大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
HashMap的线程不安全主要体现在下面两个方面:
1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
JDK1.7
在JDK1.7中,扩容数据时要进行把原数据迁移到新的位置,使用的方法:
//数据迁移的方法,头插法添加元素
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//for循环中的代码,逐个遍历链表,重新计算索引位置,将老数组数据复制到新数组中去(数组不存储实际数据,所以仅仅是拷贝引用而已)
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
//将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
//以下三行是线程不安全的关键
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这段代码是HashMap在JDK1.7的扩容操作,重新定位每个桶的下标,并采用头插法将元素迁移到新数组中。头插法会将链表的顺序翻转,这也是形成死循环的关键点。
将关键的几行代码提取出:
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
假设有两个线程,每个线程都有一个e指针和next指针,线程1的为e1和next1,线程2的为e2,next2。
假设线程1执行到 Entry<K,V> next = e.next 后,线程被挂起,此时e1指向10,next1 指向 6。
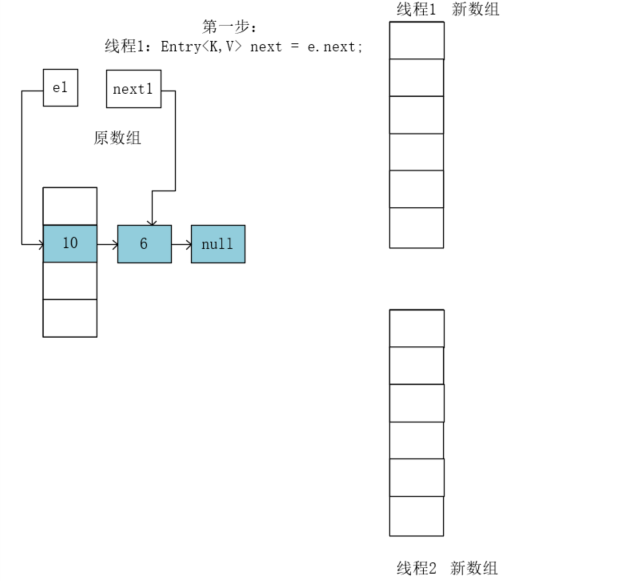

接着线程2开始执行,和线程1一样,先执行 Entry<K,V> next = e.next;将e2执向10,将next2指向6:
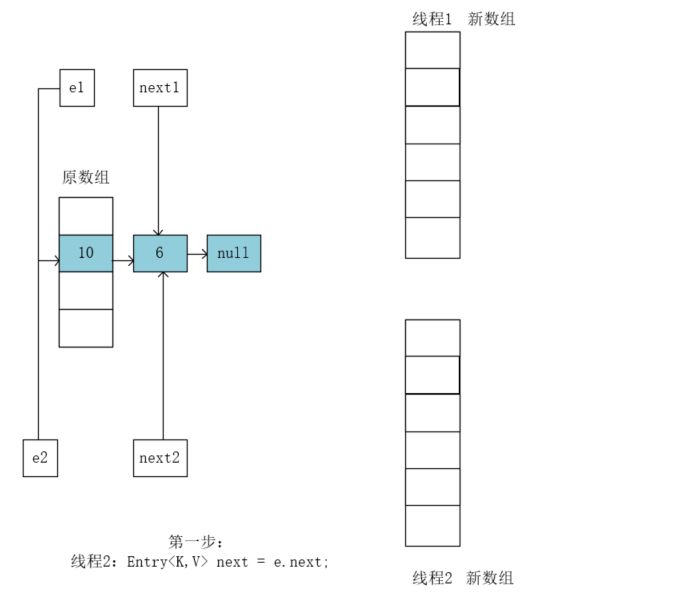
然后执行e.next = newTable[i]; 因为newTable[i]此时为null,所以e2.next为null,也就是让10指向空。
执行newTable[i] = e;将10复制到newTable[i]当中:
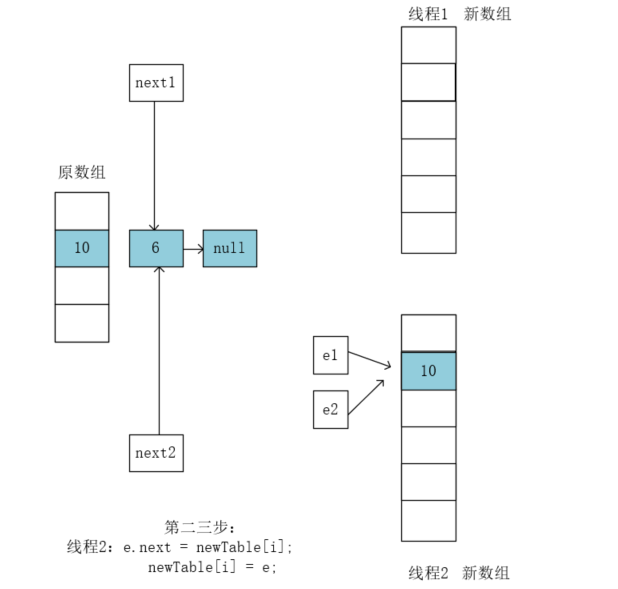
执行e = next;执行前e2指向的是10,next2执向的是6,执行后e2指向了6。
