大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
使用VGG16作为预训练模型训练Faster-RCNN-TensorFlow-Python3-master的详细步骤→Windows10+Faster-RCNN-TensorFlow-Python3-master+VOC2007数据集。
如果使用ResNet101作为预训练模型训练Faster-RCNN-TensorFlow-Python3-master,在之前使用VGG16作为预训练模型的训练步骤基础上需要修改几个地方。
- 第一个,在之前的第6步时,改为下载预训练模型ResNet101,在
./data文件夹下新建文件夹imagenet_weights,将下载好的resnet_v1_101_2016_08_28.tar.gz解压到./data/imagenet_weights路径下,并将resnet_v1_101.ckpt重命名为resnet101.ckpt。


- 第二个,在之前的第7步时,除了修改最大迭代次数
max_iters参数和迭代多少次保存一次模型snap_iterations参数之外,还需要修改以下几个参数。
① 将network参数由vgg16改为resnet101

② 将pretrained_model参数由./data/imagenet_weights/vgg16.ckpt改为./data/imagenet_weights/resnet101.ckpt

③ 增加pooling_mode、FIXED_BLOCKS、POOLING_SIZE、MAX_POOL四个参数

tf.app.flags.DEFINE_string('network', "resnet101", "The network to be used as backbone")
tf.app.flags.DEFINE_string('pretrained_model', "./data/imagenet_weights/resnet101.ckpt", "Pretrained network weights")
# ResNet options
tf.app.flags.DEFINE_string('pooling_mode', "crop", "Default pooling mode")
tf.app.flags.DEFINE_integer('FIXED_BLOCKS', 1, "Number of fixed blocks during training")
tf.app.flags.DEFINE_integer('POOLING_SIZE', 7, "Size of the pooled region after RoI pooling")
tf.app.flags.DEFINE_boolean('MAX_POOL', False, "Whether to append max-pooling after crop_and_resize")
- 第三个,对
resnet_v1.py文件进行修改,用下面的代码替换原文件中的代码。
# --------------------------------------------------------
# Tensorflow Faster R-CNN
# Licensed under The MIT License [see LICENSE for details]
# Written by Zheqi He and Xinlei Chen
# --------------------------------------------------------
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import tensorflow.contrib.slim as slim
from tensorflow.contrib.slim import losses
from tensorflow.contrib.slim import arg_scope
from tensorflow.contrib.slim.python.slim.nets import resnet_utils
from tensorflow.contrib.slim.python.slim.nets import resnet_v1
import numpy as np
from lib.nets.network import Network
from tensorflow.python.framework import ops
from tensorflow.contrib.layers.python.layers import regularizers
from tensorflow.python.ops import nn_ops
from tensorflow.contrib.layers.python.layers import initializers
from tensorflow.contrib.layers.python.layers import layers
from lib.config import config as cfg
def resnet_arg_scope(is_training=True,
weight_decay=cfg.FLAGS.weight_decay,
# weight_decay=cfg.TRAIN.WEIGHT_DECAY,
batch_norm_decay=0.997,
batch_norm_epsilon=1e-5,
batch_norm_scale=True):
batch_norm_params = {
# NOTE 'is_training' here does not work because inside resnet it gets reset:
# https://github.com/tensorflow/models/blob/master/slim/nets/resnet_v1.py#L187
'is_training': False,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'scale': batch_norm_scale,
'trainable': False,
'updates_collections': ops.GraphKeys.UPDATE_OPS
}
with arg_scope(
[slim.conv2d],
weights_regularizer=regularizers.l2_regularizer(weight_decay),
weights_initializer=initializers.variance_scaling_initializer(),
trainable=is_training,
activation_fn=nn_ops.relu,
normalizer_fn=layers.batch_norm,
normalizer_params=batch_norm_params):
with arg_scope([layers.batch_norm], **batch_norm_params) as arg_sc:
return arg_sc
class resnetv1(Network):
def __init__(self, batch_size=1, num_layers=101):
Network.__init__(self, batch_size=batch_size)
self._num_layers = num_layers
self._resnet_scope = 'resnet_v1_%d' % num_layers
def _crop_pool_layer(self, bottom, rois, name):
with tf.variable_scope(name) as scope:
batch_ids = tf.squeeze(tf.slice(rois, [0, 0], [-1, 1], name="batch_id"), [1])
# Get the normalized coordinates of bboxes
bottom_shape = tf.shape(bottom)
height = (tf.to_float(bottom_shape[1]) - 1.) * np.float32(self._feat_stride[0])
width = (tf.to_float(bottom_shape[2]) - 1.) * np.float32(self._feat_stride[0])
x1 = tf.slice(rois, [0, 1], [-1, 1], name="x1") / width
y1 = tf.slice(rois, [0, 2], [-1, 1], name="y1") / height
