大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
kubernetes之prometheus监控第二篇-alertmanager监控告警:
在前期的博文中,我已经简单的介绍过了prometheus的安装,以及通过grafana来实施监控。这篇博文,我们更深入的介绍一下prometheus的监控。本篇博文主要分为以下几个知识点:
1. 使用prometheus监控ceph存储;
2. 学习简单的PromQL语言,在grafana里面根据业务自定义dashboard;
3. alertmanager自定义告警的配置;讲述邮件告警和企业微信告警;
1. 使用prometheus监控ceph存储:
使用prometheus监控ceph存储还是比较简单的,在任何一台k8s节点上面运行一个独立的docker镜像即可;
首先在github上面下载ceph-exporter的压缩包:
https://github.com/digitalocean/ceph_exporter/releases/tag/2.0.0-jewel
下载下来之后解压目录,打包镜像、推送镜像到私有仓库、拷贝ceph配置到本地、运行ceph镜像容器:
[root@node-01 ~]# ll
total 16620
-rw-------. 1 root root 1270 Apr 5 00:24 anaconda-ks.cfg
-rw-r--r-- 1 root root 2571 May 8 18:23 ceph-deploy-ceph.log
drwxr-xr-x 6 root root 289 May 14 10:05 ceph_exporter
drwxr-xr-x 3 root root 39 May 14 09:12 ceph_exporter-2.0.0-jewel
-rw-r--r-- 1 root root 317324 May 14 09:06 ceph_exporter-2.0.0-jewel.tar.gz
-rw-r--r--. 1 root root 130 Apr 17 14:22 Dockerfile
drwxr-xr-x. 3 root root 52 Apr 30 15:07 gy
drwxr-xr-x. 2 root root 24 Apr 30 19:01 jenkins-slae
-rw-r--r-- 1 root root 12209 May 15 14:18 jira.py
drwxr-xr-x. 2 root root 24 Apr 29 14:45 jnlp
-rw-r--r--. 1 root root 118 Apr 17 14:23 kibana.yml
drwxr-xr-x 2 root root 244 May 8 15:46 my-cluster
-rw-r--r--. 1 root root 16574127 Apr 28 13:39 pinpoint-agent.zip
-rw-r--r-- 1 root root 90250 May 9 15:51 v2.13.1
[root@node-01 ~]#
# 构建镜像并上传镜像到私有仓库
[root@node-01 ceph_exporter-2.0.0-jewel]# docker build -t k8s.harbor.test.site/system/ceph_exporter:latest ./
[root@node-01 ceph_exporter-2.0.0-jewel]# docker push k8s.harbor.test.site/system/ceph_exporter:v2
# 运行一个ceph-exporter的容器,需要提前把ceph管理机器上面的ceph.conf和ceph.client.admin.keyring文件拷贝到/software目录,这两个文件一个是ceph的配置文件
里面有ceph的配置内容,包括mon节点ip等,另外一个是认证信息;
[root@node-01 ceph_exporter-2.0.0-jewel]# docker run -d -v /software/:/etc/ceph --net=host -p 9128:9128 k8s.harbor.test.site/system/ceph_exporter启动完成ceph-exporter容器之后,在宿主机就会有9128端口暴露(因为启动容器的时候配置了–net=host参数),可以通过测试curl http://ip:9128/metrics 看看是否有metrics数据。如果有数据的话,就可以配置prometheus了;
# 在prometheus.yml文件中增加ceph-exporter的配置即可;
prometheus.yml: |-
global:
scrape_interval: 1m
evaluation_interval: 1m
rule_files:
- "/etc/prometheus/prometheus.rules"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: "traefik"
static_configs:
- targets: ['traefik2-dashboard:80']
- job_name: 'ceph-exporter'
static_configs:
- targets: ['10.83.32.229:9128']
labels:
alias: ceph-exporter
- job_name: "mysql"
# 重新更新configmap,并且激活配置不用重启服务
kubectl replace -f /data/prometheus2/k8s-prometheus-grafana/prometheus/configmap.yaml --force
curl -X POST "http://10.200.66.236:9090/-/reload"
通过打开prometheus的监控页面,可以看到ceph的存储已经有metrics的数据了。然后配置grafana,
We will use dashboard IDs 917, 926 and 923 when importing dashboards on Grafana.
