大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
提前声明:该文章涉及的所有案例均为学习使用,如有侵权,请联系本人删帖!


文章目录
- 前言
- 案例1:某贴吧前十页源码下载
- 案例2:输入英文实现中文翻译
- 案例3:菜鸟教程的python100例下载
- 案例4:将某头条前20页信息存入MySQL
- 案例5:利用多线程对指定图片进行下载搜
- 案例6:电影TOP100榜有你喜欢的那一部吗
- 案例7:股票帖子里有你支持的那一只股票新闻吗
- 案例8:有你用过的常见药品吗
- 案例9:Python必备的英语单词
- 案例10:你喜欢的歌手来啦
- 案例11:你喜欢的歌手歌单来啦
- 案例12:利用selenium+Phantomjs获取图书信息
- 案例13:某讯招聘
- 案例14:英雄联盟英雄和技能(selenium+phantomjs)
- 案例15:各个不同类型的好看电影
- 案例16:分析北京的房子都是什么样
前言
- 该贴是几年前所写,由于网页会改版,所以有的代码不一定可以用,望周知。
- 个人最新爬虫专栏:专栏传送门:https://blog.csdn.net/qq_40558166/category_10816255.html
案例1:某贴吧前十页源码下载
import requests, os
base_url = 'https://tieba.baidu.com/f?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
dirname = './tieba/woman/'
if not os.path.exists(dirname):
os.makedirs(dirname)
for i in range(0, 10):
params = {
'ie': 'utf-8',
'kw': '美女',
'pn': str(i * 50)
}
response = requests.get(base_url, headers=headers, params=params)
with open(dirname + '美女第%s页.html' % (i + 1), 'w', encoding='utf-8') as file:
file.write(response.content.decode('utf-8'))
print('第{}页完成'.format(i))
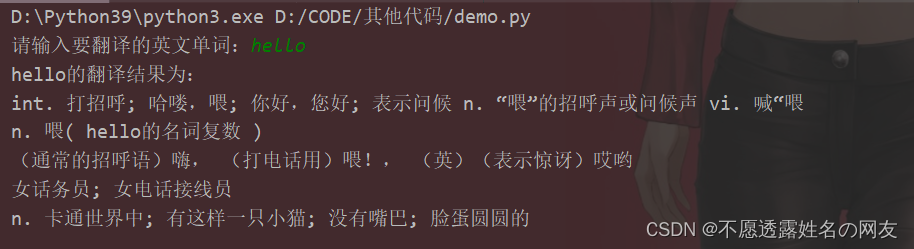
案例2:输入英文实现中文翻译
import requests
base_url = 'https://fanyi.baidu.com/sug'
kw = input('请输入要翻译的英文单词:')
data = {
'kw': kw
}
headers = {
'content-length': str(len(data)),
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'referer': 'https://fanyi.baidu.com/',
'x-requested-with': 'XMLHttpRequest'
}
response = requests.post(base_url, headers=headers, data=data)
# print(response.json())
# 结果:{'errno': 0, 'data': [{'k': 'python', 'v': 'n. 蟒; 蚺蛇;'}, {'k': 'pythons', 'v': 'n. 蟒; 蚺蛇; python的复数;'}]}
# -----------------------------把结果隔行输出
result = ''
for i in response.json()['data']:
result += i['v'] + '\n'
print(kw + '的翻译结果为:')
print(result)

案例3:菜鸟教程的python100例下载
import requests
from lxml import etree
base_url = 'https://www.runoob.com/python/python-exercise-example%s.html'
def get_element(url):
headers = {
'cookie': '__gads=Test; Hm_lvt_3eec0b7da6548cf07db3bc477ea905ee=1573454862,1573470948,1573478656,1573713819; Hm_lpvt_3eec0b7da6548cf07db3bc477ea905ee=1573714018; SERVERID=fb669a01438a4693a180d7ad8d474adb|1573713997|1573713863',
'referer': 'https://www.runoob.com/python/python-100-examples.html',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
response = requests.get(url, headers=headers)
return etree.HTML(response.text)
def write_py(i, text):
with open('练习实例%s.py' % i, 'w', encoding='utf-8') as file:
file.write(text)
def main():
for i in range(1, 101):
html = get_element(base_url % i)
content = '题目:' + html.xpath('//div[@id="content"]/p[2]/text()')[0] + '\n'
fenxi = html.xpath('//div[@id="content"]/p[position()>=2]/text()')[0]
daima = ''.join(html.xpath('//div[@class="hl-main"]/span/text()')) + '\n'
haha = '"""\n' + content + fenxi + daima + '\n"""'
write_py(i, haha)
print(fenxi)
if __name__ == '__main__':
main()

案例4:将某头条前20页信息存入MySQL
import requests, pymysql
from lxml import etree
def get_element(i):
base_url = 'https://weibo.com/a/aj/transform/loadingmoreunlogin?'
