赘述。OK,如此之后,我们就可以来测试了。
##测试
测试代码(和上面association的测试代码是一样的):
@Test
public void test7() {
SqlSession sqlSession = null;
try {
sqlSession = DBUtils.openSqlSession();
ProvinceMapper pm = sqlSession.getMapper(ProvinceMapper.class);
List<Province> list = pm.getProvince();
for (Province province : list) {
System.out.println(province);
}
sqlSession.commit();
} catch (Exception e) {
e.printStackTrace();
sqlSession.rollback();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
测试结果:
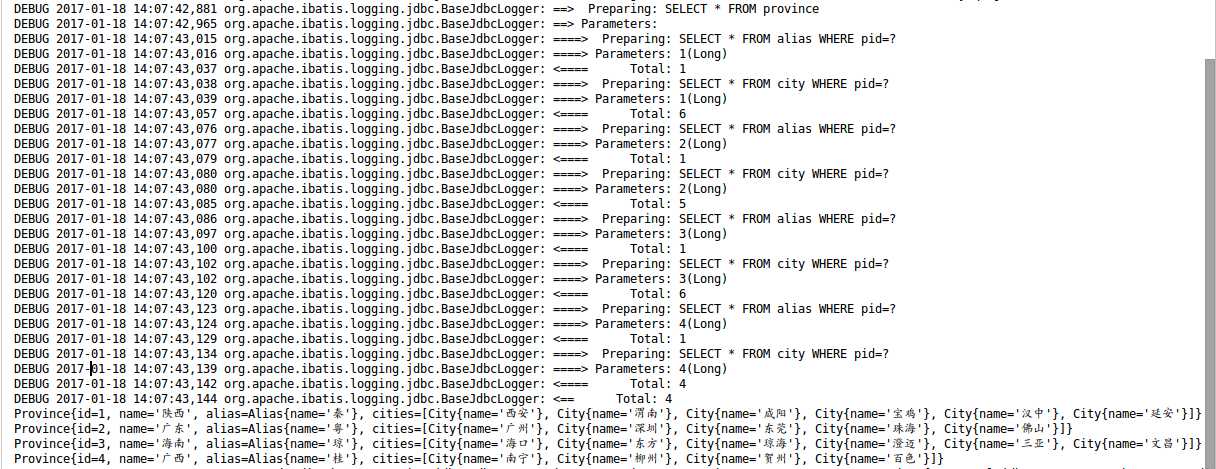
OK,Province的cities属性已经被顺利赋上值了。
#discriminator
discriminator既不是一对多也不是一对一,这个我们称之为鉴别器级联,使用它我们可以在不同的条件下执行不同的查询匹配不同的实体类,还是以上文的例子为例,不同的省份分别属于南北方,南北方的人有不同的饮食习惯,北方人吃面、南方人吃米饭,据此,我来新创建三个类,分别是Food、Rice、Noodle三个类,其中Food是Rice和Noodle的父类,将两者之间的一些共性抽取出来,这三个类如下:
public class Food {
protected Long id;
protected String name;
//省略getter/setter
}
public class Noodle extends Food{
//每天吃几次
private int price;
//省略getter/setter
}
public class Rice extends Food {
//烹饪方法
private String way;
//省略getter/setter
}
然后我在数据库中再分别创建两张表,分别是rice表和noodle表,如下:
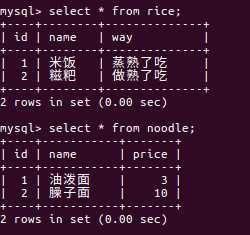
然后我现在现在再修改我的Province实体类,如下:
public class Province {
private Long id;
private String name;
private Alias alias;
private List<City> cities;
private List<Food> foods;
//省略getter/setter
}
这次多了一个foods属性,这个属性是这样,当我在数据库中查询的时候,如果查到这个省份是北方省份,那么就自动去查询noodle表,将查到的结果赋值给foods属性,如果这个省份是南方省份,那么就自动去查询rice表,将查到的结果赋值给foods属性,这种要根据查询结果动态匹配查询语句的需求,我们就可以通过discriminator来实现。OK,接下来我们为Rice和Noodle分别创建Mapper,并在mybatis-conf.xml中注册mapper,结果如下:
public interface RiceMapper {
List<Rice> findRiceByArea();
}
public interface NoodleMapper {
List<Noodle> findNoodleByArea();
}
noodleMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.sang.db.NoodleMapper">
<select id="findNoodleByArea" resultType="org.sang.bean.Noodle">
