大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
爬虫基本知识,如何发起请求,进行分析
欢迎大家去博客冰山一树Sankey,浏览效果更好。直接右上角搜索该标题即可


CSDN主页:CSDN主页-冰山一树Sankey
博客园主页:博客园主页-冰山一树Sankey
爬虫一个实战性很强的内容,下面是一些知识点,方便日后复习,具体还要去案例看看,随机应变。这是我的github爬虫仓库github-spider,欢迎大家clone进行学习和体验。
一. 网络爬虫概述
定义
网络蜘蛛(spider)、网络机器人(robot),抓取网络数据的程序
其实就是用Python程序模仿人点击浏览器并访问网站,而且模仿的越像越好,让Web站点无法发现你不是人
爬取数据的目的
1、公司项目测试数据
2、公司业务部门及其他部门所需数据
3、数据分析
企业获取数据方式
1、公司自有数据
2、第三方数据平台购买(tushare,数据堂、贵阳大数据交易所)
3、爬虫爬取数据
Python做爬虫优势
1、Python :请求模块、解析模块丰富成熟,强大的Scrapy网络爬虫框架
2、PHP :对多线程、异步支持不太好
3、JAVA:代码笨重,代码量大
4、C/C++:虽然效率高,但是代码成型慢
爬虫爬取数据步骤
1、确定需要爬取的URL地址
2、由请求模块向URL地址发出请求,并得到网站的响应(网页的源码)
3、从响应内容中提取所需数据
1、所需数据,保存
2、页面中有其他需要继续跟进的URL地址,继续第2步去发请求,如此循环
二. 爬虫请求模块
2.1 headers重构
直接访问网址,网址会直接判断为爬虫程序而非真人操作,可使用下面函数进行模仿
urllib.request.Request(url,headers)
1、url:请求的URL地址
2、headers:添加请求头(爬虫和反爬虫斗争的第一步)
#headers={'User-Agent':'sdfsdfsd'}#百度
User-Agent需要去网上搜索一个进行重构,不过令人高兴的是有直接获取随机User-Agent的库
1、安装fake_useragent类库
2、引用fake_useragent类库
3、创建对象,通过random获取随机User-Agent
使用方法
from fake_useragent import UserAgent
ua=UserAgent()
headers={
'User-Agent': ua.random
}
直接传给header对象即可
2.1 request获取
模块名导入
1、模块名:urllib.request
2、导入方式:
1、import urllib.request
2、from urllib import request
使用方法
urllib.request.urlopen(url,timeout)
参数
1、url:需要爬取的URL地址
2、timeout: 设置等待超时时间,指定时间内未得到响应抛出超时异常
进行headers重构后
req=request.Request(url=url,headers=headers)
res = request.urlopen(req)
小栗子:
向测试网站(http://httpbin.org/get)发起请求,构造请求头并从响应中确认请求头信息
from urllib import request
