大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
1:业务场景引入
1:需求①
原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中?
解决方案1:将10亿个号码存入数据库中,进行数据库查询,准确性有了,但是速度会比较慢。
解决办法二:将10亿号码放入内存中,比如Redis缓存中,这里我们算一下占用内存大小:10亿*8字节=8GB,通过内存查询,准确性和速度都有了,但是大约8gb的内存空间,挺浪费内存空间的。
2:需求②
接触过爬虫的,应该有这么一个需求,需要爬虫的网站千千万万,对于一个新的网站url,我们如何判断这个url我们是否已经爬过了?
解决办法还是上面的两种,很显然,都不太好。
3:需求③
同理还有垃圾邮箱的过滤
那么对于类似这种,大数据量集合,如何准确快速的判断某个数据是否在大数据量集合中,并且不占用内存,布隆过滤器应运而生了。
2:布隆过滤器原理分析
布隆过滤器:一种数据结构,是由一串很长的二进制向量组成,可以将其看成一个二进制数组。
1:初始化
既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。

2:添加数据
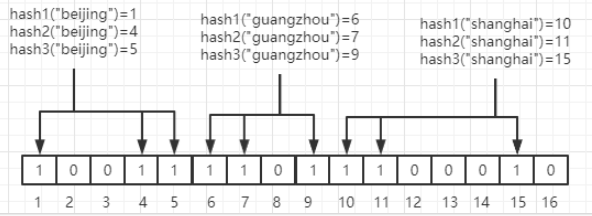
假如有三个hash函数和一个位数组,beijing经过三个hash函数,得到第1、4、5位为1,guangzhou同理得到6、7、9位1,以及shanghai得到10,11,15位为1
3:判断数据是否存在

知道了如何向布隆过滤器中添加一个数据,那么新来一个数据,我们如何判断其是否存在于这个布隆过滤器中呢?
我们只需要将这个新的数据通过上面的3个哈希函数,分别算出各个值,然后看其对应的地方是否都是1,如果存在一个不是1的情况,那么我们可以说,该新数据一定不存在于这个布隆过滤器中。
反过来说,如果通过哈希函数算出来的值,对应的地方都是1,那么我们能够肯定的得出:这个数据一定存在于这个布隆过滤器中吗?
答案是否定的。因为多个不同的数据通过hash函数算出来的结果是会有重复的,所以会存在某个位置是别的数据通过hash函数置为的1。
如上图所示,对于新的数据shenzhen,进过hash函数计算得到2,5,10,此时实际上shenzhen是不存在的。
因此:我们可以得到一个结论:布隆过滤器可以判断某个数据一定不存在,但是无法判断一定存在。
4:优缺点
布隆过滤器是用于判断一个元素是否在集合中。通过一个位数组和N个hash函数实现。
优点:
空间效率高,所占空间小。
插入和查询时间短。
缺点:
元素添加到集合中后,不能被删除
无法判断数据一定存在
有一定的误判率
3:与常规集合set的比较
布隆过滤器有一点的误识别率,但是其有2大优点,使得这个缺点在某些应用场景中是可以接受的。2大优点是空间效率和查询时间都远远高于一般的算法。
常规的数据结构set,也是经过被用于判断一个元素是否在集合中,但如果有上百万甚至更高的数据,set结构所占的空间将是巨大的,布隆过滤器只需要上百万个位即可,10多Kb即可。
4:布隆过滤器缺点分析
导致误判率这个缺点是因为hash碰撞,但布隆过滤器通过多个hash函数来降低hash碰撞带来的误判率,如下图:
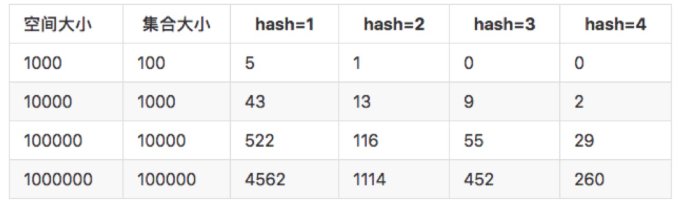
当只有1个hash函数的时候,误判率很高,但4个hash函数的时候已经缩小10多倍,可以动态根据业务需求所允许的识别率来调整hash函数的个数,当然hash函数越多,所带来的空间效率和查询效率也会有所降低。
第二个缺点相对set来说,不可以删除,因为布隆过滤器并没有存储key,而是通过key映射到位数组中。
5:使用场景
1:防止缓存穿透
缓存宕机、缓存击穿场景,一般判断用户是否在缓存中,如果在则直接返回结果,不在则查询db,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查询到,则穿透到db。如果不在布隆器中,则直接返回。
首先什么是缓存穿透,缓存穿透就是攻击者发起请求查询很多很多个redis和mysql中都不存在的key,由于这个key不存在于redis中,于是服务器会去请求mysql,但是在mysql中也找不到相应的记录。此时请求全都打在了mysql上,导致数据库压力剧增,甚至可能崩溃。
如何使用布隆过滤器防止缓存穿透
例如,某个接口是通过id来查找数据的,那么可以将数据库中这个表的所有id添加都布隆过滤器中。当用户请求这个接口,传入一个id的时候,就检验这个id是否在布隆过滤器中,如果不存在说明数据库中不存在这个id,此时直接返回空即可。
当然,使用布隆过滤器防缓存穿透有一定的缺点:
1.误判:可能有些实际上不存在的id被布隆过滤器判定为存在。
2.删除困难:加入数据库对某条数据进行删除,此时我们无法在布隆过滤器中删除这个id元素。因为删除了这个id就会将它对应的位从1设为0,这可能会影响到其他id的位。
解决办法:
针对误判,我们可以通过调整哈数函数的个数和布隆过滤器的位长度来降低误判率。这样即使真的有漏网之鱼打到了DB中也不多,对DB的性能影响不大。
针对删除困难,我们可以对数据库的数据不真正删除,而是进行软删除。所谓软删除就是不从表中删除某条记录,而是增加一个状态字段,将这行记录的状态字段设为已删除状态。
2:判断用户是否阅读
业务场景中判断用户是否阅读过某视频或文章,比如抖音或头条,当然会导致一定的误判,但不会让用户看到重复的内容。这些可以使用布隆过滤器,减少不在的用户查询db或缓存的次数。
3:WEB拦截器
如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中。可以提高缓存命中率。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185155.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
