大家好,又见面了,我是你们的朋友全栈君。
正如在Batch Domain Language中叙述的,Step是一个独立封装域对象,包含了所有定义和控制实际处理信息批任务的序列。这是一个比较抽象的描述,因为任意一个Step的内容都是开发者自己编写的Job。一个Step的简单或复杂取决于开发者的意愿。一个简单的Step也许是从本地文件读取数据存入数据库,写很少或基本无需写代码。一个复杂的Step也许有复杂的业务规则(取决于所实现的方式),并作为整个个流程的一部分。

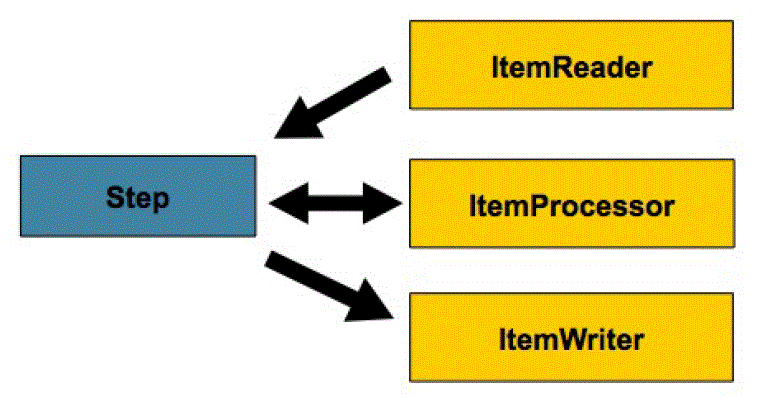
所有的批处理都可以描述为最简单的形式: 读取大量的数据, 执行某种类型的计算/转换, 以及写出执行结果.Spring Batch 提供了三个主要接口来辅助执行大量的读取与写出: ItemReader, ItemProcessor 和 ItemWriter.
1.1 ItemReader
最简单的概念, ItemReader 就是一种从各个输入源读取数据,然后提供给后续步骤的方式. 最常见的例子包括:
- Flat FileFlat File Item Readers 从纯文本文件中读取一行行的数据, 存储数据的纯文本文件通常具有固定的格式, 并且使用某种特殊字符来分隔每条记录中的各个字段(例如逗号,Comma).
- XML XML ItemReaders 独立地处理XML,包括用于解析、映射和验证对象的技术。还可以对输入数据的XML文件执行XSD schema验证。
- Database 数据库就是对请求返回结果集的资源,结果集可以被映射转换为需要处理的对象。默认的SQL ItemReaders调用一个 RowMapper 来返回对象, 并跟踪记录当前行,以备有重启的情况, 存储基本统计信息,并提供一些事务增强特性,关于事物将在稍后解释。
public interface ItemReader<T> { T read() throws Exception, UnexpectedInputException, ParseException; }read 是ItemReader中最根本的方法; 每次调用它都会返回一个 Item 或 null(如果没有更多item)。每个 item条目, 一般对应文件中的一行(line), 或者对应数据库中的一行(row), 也可以是XML文件中的一个元素(element)。 一般来说, 这些item都可以被映射为一个可用的domain对象(如 Trade, User 等等), 但也不是强制要求(最偷懒的方式,返回一个Map)。
一般约定 ItemReader 接口的实现都是向前型的(forward only). 但如果底层资源是事务性质的(如JMS队列),并且发生回滚(rollback), 那么下一次调用 read 方法有可能会返回和前次逻辑上相等的结果(对象)。值得一提的是, 处理过程中如果没有items, ItemReader 不应该抛出异常。例如,数据库 ItemReader 配置了一条查询语句, 返回结果数为0, 则第一次调用read方法将返回null。
1.2 ItemWriter
public interface ItemWriter<T> { void write(List<? extends T> items) throws Exception; }类比于ItemReader中的read,write方法是ItemWriter 接口的根本方法; 只要传入的items列表是打开的,那么它就会尝试着将其写入(write out)。 因为一般来说,items 将要被批量写入到一起,然后再输出, 所以 write 方法接受一个List 参数,而不是单个对象(item)。list输出后,在write方法返回(return)之前,对缓冲执行刷出(flush)操作是很必要的。例如,如果使用Hibernate DAO时,对每个对象要调用一次DAO写操作, 操作完成之后, 方法 return 之前,writer就应该关闭hibernate的Session会话。
1.3 ItemProcessor
public class CompositeItemWriter<T> implements ItemWriter<T> { ItemWriter<T> itemWriter; public CompositeItemWriter(ItemWriter<T> itemWriter) { this.itemWriter = itemWriter; } public void write(List<? extends T> items) throws Exception { // ... 此处可以执行某些业务逻辑 itemWriter.write(item); } public void setDelegate(ItemWriter<T> itemWriter){ this.itemWriter = itemWriter; } }public interface ItemProcessor<I, O> { O process(I item) throws Exception; }
ItemProcessor非常简单; 传入一个对象,对其进行某些处理/转换,然后返回另一个对象(也可以是同一个)。传入的对象和返回的对象类型可以一样,也可以不一致。关键点在于处理过程中可以执行一些业务逻辑操作,当然这完全取决于开发者怎么实现它。一个ItemProcessor可以被直接关联到某个Step(步骤),例如,假设ItemReader的返回类型是 Foo ,而在写出之前需要将其转换成类型Bar的对象。就可以编写一个ItemProcessor来执行这种转换:
public class Foo {} public class Bar { public Bar(Foo foo) {} } public class FooProcessor implements ItemProcessor<Foo,Bar>{ public Bar process(Foo foo) throws Exception { //执行某些操作,将 Foo 转换为 Bar对象 return new Bar(foo); } } public class BarWriter implements ItemWriter<Bar>{ public void write(List<? extends Bar> bars) throws Exception { //write bars } }
<job id="ioSampleJob"> <step name="step1"> <tasklet> <chunk reader="fooReader" processor="fooProcessor" writer="barWriter" commit-interval="2"/> </tasklet> </step> </job>1.3.1 Chaining ItemProcessors
public class Foo {} public class Bar { public Bar(Foo foo) {} } public class Foobar{ public Foobar(Bar bar) {} } public class FooProcessor implements ItemProcessor<Foo,Bar>{ public Bar process(Foo foo) throws Exception { //Perform simple transformation, convert a Foo to a Bar return new Bar(foo); } } public class BarProcessor implements ItemProcessor<Bar,FooBar>{ public FooBar process(Bar bar) throws Exception { return new Foobar(bar); } } public class FoobarWriter implements ItemWriter<FooBar>{ public void write(List<? extends FooBar> items) throws Exception { //write items } }CompositeItemProcessor<Foo,Foobar> compositeProcessor = new CompositeItemProcessor<Foo,Foobar>(); List itemProcessors = new ArrayList(); itemProcessors.add(new FooTransformer()); itemProcessors.add(new BarTransformer()); compositeProcessor.setDelegates(itemProcessors);<job id="ioSampleJob"> <step name="step1"> <tasklet> <chunk reader="fooReader" processor="compositeProcessor" writer="foobarWriter" commit-interval="2"/> </tasklet> </step> </job> <bean id="compositeItemProcessor" class="org.springframework.batch.item.support.CompositeItemProcessor"> <property name="delegates"> <list> <bean class="..FooProcessor" /> <bean class="..BarProcessor" /> </list> </property> </bean>1.3.2 Filtering Records
例如, 某个批处理作业,从一个文件中读取三种不同类型的记录: 准备 insert 的记录、准备 update 的记录,需要 delete 的记录。如果系统中不允许删除记录, 那么我们肯定不希望将 “delete” 类型的记录传递给 ItemWriter。 但因为这些记录又不是损坏的信息(bad records), 我们只想将其过滤掉,而不是跳过。 因此,ItemWriter只会收到 “insert” 和 “update”的记录。