2. 学习简单的PromQL语言,在grafana里面根据业务自定义dashboard;
前面我们讲到grafana的dashboard,都是在官方网站下载别人已经配置好的dashboard.比如k8s node监控的dashboard等,那如何自己制作dashboard呢。想要实现自己定义dashboard,必须要会一些简单的PromQL语言。下面讲一下一些简单的PromQL语言:
Prometheus通过指标名称(metrics name)以及对应的一组标签(labelset)唯一定义一条时间序列。指标名称反映了监控样本的基本标识,而label则在这个基本特征上为采集到的数据提供了多种特征维度。用户可以基于这些特征维度过滤,聚合,统计从而产生新的计算后的一条时间序列。
PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。可以这么说,PromQL是Prometheus所有应用场景的基础,理解和掌握PromQL是Prometheus入门的第一课。
查询时间序列
# 通过prometheus查询的语句和结果
http_requests_total
Element Value
http_requests_total{code="200",handler="prometheus",instance="10.83.32.226:6443",job="kubernetes-apiservers",method="get"} 546
http_requests_total{code="200",handler="prometheus",instance="10.83.32.227:6443",job="kubernetes-apiservers",method="get"} 548
http_requests_total{code="200",handler="prometheus",instance="10.83.32.228:6443",job="kubernetes-apiservers",method="get"} 547
http_requests_total{code="200",handler="prometheus",instance="localhost:9090",job="prometheus",method="get"} 134
http_requests_total{code="200",handler="prometheus",instance="my-mysql:9104",job="mysql",method="get"} 133
http_requests_total{code="200",handler="query_range",instance="localhost:9090",job="prometheus",method="get"} 59
http_requests_total{code="200",handler="series",instance="localhost:9090",job="prometheus",method="get"} 2
http_requests_total{code="200",handler="static",instance="localhost:9090",job="prometheus",method="get"} 3
http_requests_total{code="200",handler="targets",instance="localhost:9090",job="prometheus",method="get"}
# PromQL还支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配和正则匹配。
# PromQL支持使用=和!=两种完全匹配模式:可以通过key=value的模式匹配固定的查询内容
http_requests_total{instance="localhost:9090"}
Element Value
http_requests_total{code="200",handler="graph",instance="localhost:9090",job="prometheus",method="get"} 1
http_requests_total{code="200",handler="label_values",instance="localhost:9090",job="prometheus",method="get"} 1
http_requests_total{code="200",handler="prometheus",instance="localhost:9090",job="prometheus",method="get"} 136
http_requests_total{code="200",handler="query",instance="localhost:9090",job="prometheus",method="get"} 2
http_requests_total{code="200",handler="query_range",instance="localhost:9090",job="prometheus",method="get"} 59
http_requests_total{code="200",handler="series",instance="localhost:9090",job="prometheus",method="get"} 2
http_requests_total{code="200",handler="static",instance="localhost:9090",job="prometheus",method="get"} 4
http_requests_total{code="200",handler="targets",instance="localhost:9090",job="prometheus",method="get"}