x2 = tf.slice(rois, [0, 3], [-1, 1], name="x2") / width
y2 = tf.slice(rois, [0, 4], [-1, 1], name="y2") / height
# Won't be backpropagated to rois anyway, but to save time
bboxes = tf.stop_gradient(tf.concat([y1, x1, y2, x2], 1))
if cfg.FLAGS.MAX_POOL:
pre_pool_size = cfg.FLAGS.POOLING_SIZE * 2
crops = tf.image.crop_and_resize(bottom, bboxes, tf.to_int32(batch_ids), [pre_pool_size, pre_pool_size],
name="crops")
crops = slim.max_pool2d(crops, [2, 2], padding='SAME')
else:
crops = tf.image.crop_and_resize(bottom, bboxes, tf.to_int32(batch_ids),
[cfg.FLAGS.POOLING_SIZE, cfg.FLAGS.POOLING_SIZE],
name="crops")
return crops
# Do the first few layers manually, because 'SAME' padding can behave inconsistently
# for images of different sizes: sometimes 0, sometimes 1
def build_base(self):
with tf.variable_scope(self._resnet_scope, self._resnet_scope):
net = resnet_utils.conv2d_same(self._image, 64, 7, stride=2, scope='conv1')
net = tf.pad(net, [[0, 0], [1, 1], [1, 1], [0, 0]])
net = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID', scope='pool1')
return net
def build_network(self, sess, is_training=True):
# select initializers
# if cfg.TRAIN.TRUNCATED:
if cfg.FLAGS.initializer == "truncated":
initializer = tf.truncated_normal_initializer(mean=0.0, stddev=0.01)
initializer_bbox = tf.truncated_normal_initializer(mean=0.0, stddev=0.001)
else:
initializer = tf.random_normal_initializer(mean=0.0, stddev=0.01)
initializer_bbox = tf.random_normal_initializer(mean=0.0, stddev=0.001)
bottleneck = resnet_v1.bottleneck
# choose different blocks for different number of layers
if self._num_layers == 50:
blocks = [
resnet_utils.Block('block1', bottleneck,
[(256, 64, 1)] * 2 + [(256, 64, 2)]),
resnet_utils.Block('block2', bottleneck,
[(512, 128, 1)] * 3 + [(512, 128, 2)]),
# Use stride-1 for the last conv4 layer
resnet_utils.Block('block3', bottleneck,
[(1024, 256, 1)] * 5 + [(1024, 256, 1)]),
resnet_utils.Block('block4', bottleneck, [(2048, 512, 1)] * 3)
]
elif self._num_layers == 101:
# blocks = [
# resnet_utils.Block('block1', bottleneck,
# [(256, 64, 1)] * 2 + [(256, 64, 2)]),
# resnet_utils.Block('block2', bottleneck,
# [(512, 128, 1)] * 3 + [(512, 128, 2)]),
# # Use stride-1 for the last conv4 layer
# resnet_utils.Block('block3', bottleneck,
# [(1024, 256, 1)] * 22 + [(1024, 256, 1)]),
# resnet_utils.Block('block4', bottleneck, [(2048, 512, 1)] * 3)
# ]
blocks = [
resnet_v1.resnet_v1_block('block1', base_depth=64, num_units=3, stride=2),
resnet_v1.resnet_v1_block('block2', base_depth=128, num_units=4, stride=2),
resnet_v1.resnet_v1_block('block3', base_depth=256, num_units=23, stride=1),
resnet_v1.resnet_v1_block('block4', base_depth=512, num_units=3, stride=1),
]
elif self._num_layers == 152:
blocks = [
resnet_utils.Block('block1', bottleneck,
[(256, 64, 1)] * 2 + [(256, 64, 2)]),
resnet_utils.Block('block2', bottleneck,
[(512, 128, 1)] * 7 + [(512, 128, 2)]),
# Use stride-1 for the last conv4 layer
resnet_utils.Block('block3', bottleneck,
[(1024, 256, 1)] * 35 + [(1024, 256, 1)]),
resnet_utils.Block('block4', bottleneck, [(2048, 512, 1)] * 3)
]
else:
# other numbers are not supported
raise NotImplementedError
# assert (0 <= cfg.RESNET.FIXED_BLOCKS < 4)
assert (0 <= cfg.FLAGS.FIXED_BLOCKS < 4)
if cfg.FLAGS.FIXED_BLOCKS == 3:
with slim.arg_scope(resnet_arg_scope(is_training=False)):
net = self.build_base()
net_conv4, _ = resnet_v1.resnet_v1(net,
blocks[0:cfg.FLAGS.FIXED_BLOCKS],
global_pool=False,
include_root_block=False,
scope=self._resnet_scope)
elif cfg.FLAGS.FIXED_BLOCKS > 0:
with slim.arg_scope(resnet_arg_scope(is_training=False)):
net = self.build_base()
net, _ = resnet_v1.resnet_v1(net,
blocks[0:cfg.FLAGS.FIXED_BLOCKS],
global_pool=False,
include_root_block=False,
scope=self._resnet_scope)
with slim.arg_scope(resnet_arg_scope(is_training=is_training)):