要过滤某条记录, 只需要 ItemProcessor 返回“ null ” 即可. 框架将自动检测结果为“ null ”的情况, 不会将该item 添加到传给ItemWriter的list中。 像往常一样, 在 ItemProcessor 中抛出异常将会导致跳过(skip)。
1.3.3 容错(Fault Tolerance)
1.4 ItemStream
public interface ItemStream { void open(ExecutionContext executionContext) throws ItemStreamException; void update(ExecutionContext executionContext) throws ItemStreamException; void close() throws ItemStreamException; }1.5 委托模式(Delegate Pattern)与注册Step
<job id="ioSampleJob"> <step name="step1"> <tasklet> <chunk reader="fooReader" processor="fooProcessor" writer="compositeItemWriter" commit-interval="2"> <streams> <stream ref="barWriter" /> </streams> </chunk> </tasklet> </step> </job> <bean id="compositeItemWriter" class="...CustomCompositeItemWriter"> <property name="delegate" ref="barWriter" /> </bean> <bean id="barWriter" class="...BarWriter" />1.6 纯文本平面文件(Flat Files)
1.6.1 The FieldSet(字段集)
String[] tokens = new String[]{"foo", "1", "true"}; FieldSet fs = new DefaultFieldSet(tokens); String name = fs.readString(0); int value = fs.readInt(1); boolean booleanValue = fs.readBoolean(2);在 FieldSet 接口可以返回很多类型的对象/数据, 如 Date , long , BigDecimal 等。 FieldSet 最大的优势在于,它对文本输入文件提供了统一的解析。 不是每个批处理作业采用不同的方式进行解析,而一直是一致的, 不论是在处理格式异常引起的错误,还是在进行简单的数据转换。
1.6.2 FlatFileItemReader
Resource resource = new FileSystemResource("resources/trades.csv");

LineMapper
public interface LineMapper<T> { T mapLine(String line, int lineNumber) throws Exception; }FlatFileItemReader
但与 RowMapper 不同的是, LineMapper 只能取得原始行的String值, 正如上面所说, 给你的是一个半成品。 这行文本值必须先被解析为 FieldSet, 然后才可以映射为一个对象,如下所述。
LineTokenizer
public interface LineTokenizer { FieldSet tokenize(String line); }使用 LineTokenizer 的约定是, 给定一行输入内容(理论上 String 可以包含多行内容), 返回一个表示该行的 FieldSet 对象。这个FieldSet接着会传递给 FieldSetMapper。Spring Batch 包括以下LineTokenizer实现:
- DelmitedLineTokenizer 适用于处理使用分隔符(delimiter)来分隔一条数据中各个字段的文件。最常见的分隔符是逗号(comma),但管道或分号也经常使用。
- FixedLengthTokenizer 适用于记录中的字段都是“固定宽度(fixed width)”的文件。每种记录类型中,每个字段的宽度必须先定义。
- PatternMatchingCompositeLineTokenizer 通过使用正则模式匹配,来决定对特定的某一行应该使用 LineTokenizers 列表中的哪一个来执行字段拆分。
FieldSetMapper
public interface FieldSetMapper<T> { T mapFieldSet(FieldSet fieldSet); }
这和JdbcTemplate中的RowMapper是一样的道理。
DefaultLineMapper
- 从文件中读取一行。
- 将读取的字符串传给 LineTokenizer#tokenize() 方法,以获取一个 FieldSet。
- 将解析后的 FieldSet 传给 FieldSetMapper ,然后将 ItemReader#read() 方法执行的结果返回给调用者。
FlatFileItemReader
public class DefaultLineMapper<T> implements LineMapper<T>, InitializingBean { private LineTokenizer tokenizer; private FieldSetMapper<T> fieldSetMapper; public T mapLine(String line, int lineNumber) throws Exception { return fieldSetMapper.mapFieldSet(tokenizer.tokenize(line)); } public void setLineTokenizer(LineTokenizer tokenizer) { this.tokenizer = tokenizer; } public void setFieldSetMapper(FieldSetMapper<T> fieldSetMapper) { this.fieldSetMapper = fieldSetMapper; } }文件分隔符读取简单示例
ID,lastName,firstName,position,birthYear,debutYear "AbduKa00,Abdul-Jabbar,Karim,rb,1974,1996", "AbduRa00,Abdullah,Rabih,rb,1975,1999", "AberWa00,Abercrombie,Walter,rb,1959,1982", "AbraDa00,Abramowicz,Danny,wr,1945,1967", "AdamBo00,Adams,Bob,te,1946,1969", "AdamCh00,Adams,Charlie,wr,1979,2003"该文件的内容将被映射为领域对象 Player:
public class Player implements Serializable { private String ID; private String lastName; private String firstName; private String position; private int birthYear; private int debutYear; public String toString() { return "PLAYER:ID=" + ID + ",Last Name=" + lastName +",First Name=" + firstName + ",Position=" + position + ",Birth Year=" + birthYear + ",DebutYear=" +debutYear; } // setters and getters... }protected static class PlayerFieldSetMapper implements FieldSetMapper<Player> { public Player mapFieldSet(FieldSet fieldSet) { Player player = new Player(); player.setID(fieldSet.readString(0)); player.setLastName(fieldSet.readString(1)); player.setFirstName(fieldSet.readString(2)); player.setPosition(fieldSet.readString(3)); player.setBirthYear(fieldSet.readInt(4)); player.setDebutYear(fieldSet.readInt(5)); return player; } }
FlatFileItemReader<Player> itemReader = new FlatFileItemReader<Player>(); itemReader.setResource(new FileSystemResource("resources/players.csv")); //DelimitedLineTokenizer defaults to comma as its delimiter LineMapper<Player> lineMapper = new DefaultLineMapper<Player>(); lineMapper.setLineTokenizer(new DelimitedLineTokenizer()); lineMapper.setFieldSetMapper(new PlayerFieldSetMapper()); itemReader.setLineMapper(lineMapper); itemReader.open(new ExecutionContext()); Player player = itemReader.read();