范围查询:
直接通过类似于PromQL表达式httprequeststotal查询时间序列时,返回值中只会包含该时间序列中的最新的一个样本值,这样的返回结果我们称之为瞬时向量。而相应的这样的表达式称之为__瞬时向量表达式。
而如果我们想过去一段时间范围内的样本数据时,我们则需要使用区间向量表达式。区间向量表达式和瞬时向量表达式之间的差异在于在区间向量表达式中我们需要定义时间选择的范围,时间范围通过时间范围选择器[]进行定义。例如,通过以下表达式可以选择最近5分钟内的所有样本数据:
http_requests_total{instance="localhost:9090"}[5m]
http_requests_total{code="200",handler="graph",instance="localhost:9090",job="prometheus",method="get"} 1 @1558010956.845
1 @1558011016.845
1 @1558011076.845
# 除了使用m表示分钟以外,PromQL的时间范围选择器支持其它时间单位:
s - 秒
m - 分钟
h - 小时
d - 天
w - 周
y - 年时间位移操作:
而如果我们想查询,5分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢? 这个时候我们就可以使用位移操作,位移操作的关键字为offset。
http_requests_total{instance="localhost:9090"} offset 5m
Element Value
http_requests_total{code="200",handler="prometheus",instance="localhost:9090",job="prometheus",method="get"} 135使用聚合操作:
# 查询系统所有http请求的总量
sum(http_requests_total{instance="localhost:9090"})
# 查询cpu的平均值,并且按照cpu的模式排序
avg(node_cpu_seconds_total) by (mode)
Element Value
{mode="iowait"} 875.1003124999999
{mode="irq"} 0
{mode="nice"} 4.0337499999999995
{mode="softirq"} 21.6546875
{mode="steal"} 0
{mode="system"} 414.46062499999994
{mode="user"} 1247.3525000000002
{mode="idle"} 21781.5896875
# 按照主机查询各个主机的CPU使用率
sum(sum(irate(node_cpu_seconds_total{mode!='idle'}[5m])) / sum(irate(node_cpu_seconds_total[5m]))) by (instance) 更多关于PromQL的语法可以参考网址,里面有详细的学习资料:
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/promql/prometheus-query-language#fan-wei-cha-xun:
紧接着我们根据上面学习的简单的PromQL语法来制作一个Dashboard,把一个业务系统的pod资源专门放在一个Dashboard里面;
# cim业务网络流量的
sum (rate (container_network_receive_bytes_total{image!="",name=~"^k8s_.*",pod_name=~"^cim.*"}[1m])) by (pod_name)
sum (rate (container_network_transmit_bytes_total{image!="",name=~"^k8s_.*",pod_name=~"^cim.*"}[1m])) by (pod_name)
# cim业务内存使用率
sum (container_memory_working_set_bytes{image!="",name=~"^k8s_.*",pod_name=~"^cim.*"}) by (pod_name)
# cim业务cpu负载
sum (rate (container_cpu_usage_seconds_total{image!="",name=~"^k8s_.*",pod_name=~"^cim.*"}[1m])) by (pod_name)
#
3. alertmanager自定义告警的配置;讲述邮件告警和企业微信告警;
prometheus监控可以通过grafana将数据优美的展示出来,但是IT监控最主要的还是告警;如果出现故障运维人员需要第一时间能够收到告警才可以;prometheus有一个组件alertmanager来实现告警;关于告警有几个概念需要和大家聊一下:
Alertmanager处理由类似Prometheus服务器等客户端发来的警报,之后需要删除重复、分组,并将它们通过路由发送到正确的接收器,比如电子邮件、Slack等。Alertmanager还支持沉默和警报抑制的机制。
分组:
分组是指当出现问题时,Alertmanager会收到一个单一的通知,而当系统宕机时,很有可能成百上千的警报会同时生成,这种机制在较大的中断中特别有用。
例如,当数十或数百个服务的实例在运行,网络发生故障时,有可能服务实例的一半不可达数据库。在告警规则中配置为每一个服务实例都发送警报的话,那么结果是数百警报被发送至Alertmanager。
但是作为用户只想看到单一的报警页面,同时仍然能够清楚的看到哪些实例受到影响,因此,人们通过配置Alertmanager将警报分组打包,并发送一个相对看起来紧凑的通知。
