大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
1启动kettle
(1) 在存储kettle工具的文件夹里打开,看到如上图 所示红色箭头指向 的data-integration 文件夹


(2) 双击打开这个文件夹,找到 Spoon.bat ,双击启动,如上图位置所示。
(3) 启动后,打开的页面如上图所示;
2.建立一个工作 Job
(1)新建一个 job,单击左上角点击 新建 作业,如下图所示:
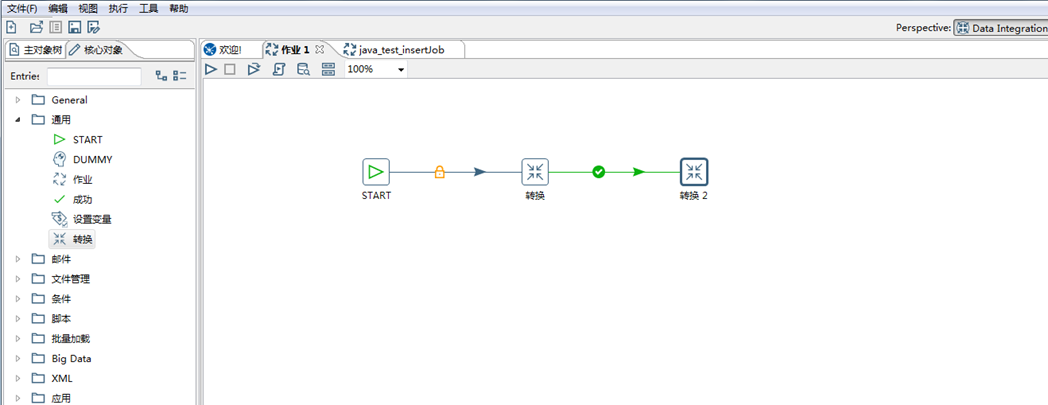
(2)点击通用,双击 START;双击转换;一个Job工作建立。效果如下图所示
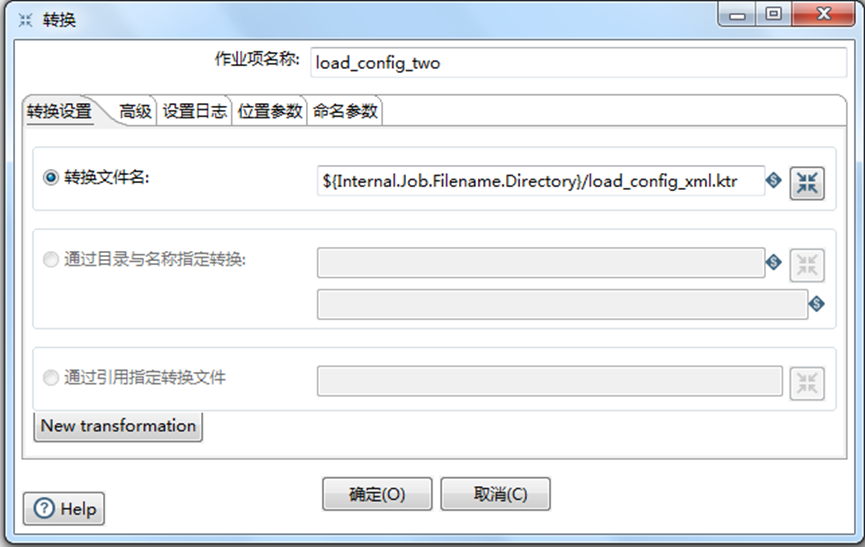
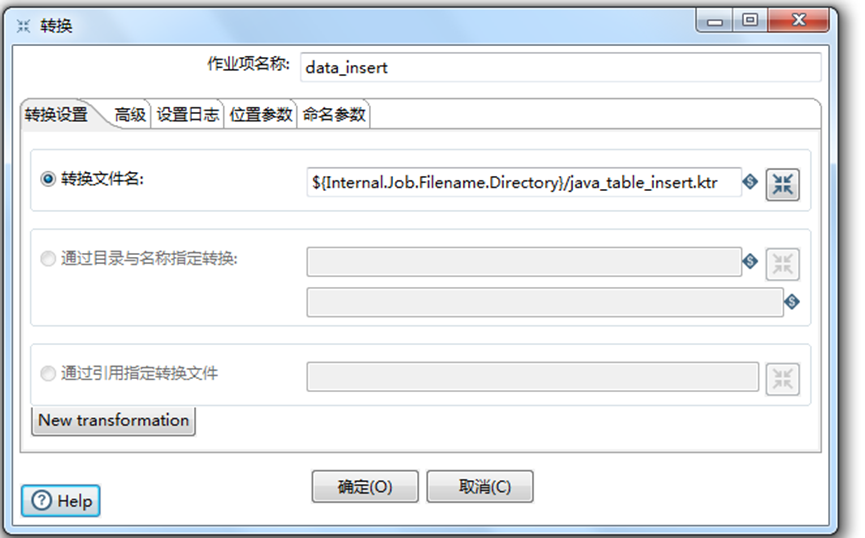
