大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
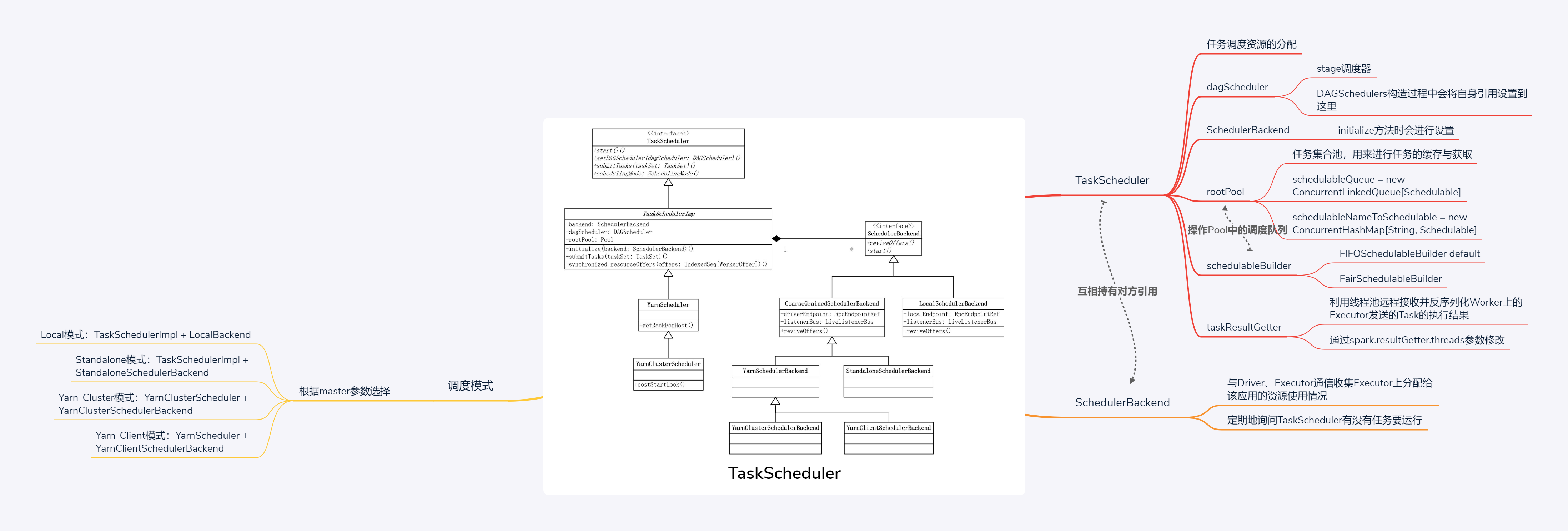
TaskScheduler可以看做任务调度的客户端,负责任务的提交,并且请求集群管理器对任务调度。TaskScheduler的类UML图如下,针对不同部署方式会有不同的TaskScheduler与SchedulerBackend进行组合。TaskScheduler类负责任务调度资源的分配,SchedulerBackend负责与Driver、Executor通信收集Executor上分配给该应用的资源使用情况。常见的任务调度模式有以下四种:
- Local模式:TaskSchedulerImpl + LocalBackend
- Standalone模式:TaskSchedulerImpl + StandaloneSchedulerBackend
- Yarn-Cluster模式:YarnClusterScheduler + YarnClusterSchedulerBackend
- Yarn-Client模式:YarnScheduler + YarnClientSchedulerBackend

下面以最常用的Yarn-Cluster模式为例,从以下四个步骤来分析源码实现方式:
- TaskScheduler的创建;
- Task的提交;
TaskScheduler的创建
-
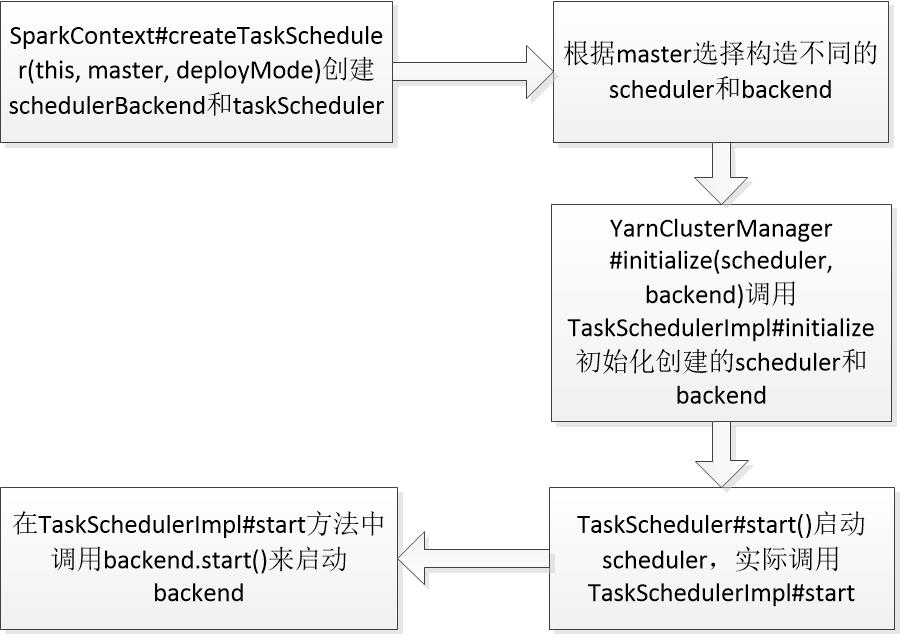
TaskScheduler是在SparkContext中定义并启动的:
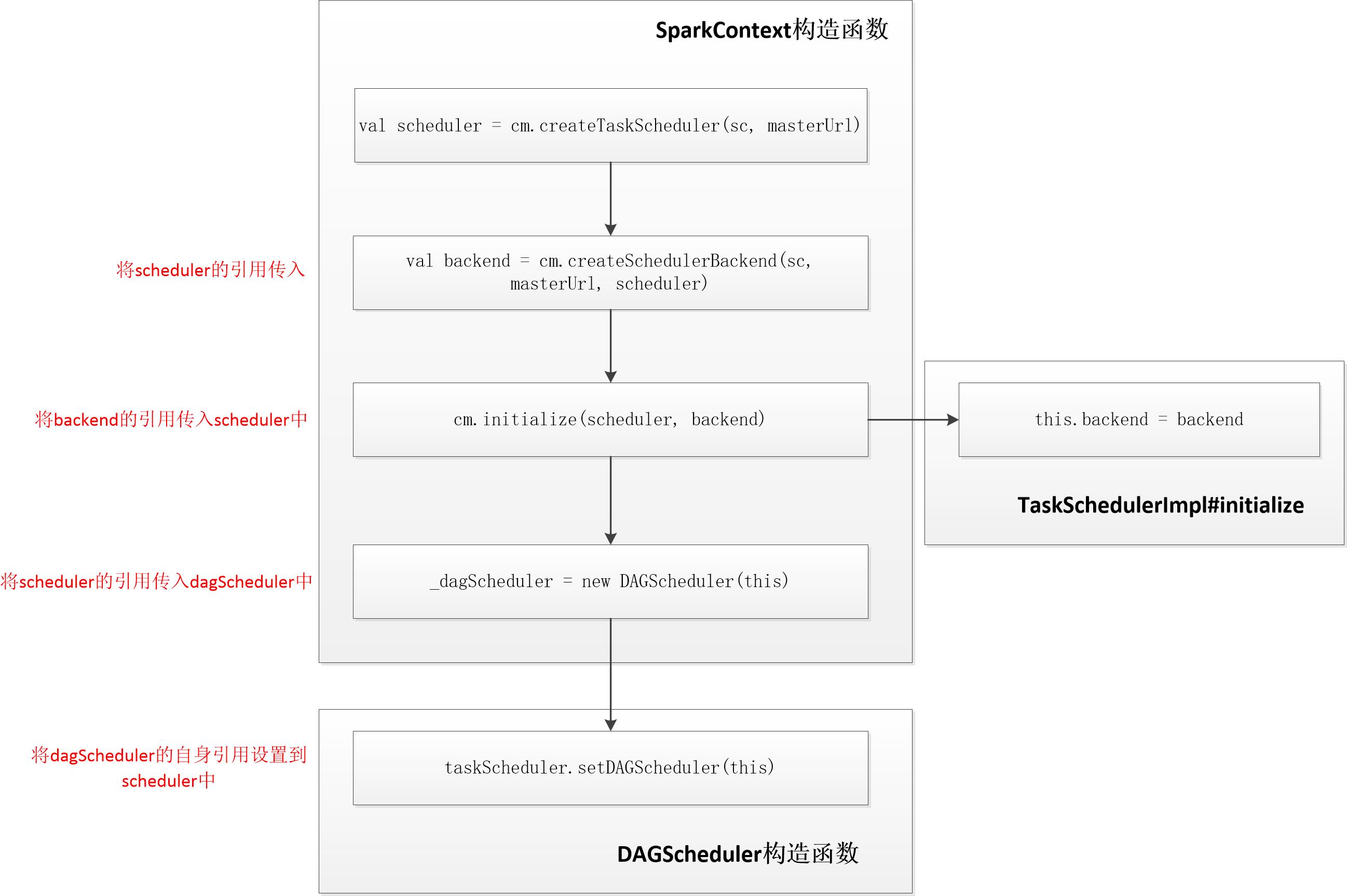
// We need to register "HeartbeatReceiver" before "createTaskScheduler" because Executor will // retrieve "HeartbeatReceiver" in the constructor. (SPARK-6640) // 需要在createTaskScheduler调用前注册HeartbeatReceiver,因为Executor在构造时就要检索HeartbeatReceiver消息 _heartbeatReceiver = env.rpcEnv.setupEndpoint( HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this)) // master是"spark.master"参数的值,deployMode是"spark.submit.deployMode"参数的值 // Create and start the scheduler // 创建task scheduler,返回(backend, scheduler)的Tuple val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode) _schedulerBackend = sched _taskScheduler = ts // DAGScheduler中保存有taskScheduler的引用,同样构造DAGScheduler时也将自身引用设置到taskScheduler中 _dagScheduler = new DAGScheduler(this) // 向HeartbeatReceiver发送一条SparkContext.taskScheduler已经创建好的消息 _heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet) // start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's // constructor // 在DAGScheduler的构造器中将自身的引用设置到taskScheduler里之后,启动TaskScheduler, // 方法中同时也会调用backend.start方法启动backend _taskScheduler.start() -
TaskScheduler的构建
createTaskScheduler方法会根据master参数匹配部署模式,创建TaskSchedulerImpl,并生成不同的SchedulerBackend(Yarn-Cluster模式:YarnClusterScheduler + YarnClusterSchedulerBackend)。
master match { case masterUrl => val cm = getClusterManager(masterUrl) match { case Some(clusterMgr) => clusterMgr case None => throw new SparkException("Could not parse Master URL: '" + master + "'") } try { // 利用集群管理器创建TaskScheduler val scheduler = cm.createTaskScheduler(sc, masterUrl) // 利用集群管理器创建SchedulerBackend,并且将scheduler的引用传入 val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler) // 内部调用TaskSchedulerImpl.initialize方法将backend引用设置到scheduler中, // 并根据schedulingMode创建调度管理器FIFOScheduler或者FairScheduler cm.initialize(scheduler, backend) (backend, scheduler) } catch { case se: SparkException => throw se case NonFatal(e) => throw new SparkException("External scheduler cannot be instantiated", e) } ... }YarnClusterScheduler和YarnScheduler类构造过程为空,TaskScheduler的构造过程全部在TaskSchedulerImpl中。
// Listener object to pass upcalls into // DAGScheduler的引用,在DAGSchedulers构造过程中会将自身引用设置到这里 var dagScheduler: DAGScheduler = null // SchedulerBackend的引用,在initialize方法时会进行设置 var backend: SchedulerBackend = null // 保留MapOutputTrackerMaster的引用,driver中存储map输出结果位置的结构 val mapOutputTracker = SparkEnv.get.