大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
参考自:
http://blog.csdn.net/zbc1090549839/article/details/44103801
http://blog.csdn.net/junmuzi/article/details/48917361
归一化方法(Normalization Method)
1。 把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
2 。把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
比如,复数阻抗可以归一化书写:Z = R + jωL = R(1 + jωL/R) ,复数部分变成了纯数量了,没有量纲。
另外,微波之中也就是电路分析、信号系统、电磁波传输等,有很多运算都可以如此处理,既保证了运算的便捷,又能凸现出物理量的本质含义。
标准化方法(Normalization Method)
数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。由于信用指标体系的各个指标度量单位是不同的,为了能够将指标参与评价计算,需要对指标进行规范化处理,通过函数变换将其数值映射到某个数值区间。
(1) 最小-最大规范化对原始数据进行线性变换。假定MaxA与MinA分别表示属性A的最大与最小值。最小最大规范化通过计算将属性A的值映射到区间[a, b]上的v。一般来说,将最小-最大规范化在用于信用指标数据上,常用的有以下两种函数形式:
a) 效益型指标(越大越好型)的隶属函数:
b) 成本型指标(越小越好型)的隶属函数:
(2) z-score规范化也称零-均值规范化。属性A的值是基于A的平均值与标准差规范化。(Ref:http://blog.csdn.net/zbc1090549839/article/details/44103801中的2)
(3) 小数定标规范化是通过移动属性A的小数点位置来实现的。小数点的移动位数依赖于A的最大绝对值。(ref:http://wenku.baidu.com/link?url=mpUUobm4WGiisLfEGxI10JSzYara-Tb2ZybL__QTj9VOUwcoEaYKdIEP9CJ5JPk5Dm6OTZQ_dn4LrZQ0KaHNWhNelAU4Xt_MMwEbWN3oxb3)
==========================================================================================================
Ok! The following just for ref. The main content is over!
///
在这里主要讨论两种归一化方法:
1、线性函数归一化(Min-Max scaling)
线性函数将原始数据线性化的方法转换到[0 1]的范围,归一化公式如下:
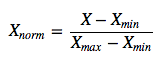

2、0均值标准化(Z-score standardization)
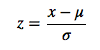
///
关于神经网络归一化方法的整理
由于采集的各数据单位不一致,因而须对数据进行[-1,1]归一化处理,归一化方法主要有如下几种,供大家参考:(by james)
1、线性函数转换,表达式如下:
y=(x-MinValue)/(MaxValue-MinValue)
说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
2、对数函数转换,表达式如下:
y=log10(x)
说明:以10为底的对数函数转换。
3、反余切函数转换,表达式如下:
y=atan(x)*2/PI
归一化是为了加快训练网络的收敛性,可以不进行归一化处理
归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1–+1之间是统计的坐标分布。归一化有同一、 统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,归一 化是同一在0-1之间的统计概率分布;
当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。为了避免出现这种情况,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。
归一化是因为sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。所以这样做分类的问题时用[0.9 0.1 0.1]就要比用[1 0 0]要好。
但是归一化处理并不总是合适的,根据输出值的分布情况,标准化等其它统计变换方法有时可能更好。
关于用premnmx语句进行归一化:
premnmx语句的语法格式是:[Pn,minp,maxp,Tn,mint,maxt]=premnmx(P,T)
其中P,T分别为原始输入和输出数据,minp和maxp分别为P中的最小值和最大值。mint和maxt分别为T的最小值和最大值。
premnmx函数用于将网络的输入数据或输出数据进行归一化,归一化后的数据将分布在[-1,1]区间内。
