大家好,又见面了,我是你们的朋友全栈君。
目录
卷积神经网络(Convolutional Nerual Network,CNN)
为什么计算机可以处理图–因为在计算机语言中图片可以用数字化,用四维数组来表示
卷积神经网络(Convolutional Nerual Network,CNN)
卷积神经网络特别适合处理像图片、视频、音频、语言文字等,这些与相互位置有一定关系的数据。
卷积神经网络与多连接神经网络一样,都属于神经网络的一种类别,只是多连接神经网络的隐藏层的特点是称为多连接层的该层上的每一个节点与上一层的全部节点是全连接的关系,卷积神经网络的隐藏层上的每一个节点与上一层的全部节点直接并非是全部连接的关系,而是仅与一部分的节点有连接。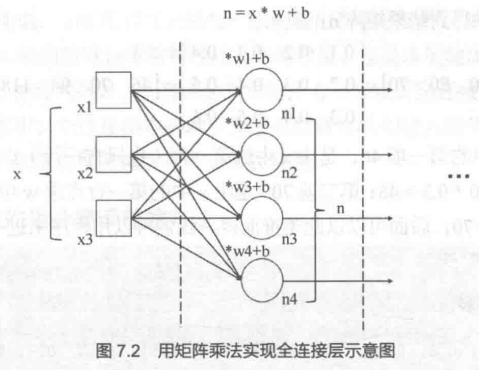

为什么计算机可以处理图片
–因为在计算机语言中图片可以用数字化,用四维数组来表示
既然卷积神经网络可以处理图片,那么我们就要理解图片在计算机语言中是如何表达的。图片其实是“点阵”图,由一个个点按照一定的顺序组合而成,那我们就可以联想到一个概念–数组。
图片可以分为三类:纯黑白图片、灰度图片、彩色图片
关于图片数字化,以最简单的纯黑白图片为例,我们可以用二维数组–矩阵来表示,比如h×w,高度h代表该点阵有多少行,也可以理解成每列有多少点;宽度w代表该点阵每行有多少点;通常我们说的摄像头是多少万像素,其实就是这个摄像头拍出来的照片保存成“点阵”图后的高度h和宽度w相乘的结果,如1900万×1250万这种写法。
上面说的是矩阵的维度,下面说矩阵中每个点的值所代表的含义。矩阵中每一个点一般叫“像素”,其值叫“像素值”,对于纯黑白图片,其像素值可以用0或1表示,0代表该点是白色,1代表该点是黑色;对于灰度图片,其像素值可以用[0,255]范围内的一个数字来代表黑色的深浅程度;对于彩色图片,每个点会用一个向量来表示,如RGB,即这个“点”此时是一个三维向量,RGB分别代表红色、绿色和蓝色,通常把这三项叫做该“点”颜色的通道,即分别为R通道、G通道、B通道。
这就意味着,世界上所有的图片,都可以数字化!图片数字化以后,就可以利用计算机语言中的数组来表达!这就是图片可以用计算机处理的第一步!
如下图,数字“2”的一个最简单的6×6的纯黑白图片的点阵图为:

该点阵图的数字化表达为(用二维数组进行表达):
[[0,0,1,1,0,0],
[0,1,0,0,1,0],
[0,0,0,0,1,0],
[0,0,0,1,0,0],
[0,0,1,0,0,0],
[0,1,1,1,1,0]]
卷积层定义
同全连接层一样,卷积层也是神经网络中包含某一特点的一个隐藏层。该隐藏层的作用就是对输入层做卷积。要了解卷积层需要了解两个概念,一是卷积核,另一个是卷积运算。
卷积核是一个数字矩阵(英文是filter,或者kernel),卷积核的大小即该数字矩阵的维度。
卷积运算,见下图,卷积核与左侧的虚线框内的子矩阵做先点乘,后求和。这个运算就是卷积运算。之后卷积核会继续与输入矩阵的第二个子矩阵进行同样的卷积运算。
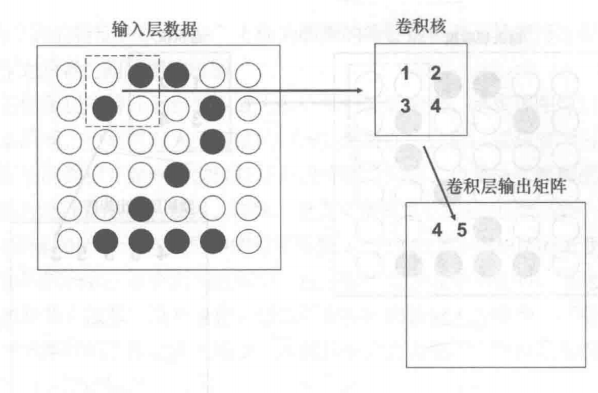
得到的卷积层输出矩阵有两种情况,①不填充节点0,则得到的输出矩阵维数会减小;②填充节点0,则得到的输出矩阵维数不变
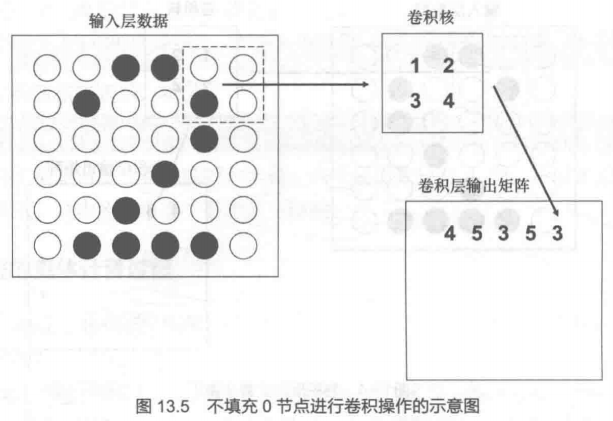
理解一下卷积运算的好处:
①降低数据维度,不填充节点0,得到的输出矩阵维数会减小。
②特征提取:卷积运算相当于把原图中相邻几个节点一起进行运算,得到一个数字,该数字包含了这几个节点的【综合数值】+【相对位置的信息】的特征(这是一个特征提取的过程)。举个栗子,图13.5中的数字5,在一定程度上代表了“2”字“向右上方转折”这一笔画特征,这是输入层的单个点所不能包含的信息。
③降低计算复杂度,利用上面的特征提取,可以利用特征来对图像进行识别,能比单点识别的运算量小。举个栗子,图13.5中的数字5,代表“2”字“向右上方转折”这一笔画特征,如果某图片的数字是“1”,进行卷积运算后得到的输出层相同位置的数字不是5,即可判断出,该数字不是2。而不用长篇幅的单点识别对比。通过特征提取,这个特征能用来识别是不是数字“2”的重要依据之一。