headers = {
'Referer': 'https://weibo.com/?category=1760',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
params = {
'ajwvr': '6',
'category': '1760',
'page': i,
'lefnav': '0',
'cursor': '',
'__rnd': '1573735870072',
}
response = requests.get(base_url, headers=headers, params=params)
response.encoding = 'utf-8'
info = response.json()
return etree.HTML(info['data'])
def main():
for i in range(1, 20):
html = get_element(i)
# 标题,发布人,发布时间,详情链接
title = html.xpath('//a[@class="S_txt1"]/text()')
author_time = html.xpath('//span[@class]/text()')
author = [author_time[i] for i in range(len(author_time)) if i % 2 == 0]
time = [author_time[i] for i in range(len(author_time)) if i % 2 == 1]
url = html.xpath('//a[@class="S_txt1"]/@href')
for j,tit in enumerate(title):
title1=tit
time1=time[j]
url1=url[j]
author1=author[j]
# print(title1,url1,time1,author1)
connect_mysql(title1,time1,author1,url1)
def connect_mysql(title, time, author, url):
db = pymysql.connect(host='localhost', user='root', password=None,database='news')
cursor = db.cursor()
sql = 'insert into sina_news(title,send_time,author,url) values("' + title + '","' + time + '","' + author + '","' + url + '")'
print(sql)
cursor.execute(sql)
db.commit()
cursor.close()
db.close()
if __name__ == '__main__':
main()
提前创库news和表sina_news
create table sina_news(
id int not null auto_increment primary key,
title varchar(100),
send_time varchar(100),
author varchar(20),
url varchar(100)
);

案例5:利用多线程对指定图片进行下载搜
import requests, json, threading, time, os
from queue import Queue
class Picture(threading.Thread):
# 初始化
def __init__(self, num, search, url_queue=None):
super().__init__()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
self.num = num
self.search = search
# 获取爬取的页数的每页图片接口url
def get_url(self):
url_list = []
for start in range(self.num):
url = 'https://pic.sogou.com/pics?query=' + self.search + '&mode=1&start=' + str(
start * 48) + '&reqType=ajax&reqFrom=result&tn=0'
url_list.append(url)
return url_list
# 获取每页的接口资源详情
def get_page(self, url):
response = requests.get(url.format('蔡徐坤'), headers=self.headers)
return response.text
#
def run(self):
while True:
# 如果队列为空代表制定页数爬取完毕
if url_queue.empty():
break
else:
url = url_queue.get() # 本页地址
data = json.loads(self.get_page(url)) # 获取到本页图片接口资源
try:
# 每页48张图片
for i in range(1, 49):
pic = data['items'][i]['pic_url']
reponse = requests.get(pic)
# 如果文件夹不存在,则创建
if not os.path.exists(r'C:/Users/Administrator/Desktop/' + self.search):
os.mkdir(r'C:/Users/Administrator/Desktop/' + self.search)
with open(r'C:/Users/Administrator/Desktop/' + self.search + '/%s.jpg' % (
str(time.time()).replace('.', '_')), 'wb') as f:
f.write(reponse.content)
print('下载成功!')
