大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
2.Keras建立多层感知器模型(接上一篇)
2.1简单介绍多层感知器模型
注:以下模型及其说明来自于《TensorFlow+Keras深度学习人工智能实践应用》林大贵 著
以矩阵方式仿真多层感知器模型的工作方式(如下图所示)


建立输入与隐藏层的公式:
h1=ReLu(x*w1+b1)
| 变量名 | 说明 |
|---|---|
| 输入层 | x仿真输入神经元接收外界传送消息,如上图所示,共有784个神经元。 |
| 隐藏层h1 | 隐藏层h1模拟内部神经元,如上图所示,共有256个隐藏神经元。 |
| 权重 | 权重模拟神经元的轴突,连接输入与接收神经元,负责传送信息。连接输入层(784个神经元)与隐藏层(256个神经元),为了让两层的每一个神经元都相互连接,总共需要784*256=200704个突触。所以w1(权重)必须是784*256的矩阵,用来模拟这些突触的功能。 |
| 偏差值b1 | 偏差值b1仿真突触的结构,代表接收神经元容易被活化的程度,偏差值越高,越容易被活化并传递信息。如上图所示,因为隐藏层共有256个神经元,所以偏差值是长度为256的向量。 |
| 激活函数 | 激活函数仿真神经传导的工作方式,在此我们使用ReLu激活函数接收刺激的总和:(x*w1+b1),经过激活函数ReLu的运算,大于临界值时,会传递至下一个神经元。 |
建立隐藏层与输出层公式:
y=softmax(h1*w2+b2)
| 变量名 | 说明 |
|---|---|
| 隐藏层h1 | 隐藏层h1模拟内部神经元,共有256个隐藏神经元。 |
| 输出层y | 模拟输出神经元,就是预测的结果,共有10个输出神经元。对应我们希望预测的数字,从0到9共有10个结果。 |
| 权重w2 | 权重模拟神经元的轴突,连接输入与接收神经元,负责传送信息。连接隐藏层(256个神经元)与输出层(10个神经元),为了让两层的每一个神经元互相连接,总共需要25610=2560个轴突。所以(w2)权重必须是25610的矩阵,用来模拟这些轴突的功能。 |
| 偏差值b2 | 偏差值b2仿真突触的结构,代表接收神经元容易被活化的程度,偏差值越高,越容易被活化并传递信息。如上图所示,因为接收神经元是输出层(10个神经元),所以偏差值是长度为10的向量。 |
| 激活函数 | 在输出层中,我们使用softmax激活函数,接收刺激的总和(w2*h1+b2)经过softmax运算后的输出是一个概率分布,共有10个输出,数值越高代表概率越高,例如输出结果由0算起第5个数字数值最高,代表预测结果是5。 |
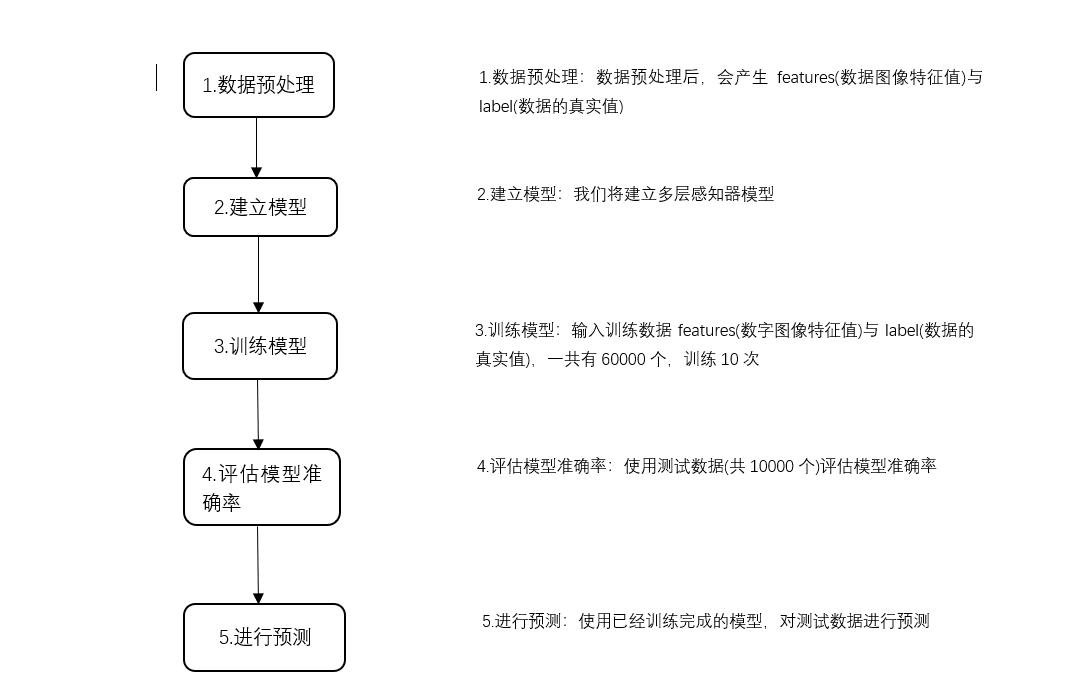