net_conv4, _ = resnet_v1.resnet_v1(net,
blocks[cfg.FLAGS.FIXED_BLOCKS:-1],
global_pool=False,
include_root_block=False,
scope=self._resnet_scope)
else: # cfg.RESNET.FIXED_BLOCKS == 0
with slim.arg_scope(resnet_arg_scope(is_training=is_training)):
net = self.build_base()
net_conv4, _ = resnet_v1.resnet_v1(net,
blocks[0:-1],
global_pool=False,
include_root_block=False,
scope=self._resnet_scope)
self._act_summaries.append(net_conv4)
self._layers['head'] = net_conv4
with tf.variable_scope(self._resnet_scope, self._resnet_scope):
# build the anchors for the image
self._anchor_component()
# rpn
rpn = slim.conv2d(net_conv4, 512, [3, 3], trainable=is_training, weights_initializer=initializer,
scope="rpn_conv/3x3")
self._act_summaries.append(rpn)
rpn_cls_score = slim.conv2d(rpn, self._num_anchors * 2, [1, 1], trainable=is_training,
weights_initializer=initializer,
padding='VALID', activation_fn=None, scope='rpn_cls_score')
# change it so that the score has 2 as its channel size
rpn_cls_score_reshape = self._reshape_layer(rpn_cls_score, 2, 'rpn_cls_score_reshape')
rpn_cls_prob_reshape = self._softmax_layer(rpn_cls_score_reshape, "rpn_cls_prob_reshape")
rpn_cls_prob = self._reshape_layer(rpn_cls_prob_reshape, self._num_anchors * 2, "rpn_cls_prob")
rpn_bbox_pred = slim.conv2d(rpn, self._num_anchors * 4, [1, 1], trainable=is_training,
weights_initializer=initializer,
padding='VALID', activation_fn=None, scope='rpn_bbox_pred')
if is_training:
rois, roi_scores = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
rpn_labels = self._anchor_target_layer(rpn_cls_score, "anchor")
# Try to have a determinestic order for the computing graph, for reproducibility
with tf.control_dependencies([rpn_labels]):
rois, _ = self._proposal_target_layer(rois, roi_scores, "rpn_rois")
else:
# if cfg.TEST.MODE == 'nms':
if cfg.FLAGS.test_mode == "nms":
rois, _ = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
# elif cfg.TEST.MODE == 'top':
elif cfg.FLAGS.test_mode == "top":
rois, _ = self._proposal_top_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
else:
raise NotImplementedError
# rcnn
if cfg.FLAGS.pooling_mode == 'crop':
pool5 = self._crop_pool_layer(net_conv4, rois, "pool5")
else:
raise NotImplementedError
with slim.arg_scope(resnet_arg_scope(is_training=is_training)):
fc7, _ = resnet_v1.resnet_v1(pool5,
blocks[-1:],
global_pool=False,
include_root_block=False,
scope=self._resnet_scope)
with tf.variable_scope(self._resnet_scope, self._resnet_scope):
# Average pooling done by reduce_mean
fc7 = tf.reduce_mean(fc7, axis=[1, 2])
cls_score = slim.fully_connected(fc7, self._num_classes, weights_initializer=initializer,
trainable=is_training, activation_fn=None, scope='cls_score')
cls_prob = self._softmax_layer(cls_score, "cls_prob")
bbox_pred = slim.fully_connected(fc7, self._num_classes * 4, weights_initializer=initializer_bbox,
trainable=is_training,
activation_fn=None, scope='bbox_pred')
self._predictions["rpn_cls_score"] = rpn_cls_score
self._predictions["rpn_cls_score_reshape"] = rpn_cls_score_reshape
self._predictions["rpn_cls_prob"] = rpn_cls_prob
self._predictions["rpn_bbox_pred"] = rpn_bbox_pred
self._predictions["cls_score"] = cls_score
self._predictions["cls_prob"] = cls_prob
self._predictions["bbox_pred"] = bbox_pred
self._predictions["rois"] = rois
self._score_summaries.update(self._predictions)
return rois, cls_prob, bbox_pred
def get_variables_to_restore(self, variables, var_keep_dic):
variables_to_restore = []
for v in variables:
# exclude the first conv layer to swap RGB to BGR
if v.name == (self._resnet_scope + '/conv1/weights:0'):
self._variables_to_fix[v.name] = v
continue
if v.name.split(':')[0] in var_keep_dic:
print('Varibles restored: %s' % v.name)
variables_to_restore.append(v)
return variables_to_restore
def fix_variables(self, sess, pretrained_model):
print('Fix Resnet V1 layers..')