#定义常用变量 url headers
url='http://httpbin.org/get'
headers={
'User-Agent':'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168
Version/11.50'
}
#1.创建请求对象
req=request.Request(url=url,headers=headers)
#2.获取请求的返回对象
res=request.urlopen(req)
#3.提取响应内容
html=res.read().decode('utf-8')
print(html)
补充:响应对象(response)方法
1、bytes = response.read() # read()得到结果为 bytes 数据类型
2、string = response.read().decode() # decode() 转为 string 数据类型
3、url = response.geturl() # 返回实际数据的URL地址
4、code = response.getcode() # 返回HTTP响应码
5、string.encode() # bytes -> string
6、bytes.decode() # string -> bytes
2.2 URL地址编码模块
当需要获取其他页面就需要进行URL地址进行编码
# 模块名
urllib.parse
# 导入
import urllib.parse
from urllib import parse
常用方法
urllib.parse.urlencode({dict})
URL地址中一个查询参数
# 查询参数:{'wd' : '美女'}
# urlencode编码后:'wd=%e7%be%8e%e5%a5%b3'
# 示例代码
query_string = {
'wd' : '美女'}
result = urllib.parse.urlencode(query_string)
# result: 'wd=%e7%be%8e%e5%a5%b3'
URL地址中多个查询参数
from urllib import parse
params = {
'wd' : '美女',
'pn' : '50'
}
params = parse.urlencode(query_string_dict)
url = 'http://www.baidu.com/s?{}'.format(params)
print(url)
urllib.parse.quote(string)编码
from urllib import parse
string = '美女'
print(parse.quote(string))
# 结果: %E7%BE%8E%E5%A5%B3
#只编译中文
urllib.parse.unquote(string)解码
from urllib import parse
string = '%E7%BE%8E%E5%A5%B3'
result = parse.unquote(string)
print(result)
四. 解析
获得的html页面并没有什么用处,需要使用解析模块进行解析
4.1 正则re解析
正则解析是一个很齐全的方法
#首先导入正则模块
import re
#建立pattern对象