except:
print('该页图片保存完毕')
if __name__ == '__main__':
# 1.获取初始化的爬取url
num = int(input('请输入爬取页数(每页48张):'))
content = input('请输入爬取内容:')
pic = Picture(num, content)
url_list = pic.get_url()
# 2.创建队列
url_queue = Queue()
for i in url_list:
url_queue.put(i)
# 3.创建线程任务
crawl = [1, 2, 3, 4, 5]
for i in crawl:
pic = Picture(num, content, url_queue=url_queue)
pic.start()
案例6:电影TOP100榜有你喜欢的那一部吗

import re, requests, json
class Maoyan:
def __init__(self, url):
self.url = url
self.movie_list = []
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
self.parse()
def parse(self):
# 爬去页面的代码
# 1.发送请求,获取响应
# 分页
for i in range(10):
url = self.url + '?offset={}'.format(i * 10)
response = requests.get(url, headers=self.headers)
''' 1.电影名称 2、主演 3、上映时间 4、评分 '''
# 用正则筛选数据,有个原则:不断缩小筛选范围。
dl_pattern = re.compile(r'<dl class="board-wrapper">(.*?)</dl>', re.S)
dl_content = dl_pattern.search(response.text).group()
dd_pattern = re.compile(r'<dd>(.*?)</dd>', re.S)
dd_list = dd_pattern.findall(dl_content)
# print(dd_list)
movie_list = []
for dd in dd_list:
print(dd)
item = {
}
# ------------电影名字
movie_pattern = re.compile(r'title="(.*?)" class=', re.S)
movie_name = movie_pattern.search(dd).group(1)
# print(movie_name)
actor_pattern = re.compile(r'<p class="star">(.*?)</p>', re.S)
actor = actor_pattern.search(dd).group(1).strip()
# print(actor)
play_time_pattern = re.compile(r'<p class="releasetime">(.*?):(.*?)</p>', re.S)
play_time = play_time_pattern.search(dd).group(2).strip()
# print(play_time)
# 评分
score_pattern_1 = re.compile(r'<i class="integer">(.*?)</i>', re.S)
score_pattern_2 = re.compile(r'<i class="fraction">(.*?)</i>', re.S)
score = score_pattern_1.search(dd).group(1).strip() + score_pattern_2.search(dd).group(1).strip()
# print(score)
item['电影名字:'] = movie_name
item['主演:'] = actor
item['时间:'] = play_time
item['评分:'] = score
# print(item)
self.movie_list.append(item)
# 将电影信息保存到json文件中
with open('movie.json', 'w', encoding='utf-8') as fp:
json.dump(self.movie_list, fp)
if __name__ == '__main__':
base_url = 'https://maoyan.com/board/4'
Maoyan(base_url)
with open('movie.json', 'r') as fp:
movie_list = json.load(fp)
print(movie_list)
案例7:股票帖子里有你支持的那一只股票新闻吗
import json
import re
import requests
class GuBa(object):
def __init__(self):
self.base_url = 'http://guba.eastmoney.com/default,99_%s.html'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
self.infos = []
self.parse()
def parse(self):
for i in range(1, 13):
response = requests.get(self.base_url % i, headers=self.headers)
'''阅读数,评论数,标题,作者,更新时间,详情页url'''
ul_pattern = re.compile(r'<ul id="itemSearchList" class="itemSearchList">(.*?)</ul>', re.S)
ul_content = ul_pattern.search(response.text)
if ul_content:
ul_content = ul_content.group()
li_pattern = re.compile(r'<li>(.*?)</li>', re.S)
li_list = li_pattern.findall(ul_content)
# print(li_list)
for li in li_list:
item = {
}
reader_pattern = re.compile(r'<cite>(.*?)</cite>', re.S)
info_list = reader_pattern.findall(li)
# print(info_list)
reader_num = ''
comment_num = ''
if info_list:
reader_num = info_list[0].strip()
comment_num = info_list[1].strip()
print(reader_num, comment_num)