2.2建立多层感知器模型的步骤
建立多层感知器模型识别MNIST数据集中的手写数字步骤如下图所示
2.3对数据进行预处理
输入上一篇文章讲到的关键代码
import numpy as np #导入相关包
import pandas as pd
from keras.utils import np_utils
from keras.datasets import mnist
np.random.seed(10)
(X_train_image,y_train_label),(X_test_image,y_test_label)=mnist.load_data() #读取MNIST数据
import matplotlib.pyplot as plt
def plot_image(image): #定义显示某个数字图像的函数
fig=plt.gcf()
fig.set_size_inches(2,2)
plt.imshow(image,cmap='binary')
plt.show()
def plot_images_labels_prediction(images,labels,prediction,idx,num=10): #定义显示features,labels和prediction的函数
fig=plt.gcf()
fig.set_size_inches(12,14)
if num>25:
num=25
for i in range(0,num):
ax=plt.subplot(5,5,1+i)
ax.imshow(images[idx],cmap='binary')
title="label="+str(labels[idx])
if len(prediction)>0:
title+=",prediction="+str(prediction[idx])
ax.set_title(title,fontsize=10)
ax.set_xticks([])
ax.set_yticks([])
idx+=1
plt.show()
X_Train=X_train_image.reshape(60000,784).astype('float32') #将特征值转换为一维向量
X_Test=X_test_image.reshape(10000,784).astype('float32')
X_Train_normalize=X_Train/255 #将一维向量的数字标准化
X_Test_normalize=X_Test/255
y_TrainOneHot=np_utils.to_categorical(y_train_label) #将labels转换为One-Hot Encoding