pattern = re.compile('正则表达式',re.S)
#得到解析内容
r_list = pattern.findall(html)
正则表达式写法
贪婪匹配(默认) : .*
非贪婪匹配 : .*?,一般使用.*?
1、想要什么内容在正则表达式中加(.*?),有空格或者不确定的地方就加.*?
2、多个分组,先按整体正则匹配,然后再提取()中数据。结果:[(),(),(),(),()]
正则表达式元字符
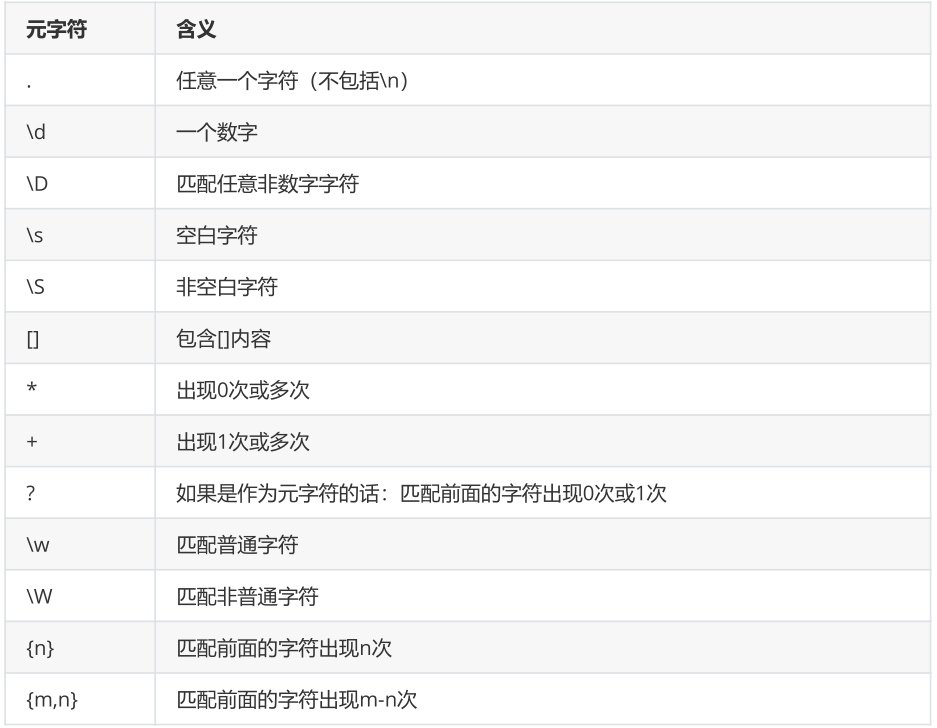
案例:这里以明日方舟贴吧的html进行说明
爬取html页面模块
from urllib import request
from urllib import parse
def get_url(wd):
url='https://tieba.baidu.com/f?{}'
params=parse.urlencode({
'kw':wd})
url=url.format(params)
return url
def request_url(url,filename):
headers = {
'User-Agent': 'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version / 11.50'
}
req=request.Request(url=url,headers=headers)
res = request.urlopen(req)
# 提取响应内容
html = res.read().decode('utf-8')
# 保存数据
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
if __name__ == '__main__':
wd=input('请输入搜索内容:')
url=get_url(wd)
filename=wd+'.html'
request_url(url,filename)
解析模块
import re
# 明日方舟内容解析
with open('明日方舟.html','r',encoding='utf-8') as f:
注意re表达式的写法
pattern=re.compile('<a rel="noopener" href=".*?" title="(.*?)".*?</div><div class="threadlist_author pull_right">.*?<span class="tb_icon_author ".*?title="(.*?)"',re.S)
r_list=pattern.findall(f.read())
# print(r_list[0][1])
if r_list:
for r in r_list:
print("名字:",r[1].replace("主题作者: ",""),"\t",
"标题:",r[0].strip())
4.2. xpath解析
XPath即为XML路径语言,它是一种用来确定XML文档中某部分位置的语言,同样适用于HTML文档的检索
使用流程
1、导入模块
from lxml import etree
2、创建解析对象
parse_html = etree.HTML(html)
3、解析对象调用xpath
r_list = parse_html.xpath('xpath表达式')