with tf.variable_scope('Fix_Resnet_V1') as scope:
with tf.device("/cpu:0"):
# fix RGB to BGR
conv1_rgb = tf.get_variable("conv1_rgb", [7, 7, 3, 64], trainable=False)
restorer_fc = tf.train.Saver({
self._resnet_scope + "/conv1/weights": conv1_rgb})
restorer_fc.restore(sess, pretrained_model)
sess.run(tf.assign(self._variables_to_fix[self._resnet_scope + '/conv1/weights:0'],
tf.reverse(conv1_rgb, [2])))
- 第四个,在之前的第9步时,点击
Run 'train'开始训练之前先修改train.py代码的如下几个地方。



# 添加的代码(使用resnet101作为预训练模型)
from lib.nets.resnet_v1 import resnetv1
# 添加结束
# 添加的代码(使用resnet101)
if cfg.FLAGS.network == 'resnet101':
self.net = resnetv1(batch_size=cfg.FLAGS.ims_per_batch)
# 添加结束
# Store the model snapshot
filename = 'resnet101_faster_rcnn_iter_{:d}'.format(iter) + '.ckpt'
filename = os.path.join(self.output_dir, filename)
self.saver.save(sess, filename)
print('Wrote snapshot to: {:s}'.format(filename))
# Also store some meta information, random state, etc.
nfilename = 'resnet101_faster_rcnn_iter_{:d}'.format(iter) + '.pkl'