我们在训练网络时如果所用的是经过归一化的样本数据,那么以后使用网络时所用的新数据也应该和样本数据接受相同的预处理,这就要用到tramnmx。
下面介绍tramnmx函数:
[Pn]=tramnmx(P,minp,maxp)
其中P和Pn分别为变换前、后的输入数据,maxp和minp分别为premnmx函数找到的最大值和最小值。
(by terry2008)
matlab中的归一化处理有三种方法
1. premnmx、postmnmx、tramnmx
2. restd、poststd、trastd
3. 自己编程
具体用那种方法就和你的具体问题有关了
(by happy)
pm=max(abs(p(i,:))); p(i,:)=p(i,:)/pm;
和
for i=1:27
p(i,:)=(p(i,:)-min(p(i,:)))/(max(p(i,:))-min(p(i,:)));
end 可以归一到0 1 之间
0.1+(x-min)/(max-min)*(0.9-0.1)其中max和min分别表示样本最大值和最小值。
这个可以归一到0.1-0.9
=============
数据类型相互转换
这种转换可能发生在算术表达式、赋值表达式和输出时。转换的方式有两种:自动转换和强制转换。
========
自动转换
自动转换由编译系统自动完成,可以将一种数据类型的数据转换为另外一种数据类型的数据。
1)算术运算中的数据转换
如果一个运算符有两个不同类型的运算分量,C语言在计算该表达式时会自动转换为同一种数据类型以便进行运算。先将较低类型的数据提升为较高的类型,从而使两者的数据类型一致(但数值不变),然后再进行计算,其结果是较高类型的数据。 自动转换遵循原则——“类型提升”:转换按数据类型提升(由低向高)的方向进行,以保证不降低精度。 数据类型的高低是根据其类型所占空间的大小来判定,占用空间越大,类型越高。反之越低。 例如:算术运算x+y,如果x和y的类型都是int型变量,则x+y的结果自然是int型。如果x是short型而y是int型,则需要首先将x转换为int型,然后再与y进行加法计算,表达式的结果为int型。
2)赋值运算的类型转换
在执行赋值运算时,如果赋值运算符两侧的数据类型不同,赋值号右侧表达式类型的数据将转换为赋值号左侧变量的类型。转换原则是:当赋值运算符“=”右侧表达式的值被计算出来后,不论是什么类型都一律转换为“=”左侧的变量的类型,然后再赋值给左侧的变量。
例如:float a;
a=10;? /*结果为a=10.0(数据填充)*/
int a;
a=15.5 /* 结果为a=15(数据截取)*/
在赋值类型转换时要注意数值的范围不能溢出。既要在该数据类型允许的范围内。如如果右侧变量数据类型长度比左侧的长时,将丢失一部分数据,从而造成数据精度的降低。
3)数据输出时的类型转换
在输出时,数据将转换为格式控制符所要求的类型。同样可能发生数据丢失或溢出。类型转换的实际情况是:字符型到整型是取字符的ASCII码值;整型到字符型只是取其低8位;实型到整型要去掉小数部分;整型到实型数值不变,但以实数形式存放;双精度到实型是四舍五入的。
========
强制转换
一般情况下,数据类型的转换通常是由编译系统自动进行的,不需要程序员人工编写程序干预,所以又被称为隐式类型转换。但如果程序要求一定将某一类型的数据从该种类型强制地转换为另外一种类型,则需要人工编程进行强制类型转换,也称为显式转换。强制类型转换的目地是使数据类型发生改变,从而使不同类型的数据之间的运算能够进行下去。
语法格式如下:
(类型说明符)表达式
功能是强行地将表达式的类型转换为括号内要求的类型。
例如:(int)4.2的结果是4;
又如:int x;
(float)x;x的值被强制转换为实型,但是并不改变的x类型是整型。只是在参与运算处理时按照实型处理。
======
线性函数转转讲一系列数据映射到相应区间,例如将所有数据映射到 1~100
可用下列函数
y=((x-min)/(max-min))*(100-1)+1
1-100 范围内
min是数据集中最小值,max是最大值
///
为什么在距离度量计算相似性、PCA中使用第二种方法(Z-score standardization)会更好呢?我们进行了以下的推导分析:
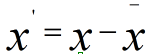
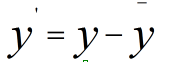
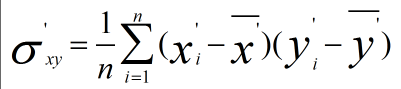
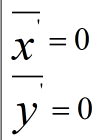
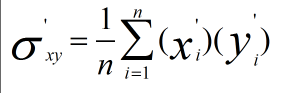
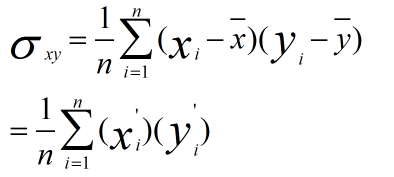
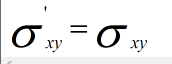
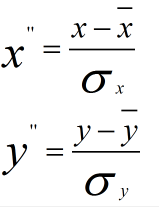

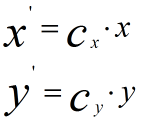
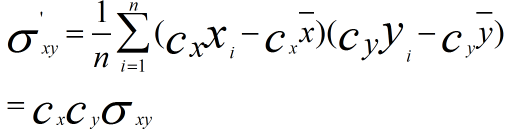
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183142.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
