大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
基本原理
在信息论中,熵是对不确定性的一种度量。信息量越大,不确定性就越小,熵也就越小;信息量越小,不确定性越大,熵也越大。
根据熵的特性,可以通过计算熵值来判断一个事件的随机性及无序程度,也可以用熵值来判断某个指标的离散程度,指标的离散程度越大,该指标对综合评价的影响(权重)越大。比如样本数据在某指标下取值都相等,则该指标对总体评价的影响为0,权值为0.
熵权法是一种客观赋权法,因为它仅依赖于数据本身的离散性。
熵权法步骤
第一步:指标的归一化处理(异质指标同质化):由于各项指标的计量单位并不统一,因此在用他们计算综合指标前,先要进行标准化处理,即把指标的绝对值转化为相对值,从而解决各项不同质指标值的同质化问题。
另外,正向指标和负向指标数值代表的含义不同(正向指标数值越高越好,负向指标数值越低越好),因此,对于正向、负向指标需要采用不同的算法进行数据标准化处理。
正向指标: x i j ′ = x i j − min { x 1 j , … , x n j } max { x 1 j , … , x r j } − min { x 1 j , … , x n j } x_{i j}^{\prime}=\frac{x_{i j}-\min \left\{x_{1 j}, \ldots, x_{n j}\right\}}{\max \left\{x_{1 j}, \ldots, x_{r j}\right\}-\min \left\{x_{1 j}, \ldots, x_{n j}\right\}} xij′=max{
x1j,…,xrj}−min{
x1j,…,xnj}xij−min{
x1j,…,xnj}
负向指标: x i j ′ = max { x 1 j , … , x n j } − x i j max { x 1 j , … , x r j } − min { x 1 j , … , x n j } x_{i j}^{\prime}=\frac{\max \left\{x_{1 j}, \ldots, x_{n j}\right\}-x_{i j}}{\max \left\{x_{1 j}, \ldots, x_{r j}\right\}-\min \left\{x_{1 j}, \ldots, x_{n j}\right\}} xij′=max{
x1j,…,xrj}−min{
x1j,…,xnj}max{
x1j,…,xnj}−xij
第二步:计算第j项指标下第i个样本值占该指标的比重 p i j = x i j ∑ i = 1 n x i j , i = 1 , ⋯ , n , j = 1 , ⋯ , m p_{i j}=\frac{x_{i j}}{\sum_{i=1}^{n} x_{i j}}, \quad i=1, \cdots, n, j=1, \cdots, m pij=∑i=1nxijxij,i=1,⋯,n,j=1,⋯,m
第三步:计算第j项指标的熵值 e j = − k ∑ i = 1 n p i j ln ( p i j ) , j = 1 , ⋯ , m e_{j}=-k \sum_{i=1}^{n} p_{i j} \ln \left(p_{i j}\right), \quad j=1, \cdots, m ej=−ki=1∑npijln(pij),j=1,⋯,m 其中 k = 1 / ln ( n ) > 0 k=1 / \ln (n)>0 k=1/ln(n)>0 ,满足 e j ≥ 0 e_{j} \geq 0 ej≥0。
第四步:计算信息熵冗余度(差异) d j = 1 − e j , j = 1 , ⋯ , m d_{j}=1-e_{j}, \quad j=1, \cdots, m dj=1−ej,j=1,⋯,m
第五步:计算各项指标的权重 w j = d j ∑ j = 1 m d j , j = 1 , ⋯ , m w_{j}=\frac{d_{j}}{\sum_{j=1}^{m} d_{j}}, \quad j=1, \cdots, m wj=∑j=1mdjdj,j=1,⋯,m
第六步:计算各样本的综合得分 s i = ∑ j = 1 m w j x i j , i = 1 , ⋯ , n s_{i}=\sum_{j=1}^{m} w_{j} x_{i j}, \quad i=1, \cdots, n si=j=1∑mwjxij,i=1,⋯,n 其中, x i j x_{i j} xij 为标准化后的数据。
脚本实现
数据读入。
library(forecast)
library(XLConnect)
sourui <- read.csv("E:/R/operation/train.csv",header = T)
部分数据展现
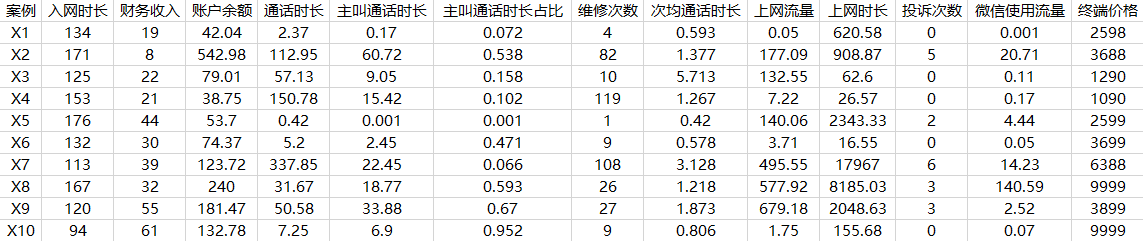

索引列删除
sourui$案例 <- NULL
第一步:归一化处理。
min.max.norm <- function(x){
(x-min(x))/(max(x)-min(x))
}
max.min.norm <- function(x){
(max(x)-x)/(max(x)-min(x))
}
sourui_1 <- apply(sourui[,-c(7,11)],2,min.max.norm) #正向指标
sourui_2 <- apply(sourui[,c(7,11)],2,max.min.norm) #负向指标
sourui_t <- cbind(sourui_1,sourui_2)
第二步:求出所有样本对指标Xj的贡献总量
first1 <- function(data)
{
x <- c(data)
for(i in 1:length(data))
x[i] = data[i]/sum(data[])
return(x)
}
dataframe <- apply(sourui_t,2,first1)
第三步:将上步生成的矩阵每个元素变成每个元素与该ln(元素)的积并计算信息熵。
first2 <- function(data)
{
x <- c(data)
for(i in 1:length(data)){
if(data[i] == 0){
x[i] = 0
}else{
x[i] = data[i] * log(data[i])
}
}
return(x)
}
dataframe1 <- apply(dataframe,2,first2)
k <- 1/log(length(dataframe1[,1]))
d <- -k * colSums(dataframe1)
第四步:计算冗余度。
d <- 1-d
第五步:计算各项指标的权重。
w <- d/sum(d)
w
最终输出结果展现,输出的为各项指标的权重得分

应用:基于各指标及权重值,可以对每个样本计算线性得分(使用归一化后数据)
实现:
sourui$评分 <- 0 for (i in 1:13){ sourui$评分 <- sourui$评分 + dataframe0[,i] * w1[i,] }
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185558.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