常用方法
1、contains() :匹配属性值中包含某些字符串节点
# 查找id属性值中包含字符串 "car_" 的 li 节点
//li[contains(@id,"car_")]
2、text() :获取节点的文本内容
# 查找所有汽车的价格
//li/p[@class="price"]/text()
3.匹配多路径
xpath表达式1 | xpath表达式2 | xpath表达式3
示例
<ul class="CarList">
<li class="bjd" id="car_001" href="http://www.bjd.com/">
<p class="name">布加迪</p>
<p class="model">威航</p>
<p class="price">2500万</p>
<p class="color">红色</p>
</li>
<li class="byd" id="car_002" href="http://www.byd.com/">
<p class="name">比亚迪</p>
<p class="model">秦</p>
<p class="price">15万</p>
<p class="color">白色</p>
</li>
</ul>
1、查找所有的li节点
//li
2、获取所有汽车的名称
//li/p[@class='name']/text()
3、获取比亚迪的型号
//li/p[@class='model']/text()
4、获取每辆车的连接
//ul/li@href
五. 数据保存
解析得到数据需要保存,一般使用csv,mysql,Mongo
5.1 保存csv文件
使用流程
import csv
with open('film.csv','w') as f:
writer = csv.writer(f)
writer.writerow([])
示例
# 单行写入(writerow([]))
import csv
with open('test.csv','w',newline='') as f:
writer = csv.writer(f)
writer.writerow(['步惊云','36'])
writer.writerow(['超哥哥','25'])
# 多行写入(writerows([(),(),()]
import csv
#window下 需要加newline='' 否则会有空行的现象。数据都在但是
#会隔一个空行显示一条数据
with open('test.csv','w',newline='') as f:
writer = csv.writer(f)
writer.writerows([('聂风','36'),('秦霜','25'),('孔慈','30')])
# 存入csv文件 - writerows()
def write_html(self,film_list):
L = []
with open('film.csv','a') as f:
# 初始化写入对象,注意参数f别忘了
writer = csv.writer(f)
for film in film_list:
t = (
film[0].strip(),
film[1].strip(),
film[2].strip()[5:15]
)
L.append(t)
# writerows()参数为列表
writer.writerows(L)