根据Name映射 Fields
tokenizer.setNames(new String[] {"ID", "lastName","firstName","position","birthYear","debutYear"});FieldSetMapper 可以像下面这样使用此信息:
public class PlayerMapper implements FieldSetMapper<Player> { public Player mapFieldSet(FieldSet fs) { if(fs == null){ return null; } Player player = new Player(); player.setID(fs.readString("ID")); player.setLastName(fs.readString("lastName")); player.setFirstName(fs.readString("firstName")); player.setPosition(fs.readString("position")); player.setDebutYear(fs.readInt("debutYear")); player.setBirthYear(fs.readInt("birthYear")); return player; } }将FieldSet字段映射为Domain Object
BeanWrapperFieldSetMapper 的配置如下所示:
<bean id="fieldSetMapper" class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"> <property name="prototypeBeanName" value="player" /> </bean> <bean id="player" class="org.springframework.batch.sample.domain.Player" scope="prototype" />对于 FieldSet 中的每个条目(entry), mapper都会在Player对象的新实例中查找相应的setter (因此,需要指定 prototype scope),和 Spring容器 查找 setter匹配属性名是一样的方式。FieldSet 中每个可用的字段都会被映射, 然后返回组装好的 Player 对象,不需要再手写代码。
Fixed Length File Formats
UK21341EAH4121131.11customer1 UK21341EAH4221232.11customer2 UK21341EAH4321333.11customer3 UK21341EAH4421434.11customer4 UK21341EAH4521535.11customer5虽然看起来像是一个很长的字段,但实际上代表了4个分开的字段:
- ISIN : 唯一标识符,订购的商品编码 – 占12字符。
- Quantity : 订购的商品数量 – 占3字符。
- Price : 商品的价格 – 占5字符。
- Customer : 订购商品的顾客Id – 占9字符。
<bean id="fixedLengthLineTokenizer" class="org.springframework.batch.io.file.transform.FixedLengthTokenizer"> <property name="names" value="ISIN,Quantity,Price,Customer" /> <property name="columns" value="1-12, 13-15, 16-20, 21-29" /> </bean>因为 FixedLengthLineTokenizer 使用的也是 LineTokenizer 接口, 所以返回值同样是 FieldSet, 和使用分隔符基本上是一样的。这也就可以使用同样的方式来处理其输出, 例如使用 BeanWrapperFieldSetMapper。
单文件中含有多种类型数据的处理
USER;Smith;Peter;;T;20014539;F LINEA;1044391041ABC037.49G201XX1383.12H LINEB;2134776319DEF422.99M005LI这个文件中有三种类型的记录, “USER”, “LINEA”, 以及 “LINEB”。 一行 “USER” 对应一个 User 对象。 “LINEA” 和 “LINEB”对应的都是 Line 对象, 只是 “LINEA” 包含的信息比“LINEB”要多。
<bean id="orderFileLineMapper" class="org.spr...PatternMatchingCompositeLineMapper"> <property name="tokenizers"> <map> <entry key="USER*" value-ref="userTokenizer" /> <entry key="LINEA*" value-ref="lineATokenizer" /> <entry key="LINEB*" value-ref="lineBTokenizer" /> </map> </property> <property name="fieldSetMappers"> <map> <entry key="USER*" value-ref="userFieldSetMapper" /> <entry key="LINE*" value-ref="lineFieldSetMapper" /> </map> </property> </bean>在这个示例中, “LINEA” 和 “LINEB” 使用独立的 LineTokenizer,但使用同一个 FieldSetMapper.
<entry key="*" value-ref="defaultLineTokenizer" />还有一个 PatternMatchingCompositeLineTokenizer 可用来单独解析。
Flat File 的异常处理
在解析一行时, 可能有很多情况会导致异常被抛出。很多平面文件不是很完整, 或者里面的某些记录格式不正确。许多用户会选择忽略这些错误的行, 只将这个问题记录到日志, 比如原始行,行号。稍后可以人工审查这些日志,也可以由另一个批处理作业来检查。出于这个原因,Spring Batch提供了一系列的异常类: FlatFileParseException ,和 FlatFileFormatException 。
FlatFileParseException 是由 FlatFileItemReader 在读取文件时解析错误而抛出的。 FlatFileFormatException 是由实现了LineTokenizer 接口的类抛出的, 表明在拆分字段时发生了一个更具体的错误。
IncorrectTokenCountException
tokenizer.setNames(new String[] {"A", "B", "C", "D"}); try { tokenizer.tokenize("a,b,c"); }catch(IncorrectTokenCountException e){ assertEquals(4, e.getExpectedCount()); assertEquals(3, e.getActualCount()); }因为 tokenizer 配置了4列的名称,但在这个文件中只找到 3 个字段, 所以会抛出 IncorrectTokenCountException 异常。
IncorrectLineLengthException
tokenizer.setColumns(new Range[] { new Range(1, 5), new Range(6, 10), new Range(11, 15) }); try { tokenizer.tokenize("12345"); fail("Expected IncorrectLineLengthException"); } catch (IncorrectLineLengthException ex) { assertEquals(15, ex.getExpectedLength()); assertEquals(5, ex.getActualLength()); }上面配置的范围是: 1-5 , 6-10 , 以及 11-15 , 因此预期的总长度是15。但在这里传入的行的长度是 5 ,所以会导致IncorrectLineLengthException 异常。之所以直接抛出异常, 而不是先去映射第一个字段的原因是为了更早发现处理失败, 而不再调用 FieldSetMapper 来读取第2列。但是呢,有些情况下, 行的长度并不总是固定的。 出于这个原因, 可以通过设置’strict’ 属性的值,不验证行的宽度:
tokenizer.setColumns(new Range[] { new Range(1, 5), new Range(6, 10) }); tokenizer.setStrict(false); FieldSet tokens = tokenizer.tokenize("12345"); assertEquals("12345", tokens.readString(0)); assertEquals("", tokens.readString(1));上面示例和前一个几乎完全相同, 只是调用了 tokenizer.setStrict(false) 。这个设置告诉 tokenizer 在对一行进行解析(tokenizing)时不要去管(enforce)行的长度。然后就正确地创建了一个 FieldSet并返回。当然,剩下的值就只会包含空的token值。
1.6.3 FlatFileItemWriter
LineAggregator
public interface LineAggregator<T> { public String aggregate(T item); }接口 LineAggregator 与 LineTokenizer 相互对应. LineTokenizer 接收 String ,处理后返回一个 FieldSet 对象, 而LineAggregator 则是接收一条记录,返回对应的 String.