(4) 双击 转换,如下图所示:作业项名称 是修改 该转换的名称,转换 文件名是配置地址获取转换信息的,一般配置名为: I n t e r n a l . J o b . F i l e n a m e . D i r e c t o r y / ? ? ? . k t r 如 转 换 名 称 为 {Internal.Job.Filename.Directory}/???.ktr 如转换名称为 Internal.Job.Filename.Directory/???.ktr如转换名称为{Internal.Job.Filename.Directory}/load_config_xml.ktr
(5) 双击 转换2,如下图所示:作业项名称 是修改 该转换的名称,转换 文件名是配置地址获取转换信息的,一般配置名为: I n t e r n a l . J o b . F i l e n a m e . D i r e c t o r y / ? ? ? . k t r 如 转 换 名 称 为 {Internal.Job.Filename.Directory}/???.ktr 如转换名称为 Internal.Job.Filename.Directory/???.ktr如转换名称为{Internal.Job.Filename.Directory}/java_table_insert.ktr
(5) 选择保存 这个新建的 job,必须要指定一个固定的文件夹,方便以后修改与维护,同时也是为了读取配相关的信息,以免导致程序执行异常。
3新建转换操作
(1),由上一部操作步骤可知,新建了两个转换工作。第一个转换 是配置数据库读写环境配置(比如是 load_config_xml.ktr),
左点击 左上角的文件,新建转换,并命名为load_config_xml
A,点击输入,双击 XML输入,点击作业,双击 设置变量 如下图所示
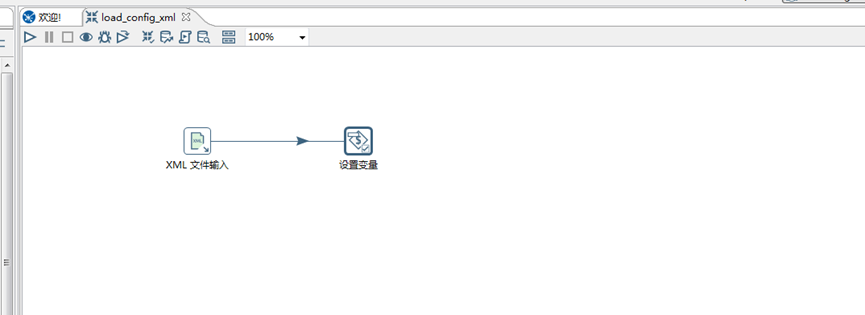
B,在刚才保存job 指定的文件夹,新建一个 xml文件(比如 config.xml),如下图所示:
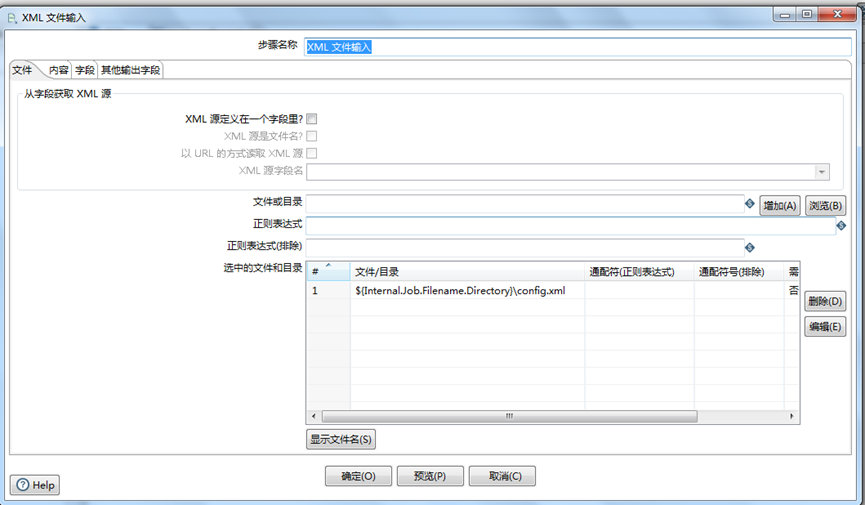