分组警报、警报时间,以及接收警报的receiver是在配置文件中通过路由树配置的。
抑制:
抑制是指当警报发出后,停止重复发送由此警报引发其他错误的警报的机制。
例如,当警报被触发,通知整个集群不可达,可以配置Alertmanager忽略由该警报触发而产生的所有其他警报,这可以防止通知数百或数千与此问题不相关的其他警报。
抑制机制可以通过Alertmanager的配置文件来配置
沉默:
沉默是一种简单的特定时间静音提醒的机制。一种沉默是通过匹配器来配置,就像路由树一样。传入的警报会匹配RE,如果匹配,将不会为此警报发送通知。
沉默机制可以通过Alertmanager的Web页面进行配置。
alertmanager路由:
路由块定义了路由树及其子节点。如果没有设置的话,子节点的可选配置参数从其父节点继承。
每个警报进入配置的路由树的顶级路径,顶级路径必须匹配所有警报(即没有任何形式的匹配)。然后匹配子节点。如果continue的值设置为false,它在匹配第一个孩子后就停止;如果在子节点匹配,continue的值为true,警报将继续进行后续兄弟姐妹的匹配。如果警报不匹配任何节点的任何子节点(没有匹配的子节点,或不存在),该警报基于当前节点的配置处理。
接收器 receiver
顾名思义,警报接收的配置。比如邮件配置和企业微信配置等
报警规则:
报警规则允许你定义基于Prometheus语言表达的报警条件,并发送报警通知到外部服务。一般在prometheus的配置文件里面配置。
FOR子句使得Prometheus等待第一个传进来的向量元素(例如高HTTP错误的实例),并计数一个警报。如果元素是active,但是没有firing的,就处于pending状态。
LABELS(标签)子句允许指定一组附加的标签附到警报上。现有的任何标签都会被覆盖,标签值可以被模板化。
ANNOTATIONS(注释)子句指定另一组未查明警报实例的标签,它们被用于存储更长的其他信息,例如警报描述或者链接,注释值可以被模板化。
发送警报通知
Prometheus可以周期性的发送关于警报状态的信息到Alertmanager实例,然后Alertmanager调度来发送正确的通知。该Alertmanager可以通过-alertmanager.url命令行flag来配置。
首先启动一个alertmanager的deployment,配置清单如下:
# 第一个文件是alertmanager的configmap,其中定义了邮件和企业微信通知
[root@master-01 altermanager]# cat altermanager-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager-config
namespace: kube-system
data:
config.yml: |-
global:
resolve_timeout: 5m #该参数定义了当Alertmanager持续多长时间未接收到告警后标记告警状态为resolved(已解决)
smtp_smarthost: 'smtp.exmail.qq.com:25'
smtp_from: 'gaoyang@test.cn'
smtp_auth_username: 'gaoyang@test.cn'
smtp_auth_password: '111111'
smtp_hello: 'test.cn'
smtp_require_tls: false
wechat_api_url: "https://qyapi.weixin.qq.com/cgi-bin/" #企业微信的api参数,后续会介绍
wechat_api_secret: "dfadfadsfsdgfsdgdfhgfhggsfadf"
wechat_api_corp_id: "1223435sdfsdfsd"
templates:
- '/usr/local/prometheus/alertmanager/template/default.tmpl'
route:
receiver: 'alert-emailer' #定义第一个邮件接受器
group_by: ['alertname','priority']
group_wait: 10s #发送一组新的警报的初始等待时间,也就是初次发警报的延时
group_interval: 5m #初始警报组如果已经发送,需要等待多长时间再发送同组新产生的其他报警
repeat_interval: 30m #如果警报已经成功发送,间隔多长时间再重复发送
routes:
- receiver: email
group_wait: 10s
match: #这里定义了匹配的标签,需要和prometheus里面的规则文件的标签一致,也就是有team: node标签的告警,通过邮件来告警,如果有team: node2标签的通过企业微信来告警
team: node
- receiver: wechat
group_wait: 10s
match:
team: node2
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
to_user: "GaoYang" #企业微信的用户ID
agent_id: "1000002" # 企业微信的app应用ID,需要提前在企业微信里面创建应用;
corp_id: "1223435sdfsdfsd" # 企业微信公司ID
api_secret: "dfadfadsfsdgfsdgdfhgfhggsfadf"
- name: 'alert-emailer'
email_configs:
- to: 2145436855@qq.com
send_resolved: true
- name: email
email_configs:
- to: 'zgui2220@163.com'
send_resolved: true