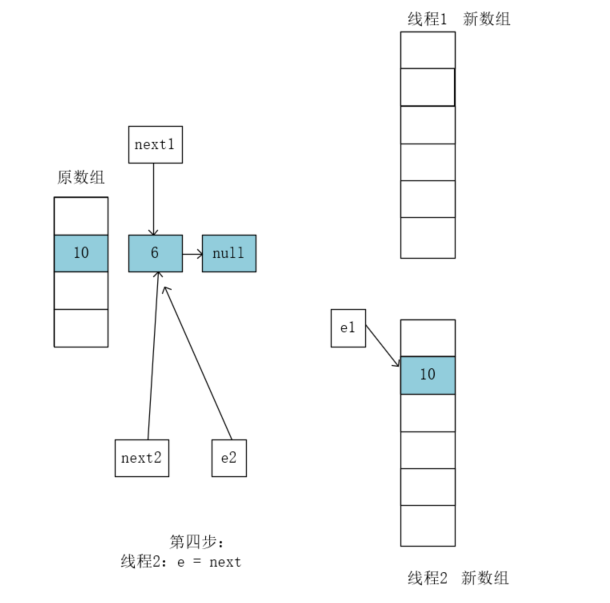
执行到此线程2的第一轮循环结束,开始第二轮执行:
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
执行Entry<K,V> next = e.next; e就是e2喽,此时指向的是6,那么e.next就是null,意思就是让next2为null:
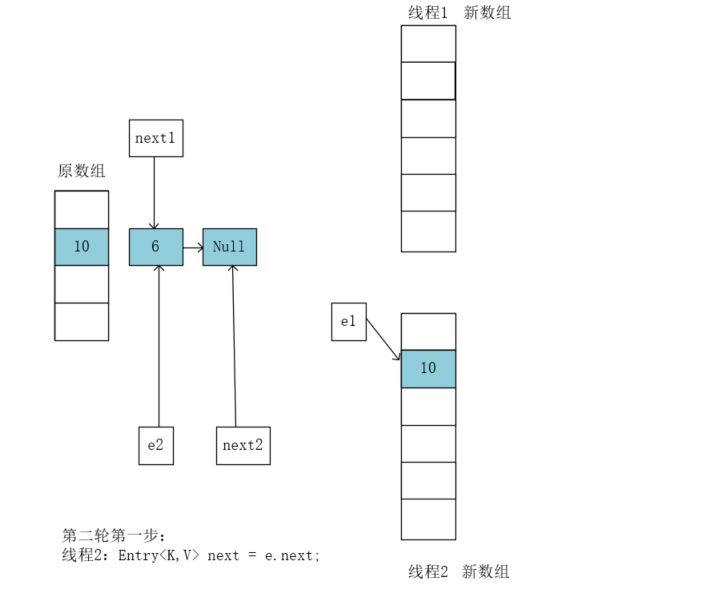
然后执行e.next = newTable[i]; 因为Table[i]此时已经有了值为10,e2指向6,所以执行后e2.next指向了新表中的10。
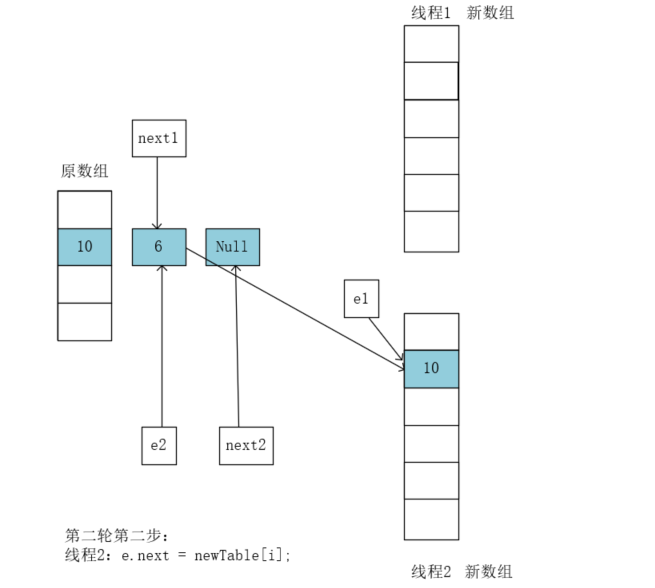
执行newTable[i] = e;将6复制到newTable[i]当中,假如6在新表中的位置和10一样的话,执行这一步的结果就是:
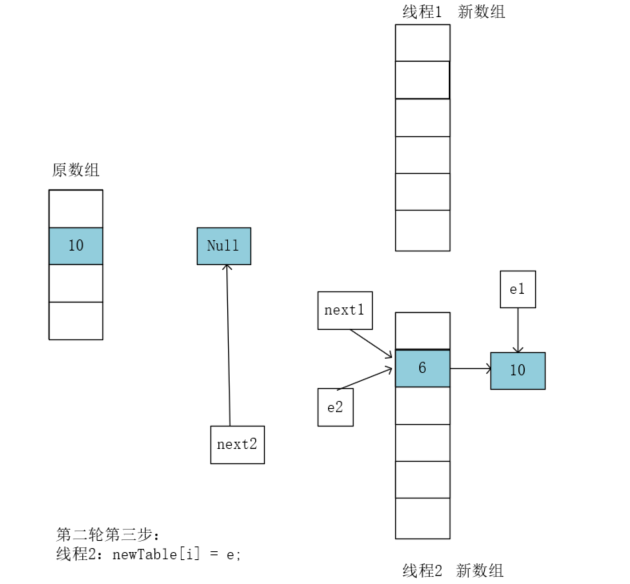
执行e = next;将e2指向null。执行前next2是为空的,执行后e2也就为空:
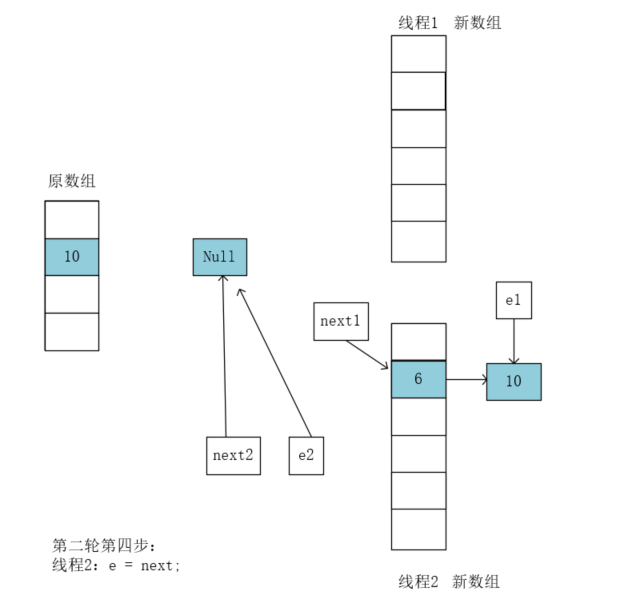
线程2执行完毕。线程1继续执行,之前是执行到了:Entry<K,V> next = e.next; 此时e1执向的还是10,next1指向的是6,。
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
接下来线程1执行e.next = newTable[i]; 线程1的newTable[i]此时为空:
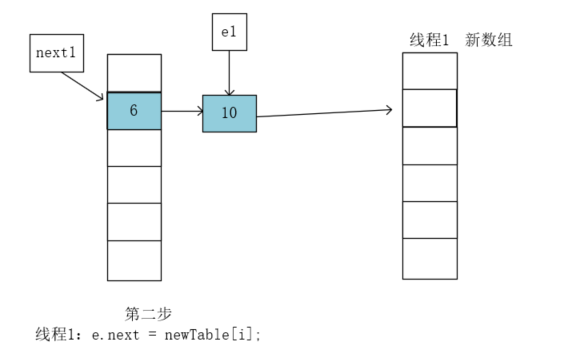
执行newTable[i] = e; 就是将10这个节点放入到新数组:
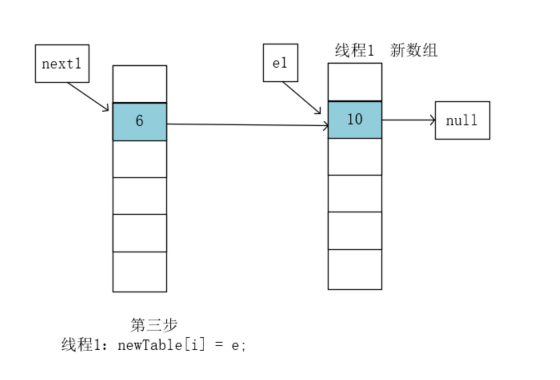
执行e = next; 执行前next1指向的是6,e1执行的是10,执行后,e1指向了6:
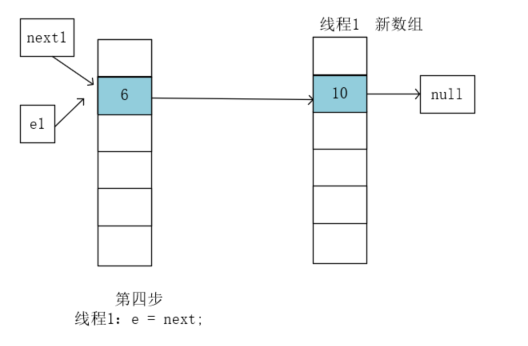
线程1第一轮循环执行结束,开始执行第二轮循环:
Entry<K,V> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
执行Entry<K,V> next = e.next; 执行前e1指向的是6,e1.next指向的是10,next1指向的也是6,此时就是让next1指向10:
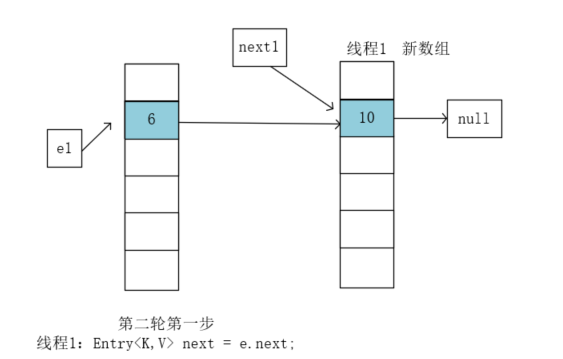
继续执行e.next = newTable[i]; 此时newTable[i]已经是10,e1是6,e.next本来就是指向10,执行前后结果并没有发生变化。
执行newTable[i] = e; e1指向的是6,把6复制到新的数组当中:
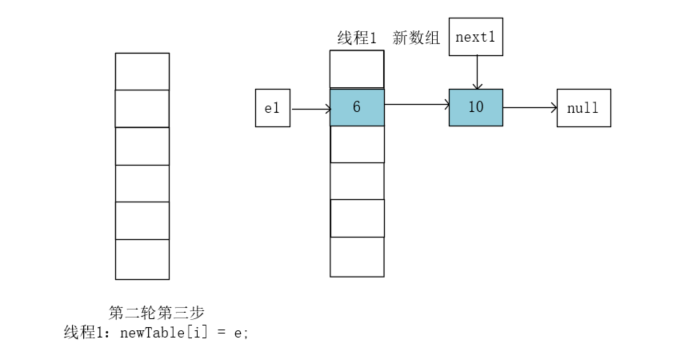
执行e = next;``next1执行前指向的是10,将e1指向10:
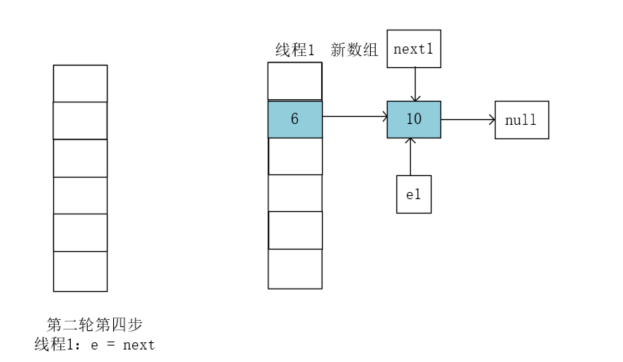
第二轮循环执行结束,开始第三轮循环。
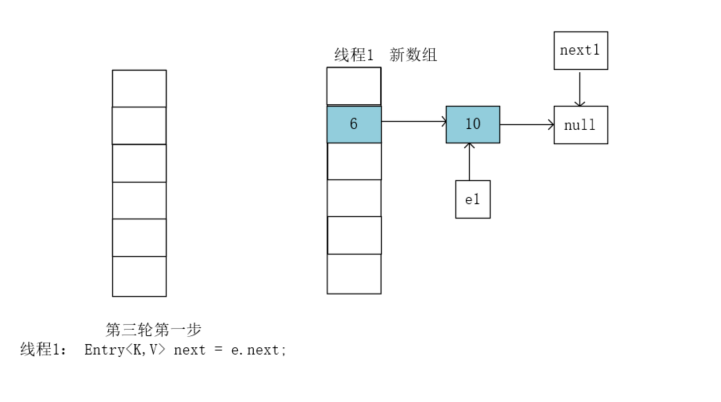
执行Entry<K,V> next = e.next;,e1原本指向的10,e1.next就是null,执行后next1指向null:
执行e.next = newTable[i]; newTable[i]本来是6,e1执行的是10,e1.next本来是null,执行结束后就是让10指向了6:
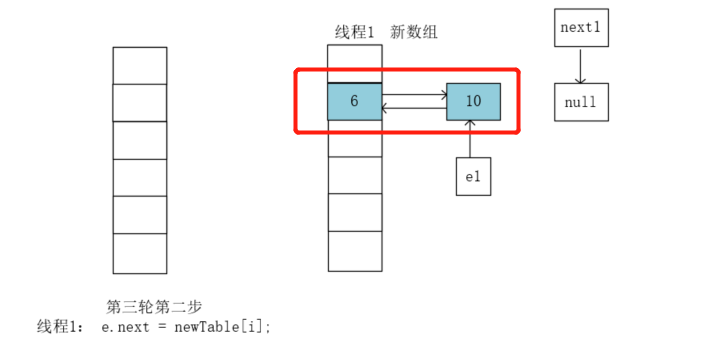
此时环路形成了,陷入了死循环
JDK1.8
对于JDK1.8当中,添加元素使用尾插法。如果对应角标是单向链表,将单向链表进行迁移,如果是红黑树,将双向链表进行数据迁移。
看一下下面这段JDK1.8中的put操作代码:
1 public V put(K key, V value) {
2 // 对key的hashCode()做hash
3 return putVal(hash(key), key, value, false, true);
4 }
5
6 final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
7 boolean evict) {
8 Node<K,V>[] tab; Node<K,V> p; int n, i;
9 // 步骤①:table为空则创建,触发resize方法
10 if ((tab = table) == null || (n = tab.length) == 0)
11 n = (tab = resize()).length;
12 // 步骤②:计算index,并对null做处理
13 if ((p = tab[i = (n - 1) & hash]) == null)