C.双击 XML文件输入,输入配置${Internal.Job.Filename.Directory}\config.xml 这个目录,配置形式如下图所示
D.双击 设置变量,根据config.xml里面的变量配置,编写如下图所示的变量引用配置
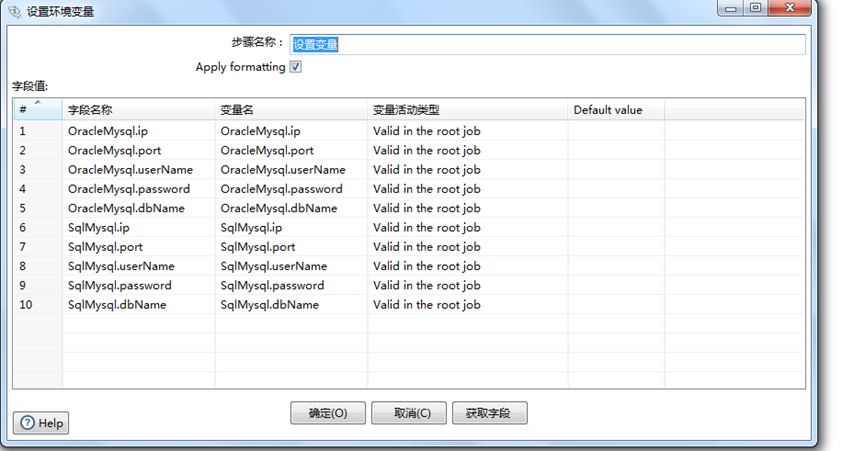
E.保存这个转化操作,保存到和 job存储的同一个文件夹
(2).新建第二个 转换操作,该转换 是为了把数据 从一个数据库 移步插入到 另一个数据库,
左点击 左上角的文件,新建转换,并命名为java_table_insert
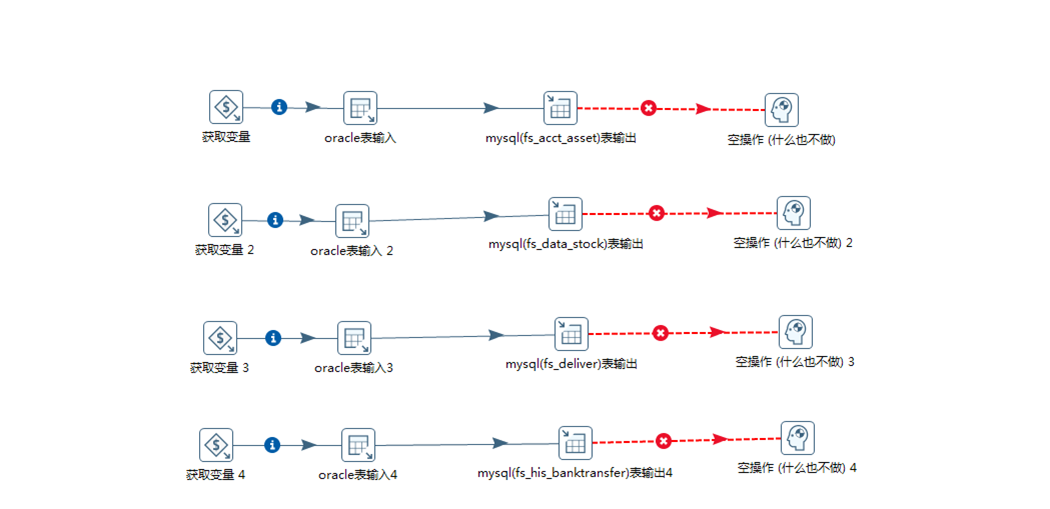
A. 点击作业,双击 获取变量;点击表输入,双击 表输入;点击 表输出,双击表输出;点击 流程, 双击 空操作,效果图 如下图所示
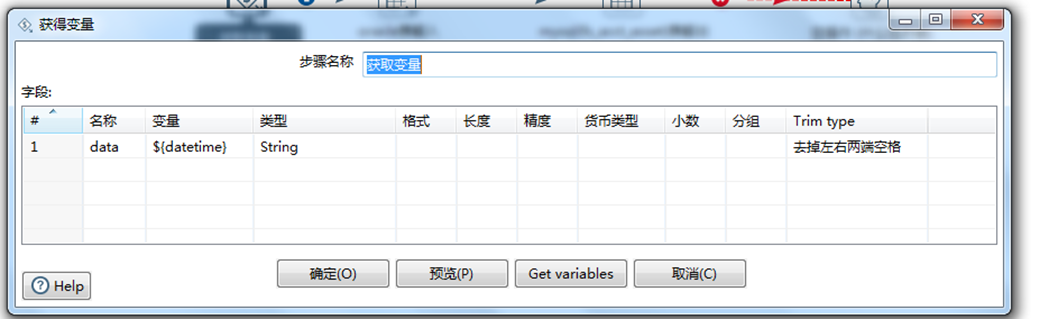