nfilename = os.path.join(self.output_dir, nfilename)
经过上面的几步修改后,就可以运行train.py开始训练模型了。
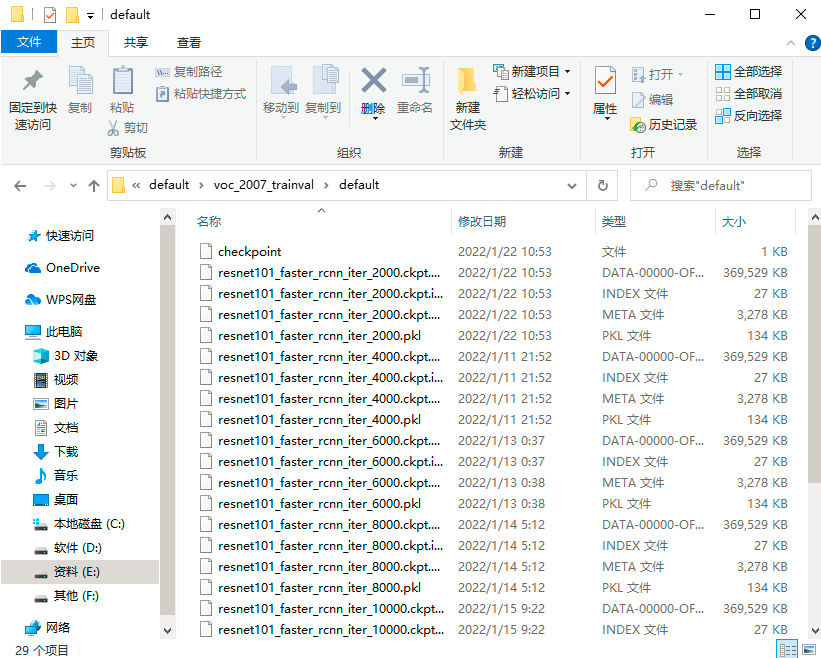
训练时,模型保存的路径是./default/voc_2007_trainval/default,每次保存模型都是保存4个文件,如下图所示。
相应地,测试时也需要修改几个地方。
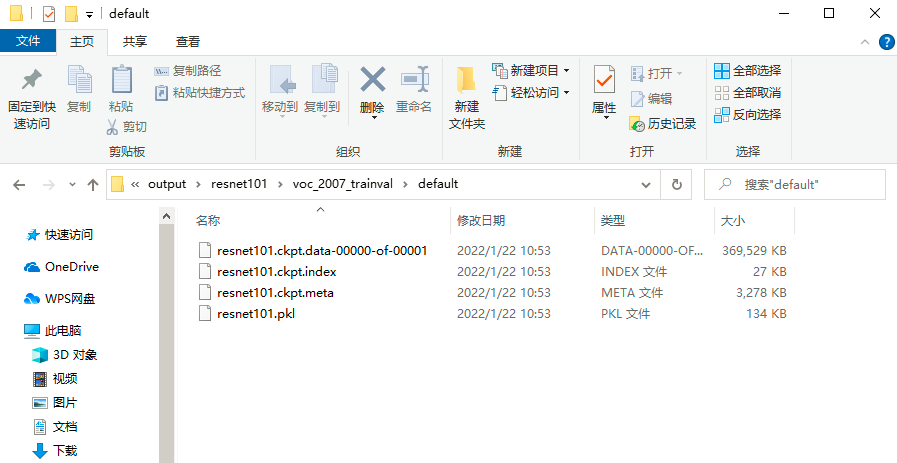
- 第一个,在之前的第12步时,改为新建
./output/resnet101/voc_2007_trainval/default文件夹,从./default/voc_2007_trainval/default路径下复制一组模型数据到新建的文件夹下,并将所有文件名改为resnet101.后缀。
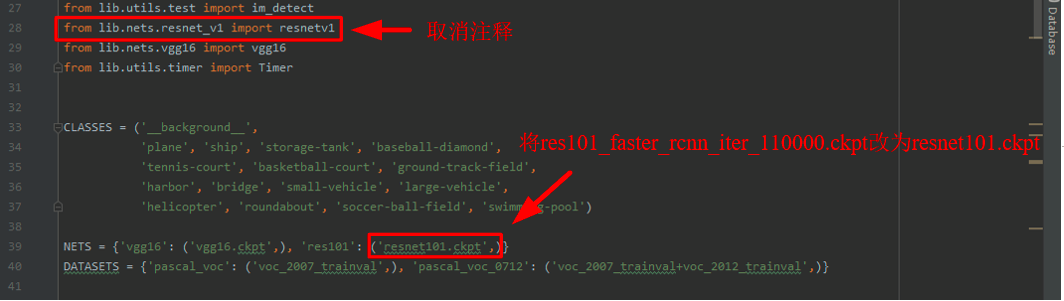
- 第二个,在之前的第13步时,对
demo.py再进行如下的修改。
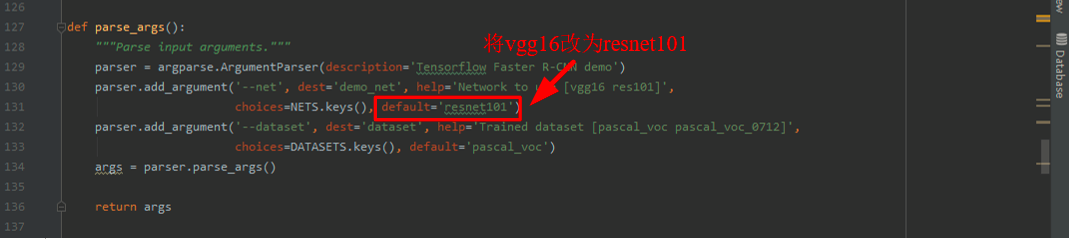

经过上面的几步修改后,就可以运行demo.py开始测试模型了。
在输出PR曲线并计算AP值时,同样也需要修改test_net.py文件中的几个地方,如下图所示。


# 添加的代码(使用resnet101)
from lib.nets.resnet_v1 import resnetv1
# 添加结束
# NETS = {'vgg16': ('vgg16.ckpt',)} # 自己需要修改:训练输出模型
NETS = {
'resnet101': ('resnet101.ckpt',)} # 自己需要修改:训练输出模型
经过上面的几步修改后,就可以运行test_net.py来输出PR曲线并计算AP值了。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185293.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