PassThroughLineAggregator
public class PassThroughLineAggregator<T> implements LineAggregator<T> { public String aggregate(T item) { return item.toString(); } }
上面的实现对于需要直接转换为string的时候是很管用的,但是 FlatFileItemWriter 的一些优势也是很有必要的,比如 事务,以及支持重启特性等.
简单的文件写入示例
- 将要写出的对象传递给 LineAggregator 以获取一个字符串(String).
- 将返回的 String 写入配置指定的文件中.
下面是 FlatFileItemWriter 中对应的代码:
public void write(T item) throws Exception { write(lineAggregator.aggregate(item) + LINE_SEPARATOR); }简单的配置如下所示:
<bean id="itemWriter" class="org.spr...FlatFileItemWriter"> <property name="resource" value="file:target/test-outputs/output.txt" /> <property name="lineAggregator"> <bean class="org.spr...PassThroughLineAggregator"/> </property> </bean>
属性提取器 FieldExtractor
- 从文件中读取一行.
- 将这一行字符串传递给 LineTokenizer#tokenize() 方法, 以获取 FieldSet 对象
- 将分词器返回的 FieldSet 传给一个 FieldSetMapper 映射器, 然后将 ItemReader#read() 方法得到的结果 return。
文件的写入也很类似, 但步骤正好相反:
- 将要写入的对象传递给 writer
- 将领域对象的属性域转换为数组
- 将结果数组合并(aggregate)为一行字符串
public interface FieldExtractor<T> { Object[] extract(T item); }
FieldExtractor 的实现类应该根据传入对象的属性创建一个数组, 稍后使用分隔符将各个元素写入文件,或者作为 field-width line 的一部分.
PassThroughFieldExtractor
BeanWrapperFieldExtractor
BeanWrapperFieldExtractor<Name> extractor = new BeanWrapperFieldExtractor<Name>(); extractor.setNames(new String[] { "first", "last", "born" }); String first = "Alan"; String last = "Turing"; int born = 1912; Name n = new Name(first, last, born); Object[] values = extractor.extract(n); assertEquals(first, values[0]); assertEquals(last, values[1]); assertEquals(born, values[2]);
这个 extractor 实现只有一个必需的属性,就是 names , 里面用来存放要映射字段的名字。 就像 BeanWrapperFieldSetMapper 需要字段名称来将 FieldSet 中的 field 映射到对象的 setter 方法一样, BeanWrapperFieldExtractor 需要 names 映射 getter 方法来创建一个对象数组。值得注意的是, names的顺序决定了field在数组中的顺序。
分隔符文件(Delimited File)写入示例
public class CustomerCredit { private int id; private String name; private BigDecimal credit; //getters and setters removed for clarity }因为使用到了领域对象,所以必须提供 FieldExtractor 接口的实现,当然也少不了要使用的分隔符:
<bean id="itemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter"> <property name="resource" ref="outputResource" /> <property name="lineAggregator"> <bean class="org.spr...DelimitedLineAggregator"> <property name="delimiter" value=","/> <property name="fieldExtractor"> <bean class="org.spr...BeanWrapperFieldExtractor"> <property name="names" value="name,credit"/> </bean> </property> </bean> </property> </bean>
在这种情况下, 本章前面提到过的 BeanWrapperFieldExtractor 被用来将 CustomerCredit 中的 name 和 credit 字段转换为一个对象数组, 然后在各个字段之间用逗号分隔写入文件。
固定宽度的(Fixed Width)文件写入示例
<bean id="itemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter"> <property name="resource" ref="outputResource" /> <property name="lineAggregator"> <bean class="org.spr...FormatterLineAggregator"> <property name="fieldExtractor"> <bean class="org.spr...BeanWrapperFieldExtractor"> <property name="names" value="name,credit" /> </bean> </property> <property name="format" value="%-9s%-2.0f" /> </bean> </property> </bean>上面的示例大部分看起来是一样的, 只有 format 属性的值不同:
<property name="format" value="%-9s%-2.0f" />底层实现采用 Java 5 提供的 Formatter 。Java的 Formatter (格式化) 基于C语言的 printf 函数功能。关于如何配置formatter 请参考 Formatter 的javadoc.