B.双击 获取变量,配置变量如下图所示,datetime 必须要和 后台代码离的变量名 一样
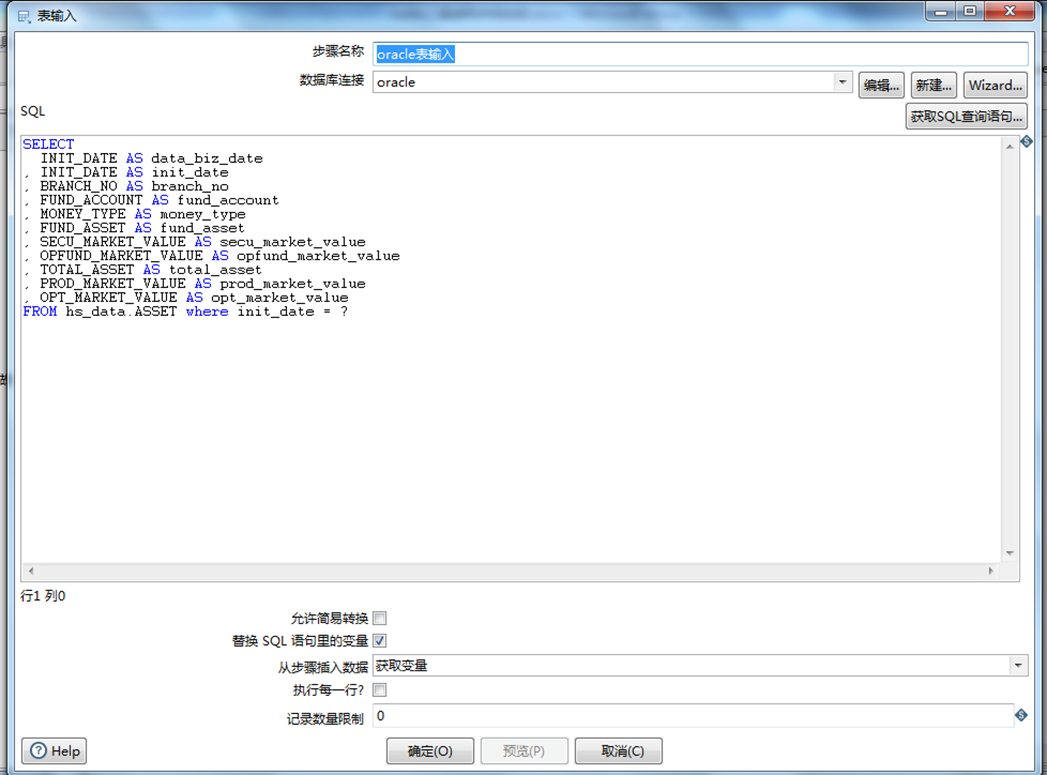
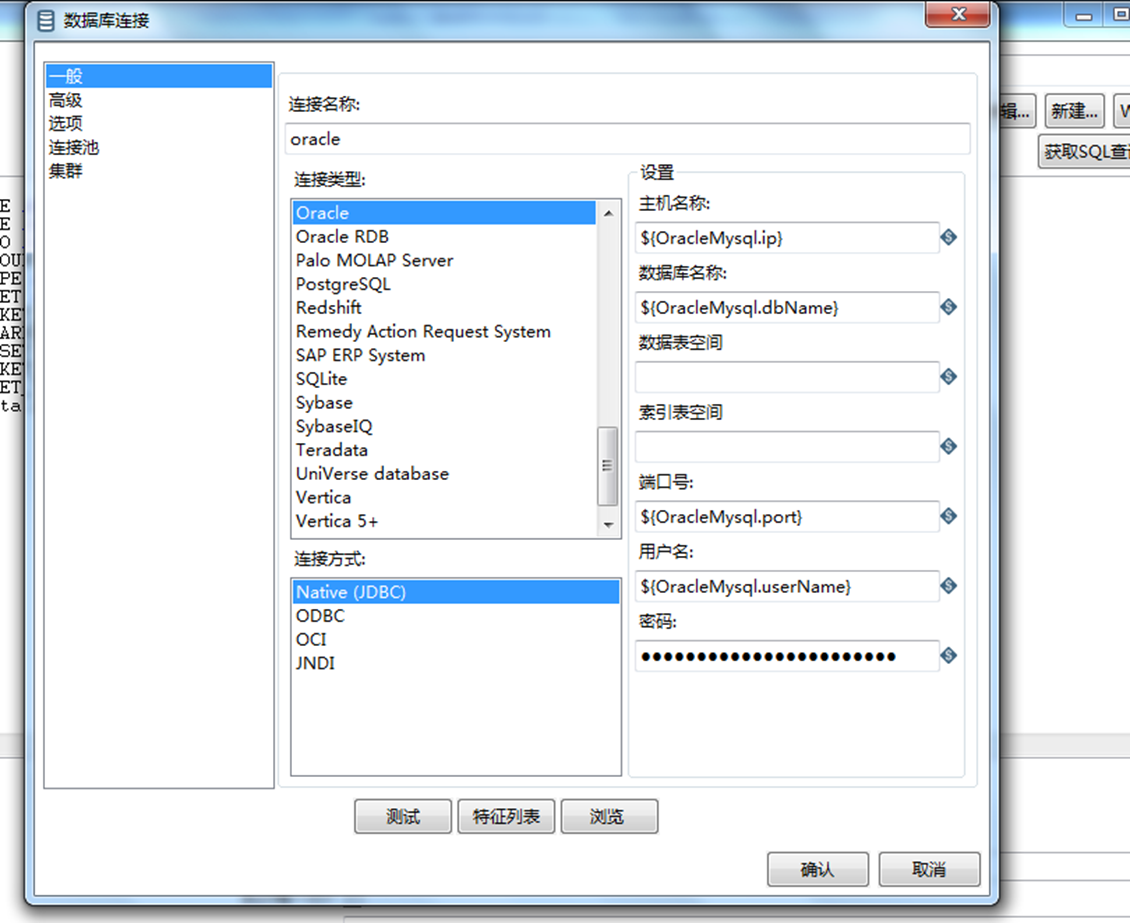
C.双击 表输入,点击 新建,配置文件(包括查询的 SQL语句 和 数据库服务器配置环境,查询的字段 必须要与 同步的插入的另一个数据库字段要一致,如果没有必要,可设置字段为空) 如下图所示
D.双击 表输出,点击 新建,配置文件(包括配置插入的表名 和 数据库服务器配置环境) 如下图所示
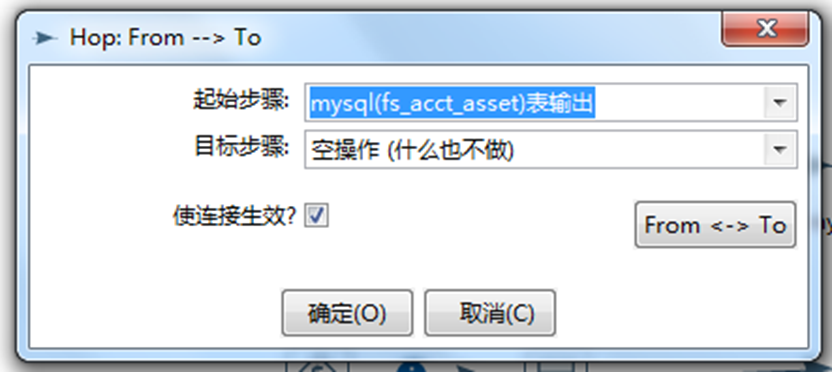
E.编辑空操作 ,主要是针对 表输入数据库出现重复数据 和 执行出现的一些非代码类型异常 而导致整个job工作出现异常的不执行操作。效果图配置如下
4.判断数据移步是否成功?(从一个环境把数据同步到另一个环境)
A.新建一个转换 操作(如下图 his_bantransfer)