# 第二个文件是定义企业微信发送的模板格式文件
[root@master-01 altermanager]# cat altermanager-template-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: null
name: alertmanager-templates
namespace: kube-system
data:
default.tmpl: |
{
{ define "wechat.default.message" }}
{
{ range .Alerts }}
========start==========
告警程序:prometheus_alert
告警级别:{
{ .Labels.severity }}
告警类型:{
{ .Labels.alertname }}
故障主机: {
{ .Labels.instance }}
告警主题: {
{ .Annotations.summary }}
告警详情: {
{ .Annotations.description }}
触发时间: {
{ .StartsAt.Format "2006-01-02 15:04:05" }}
========end==========
{
{ end }}
{
{ end }}
[root@master-01 altermanager]#
#定义一个持久化的存储
[root@master-01 altermanager]# cat altermanager-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: alertmanager
namespace: kube-system
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
[root@master-01 altermanager]#
#定义一个deployment文件
[root@master-01 altermanager]# cat altermanager-Deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
name: alertmanager
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: prom/alertmanager:latest
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: config-volume #挂载配置文件
mountPath: /etc/alertmanager
- name: alertmanager
mountPath: /alertmanager
- name: alertmanager-templates #挂载模板文件
mountPath: /usr/local/prometheus/alertmanager/template/
volumes:
- name: config-volume
configMap:
name: alertmanager-config
- name: alertmanager-templates
configMap:
name: alertmanager-templates
- name: alertmanager
persistentVolumeClaim:
claimName: alertmanager
# 定义一个ingress
[root@master-01 altermanager]# cat altermanager-ing.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: altermanager
namespace: kube-system
spec:
rules:
- host: k8s.altermanager.test.site
http:
paths:
- path: /
backend:
serviceName: alertmanager
servicePort: 9093
# 定义一个时区文件,更正容器中的时区
[root@master-01 altermanager]# cat presetpod.yaml
apiVersion: settings.k8s.io/v1alpha1
kind: PodPreset
metadata:
name: alert-timezone2
namespace: kube-system
spec:
selector:
matchLabels:
app: alertmanager
env:
- name: TZ
value: Asia/Shanghai
# 定义一个服务文件
[root@master-01 altermanager]# cat alertmanager-Service.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-system
annotations:
prometheus.io/scrape: 'true'
prometheus.io/path: /
prometheus.io/port: '8080'
spec:
selector:
app: alertmanager
type: NodePort
ports:
- port: 9093
targetPort: 9093
nodePort: 31000
[root@master-01 altermanager]#
另外说下Alert的三种状态:
1. pending:警报被激活,但是低于配置的持续时间。这里的持续时间即rule里的FOR字段设置的时间。改状态下不发送报警。
2. firing:警报已被激活,而且超出设置的持续时间。该状态下发送报警。
3. inactive:既不是pending也不是firing的时候状态变为inactive
配置prometheus的告警规则