title_pattern = re.compile(r'title="(.*?)" class="note">', re.S)
title = title_pattern.search(li).group(1)
# print(title)
author_pattern = re.compile(r'target="_blank"><font>(.*?)</font></a><input type="hidden"', re.S)
author = author_pattern.search(li).group(1)
# print(author)
date_pattern = re.compile(r'<cite class="last">(.*?)</cite>', re.S)
date = date_pattern.search(li).group(1)
# print(date)
detail_pattern = re.compile(r' <a href="(.*?)" title=', re.S)
detail_url = detail_pattern.search(li)
if detail_url:
detail_url = 'http://guba.eastmoney.com' + detail_url.group(1)
else:
detail_url = ''
print(detail_url)
item['title'] = title
item['author'] = author
item['date'] = date
item['reader_num'] = reader_num
item['comment_num'] = comment_num
item['detail_url'] = detail_url
self.infos.append(item)
with open('guba.json', 'w', encoding='utf-8') as fp:
json.dump(self.infos, fp)
gb=GuBa()
案例8:有你用过的常见药品吗
''' 前50页药品的总价,描述,评论数量,详情页链接 '''
import requests, re,json
class Drugs:
def __init__(self):
self.url = url = 'https://www.111.com.cn/categories/953710-j%s.html'
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
self.Drugs_list=[]
self.parse()
def parse(self):
for i in range(51):
response = requests.get(self.url % i, headers=self.headers)
# print(response.text)
# 字段:药名,总价,评论数量,详情页链接
Drugsul_pattern = re.compile('<ul id="itemSearchList" class="itemSearchList">(.*?)</ul>', re.S)
Drugsul = Drugsul_pattern.search(response.text).group()
# print(Drugsul)
Drugsli_list_pattern = re.compile('<li id="producteg(.*?)</li>', re.S)
Drugsli_list = Drugsli_list_pattern.findall(Drugsul)
Drugsli_list = Drugsli_list
# print(Drugsli_list)
for drug in Drugsli_list:
# ---药名
item={
}
name_pattern = re.compile('alt="(.*?)"', re.S)
name = name_pattern.search(str(drug)).group(1)
# print(name)
# ---总价
total_pattern = re.compile('<span>(.*?)</span>', re.S)
total = total_pattern.search(drug).group(1).strip()
# print(total)
# ----评论
comment_pattern = re.compile('<em>(.*?)</em>')
comment = comment_pattern.search(drug)
if comment:
comment_group = comment.group(1)
else:
comment_group = '0'
# print(comment_group)
# ---详情页链接
href_pattern = re.compile('" href="//(.*?)"')
href='https://'+href_pattern.search(drug).group(1).strip()
# print(href)
item['药名']=name
item['总价']=total
item['评论']=comment
item['链接']=href
self.Drugs_list.append(item)
drugs = Drugs()
print(drugs.Drugs_list)
案例9:Python必备的英语单词
import json
import requests
from lxml import etree
base_url = 'https://www.shanbay.com/wordlist/110521/232414/?page=%s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
def get_text(value):
if value:
return value[0]
return ''
word_list = []
for i in range(1, 4):
# 发送请求
response = requests.get(base_url % i, headers=headers)
# print(response.text)
html = etree.HTML(response.text)
tr_list = html.xpath('//tbody/tr')
# print(tr_list)
for tr in tr_list:
item = {
}#构造单词列表
en = get_text(tr.xpath('.//td[@class="span2"]/strong/text()'))
tra = get_text(tr.xpath('.//td[@class="span10"]/text()'))
print(en, tra)
if en:
item[en] = tra
word_list.append(item)
面向对象:
import requests
from lxml import etree
class Shanbei(object):
def __init__(self):