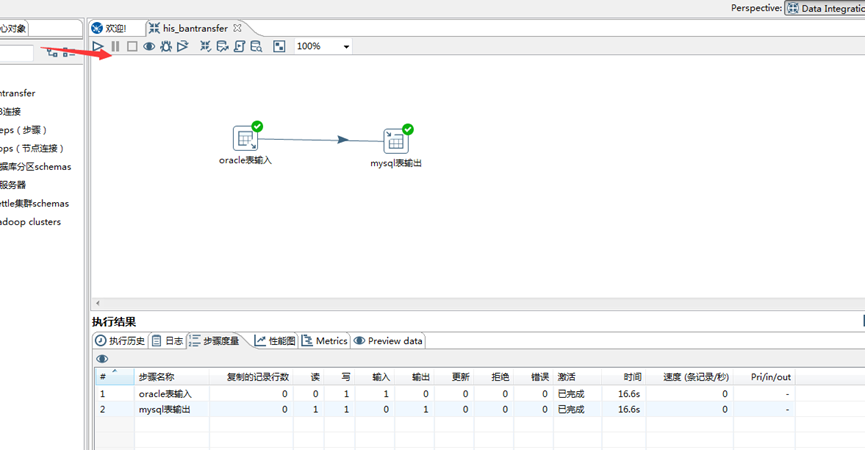
B. 点击 如下图红箭头指向的 按钮,界面如图所示,执行成功
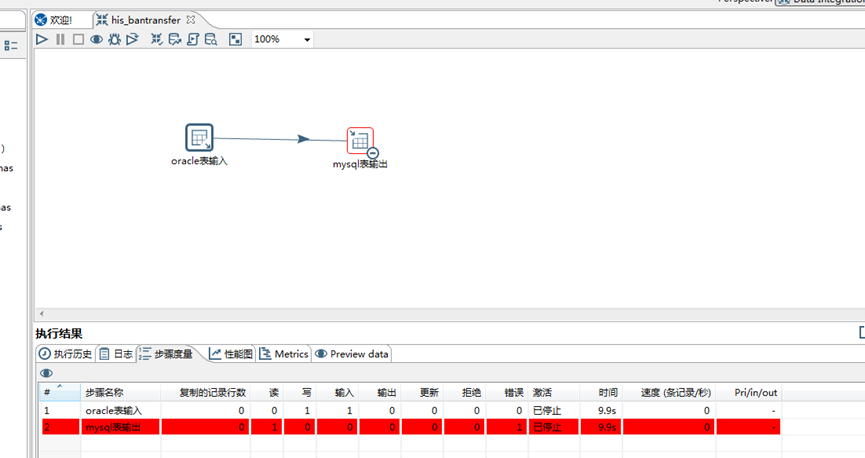
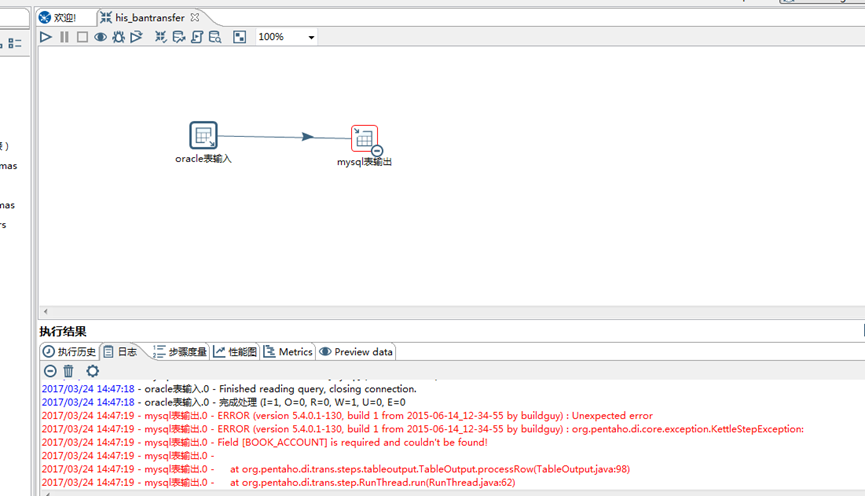
C,点击 如下图红箭头指向的 按钮,页面 出现如下图的红色标志,说明数据没有执行迁移成功,请点击 日志查看,会有提示说明;对症修改即可
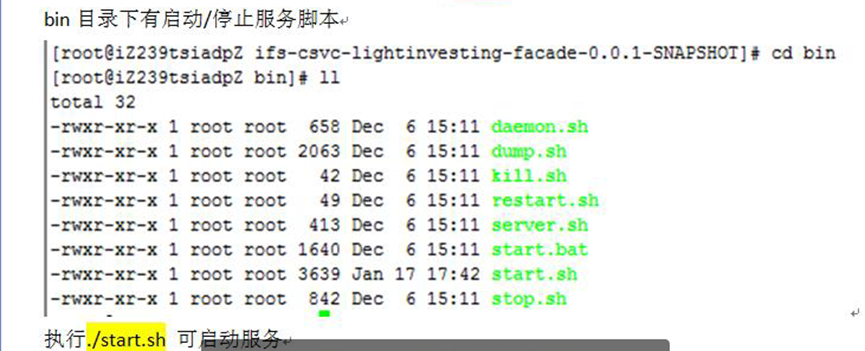
5.kettle工具部署和后台配置 启动
1、在linux环境目录下 新建一个kettle文件夹(放在 root或home 文件夹下都可以)
2、把 data-integration 这个工具文件夹粘贴在 kettle文件夹下面
3、把 data_insert_kettle 这个文件夹也放在kettle文件夹下面,并且与 data-integration这个文件夹是并行独立关系