14 tab[i] = newNode(hash, key, value, null);
15 else {
16 Node<K,V> e; K k;
17 // 步骤③:节点key存在,直接覆盖value
18 if (p.hash == hash &&
19 ((k = p.key) == key || (key != null && key.equals(k))))
20 e = p;
21 // 步骤④:判断该链为红黑树
22 else if (p instanceof TreeNode)
23 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
24 // 步骤⑤:该链为链表
25 else {
26 for (int binCount = 0; ; ++binCount) {
27 if ((e = p.next) == null) {
//对于计算出的存储位置下标已经有数据,也就是冲突,转成链表存到下一位
28 p.next = newNode(hash, key,value,null);
//链表长度大于8转换为红黑树进行处理
29 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
30 treeifyBin(tab, hash);
31 break;
32 }
// key已经存在直接覆盖value
33 if (e.hash == hash &&
34 ((k = e.key) == key || (key != null && key.equals(k))))
35 break;
36 p = e;
37 }
38 }
39
40 if (e != null) {
// existing mapping for key
41 V oldValue = e.value;
42 if (!onlyIfAbsent || oldValue == null)
43 e.value = value;
44 afterNodeAccess(e);
45 return oldValue;
46 }
47 }
48 ++modCount;
49 // 步骤⑥:超过最大容量就扩容,门限原本是初始容量*0.75
50 if (++size > threshold)
51 resize(); //扩原来的2倍
52 afterNodeInsertion(evict);
53 return null;
54 }