SELECT * FROM noodle
</select>
</mapper>
riceMapper.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.sang.db.RiceMapper">
<select id="findRiceByArea" resultType="org.sang.bean.Rice">
SELECT * FROM rice
</select>
</mapper>
mybaits-conf.xml
<mappers>
<mapper resource="provinceMapper.xml"/>
<mapper resource="aliasMapper.xml"/>
<mapper resource="cityMapper.xml"/>
<mapper resource="riceMapper.xml"/>
<mapper resource="noodleMapper.xml"/>
</mappers>
OK ,做完这些之后接下来我们就可以来稍微的完善下provinceMapper.xml了,如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.sang.db.ProvinceMapper">
<resultMap id="provinceResultMapper" type="org.sang.bean.Province">
<id column="id" property="id"/>
<association property="alias" column="id" select="org.sang.db.AliasMapper.findAliasByPid"/>
<collection property="cities" column="id" select="org.sang.db.CityMapper.findCityByPid"/>
<discriminator javaType="int" column="area">
<case value="1" resultMap="noodleResultMap"></case>
<case value="2" resultMap="riceResultMap"></case>
</discriminator>
</resultMap>
<resultMap id="noodleResultMap" type="org.sang.bean.Province" extends="provinceResultMapper">
<collection property="foods" column="area" select="org.sang.db.NoodleMapper.findNoodleByArea"/>
</resultMap>
<resultMap id="riceResultMap" type="org.sang.bean.Province" extends="provinceResultMapper">
<collection property="foods" column="area" select="org.sang.db.RiceMapper.findRiceByArea"/>
</resultMap>
<select id="getProvince" resultMap="provinceResultMapper">
SELECT * FROM province
</select>
</mapper>
小伙伴们注意,我们在这里添加了discriminator节点,该节点有点类似于switch语句,column表示用哪个值参与比较,我们这里使用area字段进行比较,当area为0时(即北方省份)我们使用的resultMap为noodleResultMap,当area为1时(即南方省份)我们使用的resultMap为riceResultMap,然后我们在下面再分别定义riceResultMap和noodleResultMap,但是注意这两个里边返回值类型都是Province,也都是继承自provinceResultMapper,这里的继承和我们Java中面向对象的继承差不多,父类有的子类继承之后也都自动具备了。这样做时候,我们再来运行刚才的测试代码,结果如下:

和我们想的基本一致。
#延迟加载问题
按照上文我们介绍的方式,每次查询省份的时候都会去查询别名食物等表,有的时候我们可能并不需要这些数据但是却无可避免的要调用这个方法,那么在mybatis中,针对这个问题也提出了相应的解决方案,那就是延迟加载,延迟加载就是当我需要调用这条数据的时候mybatis再去数据库中查询这条数据,比如Province的foods属性,当我调用Province的getFoods()方法来获取这条数据的时候系统再去执行相应的查询操作。OK,针对这个需求mybatis给我们提供了两种不同的方式,一种是在mybatis的配置文件中进行配置,还有一种是针对不同的查询进行单独配置,我们接下来就来看一下这两种不同的配置方式。
##在mybatis的配置文件中进行配置
这种配置有点类似于全局配置,配置成功之后,所有的查询操作都开启了延迟加载。配置方式如下:
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
OK,直接在mybatis-conf.xml中添加如上配置即可。那么这里涉及到两个属性,含义不同,我们来分别看一下:
1.lazyLoadingEnabled表示是否开启延迟加载,默认为false表示没有开启,true表示开启延迟加载。
2.aggressiveLazyLoading表示延迟加载的时候内容是按照层级来延迟加载还是按照需求来延迟加载,默认为true表示按照层级来延迟加载,false表示按照需求来延迟加载。以我们上文查询食物的需求为例,去查询rice表或者noodle表是属于同一级的,但是在我查询到陕西省的时候,这个时候只需要去查询noodle表就可以了,当我查询到广东省的时候再去查询rice表,但是如果aggressiveLazyLoading为true的话,即使我只查询到陕西省,系统也会去把rice和noodle都查一遍,因为它俩属于同一级,而如果aggressiveLazyLoading为false的话,那么当我查询到陕西省的时候,系统就只查询noodle表,当我查询到广东省的时候系统才去查询rice表。
OK,这样配置之后,我们再来看看查询日志:
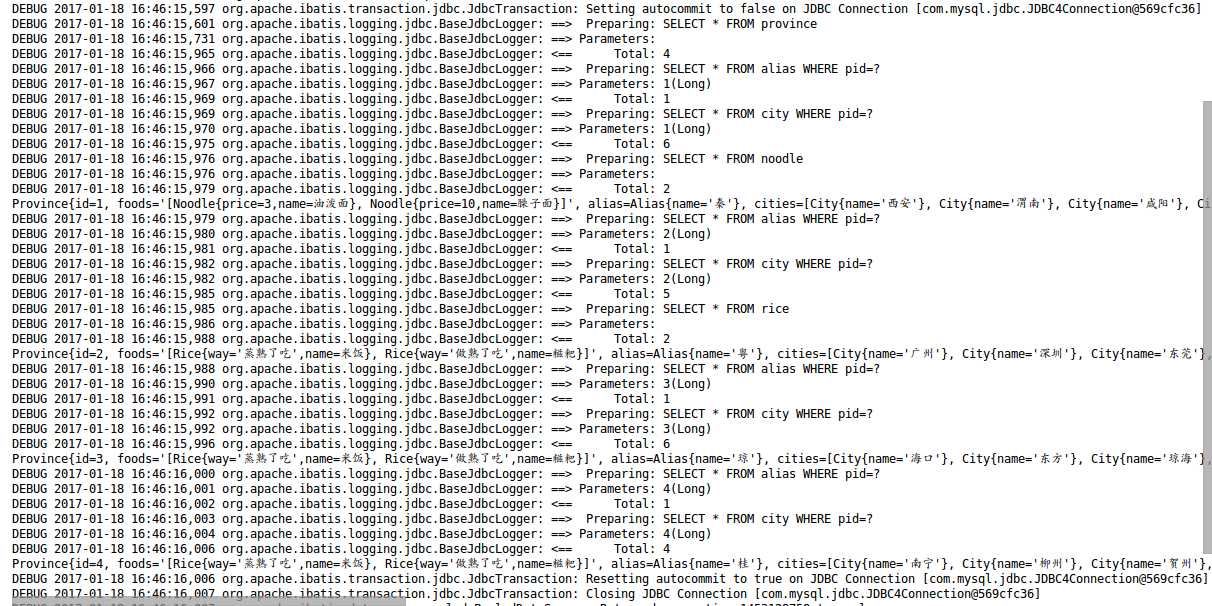
和我们想的一致。
##在针对不同的查询进行配置
OK,上面这种配置算是一种全局配置,如果我们想针对某一条查询开启延迟加载该怎么做呢?比如针对省份别名的查询我想即时加载,而针对城市的查询我想延迟加载该怎么办呢?很简单,在association和collection中配置fetchType属性就可以啦。如上需求,如下配置:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.sang.db.ProvinceMapper">
<resultMap id="provinceResultMapper" type="org.sang.bean.Province">
<id column="id" property="id"/>
<association property="alias" column="id" select="org.sang.db.AliasMapper.findAliasByPid" fetchType="eager"/>
<collection property="cities" column="id" select="org.sang.db.CityMapper.findCityByPid" fetchType="lazy"/>
<discriminator javaType="int" column="area">
<case value="1" resultMap="noodleResultMap"></case>