self.base_url = 'https://www.shanbay.com/wordlist/110521/232414/?page=%s'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
self.word_list = []
self.parse()
def get_text(self, value):
# 防止为空报错
if value:
return value[0]
return ''
def parse(self):
for i in range(1, 4):
# 发送请求
response = requests.get(self.base_url % i, headers=self.headers)
# print(response.text)
html = etree.HTML(response.text)
tr_list = html.xpath('//tbody/tr')
# print(tr_list)
for tr in tr_list:
item = {
} # 构造单词列表
en = self.get_text(tr.xpath('.//td[@class="span2"]/strong/text()'))
tra = self.get_text(tr.xpath('.//td[@class="span10"]/text()'))
print(en, tra)
if en:
item[en] = tra
self.word_list.append(item)
shanbei = Shanbei()
案例10:你喜欢的歌手来啦
- 需要把推荐歌手和入驻歌手去掉
- 链接:aHR0cHM6Ly9tdXNpYy4xNjMuY29tL2Rpc2NvdmVyL2FydGlzdA==
import requests,json
from lxml import etree
url = 'https://music.163.com/discover/artist'
singer_infos = []
# ---------------通过url获取该页面的内容,返回xpath对象
def get_xpath(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
response = requests.get(url, headers=headers)
return etree.HTML(response.text)
# --------------通过get_xpath爬取到页面后,我们获取华宇,华宇男等分类
def parse():
html = get_xpath(url)
fenlei_url_list = html.xpath('//ul[@class="nav f-cb"]/li/a/@href') # 获取华宇等分类的url
# print(fenlei_url_list)
# --------将热门和推荐两栏去掉筛选
new_list = [i for i in fenlei_url_list if 'id' in i]
for i in new_list:
fenlei_url = 'https://music.163.com' + i
parse_fenlei(fenlei_url)
# print(fenlei_url)
# -------------通过传入的分类url,获取A,B,C页面内容
def parse_fenlei(url):
html = get_xpath(url)
# 获得字母排序,每个字母的链接
zimu_url_list = html.xpath('//ul[@id="initial-selector"]/li[position()>1]/a/@href')
for i in zimu_url_list:
zimu_url = 'https://music.163.com' + i
parse_singer(zimu_url)
# ---------------------传入获得的字母链接,开始爬取歌手内容
def parse_singer(url):
html = get_xpath(url)
item = {
}
singer_names = html.xpath('//ul[@id="m-artist-box"]/li/p/a/text()')
# --详情页看到页面结构会有两个a标签,所以取第一个
singer_href = html.xpath('//ul[@id="m-artist-box"]/li/p/a[1]/@href')
# print(singer_names,singer_href)
for i, name in enumerate(singer_names):
item['歌手名'] = name
item['音乐链接'] = 'https://music.163.com' + singer_href[i].strip()
# 获取歌手详情页的链接
url = item['音乐链接'].replace(r'?id', '/desc?id')
# print(url)
parse_detail(url, item)
print(item)
# ---------获取详情页url和存着歌手名字和音乐列表的字典,在字典中添加详情页数据
def parse_detail(url, item):
html = get_xpath(url)
desc_list = html.xpath('//div[@class="n-artdesc"]/p/text()')
item['歌手信息'] = desc_list
singer_infos.append(item)
write_singer(item)
# ----------------将数据字典写入歌手文件
def write_singer(item):
with open('singer.json', 'a+', encoding='utf-8') as file:
json.dump(item,file)
if __name__ == '__main__':
parse()
案例11:你喜欢的歌手歌单来啦
- 链接:aHR0cHM6Ly93d3cua3Vnb3UuY29tL3l5L3Npbmdlci9pbmRleC8lcy0lcy0xLmh0bWw=
import json, requests
from lxml import etree
class KuDog:
def __init__(self):
self.base_url = 'https://www.kugou.com/yy/singer/index/%s-%s-1.html'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
self.parse()
# ---------------通过url获取该页面的内容,返回xpath对象
def get_xpath(self, url, headers):
try:
response = requests.get(url, headers=headers)
return etree.HTML(response.text)
except Exception:
print(url, '该页面没有相应!')