5.2 Mysql数据库
首先需要建立一个数据库表用于存储数据
# 连接到mysql数据库
mysql -uroot -p123456
# 建库建表
create database filmsdb charset utf8;
use maoyandb;
create table films(
name varchar(100),
star varchar(300),
time date
)charset=utf8;
使用流程
导入pymysql
import pymysql
建立连接
self.db=pymysql.connect(host='localhost',user='root',password='123456',database='filmsdb',charset='utf8')
建立游标
self.cursor=self.db.cursor()
提交单条数据
ins = 'insert into films values(%s,%s,%s)'
for film in film_list:
L = (
film[0].strip(),
film[1].strip(),
film[2].strip()
)
self.cursor.execute(ins, L)
# 千万别忘了提交到数据库执行
self.db.commit()
提交多条数据
# mysql - executemany([(),(),()]) 建议使用这种
def write_html(self, film_list):
L = []
ins = 'insert into films values(%s,%s,%s)'
for film in film_list:
t = (
film[0].strip(),
film[1].strip(),
film[2].strip()
)
L.append(t)
self.cursor.executemany(ins, L)
# 千万别忘了提交到数据库执行
self.db.commit()
5.3 Mongo数据库
MongoDB是一个基于磁盘的菲关系型数据库(key-value)数据库,value为json串
常用命令
1.mongo #进入输入库
2.show dbs #查看所有库
3.use 库名
4.show collections #查看当前库的所有集合
5.db.集合名.find().pretty()#带格式的查询
6.db.集合名.count()#统计集合文档个数
7.db.dropDatabase()#删除数据库
使用流程
导入pymongo
import pymysql
建立库
self.conn=pymongo.MongoClient('localhost',27017)
self.db=self.conn['filmsdb']
建立表名
self.myset=self.db['films']
提交数据,注意提交格式为字典格式
def write_html(self, film_list):
L = []
item={
}
for film in film_list:
item['name']=film[0].strip(),
film[1].strip(),
film[2].strip()
L.append(item)
#添加单条数据
self.myset.insert_one(item)