y_TestOneHot=np_utils.to_categorical(y_test_label)
2.4建立模型并开始训练
导入相关模块
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
建立Sequential模型,并且加入‘’输入层“,”Dropout功能“和”输出层“
model=Sequential() #建立模型
model.add(Dense(units=256, #定义”隐藏层“神经元个数为256
input_dim=784, #定义”输入层“神经元个数为784,因为28*28=784
kernel_initializer='normal', #使用normal distribution正态分布来初始化权重(weight)和偏差
activation='relu')) #定义激活函数为relu
model.add(Dropout(0.5)) #加入Doupout功能,防止过拟合
model.add(Dense(units=10, #定义”输出层“神经元个数为10,代表0~9个数
kernel_initializer='normal',
activation='softmax')) #激活函数为softmax
定义训练方式
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
各参数的解释如下表
| 参数名 | 说明 |
|---|---|
| loss | 设置损失函数,在深度学习中使用cross_entropy(交叉熵)训练的效果比较好 |
| optimizer | 设置训练时,在深度学习中使用adam优化器可以让训练速度更快,还可以提高准确率 |
| metrics | 设置评估模型的方式是准确率 |
接下来开始训练
train_history=model.fit(x=X_Train_normalize,y=y_TrainOneHot,validation_split=0.2,epochs=10,batch_size=200,verbose=2)
| 参数名 | 说明 |
|---|---|
| x=X_Train_normalize | x代表要输入的特征值,所以将输入特征X_Train_normalize赋值给x |
| y=y_TrainOneHot | y代表要输入的标签,所以将标签值y_TrainOneHot赋给y |
| validation_split=0.2 | 表示要把训练数据集中的80%用于训练模型,20%用于验证模型 |
| epochs=10 | 表示要训练10个周期 |
| batch_size=200 | 表示每个周期中的每一批次的数据量大小是200 |
| verbose=2 | 显示训练过程 |