④增加卷积层的数量,可以把低级别的特征逐步提取成为高级别特征。—-这是卷积层的最重要的能力!!
卷积层计算的代码实现
import tensorflow as tf
xData=tf.constant([[[0],[0],[1],[1],[0],[0]],[[0],[1],[0],[0],[1],[0]],
[[0],[0],[0],[0],[1],[0]],[[0],[0],[0],[1],[0],[0]],
[[0],[0],[1],[0],[0],[0]],[[0],[1],[1],[1],[1],[0]]],dtype=tf.float32)
kernel=tf.constant([[[1],[2]],[[3],[4]]],dtype=tf.float32)
y=tf.nn.conv2d(input=tf.reshape(xData,[1,6,6,1]),filter=tf.reshape(kernel,[2,2,1,1]),striders=[1,1,1,1],padding='VALID')
sess=tf.Session()
result=sess.run(y)
print(y)解释一下代码所用到的语句的意思
tf.constant是tf中生成一个不会改变的张量的函数,即常量张量
tf.nn.conv2d(input,filter,strides=[,,,],padding=)
tf.nn.conv2d的四个命名参数:
input是输入数据,input要求输入的数据是一个四维数组,上面xData我们定义的是一个三维数组,通过tf.reshape把三维的数组变成四维的数组输入给input。
其中第一个维度代表一次要处理的图片数量,第二、三个维度代表输入图片的h和w,第四个维度代表图片彩色的通道数。
这里我们把xData reshape成[1,6,6,1],即一次处理一张图片,该图片的h和w分别为6、6,黑白图片的通道数为1,把xData reshape后满足参数input的要求。
即记住input实际输入的是一个四维数组
简记input=[一次处理图片数量,h,w,通道数量]
filter是卷积核,要求输入的数据也是一个四维数组,简记filter=[h,w,输入通道数,输出通道数]
其中输入通道数和输出通道数一般都是相等的。
对于上面代码filter=tf.reshape(kernel,[2,2,1,1])中[2,2,1,1]的理解可以参照上段对input的理解。
且记住filter实际输入的是一个四维数组
strides=[,,,]输入的是一个四维的向量,用于指定卷积时卷积核移动的步长。
每个维度分别对应在输入数组(input)4个维度上的步长。
举个栗子:striders=[1,2,3,1],即代表对输入数组(input),每次处理1张图片,每张图片隔2步横着走,隔3步竖着走,在单个通道内走1步
padding只有两个值:'VALID' or 'SAME',前者代表不填充节点0,后者代表填充节点0多说一句~这里提供的代码时1.x版本的tensorflow可运行的代码,如果安装的2.x版本的tensorflow可以在上段代码的前面加上下面两句话(本意是导入1.x版本的tensorflow且使得2.x版本的语句失效,不过这个方法会出现警告,有一天可能会失效~~)
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term#即disable_resource_variables在未来的版本中会被去掉
以上为作者学习《深度学习–基于Python语言和TensorFlow平台(视频讲解版)》对卷积神经网络的复习、理解加总结,如需学习更详尽的知识,请参考本书。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137862.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