处理文件创建(Handling File Creation)
(exception)。
但是文件的写入就没那么简单了。乍一看可能会觉得跟 FlatFileItemWriter 一样简单直接粗暴: 如果文件存在则抛出异常, 如果
不存在则创建文件并开始写入。
但是, 作业的重启有可能会有BUG。 在正常的重启情景中, 约定与前面所想的恰恰相反: 如果文件存在, 则从已知的最后一个
正确位置开始写入, 如果不存在, 则抛出异常。
如果此作业(Job)的文件名每次都是一样的那怎么办? 这时候可能需要删除已存在的文件(重启则不删除)。 因为有这些可能性,
FlatFileItemWriter 有一个属性 shouldDeleteIfExists 。将这个属性设置为 true , 打开 writer 时会将已有的同名文件删除。
1.7 XML Item Readers and Writers
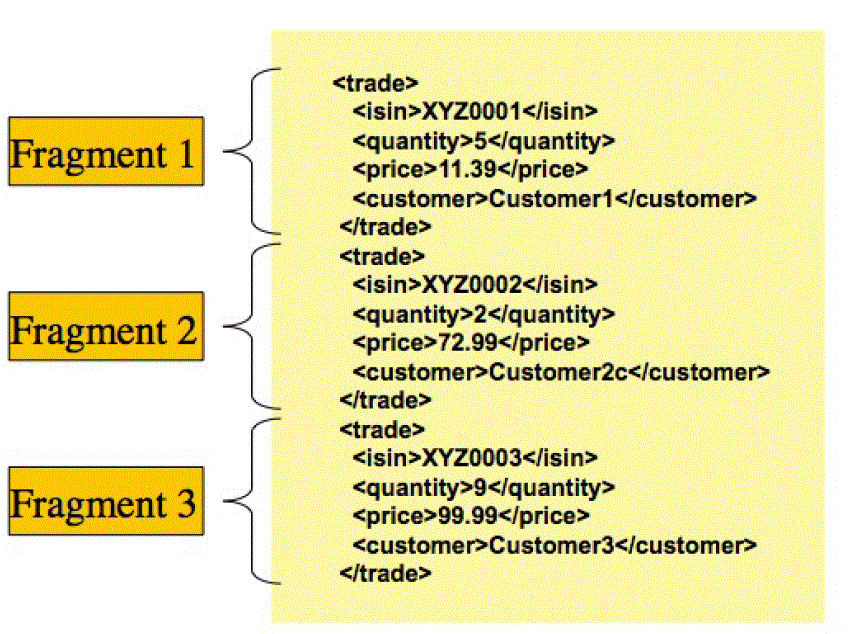

1.7.1 StaxEventItemReader
<?xml version="1.0" encoding="UTF-8"?> <records> <trade xmlns="http://springframework.org/batch/sample/io/oxm/domain"> <isin>XYZ0001</isin> <quantity>5</quantity> <price>11.39</price> <customer>Customer1</customer> </trade> <trade xmlns="http://springframework.org/batch/sample/io/oxm/domain"> <isin>XYZ0002</isin> <quantity>2</quantity> <price>72.99</price> <customer>Customer2c</customer> </trade> <trade xmlns="http://springframework.org/batch/sample/io/oxm/domain"> <isin>XYZ0003</isin> <quantity>9</quantity> <price>99.99</price> <customer>Customer3</customer> </trade> </records>
- Root Element Name 片段根元素的名称就是要映射的对象。上面的示例代表的是 trade 的值。
- Resource Spring Resource 代表了需要读取的文件。
- Unmarshaller Spring OXM提供的Unmarshalling 用于将 XML片段映射为对象.
<bean id="itemReader" class="org.springframework.batch.item.xml.StaxEventItemReader"> <property name="fragmentRootElementName" value="trade" /> <property name="resource" value="data/iosample/input/input.xml" /> <property name="unmarshaller" ref="tradeMarshaller" /> </bean>请注意,在上面的例子中,我们选用一个 XStreamMarshaller, 里面接受一个id为 aliases 的 map, 将首个entry的 key 值作为文档片段的name(即根元素), 将 value 作为绑定的对象类型。类似于FieldSet, 后面的其他元素映射为对象内部的字段名/值对。在配置文件中,我们可以像下面这样使用Spring配置工具来描述所需的alias:
<bean id="tradeMarshaller" class="org.springframework.oxm.xstream.XStreamMarshaller"> <property name="aliases"> <util:map id="aliases"> <entry key="trade" value="org.springframework.batch.sample.domain.Trade" /> <entry key="price" value="java.math.BigDecimal" /> <entry key="name" value="java.lang.String" /> </util:map> </property> </bean>
当 reader 读取到XML资源的一个新片段时(匹配默认的标签名称)。reader 根据这个片段构建一个独立的XML(或至少看起来是这样),并将 document 传给反序列化器(通常是一个Spring OXM Unmarshaller 的包装类)将XML映射为一个Java对象。
StaxEventItemReader xmlStaxEventItemReader = new StaxEventItemReader() Resource resource = new ByteArrayResource(xmlResource.getBytes()) Map aliases = new HashMap(); aliases.put("trade","org.springframework.batch.sample.domain.Trade"); aliases.put("price","java.math.BigDecimal"); aliases.put("customer","java.lang.String"); Marshaller marshaller = new XStreamMarshaller(); marshaller.setAliases(aliases); xmlStaxEventItemReader.setUnmarshaller(marshaller); xmlStaxEventItemReader.setResource(resource); xmlStaxEventItemReader.setFragmentRootElementName("trade"); xmlStaxEventItemReader.open(new ExecutionContext()); boolean hasNext = true CustomerCredit credit = null; while (hasNext) { credit = xmlStaxEventItemReader.read(); if (credit == null) { hasNext = false; } else { System.out.println(credit); } }1.7.2 StaxEventItemWriter
<bean id="itemWriter" class="org.springframework.batch.item.xml.StaxEventItemWriter"> <property name="resource" ref="outputResource" /> <property name="marshaller" ref="customerCreditMarshaller" /> <property name="rootTagName" value="customers" /> <property name="overwriteOutput" value="true" /> </bean>上面配置了3个必需的属性,以及1个可选属性 overwriteOutput = true , (本章前面提到过) 用来指定一个已存在的文件是否可以被覆盖。应该注意的是, writer 使用的 marshaller 和前面讲的 reading 示例中是完全相同的:
<bean id="customerCreditMarshaller" class="org.springframework.oxm.xstream.XStreamMarshaller"> <property name="aliases"> <util:map id="aliases"> <entry key="customer" value="org.springframework.batch.sample.domain.CustomerCredit" /> <entry key="credit" value="java.math.BigDecimal" /> <entry key="name" value="java.lang.String" /> </util:map> </property> </bean>StaxEventItemWriter staxItemWriter = new StaxEventItemWriter() FileSystemResource resource = new FileSystemResource("data/outputFile.xml") Map aliases = new HashMap(); aliases.put("customer","org.springframework.batch.sample.domain.CustomerCredit"); aliases.put("credit","java.math.BigDecimal"); aliases.put("name","java.lang.String"); Marshaller marshaller = new XStreamMarshaller(); marshaller.setAliases(aliases); staxItemWriter.setResource(resource); staxItemWriter.setMarshaller(marshaller); staxItemWriter.setRootTagName("trades"); staxItemWriter.setOverwriteOutput(true); ExecutionContext executionContext = new ExecutionContext(); staxItemWriter.open(executionContext); CustomerCredit Credit = new CustomerCredit(); trade.setPrice(11.39); credit.setName("Customer1"); staxItemWriter.write(trade);
1.8 多个数据输入文件
file-1.txt file-2.txt ignored.txt
file-1.txt 和 file-2.txt 具有相同的格式, 根据业务需求需要一起处理. 可以通过 MuliResourceItemReader 使用 通配符的形式来读取这两个文件:
<bean id="multiResourceReader" class="org.spr...MultiResourceItemReader"> <property name="resources" value="classpath:data/input/file-*.txt" /> <property name="delegate" ref="flatFileItemReader" /> </bean>delegate 引用的是一个简单的 FlatFileItemReader。上面的配置将会从两个输入文件中读取数据,处理回滚以及重启场景。应该注意的是,所有 ItemReader 在添加额外的输入文件后(如本示例),如果重新启动则可能会导致某些潜在的问题。 官方建议是每个批作业处理独立的目录,一直到成功完成为止。
1.9 数据库(Database)
1.9.1 基于Cursor的ItemReaders
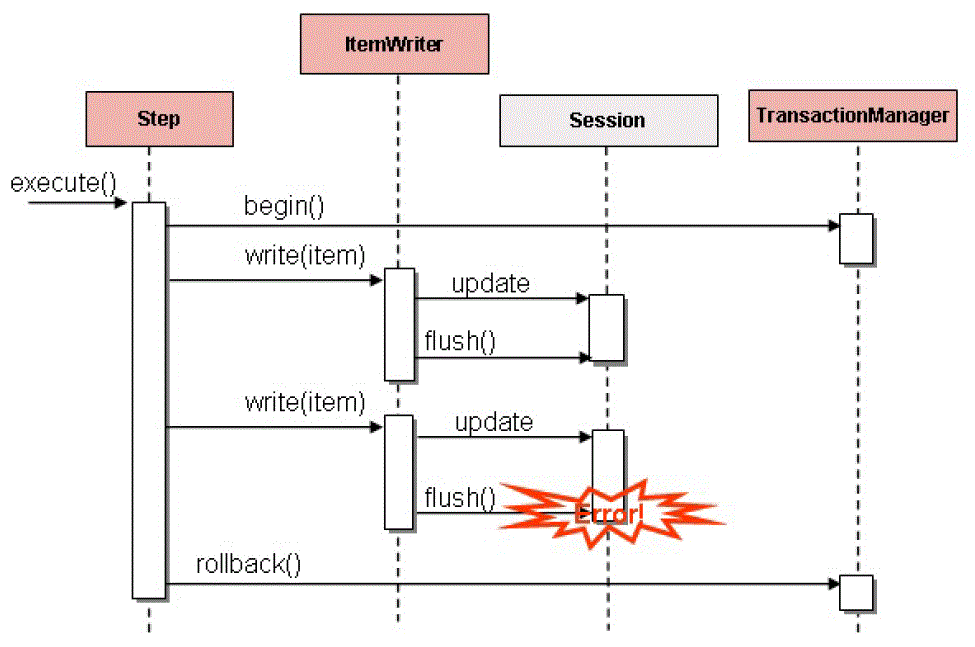
Spring Batch 基于 cursor 的 ItemReaders 在初始化时打开游标, 每次调用 read 时则将游标向前移动一行, 返回一个可用于进行处理的映射对象。最好将会调用 close 方法, 以确保所有资源都被释放。
Spring 的 JdbcTemplate 的解决办法, 是通过回调模式将 ResultSet 中所有行映射之后,在返回调用方法前关闭结果集来处理的。
但是,在批处理的时候就不一样了, 必须得等 step 执行完成才能调用close。下图描绘了基于游标的ItemReader是如何处理的,使用的SQL语句非常简单, 而且都是类似的实现方式:
JdbcCursorItemReader
CREATE TABLE CUSTOMER ( ID BIGINT IDENTITY PRIMARY KEY, NAME VARCHAR(45), CREDIT FLOAT );
public class CustomerCreditRowMapper implements RowMapper { public static final String ID_COLUMN = "id"; public static final String NAME_COLUMN = "name"; public static final String CREDIT_COLUMN = "credit"; public Object mapRow(ResultSet rs, int rowNum) throws SQLException { CustomerCredit customerCredit = new CustomerCredit(); customerCredit.setId(rs.getInt(ID_COLUMN)); customerCredit.setName(rs.getString(NAME_COLUMN)); customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN)); return customerCredit; } }
//For simplicity sake, assume a dataSource has already been obtained JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource); List customerCredits = jdbcTemplate.query("SELECT ID, NAME, CREDIT from CUSTOMER", new CustomerCreditRowMapper());当执行完上面的代码, customerCredits 这个 List 中将包含 1000 个 CustomerCredit 对象。 在 query 方法中, 先从DataSource 获取一个连接, 然后用来执行给定的SQL, 获取结果后对 ResultSet 中的每一行调用一次 mapRow 方法。 让我们来对比一下 JdbcCursorItemReader 的实现:
JdbcCursorItemReader itemReader = new JdbcCursorItemReader(); itemReader.setDataSource(dataSource); itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER"); itemReader.setRowMapper(new CustomerCreditRowMapper()); int counter = 0; ExecutionContext executionContext = new ExecutionContext(); itemReader.open(executionContext); Object customerCredit = new Object(); while(customerCredit != null){ customerCredit = itemReader.read(); counter++; } itemReader.close(executionContext);<bean id="itemReader" class="org.spr...JdbcCursorItemReader"> <property name="dataSource" ref="dataSource"/> <property name="sql" value="select ID, NAME, CREDIT from CUSTOMER"/> <property name="rowMapper"> <bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/> </property> </bean>
HibernateCursorItemReader
HibernateTemplate , Spring Batch开发者也面临同样的选择。HibernateCursorItemReader 是 Hibernate 的游标实现。 其实在批处理中使用 Hibernate 那是相当有争议。这很大程度上是因为 Hibernate 最初就是设计了用来开发在线程序的。
但也不是说Hibernate就不能用来进行批处理。最简单的解决办法就是使用一个 StatelessSession (无状态会话), 而不使用标准 session 。这样就去掉了在批处理场景中 Hibernate 那些恼人的缓存、脏检查等等。
更多无状态会话与正常hibernate会话之间的差异, 请参考你使用的 hibernate 版本对应的文档。HibernateCursorItemReader 允许您声明一个HQL语句, 并传入 SessionFactory , 然后每次调用 read 时就会返回一个对象, 和 JdbcCursorItemReader 一样。下面的示例配置也使用和 JDBC reader 相同的数据库表:
HibernateCursorItemReader itemReader = new HibernateCursorItemReader(); itemReader.setQueryString("from CustomerCredit"); //For simplicity sake, assume sessionFactory already obtained. itemReader.setSessionFactory(sessionFactory); itemReader.setUseStatelessSession(true); int counter = 0; ExecutionContext executionContext = new ExecutionContext(); itemReader.open(executionContext); Object customerCredit = new Object(); while(customerCredit != null){ customerCredit = itemReader.read(); counter++; } itemReader.close(executionContext);
hibernate 映射文件正确的话。 useStatelessSession 属性的默认值为 true , 这里明确设置的目的只是为了引起你的注意,我们可以通过他来进行切换。 还值得注意的是 可以通过 setFetchSize 设置底层 cursor 的 fetchSize 属性 。与JdbcCursorItemReader一样,配置很简单:
<bean id="itemReader" class="org.springframework.batch.item.database.HibernateCursorItemReader"> <property name="sessionFactory" ref="sessionFactory" /> <property name="queryString" value="from CustomerCredit" /> </bean>StoredProcedureItemReader
- 作为一个 ResultSet 返回(SQL Server, Sybase, DB2, Derby 以及 MySQL支持)
- 作为一个 out 参数返回 ref-cursor (Oracle和PostgreSQL使用这种方式)
- 作为存储函数(stored function)的返回值
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader"> <property name="dataSource" ref="dataSource"/> <property name="procedureName" value="sp_customer_credit"/> <property name="rowMapper"> <bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/> </property> </bean>这个例子依赖于存储过程提供一个 ResultSet 作为返回结果(方式1)。