<case value="2" resultMap="riceResultMap"></case>
</discriminator>
</resultMap>
<resultMap id="noodleResultMap" type="org.sang.bean.Province" extends="provinceResultMapper">
<collection property="foods" column="area" select="org.sang.db.NoodleMapper.findNoodleByArea"/>
</resultMap>
<resultMap id="riceResultMap" type="org.sang.bean.Province" extends="provinceResultMapper">
<collection property="foods" column="area" select="org.sang.db.RiceMapper.findRiceByArea"/>
</resultMap>
<select id="getProvince" resultMap="provinceResultMapper">
SELECT * FROM province
</select>
</mapper>
eager表示即时加载,lazy表示延迟加载。OK,做了如上配置之后,我们再来看看查询日志:
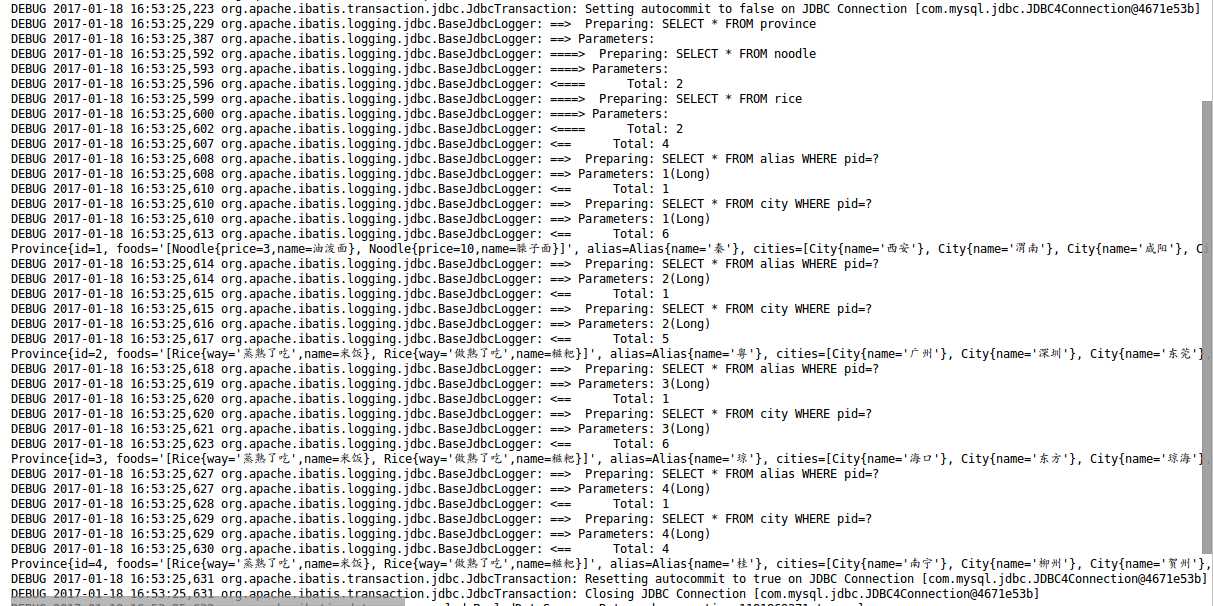
和我们想的基本一致。
#小插曲
关于resultMap我们就说上面那么多。最后我们再来稍微说一下mapper中的sql元素吧。sql元素有点像变量的定义,如果一个表的字段特别多,我们总是写select XXX,XXX,XXX from X总是很麻烦,我们可能希望将一些通用的东西提取成变量然后单独引用,那么这个提取方式也很简单,那就是sql变量,如下:
<sql id="selectAll">
SELECT * FROM user
</sql>
这里是将整个查询语句封装,然后在select中引用即可,如下:
<select id="getUser2" resultType="user">
<include refid="selectAll"/>
</select>
也可以只封装一部分查询语句,如下:
<sql id="selectAll3">
id,username,address,password
</sql>
引用方式如下:
<select id="getUser3" resultType="user">
SELECT
<include refid="selectAll3"/> FROM user
</select>
还可以在封装的时候使用一些变量,如下:
<sql id="selectAll4">
${prefix}.id,${prefix}.username,${prefix}.address
</sql>
注意变量引用方式是$符号哦,不是#,引用方式如下:
<select id="getUser4" resultType="user" parameterType="string">
SELECT
<include refid="selectAll4">
<property name="prefix" value="u"/>
</include> FROM user u
</select>
在property中设置prefix的值。
OK,以上。
本文案例下载:
本文案例GitHub地址https://github.com/lenve/JavaEETest/tree/master/Test27-mybatis7。
参考资料:
《深入浅出MyBatis 技术原理与实战》第四章
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/215902.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