return ''
# --------------------通过歌手详情页获取歌手简介
def parse_info(self, url):
html = self.get_xpath(url, self.headers)
info = html.xpath('//div[@class="intro"]/p/text()')
return info[0]
# --------------------------写入方法
def write_json(self, value):
with open('kugou.json', 'a+', encoding='utf-8') as file:
json.dump(value, file)
# -----------------------------用ASCII码值来变换abcd...
def parse(self):
for j in range(97, 124):
# 小写字母为97-122,当等于123的时候我们按歌手名单的其他算,路由为null
if j < 123:
p = chr(j)
else:
p = "null"
for i in range(1, 6):
response = requests.get(self.base_url % (i, p), headers=self.headers)
# print(response.text)
html = etree.HTML(response.text)
# 由于数据分两个url,所以需要加起来数据列表
name_list1 = html.xpath('//ul[@id="list_head"]/li/strong/a/text()')
sing_list1 = html.xpath('//ul[@id="list_head"]/li/strong/a/@href')
name_list2 = html.xpath('//div[@id="list1"]/ul/li/a/text()')
sing_list2 = html.xpath('//div[@id="list1"]/ul/li/a/@href')
singer_name_list = name_list1 + name_list2
singer_sing_list = sing_list1 + sing_list2
# print(singer_name_list,singer_sing_list)
for i, name in enumerate(singer_name_list):
item = {
}
item['名字'] = name
item['歌单'] = singer_sing_list[i]
# item['歌手信息']=parse_info(singer_sing_list[i])#被封了
print(item)
self.write_json(item)
music = KuDog()

案例12:利用selenium+Phantomjs获取图书信息
由于数据有js方法写入,这里我们使用selenium+Phantomjs获取
import time, json
from lxml import etree
from selenium import webdriver
base_url = 'https://search.douban.com/book/subject_search?search_text=python&cat=1001&start=%s'
driver = webdriver.PhantomJS()
def get_text(text):
if text:
return text[0]
return ''
def parse_page(text):
html = etree.HTML(text)
div_list = html.xpath('//div[@id="root"]/div/div/div/div/div/div[@class="item-root"]')
# print(div_list)
for div in div_list:
item = {
}
''' 图书名称,评分,评价数,详情页链接,作者,出版社,价格,出版日期 '''
name = get_text(div.xpath('.//div[@class="title"]/a/text()'))
scores = get_text(div.xpath('.//span[@class="rating_nums"]/text()'))
comment_num = get_text(div.xpath('.//span[@class="pl"]/text()'))
detail_url = get_text(div.xpath('.//div[@class="title"]/a/@href'))
detail = get_text(div.xpath('.//div[@class="meta abstract"]/text()'))
if detail:
detail_list = detail.split('/')
else:
detail_list = ['未知', '未知', '未知', '未知']
# print(detail_list)
if all([name, detail_url]): # 如果名字和详情链接为true
item['书名'] = name
item['评分'] = scores
item['评论'] = comment_num
item['详情链接'] = detail_url
item['出版社'] = detail_list[-3]
item['价格'] = detail_list[-1]
item['出版日期'] = detail_list[-2]
author_list = detail_list[:-3]
author = ''
for aut in author_list:
author += aut + ' '
item['作者'] = author
print(item)
write_singer(item)
def write_singer(item):
with open('book.json', 'a+', encoding='utf-8') as file:
json.dump(item, file)
if __name__ == '__main__':
for i in range(10):
driver.get(base_url % (i * 15))
# 等待
time.sleep(2)
html_str = driver.page_source
parse_page(html_str)
案例13:某讯招聘
案例14:英雄联盟英雄和技能(selenium+phantomjs)
from selenium import webdriver
from lxml import etree
import requests, json
driver = webdriver.PhantomJS()
base_url = 'https://lol.qq.com/data/info-heros.shtml'
driver.get(base_url)
html = etree.HTML(driver.page_source)
hero_url_list = html.xpath('.//ul[@id="jSearchHeroDiv"]/li/a/@href')
hero_list = [] # 存放所有英雄的列表
for hero_url in hero_url_list:
id = hero_url.split('=')[-1]