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader"> <property name="dataSource" ref="dataSource"/> <property name="procedureName" value="sp_customer_credit"/> <property name="refCursorPosition" value="1"/> <property name="rowMapper"> <bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/> </property> </bean>如果存储函数的返回值是一个游标(方式 3), 则需要将 function 属性设置为 true , 默认为 false 。如下面所示:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader"> <property name="dataSource" ref="dataSource"/> <property name="procedureName" value="sp_customer_credit"/> <property name="function" value="true"/> <property name="rowMapper"> <bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/> </property> </bean>在所有情况下,我们都需要定义 RowMapper 以及 DataSource, 还有存储过程的名字。
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader"> <property name="dataSource" ref="dataSource"/> <property name="procedureName" value="spring.cursor_func"/> <property name="parameters"> <list> <bean class="org.springframework.jdbc.core.SqlOutParameter"> <constructor-arg index="0" value="newid"/> <constructor-arg index="1"> <util:constant static-field="oracle.jdbc.OracleTypes.CURSOR"/> </constructor-arg> </bean> <bean class="org.springframework.jdbc.core.SqlParameter"> <constructor-arg index="0" value="amount"/> <constructor-arg index="1"> <util:constant static-field="java.sql.Types.INTEGER"/> </constructor-arg> </bean> <bean class="org.springframework.jdbc.core.SqlParameter"> <constructor-arg index="0" value="custid"/> <constructor-arg index="1"> <util:constant static-field="java.sql.Types.INTEGER"/> </constructor-arg> </bean> </list> </property> <property name="refCursorPosition" value="1"/> <property name="rowMapper" ref="rowMapper"/> <property name="preparedStatementSetter" ref="parameterSetter"/> </bean>除了参数声明, 我们还需要指定一个 PreparedStatementSetter 实现来设置参数值。这和上面的 JdbcCursorItemReader 一样。
1.9.2 可分页的 ItemReader
JdbcPagingItemReader
SqlPagingQueryProviderFactoryBean 需要指定一个 select 子句以及一个 from 子句(clause). 当然还可以选择提供 where子句. 这些子句加上所需的排序列 sortKey 被组合成为一个 SQL 语句(statement).
在 reader 被打开以后, 每次调用 read 方法则返回一个 item,和其他的 ItemReader一样. 使用分页是因为可能需要额外的行.
<bean id="itemReader" class="org.spr...JdbcPagingItemReader"> <property name="dataSource" ref="dataSource"/> <property name="queryProvider"> <bean class="org.spr...SqlPagingQueryProviderFactoryBean"> <property name="selectClause" value="select id, name, credit"/> <property name="fromClause" value="from customer"/> <property name="whereClause" value="where status=:status"/> <property name="sortKey" value="id"/> </bean> </property> <property name="parameterValues"> <map> <entry key="status" value="NEW"/> </map> </property> <property name="pageSize" value="1000"/> <property name="rowMapper" ref="customerMapper"/> </bean>‘ parameterValues ‘属性可用来为查询指定参数映射map。如果在where子句中使用了命名参数,那么这些entry的key应该和命名参数一一对应。如果使用传统的 ‘?’ 占位符, 则每个entry的key就应该是占位符的数字编号,和JDBC占位符一样索引都是从1开始。
JpaPagingItemReader
JpaPagingItemReader 允许您声明一个JPQL语句,并传入一个 EntityManagerFactory 。然后就和其他的 ItemReader 一样,每次调用它的 read 方法都会返回一个 item. 当需要更多实体,则内部就会自动发生分页。下面是一个示例配置,和上面的JDBC reader一样,都是 ‘customer credit’:
<bean id="itemReader" class="org.spr...JpaPagingItemReader"> <property name="entityManagerFactory" ref="entityManagerFactory"/> <property name="queryString" value="select c from CustomerCredit c"/> <property name="pageSize" value="1000"/> </bean>
IbatisPagingItemReader
下面是和上面的示例同样功能的配置,使用IbatisPagingItemReader来读取CustomerCredits:
<bean id="itemReader" class="org.spr...IbatisPagingItemReader"> <property name="sqlMapClient" ref="sqlMapClient"/> <property name="queryId" value="getPagedCustomerCredits"/> <property name="pageSize" value="1000"/> </bean>上述 IbatisPagingItemReader 配置引用了一个IBATIS查询,名为“getPagedCustomerCredits”。如果使用MySQL,那么查询XML应该类似于下面这样。
<select id="getPagedCustomerCredits" resultMap="customerCreditResult"> select id, name, credit from customer order by id asc LIMIT #_skiprows#, #_pagesize# </select>_skiprows 和 _pagesize 变量都是 IbatisPagingItemReader 提供的,还有一个 _page 变量,需要时也可以使用。分页查询的语法根据数据库不同使用。下面是使用Oracle的一个例子(但我们需要使用CDATA来包装某些特殊符号,因为是放在XML文档中嘛):
<select id="getPagedCustomerCredits" resultMap="customerCreditResult"> select * from ( select * from ( select t.id, t.name, t.credit, ROWNUM ROWNUM_ from customer t order by id )) where ROWNUM_ <![CDATA[ > ]]> ( #_page# * #_pagesize# ) ) where ROWNUM <![CDATA[ <= ]]> #_pagesize# </select>1.9.3 Database ItemWriters
1.10 重用已存在的 Service
<bean id="itemReader" class="org.springframework.batch.item.adapter.ItemReaderAdapter"> <property name="targetObject" ref="fooService" /> <property name="targetMethod" value="generateFoo" /> </bean> <bean id="fooService" class="org.springframework.batch.item.sample.FooService" />
特别需要注意的是, targetMethod 必须和 read 方法行为对等: 如果不存在则返回null, 否则返回一个 Object。 其他的值会使框架不知道何时该结束处理, 或者引起无限循环或不正确的失败,这取决于 ItemWriter 的实现。 ItemWriter 的实现同样简单:
<bean id="itemWriter" class="org.springframework.batch.item.adapter.ItemWriterAdapter"> <property name="targetObject" ref="fooService" /> <property name="targetMethod" value="processFoo" /> </bean> <bean id="fooService" class="org.springframework.batch.item.sample.FooService" />1.11 输入校验