其中第13行代码是判断是否出现hash碰撞,假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第13行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
除此之前,还有就是代码的第50行处有个++size,我们这样想,还是线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10,当线程A执行到第50行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU,线程B快乐的拿到CPU还是从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存,然后线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全。
Jdk1.8当中如何解决HashMap扩容成环问题
扩容源码:
final Node< K,V >[] resize() {
Node< K,V >[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//在容量不超过做大容量的时候,扩容扩大为原来的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
...省略部分代码
@SuppressWarnings({
"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//遍历旧数组中的元素,复制到table数组中
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//在这里可能会出现数据丢失
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode< K,V >)e).split(this, newTab, j, oldCap);
else {
// preserve order
Node< K,V > loHead = null, loTail = null;
Node< K,V > hiHead = null, hiTail = null;
Node< K,V > next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
.
在JDK1.8中机智的使用两组指针解决这个问题,主要代码如下:
Node< K,V > loHead = null, loTail = null;
Node< K,V > hiHead = null, hiTail = null;
Node< K,V > next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
定义了两组指针,分别是高位指针和低位指针:
Node< K,V > loHead = null, loTail = null;
Node< K,V > hiHead = null, hiTail = null;
这两组指针将链表分成了两部分,高位指针指向哪些扩容后下标变为(旧索引+扩容大小),低位指针指向哪些扩容后下标还保持不变的节点。分成两条链表今次那个迁移,迁移后节点的前后顺序保持不变,不会出现环的情况。
另外可以看到我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”
扩容的地方是红黑树
上面看到的扩容的地方是链表,如果是红黑树呢?
//这个函数的功能是对红黑树进行 rehash 操作
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
// Relink into lo and hi lists, preserving order
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
//由于 TreeNode 节点之间存在双端链表的关系,可以利用链表关系进行 rehash
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
//rehash 操作之后注意对根据链表长度进行 untreeify 或 treeify 操作
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}//end if
}//end split
可以看到由TreeNode 节点之间存在双端链表的关系,可以利用链表关系进行处理红黑树,也就是说红黑树里还存着next的信息,只不过平时不用,到扩容的时候就用上了,作为链表来处理,分为高位链表和低位链表。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183237.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
