大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
ROC 曲线和 AUC 常被用来评价一个
二值分类器 的优劣。
混淆矩阵
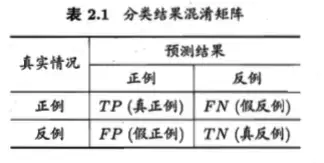

其中,TP(真正,True Positive)表示真正结果为正例,预测结果也是正例;FP(假正,False Positive)表示真实结果为负例,预测结果却是正例;TN(真负,True Negative)表示真实结果为正例,预测结果却是负例;FN(假负,False Negative)表示真实结果为负例,预测结果也是负例。显然,TP+FP+FN+TN=样本总数。


精确率和准确率是比较容易混淆的两个评估指标,两者是有区别的。精确率是一个二分类指标,而准确率能应用于多分类,其计算公式为:
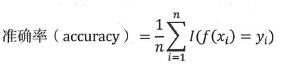
ROC
机器学习模型中,很多模型输出是预测概率。而使用精确率、召回率这类指标进行模型评估时,还需要对预测概率设分类阈值,比如预测概率大于阈值为正例,反之为负例。这使得模型多了一个超参数,并且这个超参数会影响模型的泛化能力。
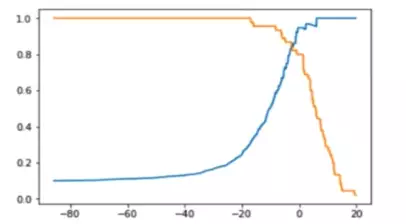
- 精准率:蓝色曲线
- 召回率:黄色曲线
- X:阈值
- Y:精准率和召回率各自的值
当我们调整阈值时,就会造成不同的精准率和召回率,阈值越高,精准率越高,召回率越低。阈值越低则相反。
接收者操作特征(Receiver Operating Characteristic,ROC)曲线不需要设定这样的阈值。ROC曲线纵坐标是真正率,横坐标是假正率,其对应的计算公式为:
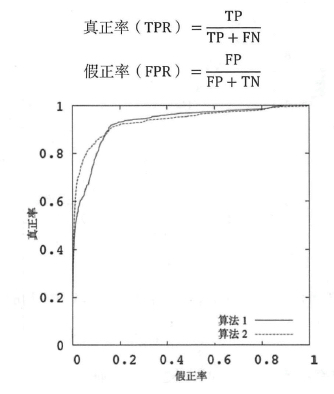
先看图中的四个点和对角线:
- (0,1) :即 FPR=0, TPR=1,这意味着 FN(false negative)=0,并且FP(false positive)=0。这意味着分类器很完美,因为它将所有的样本都正确分类。
- (1,0) :即 FPR=1,TPR=0,这个分类器是最糟糕的,因为它成功避开了所有的正确答案。
- (0,0) :即 FPR=TPR=0,即 FP(false positive)=TP(true positive)=0,此时分类器将所有的样本都预测为负样本(negative)。
- (1,1) :分类器将所有的样本都预测为正样本。
- 对角线上的点 :表示分类器将一半的样本猜测为正样本,另外一半的样本猜测为负样本。
因此,ROC 曲线越接近左上角,分类器的性能越好。
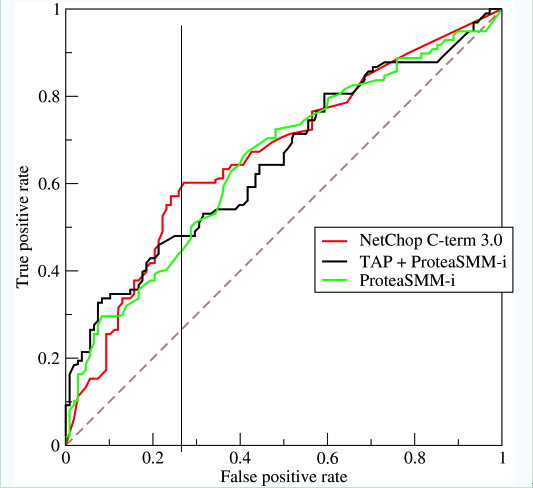
如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的FPR=0.23的情况下,红色分类器得到更高的TPR。也就表明,ROC越往上,分类器效果越好。
sklearn中roc计算代码示例:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html
AOU
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。AUC是一个数值,当仅仅看 ROC 曲线分辨不出哪个分类器的效果更好时,用这个数值来判断。
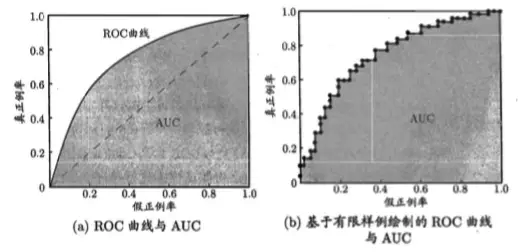
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
- AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.