#添加多条数据
self.myset.insert_many(L)
六. requests获取
6.1 常用方式
requests相对于request对象,使用起来更加快速简洁,可相当于request加强版
# 向网站发起请求,并获取响应对象
res = requests.get(url,headers=headers)
常用方法
# print(res.encoding)
# 取字符串
# print(res.text)
# 取字节流
# print(res.content)
# http响应码
# print(res.status_code)
# 实际url
# print(res.url)
6.2 URL地址编码
不仅如此,对于2.3的URL地址编码,也可以直接进行赋值
import requests
baseurl = 'http://tieba.baidu.com/f?'
params = {
'kw' : '古力娜扎吧',
'pn' : '50'
}
headers = {'User-Agent' : 'Mozilla/4.0'}
# 自动对params进行编码,然后自动和url进行拼接,去发请求
res = requests.get(url=baseurl,params=params,headers=headers)
res.encoding = 'utf-8'
print(res.text)
6.3 客户端认证-auth
1、针对于需要web客户端用户名密码认证的网站
2、auth = ('username','password')
3、将auth放在requests.get()方法里面
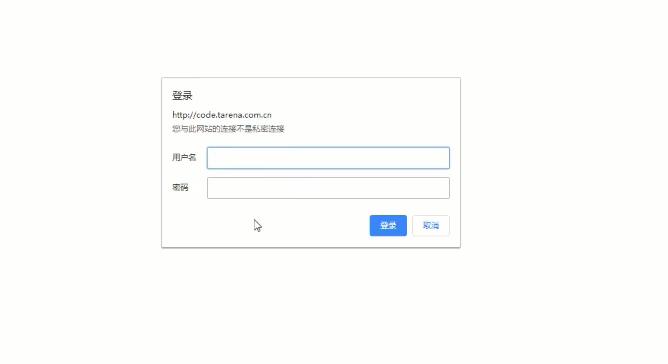
6.3 SSL证书认证参数-verify
1、适用网站: https类型网站但是没有经过 证书认证机构 认证的网站
2、适用场景: 抛出 SSLError 异常则考虑使用此参数适用网站及场景
参数类型
1、verify=True(默认) : 检查证书认证
2、verify=False(常用): 忽略证书认证
# 示例
response = requests.get(
url=url,
params=params,
headers=headers,
verify=False
)
6.4 代理参数-proxies
定义: 代替你原来的IP地址去对接网络的IP地址。
作用: 隐藏自身真实IP,避免被封。
如何获取免费的代理Ip,可取下面下面网址看看,然后编写爬虫爬取并测试
- 89
- 芝麻
- 快代理
- 西刺代理
- 全网代理
- 代理精灵
import requests
url='http://httpbin.org/get'
headers={
'User-Agent':'Mozilla/5.0'}
#定义代理,在代理网站中找免费ip
proxies={
'http':'http://110.89.122.28:8080',
'https':'https://110.89.122.28:8080'
}
html=requests.get(url=url,proxies=proxies,headers=headers,timeout=5).text
print(html)
6.5 requests.post()参数
适用场景:Post类型请求的网站