# print(id)
detail_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/' + id + '.js'
# print(detail_url)
headers = {
'Referer': 'https://lol.qq.com/data/info-defail.shtml?id =4',
'Sec-Fetch-Mode': 'cors',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
response = requests.get(detail_url, headers=headers)
n = json.loads(response.text)
hero = [] # 存放单个英雄
item_name = {
}
item_name['英雄名字'] = n['hero']['name'] + ' ' + n['hero']['title']
hero.append(item_name)
for i in n['spells']: # 技能
item_skill = {
}
item_skill['技能名字'] = i['name']
item_skill['技能描述'] = i['description']
hero.append(item_skill)
hero_list.append(hero)
# print(hero_list)
with open('hero.json','w') as file:
json.dump(hero_list,file)
案例15:各个不同类型的好看电影
- 链接:aHR0cHM6Ly9tb3ZpZS5kb3ViYW4uY29tL2NoYXJ0
import json
import re, requests
from lxml import etree
# 获取网页的源码
def get_content(url, headers):
response = requests.get(url, headers=headers)
return response.text
# 获取电影指定信息
def get_movie_info(text):
text = json.loads(text)
item = {
}
for data in text:
score = data['score']
image = data['cover_url']
title = data['title']
actors = data['actors']
detail_url = data['url']
vote_count = data['vote_count']
types = data['types']
item['评分'] = score
item['图片'] = image
item['电影名'] = title
item['演员'] = actors
item['详情页链接'] = detail_url
item['评价数'] = vote_count
item['电影类别'] = types
print(item)
# 获取电影api数据的
def get_movie(type, url):
headers = {
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
n = 0
# 获取api数据,并判断分页
while True:
text = get_content(url.format(type, n), headers=headers)
if text == '[]':
break
get_movie_info(text)
n += 20
# 主方法
def main():
base_url = 'https://movie.douban.com/chart'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Referer': 'https://movie.douban.com/explore'
}
html_str = get_content(base_url, headers=headers) # 分类页首页
html = etree.HTML(html_str)
movie_urls = html.xpath('//div[@class="types"]/span/a/@href') # 获得每个分类的连接,但是切割type
for url in movie_urls:
p = re.compile('type=(.*?)&interval_id=')
type_ = p.search(url).group(1)
ajax_url = 'https://movie.douban.com/j/chart/top_list?type={}&interval_id=100%3A90&action=&start={}&limit=20'
get_movie(type_, ajax_url)
if __name__ == '__main__':
main()
案例16:分析北京的房子都是什么样
链接:aHR0cHM6Ly9iai5mYW5nLmxpYW5qaWEuY29tL2xvdXBhbi8=
- 1、获取所有的城市的拼音
- 2、根据拼音去拼接url,获取所有的数据。
- 3、列表页:楼盘名称,均价,建筑面积,区域,商圈详情页:户型([“8室5厅8卫”, “4室2厅3卫”, “5室2厅2卫”]),朝向,图片(列表),用户点评(选爬)
问题1:
当该区没房子的时候,猜你喜欢这个会和有房子的块class一样,因此需要判断

问题2:
获取每个区的页数,使用js将页数隐藏
https://bj.fang.lianjia.com/loupan/区/pg页数%s
我们可以发现规律,明明三页,当我们写pg5时候,会跳转第一页
因此我们可以使用while判断,当每个房子的链接和该区最大房子数相等代表该区爬取完毕

代码:
import requests
from lxml import etree
# 获取网页源码
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
response = requests.get(url, headers=headers)
return response.text
# 获取城市拼音列表
def get_city_url():
url = 'https://bj.fang.lianjia.com/loupan/'
html = etree.HTML(get_html(url))
city = html.xpath('//div[@class="filter-by-area-container"]/ul/li/@data-district-spell')
city_url = ['https://bj.fang.lianjia.com/loupan/{}/pg%s'.format(i) for i in city]
return city_url
# 爬取对应区的所有房子url
def get_detail(url):
# 使用第一页来判断是否有分页
html = etree.HTML(get_html(url % (1)))
empty = html.xpath('//div[@class="no-result-wrapper hide"]')
if len(empty) != 0: # 不存在此标签代表没有猜你喜欢
i = 1
max_house = html.xpath('//span[@class="value"]/text()')[0]
house_url = []
while True: # 分页