4、配置文件中配置 (所以配置文件都放在data_insert_kettle 这个文件夹里)
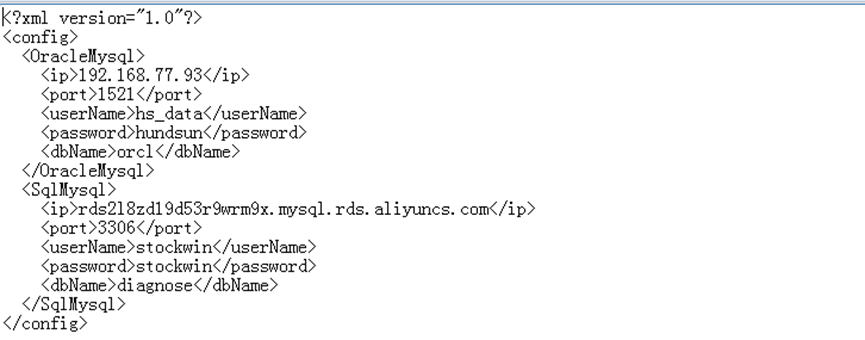
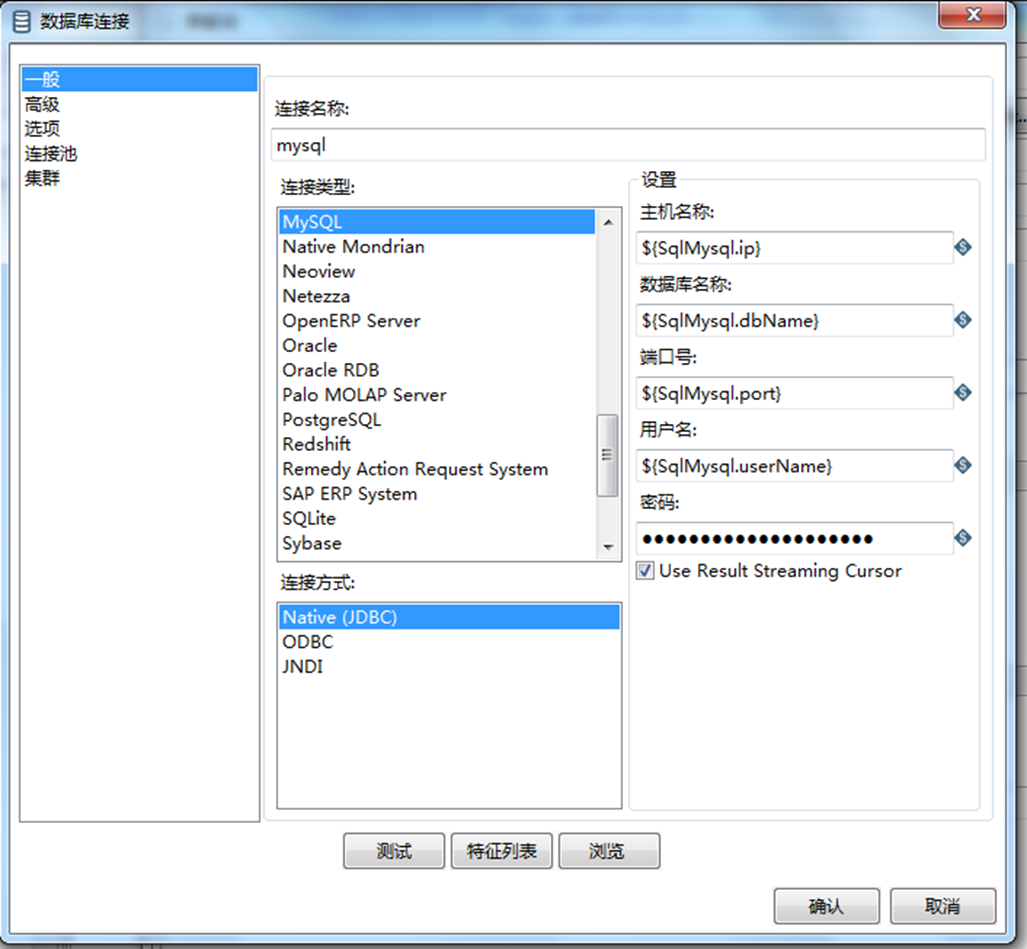
(1)、数据库服务器是配置在config.xml里, 配置的是oracl环境,获取的是用户中心那边的数据
配置的是 mysql环境,添加到开发本地数据库
(2)、java_test_insertJob.kjb 它是一个job命令,不需要修改,只负责执行
(3)、java_table_insert.ktr 它是一个转换,所有的获取数据条件和sql语句编写 、数据插入库均在这个转换里完成,要增加或改变也需 要在这里完成,然后把这个转换升级到服务器环境里就可以了
(4)、fstock.biz.trade.job.job_address_url= /root/kettle/data_insert_kettle/java_test_insert.kjb