[root@master-01 prometheus]# cat configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-system
data:
prometheus.rules: |-
groups:
- name: node-resource #规则组名称
rules:
- alert: InstanceDown #单个规则的名称
expr: up == 0 #匹配规则,就是prometheus里面的targets属于down的状态
for: 1m #持续时间
labels: #标签
team: node # 自定义标签,和前面的alertmanager configmap里面的标签关联起来
annotations: # 告警正文
description: '{
{ $labels.instance }} of job {
{ $labels.job }} has been down for more than 1 minutes.'
summary: Instance {
{ $labels.instance }} down
- alert: NodeFilesystemUsage
expr: (node_filesystem_size_bytes{device="rootfs"} - node_filesystem_free_bytes{device="rootfs"}) / node_filesystem_size_bytes{device="rootfs"} * 100 > 90
for: 2m
labels:
team: node
annotations:
summary: "{
{$labels.instance}}: High Filesystem usage detected"
description: "{
{$labels.instance}}: Filesystem usage is above 80% (current value is: {
{ $value }}"
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 90
for: 2m
labels:
team: node
annotations:
summary: "{
{$labels.instance}}: High Memory usage detected"
description: "{
{$labels.instance}}: Memory usage is above 20% (current value is: {
{ $value }}"
- alert: NodeCPUUsage
expr: (100 - (avg by (instance) (irate(node_cpu{job="kubernetes-node-exporter",mode="idle"}[5m])) * 100)) > 90
for: 2m
labels:
team: node
annotations:
summary: "{
{$labels.instance}}: High CPU usage detected"
description: "{
{$labels.instance}}: CPU usage is above 80% (current value is: {
{ $value }}"
- alert: node_memory_Dirty
expr: node_memory_Dirty_bytes>200000
for: 2m
labels:
team: node
annotations:
summary: "{
{$labels.instance}}: node_memory_dirty_bytes detected"
description: "{
{$labels.instance}}: node_memory_dirty_bytes is above 200K (current value is: {
{ $value }}"
prometheus.yml: |-
global:
scrape_interval: 1m #Server端抓取数据的时间间隔
evaluation_interval: 1m #评估报警规则的时间间隔
rule_files:
- "/etc/prometheus/prometheus.rules" #定义告警文件,这个文件是通过configmap映射到容器的etc目录
4. 通过企业微信创建企业和应用;
1. 申请一个企业微信号:
2. 管理员登录企业微信web管理控制台:
3. 创建接收消息的子部门:
4. 添加子部门成员:
5. 新建“自建”->“创建应用”:
6. 点创建应用完成后,会生成AgentId和Secret:
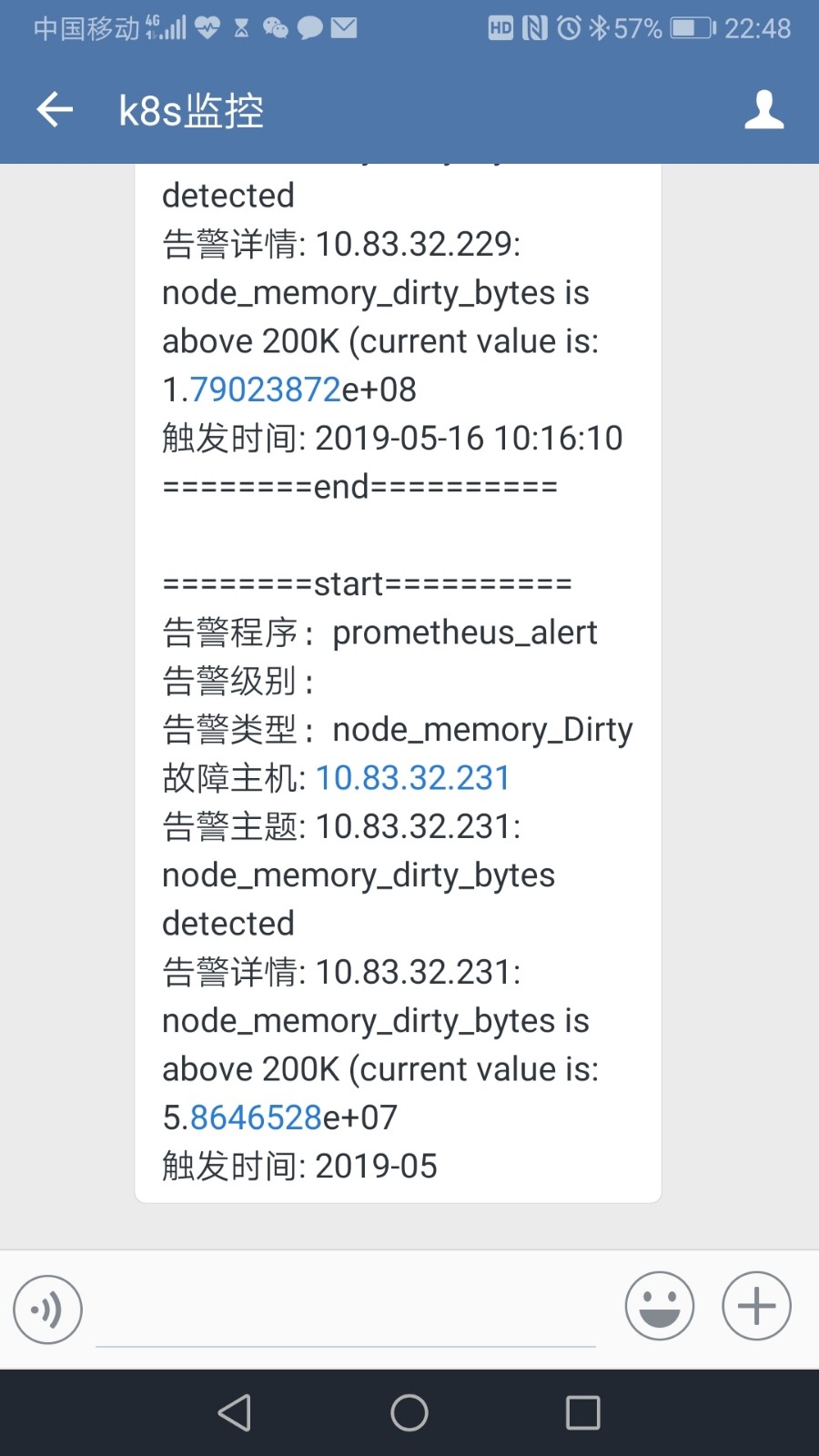
7. 企业微信收到告警的效果

关于博文详细内容请关注我的个人微信公众号 “云时代IT运维”,本公众号旨在共享互联网运维新技术,新趋势; 包括IT运维行业的咨询,运维技术文档分享。重点关注devops、jenkins、zabbix监控、kubernetes、ELK、各种中间件的使用,比如redis、MQ等;shell和python等运维编程语言;本人从事IT运维相关的工作有十多年。2008年开始专职从事Linux/Unix系统运维工作;对运维相关技术有一定程度的理解。本公众号所有博文均是我的实际工作经验总结,基本都是原创博文。我很乐意将我积累的经验、心得、技术与大家分享交流!希望和大家在IT运维职业道路上一起成长和进步;

转载于:https://blog.51cto.com/zgui2000/2396797
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186328.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