public interface Validator { void validate(Object value) throws ValidationException; }
约定是如果对象无效则 validate 方法抛出一个异常, 如果对象合法那就正常返回。 Spring Batch 提供了开箱即用的ItemProcessor:
<bean class="org.springframework.batch.item.validator.ValidatingItemProcessor"> <property name="validator" ref="validator" /> </bean> <bean id="validator" class="org.springframework.batch.item.validator.SpringValidator"> <property name="validator"> <bean id="orderValidator" class="org.springmodules.validation.valang.ValangValidator"> <property name="valang"> <value> <![CDATA[ { orderId : ? > 0 AND ? <= 9999999999 : 'Incorrect order ID' : 'error.order.id' } { totalLines : ? = size(lineItems) : 'Bad count of order lines' : 'error.order.lines.badcount'} { customer.registered : customer.businessCustomer = FALSE OR ? = TRUE : 'Business customer must be registered' : 'error.customer.registration'} { customer.companyName : customer.businessCustomer = FALSE OR ? HAS TEXT : 'Company name for business customer is mandatory' :'error.customer.companyname'} ]]> </value> </property> </bean> </property> </bean>
1.12 不保存执行状态
<bean id="playerSummarizationSource" class="org.spr...JdbcCursorItemReader"> <property name="dataSource" ref="dataSource" /> <property name="rowMapper"> <bean class="org.springframework.batch.sample.PlayerSummaryMapper" /> </property> <property name="saveState" value="false" /> <property name="sql"> <value> SELECT games.player_id, games.year_no, SUM(COMPLETES), SUM(ATTEMPTS), SUM(PASSING_YARDS), SUM(PASSING_TD), SUM(INTERCEPTIONS), SUM(RUSHES), SUM(RUSH_YARDS), SUM(RECEPTIONS), SUM(RECEPTIONS_YARDS), SUM(TOTAL_TD) from games, players where players.player_id = games.player_id group by games.player_id, games.year_no </value> </property> </bean>
1.13 创建自定义 ItemReaders 与 ItemWriters
1.13.1 自定义 ItemReader 示例
public class CustomItemReader<T> implements ItemReader<T>{ List<T> items; public CustomItemReader(List<T> items) { this.items = items; } public T read() throws Exception, UnexpectedInputException,NoWorkFoundException, ParseException { if (!items.isEmpty()) { return items.remove(0); } return null; } }List<String> items = new ArrayList<String>(); items.add("1"); items.add("2"); items.add("3"); ItemReader itemReader = new CustomItemReader<String>(items); assertEquals("1", itemReader.read()); assertEquals("2", itemReader.read()); assertEquals("3", itemReader.read()); assertNull(itemReader.read());使 ItemReader 支持重启
如果需要保存状态信息,那应该使用 ItemStream 接口:
public class CustomItemReader<T> implements ItemReader<T>, ItemStream { List<T> items; int currentIndex = 0; private static final String CURRENT_INDEX = "current.index"; public CustomItemReader(List<T> items) { this.items = items; } public T read() throws Exception, UnexpectedInputException,ParseException { if (currentIndex < items.size()) { return items.get(currentIndex++); } return null; } public void open(ExecutionContext executionContext) throws ItemStreamException { if(executionContext.containsKey(CURRENT_INDEX)){ currentIndex = new Long(executionContext.getLong(CURRENT_INDEX)).intValue(); }else{ currentIndex = 0; } } public void update(ExecutionContext executionContext) throws ItemStreamException { executionContext.putLong(CURRENT_INDEX, new Long(currentIndex).longValue()); } public void close() throws ItemStreamException {} }
ExecutionContext executionContext = new ExecutionContext(); ((ItemStream)itemReader).open(executionContext); assertEquals("1", itemReader.read()); ((ItemStream)itemReader).update(executionContext); List<String> items = new ArrayList<String>(); items.add("1"); items.add("2"); items.add("3"); itemReader = new CustomItemReader<String>(items); ((ItemStream)itemReader).open(executionContext); assertEquals("2", itemReader.read());
还值得注意的是 ExecutionContext 中使用的 key 不应该过于简单。这是因为 ExecutionContext 被一个 Step 中的所有ItemStreams 共用。在大多数情况下,使用类名加上 key 的方式应该就足以保证唯一性。然而,在极端情况下, 同一个类的多个ItemStream 被用在同一个Step中时( 如需要输出两个文件的情况),就需要更加具备唯一性的name标识。出于这个原因,SpringBatch 的许多 ItemReader 和 ItemWriter 实现都有一个 setName() 方法, 允许覆盖默认的 key name。
1.13.2 自定义 ItemWriter 示例
public class CustomItemWriter<T> implements ItemWriter<T> { List<T> output = TransactionAwareProxyFactory.createTransactionalList(); public void write(List<? extends T> items) throws Exception { output.addAll(items); } public List<T> getOutput() { return output; } }
让 ItemWriter 支持重新启动
实际开发中, 如果自定义 ItemWriter restartable(支持重启),则会委托另一个 writer(例如, 在写入文件时), 否则会写入到关系型数据库(支持事务的资源)中, 此时 ItemWriter 不需要 restartable特性,因为自身是无状态的。 如果你的 writer 有状态, 则应该实现2个接口: ItemStream 和 ItemWriter 。 请记住, writer客户端需要知道 ItemStream 的存在, 所以需要在 xml 配置文件中将其注册为 stream.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140407.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