从上面定义可知,意思是随机挑选一个正样本和一个负样本,当前分类算法得到的 Score 将这个正样本排在负样本前面的概率就是 AUC 值。AUC 值是一个概率值,AUC 值越大,分类算法越好。
sklearn中aou计算代码示例:
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html
PRC
PRC (precision recall curve) 一般指 PRC 曲线,PRC 曲线的纵坐标为 precision,横坐标为 recall。它的生成方式与 ROC 曲线类似,也是取不同的阈值(threshold)来生成不同的坐标点,最后连接起来生成。
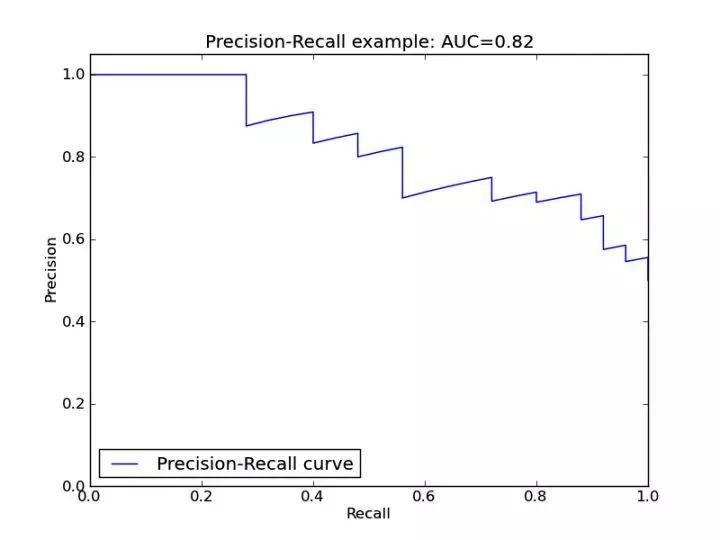
来看下一个特殊的点(1, 1),即 recall=1,precision=1,这意味着 FN=0,FP=0,此时分类器模型的效果非常完美。由此可以知道,越靠近右上角,说明模型效果越好。
由于 recall 与 TPR 是一个意思,所以 PRC 曲线的横坐标与 ROC 曲线的纵坐标一样。
F1-Score
F1分数可以看作是模型精准率和召回率的一种加权平均,它的最大值是1,最小值是0。
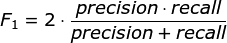
其变形来源于:
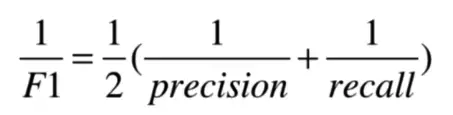
我们使用调和平均而不是简单的算术平均的原因是:调和平均可以惩罚极端情况。一个具有 1.0 的精度,而召回率为 0 的分类器,这两个指标的算术平均是 0.5,但是 F1 score 会是 0。F1 score 给了精度和召回率相同的权重,它是通用 Fβ指标的一个特殊情况,在 Fβ中,β 可以用来给召回率和精度更多或者更少的权重。
Fβ的计算公式:
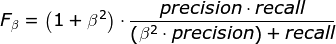
F1分数认为召回率和精确率同等重要,F2分数认为召回率的重要程度是精确率的2倍,而F0.5分数认为召回率的重要程度是精确率的一半。
另外:G分数是另一种统一精确率和的召回率系统性能评估标准,G分数被定义为召回率和精确率的几何平均数。
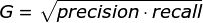
多分类的F1-Score
多分类问题的F1-Score是采用先计算每个分类的f1-score,然后求各个分类的均值。
(1)计算各分类的f1-score
- TP(True Positive):预测答案正确
- FP(False Positive):错将其他类预测为本类
- FN(False Negative):本类标签预测为其他类标
predictions = pval < epsilon
tp = sum((predictions == 1) & (y == 1))
fp = sum((predictions == 1) & (y == 0))
fn = sum((predictions == 0) & (y == 1))
precision = tp / (tp + fp)
recall = tp / (tp + fn)
F1 = 2 * precision * recall / (precision + recall)
(2)多分类的整体f1-score
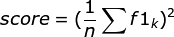
sklearn中f1-score计算代码示例:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html
选择指标
为什么要出现这么多评估指标呢?实际上,不同的分类任务适合使用不同的指标来衡量。
例如,推荐系统中,如果希望更精准的了解客户需求,避免推送用户不感兴趣的内容,precision 就更加重要;在疾病检测的时候,我们不希望查漏任何一项疾病,这时 recall(TPR) 就更重要。当两者都需要考虑时,F1-score 就是一种参考指标。
真实世界中的数据经常会面临 class imbalance 问题,即正负样本比例失衡,而且测试数据中的正负样本的分布也可能随着时间变化。根据计算公式可以推知,在测试数据出现imbalance 时 ROC 曲线能基本保持不变,而 PRC 则会出现大变化。
参考:
《美团机器学习学习实践》
ROC曲线与AUC值:http://www.cnblogs.com/gatherstars/p/6084696.html
什么是 ROC AUC:https://www.jianshu.com/p/42bfe1a79d12
Wiki F1-score:https://en.wikipedia.org/wiki/F1_score
详解sklearn的多分类模型评价指标:https://zhuanlan.zhihu.com/p/59862986
一文读懂二元分类模型评估指标:https://cloud.tencent.com/developer/article/1099537
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183475.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