| train_history | 训练结果会保存在train_history中 |
执行代码,运行结果如下
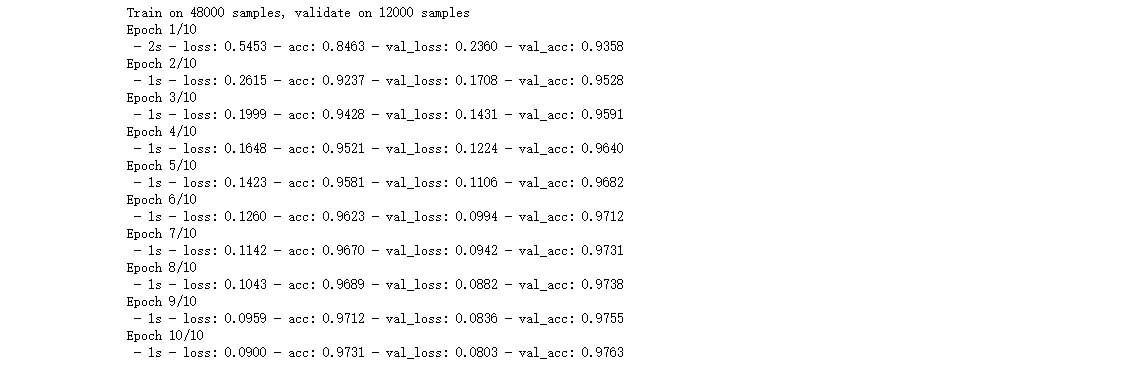
可以看到,训练样本原来是60000的,把其中的48000作为训练集,剩下的12000作为验证集。另外,我们还注意到,loss(训练集的损失函数)和val_loss(验证集的损失函数)在逐步减小,acc(训练集的准确率)和val_acc(验证集的准确率)在提升。
接下来我们定义一个函数显示训练过程
def show_train_history(train_histroy,train,validation): #输入参数为train_history和train_histroy.history中的索引train,validation
plt.plot(train_histroy.history[train]) #train_histroy.history是一个字典
plt.plot(train_history.history[validation])
plt.title('Train Histroy')
plt.ylabel(train)
plt.xlabel('epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
画出准确率曲线
show_train_history(train_history,'acc','val_acc')
执行结果
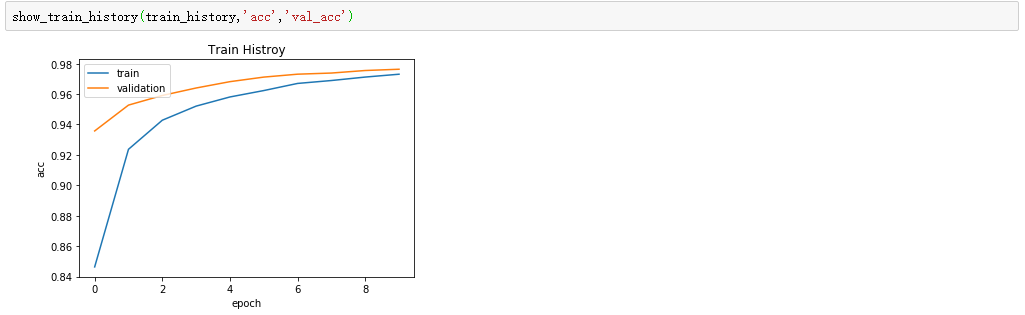
可以看到,训练和验证的准确率都随着epoch增加而增加,即准确率越来越高。
顺便再看下损失函数的曲线图
show_train_history(train_history,'loss','val_loss')
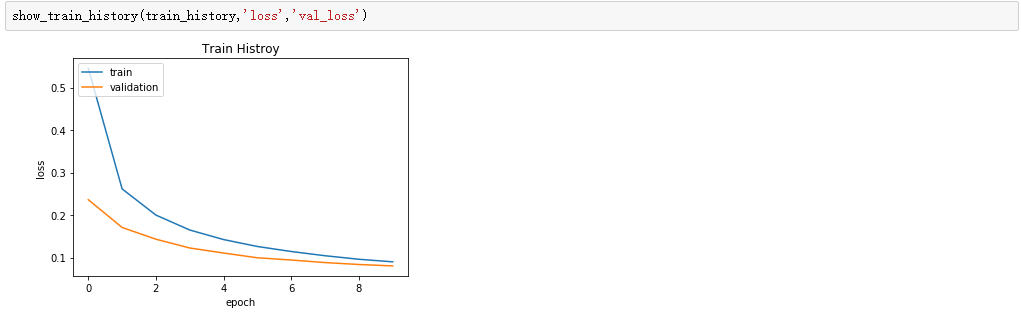
损失函数在逐步减小。
接下来,模型训练完后,在开始预测前,我们先评估一下训练模型的准确率是多少
scores=model.evaluate(X_Test_normalize,y_TestOneHot)
print(scores)
运行结果

说明:X_Test_normalize为测试集,y_TestOneHot为标签,scores的第一项为损失函数,第二项为准确率,可以看到用测试集评估该模型的准确率为0.9768。
最后,开始预测
prediction=model.predict_classes(X_Test)
我们看下前25项的预测结果
plot_images_labels_prediction(X_test_image,y_test_label,prediction,idx=1,num=25)