这个url路径要在com.hundson.diagnose.front目录下的 profile.dev.properties 里配置
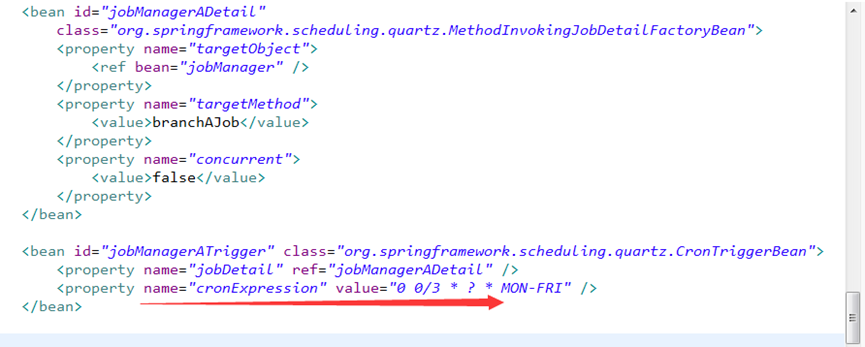
5、在com.hundsun.diagnose.front/src/resource/conf/spring/diag-timer-task.xml 里配置定时任务,任务定时为 3分钟执行一次
6、启动com.hundsun.diagnose.front 项目,调用 JavaExcuteKettleJob 中的 doJob(init_date)方法,该方法含有一个日期传参;启动页面如下图所示:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184036.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