html = etree.HTML(get_html(url % (i)))
house_url += html.xpath('//ul[@class="resblock-list-wrapper"]/li/a/@href')
i += 1
if len(house_url) == int(max_house):
break
detail_url = ['https://bj.fang.lianjia.com/' + i for i in house_url] # 该区所有房子的url
info(detail_url)
# 获取每个房子的详细信息
def info(url):
for i in url:
item = {
}
page = etree.HTML(get_html(i))
item['name'] = page.xpath('//h2[@class="DATA-PROJECT-NAME"]/text()')[0]
item['price_num'] = page.xpath('//span[@class="price-number"]/text()')[0] + page.xpath(
'//span[@class="price-unit"]/text()')[0]
detail_page = etree.HTML(get_html(i + 'xiangqing'))
item['type'] = detail_page.xpath('//ul[@class="x-box"]/li[1]/span[2]/text()')[0]
item['address'] = detail_page.xpath('//ul[@class="x-box"]/li[5]/span[2]/text()')[0]
item['shop_address'] = detail_page.xpath('//ul[@class="x-box"]/li[6]/span[2]/text()')[0]
print(item)
def main():
# 1、获取所有的城市的拼音
city = get_city_url()
# 2、根据拼音去拼接url,获取所有的数据。
for url in city:
get_detail(url)
if __name__ == '__main__':
main()

多线程版:
import requests, threading
from lxml import etree
from queue import Queue
import pymongo
class House(threading.Thread):
def __init__(self, q=None):
super().__init__()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
self.q = q
# 获取网页源码
def get_html(self, url):
response = requests.get(url, headers=self.headers)
return response.text
# 获取城市拼音列表
def get_city_url(self):
url = 'https://bj.fang.lianjia.com/loupan/'
html = etree.HTML(self.get_html(url))
city = html.xpath('//div[@class="filter-by-area-container"]/ul/li/@data-district-spell')
city_url = ['https://bj.fang.lianjia.com/loupan/{}/pg%s'.format(i) for i in city]
return city_url
# 爬取对应区的所有房子url
def get_detail(self, url):
# 使用第一页来判断是否有分页
html = etree.HTML(self.get_html(url % (1)))
empty = html.xpath('//div[@class="no-result-wrapper hide"]')
if len(empty) != 0: # 不存在此标签代表没有猜你喜欢
i = 1
max_house = html.xpath('//span[@class="value"]/text()')[0]
house_url = []
while True: # 分页
html = etree.HTML(self.get_html(url % (i)))
house_url += html.xpath('//ul[@class="resblock-list-wrapper"]/li/a/@href')
i += 1
if len(house_url) == int(max_house):
break
detail_url = ['https://bj.fang.lianjia.com/' + i for i in house_url] # 该区所有房子的url
self.info(detail_url)
# 获取每个房子的详细信息
def info(self, url):
for i in url:
item = {
}
page = etree.HTML(self.get_html(i))
item['name'] = page.xpath('//h2[@class="DATA-PROJECT-NAME"]/text()')[0]
item['price_num'] = page.xpath('//span[@class="price-number"]/text()')[0] + page.xpath(
'//span[@class="price-unit"]/text()')[0]
detail_page = etree.HTML(self.get_html(i + 'xiangqing'))
item['type'] = detail_page.xpath('//ul[@class="x-box"]/li[1]/span[2]/text()')[0]
item['address'] = detail_page.xpath('//ul[@class="x-box"]/li[5]/span[2]/text()')[0]
item['shop_address'] = detail_page.xpath('//ul[@class="x-box"]/li[6]/span[2]/text()')[0]
print(item)
def run(self):
# 1、获取所有的城市的拼音
# city = self.get_city_url()
# 2、根据拼音去拼接url,获取所有的数据。
while True:
if self.q.empty():
break
self.get_detail(self.q.get())
if __name__ == '__main__':
# 1.先获取区列表
house = House()
city_list = house.get_city_url()
# 2.将去加入队列
q = Queue()
for i in city_list:
q.put(i)
# 3.创建线程任务
a = [1, 2, 3, 4]
for i in a:
p = House(q)
p.start()
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183629.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...