response = requests.post(url,data=data,headers=headers)
data参数 :post数据(Form表单数据-字典格式)
七. 动态数据抓取
7.1 爬取方法
动态数据的抓取相对于静态数据来说,就是url不是网址具体的url,具体的url需要用调试工具进行调试,然后选择网络,XHR,下面的动态加载的内容就是由web后台发过来的动态数据,其格式为json格式
这里以豆瓣为例
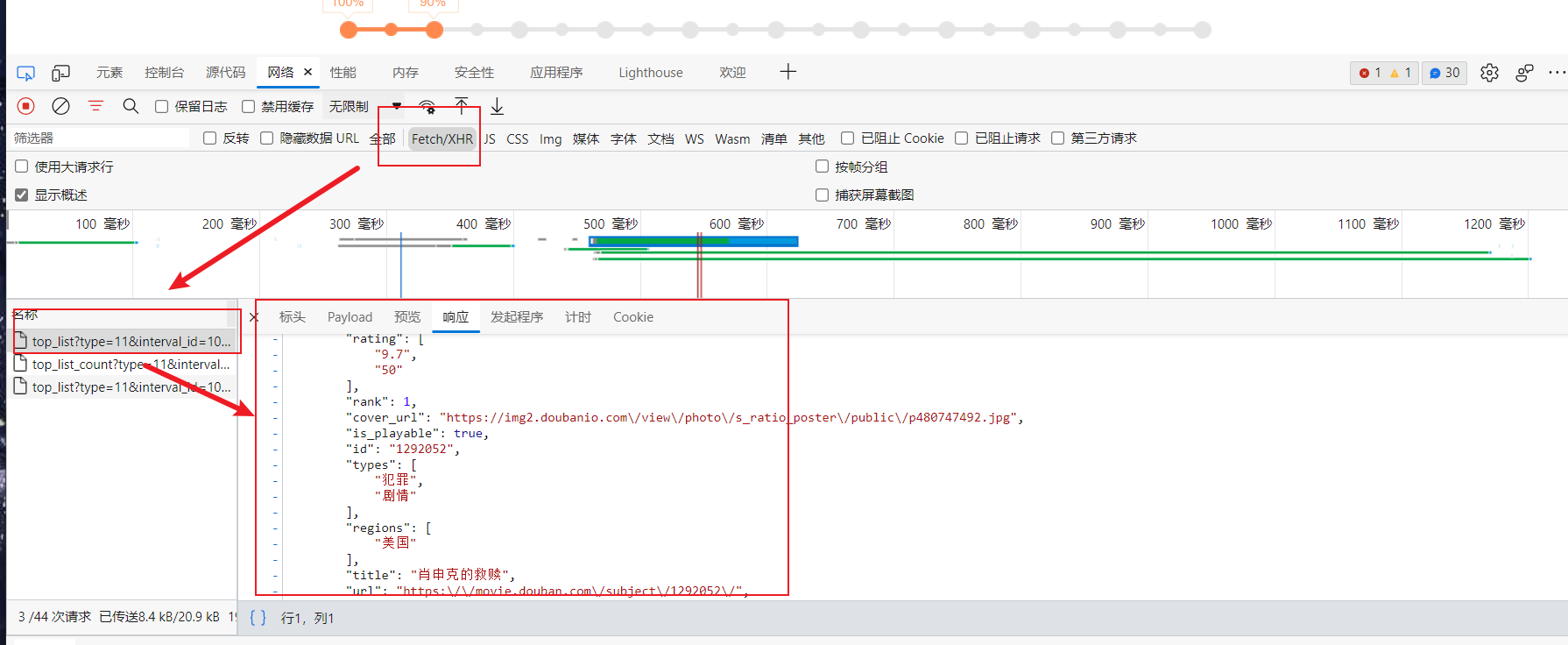
标头里就是具体的json数据的请求url
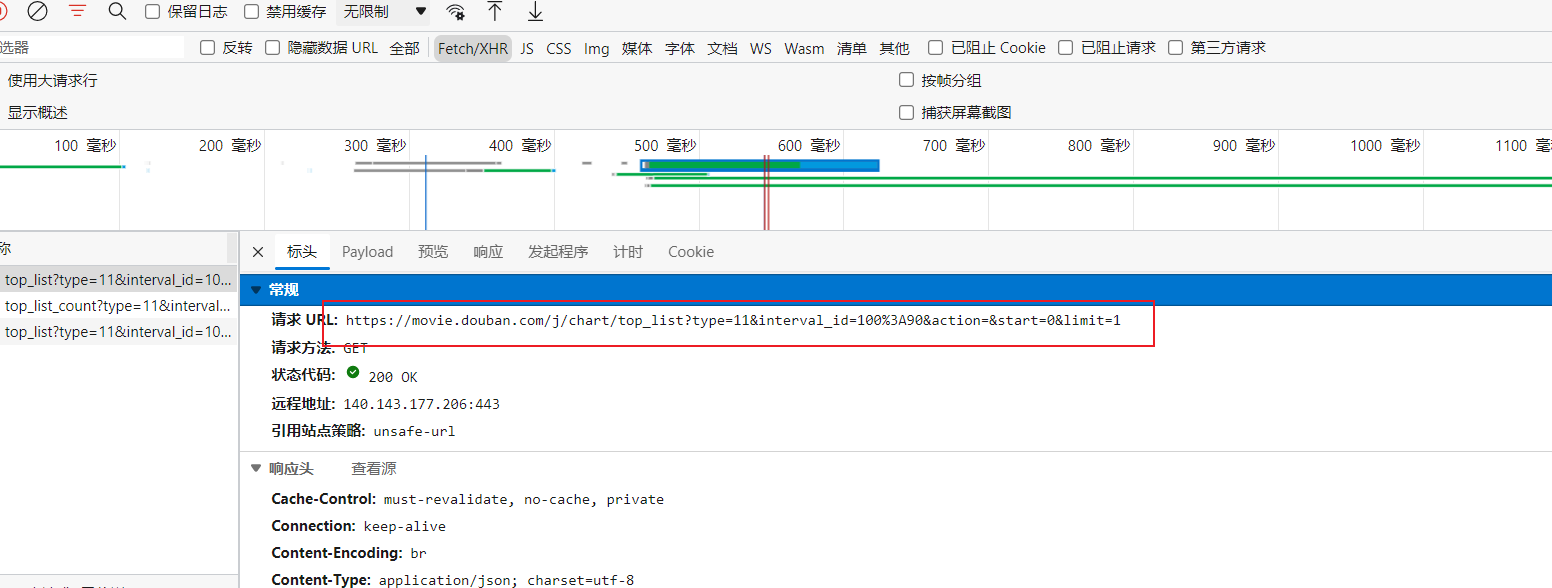
将url用于requests.get()请求响应就会得到其数据,然后进行解析即可。
下面是具体的响应数据提取方法
7.2 json模块
json.loads(json)
作用:把json格式的字符串转为Python数据类型——字典
示例:html_json = json.loads(res.text)
json.dumps(python)
作用:把 python 类型 转为 json 类型
json.dump(python,f,ensure_ascii=False)
作用:将python的格式类型也就是字典,转换为json并存到文件里
json.dump(python,f,ensure_ascii=False)
第1个参数: python类型的数据(字典,列表等)
第2个参数: 文件对象
第3个参数: ensure_ascii=False # 序列化时编码
json.load(f)
作用:将json文件读取,并转为python类型
对于上面的get请求后,可通requests.get().json()获得json数据,这是最简单的方法,
也可以通过requests.get().text,然后再进行loads方法
7.3 jsonpath模块
对于得到的json数据,我们可以一层一层的去提取,但是如果层数太多的化,提取就会很困难,而使用jsonpath模块就可以更加key和下标来批量提取value
安装
jsonpath是第三方模块,需要额外安装,直接使用命令pip install jsonpath即可安装使用了。
使用
from jsonpath import jsonpath
#jsondata就是所取进行解析的json数据
ret = jsonpath(jsondata, 'jsonpath语法规则字符串')
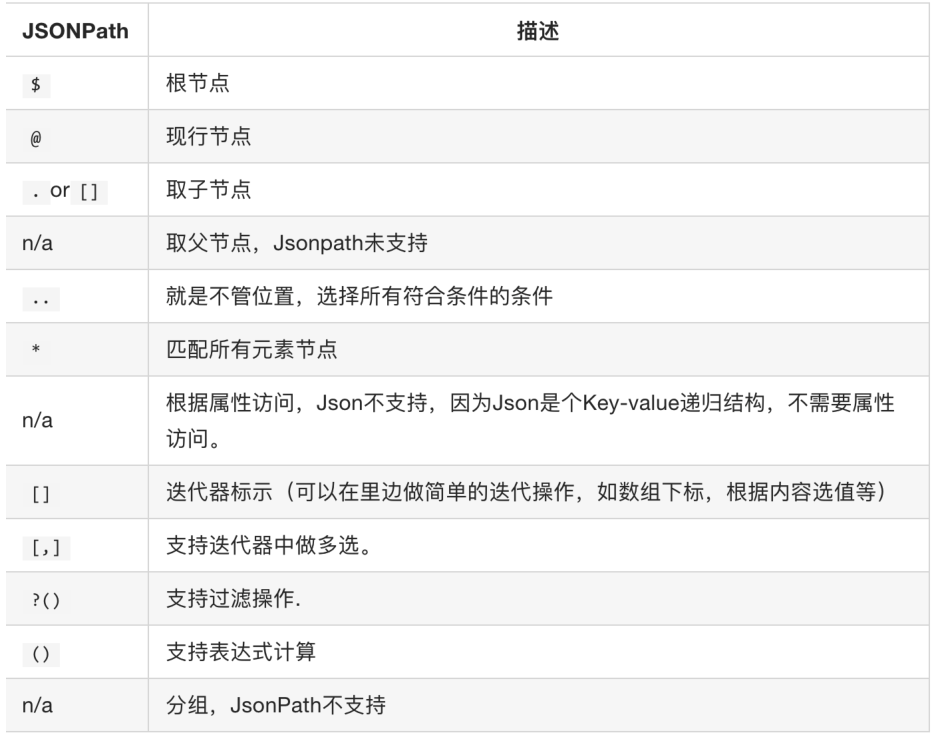
这里举个使用例子,提取python
import jsonpath
data={'key1':{'key2':{'key3':{'key4':{'key5':'key6':{'key7':python}}}}}}
#进行提取
result=jsonpath.jsonpath(data,'$.key1.key2.key3.key4.key5.key6.key7')[0]
#或者
result=jsonpath.jsonpath(data,'$..key7')[0]
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186480.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