运行结果
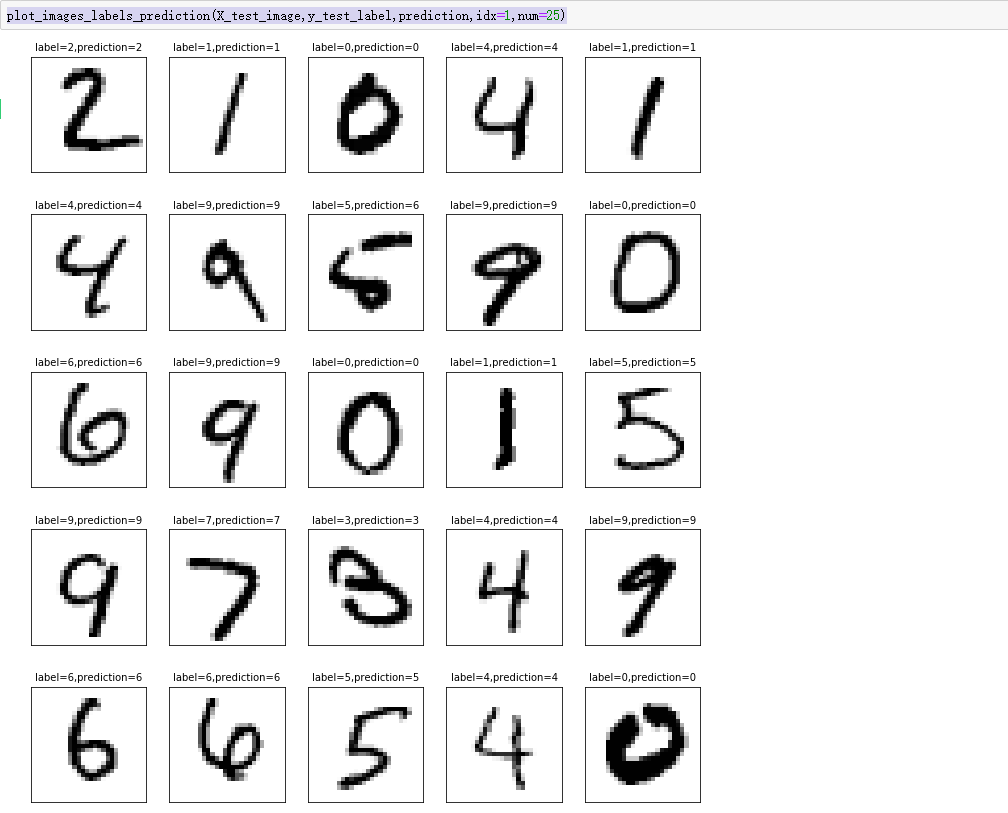
容易得知,10000个测试数据中肯定有预测错的,我们可以定义一个函数来查看预测错误的数量和图形
def show_wrong(images,labels,prediction):
fig=plt.gcf()
fig.set_size_inches(20,60)
array=[]
for i in range(0,10000):
if(str(labels[i])!=str(prediction[i])): #把测试集的标签和预测结果进行比较,不相等的就是预测错误的,用一个数组保存不相等的索引
array.append(i)
for i in range(0,len(array)):
ax=plt.subplot(30,8,1+i)
ax.imshow(images[array[i]],cmap='binary')
title="label="+str(labels[array[i]])+",prediction="+str(prediction[array[i]])
ax.set_title(title,fontsize=12)
ax.set_xticks([])
ax.set_yticks([])
plt.show()
print("预测错误的一共有"+str(len(array))+"个")
运行
show_wrong(x_Test,y_Test,prediction)
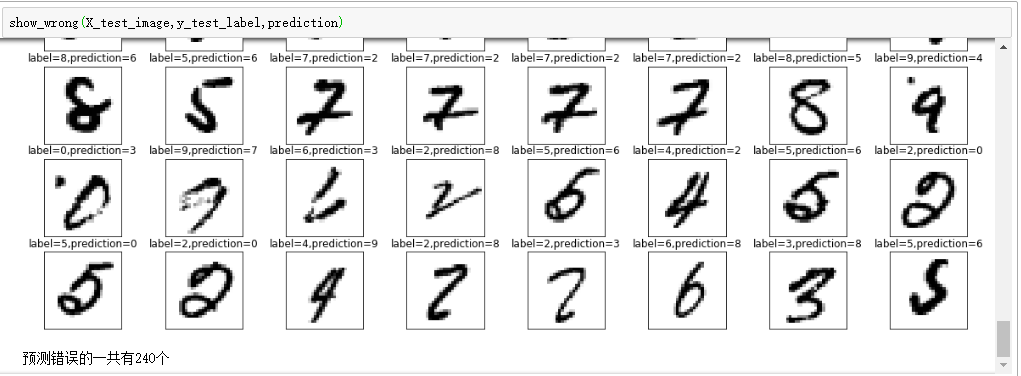
由于一共有240个图形是被预测错误的,篇幅较长,所以只截了最后的一小部分图
另外,我们还可以建立一个混淆矩阵来统计查看什么数字的预测准确率最高,哪些数字最容易被预测错误。
这里用pandas建立一个混淆矩阵
import pandas as pd
pd.crosstab(y_test_label,prediction,rownames=['lable'],colnames=['prediction'])
运行结果

根据经验,可以看出多层感知器模型识别的准确率不是很高,只有0.9768,要想提高准确率,还可以增加隐藏层神经元的个数,但是这样做会增加训练的时间,并且效率也很低,本人试过把隐藏层的神经元个数增加到1000个,准确率是0.9779,或者再增加一个隐藏层,得到的准确率是0.9797。如果想进一步提高准确率,就应该使用卷积神经网络了。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184297.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