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster] // 调度器,在initialize方法中根据schedulingMode创建FIFO或者FAIR调度器,默认为FIFO private var schedulableBuilder: SchedulableBuilder = null // default scheduler is FIFO private val schedulingModeConf = conf.get(SCHEDULER_MODE_PROPERTY, SchedulingMode.FIFO.toString) val schedulingMode: SchedulingMode = try { SchedulingMode.withName(schedulingModeConf.toUpperCase(Locale.ROOT)) } catch { case e: java.util.NoSuchElementException => throw new SparkException(s"Unrecognized $SCHEDULER_MODE_PROPERTY: $schedulingModeConf") } // 表示资源池或者任务集管理器的可调度实体 val rootPool: Pool = new Pool("", schedulingMode, 0, 0) // This is a var so that we can reset it for testing purposes. // Runs a thread pool that deserializes and remotely fetches (if necessary) task results. // 创建TaskResultGetter,利用线程池远程接收并反序列化Worker上的Executor发送的Task的执行结果 // 线程池利用Executors.newFixedThreadPool创建的,默认4个线程,线程名字以task-result-getter开头, // 可通过spark.resultGetter.threads参数修改 private[spark] var taskResultGetter = new TaskResultGetter(sc.env, this) -
TaskScheduler的初始化
创建完TaskScheduler和SchedulerBackend后,调用YarnClusterManager的initialize方法对其进行初始化,而其实际是调用TaskSchedulerImpl的initialize方法。以默认的FIFO调度为例,TaskSchedulerImpl的初始化过程如下:
-
设置SchedulerBackend引用。
-
根据schedulingMode配置来创建FIFOSchedulableBuilder或FairSchedulableBuilder,用来操作Pool中的调度队列。
-
创建Pool,Pool中缓存了调度队列、调度算法及TaskSetManager集合等信息。
def initialize(backend: SchedulerBackend) { this.backend = backend schedulableBuilder = { schedulingMode match { case SchedulingMode.FIFO => new FIFOSchedulableBuilder(rootPool) case SchedulingMode.FAIR => new FairSchedulableBuilder(rootPool, conf) case _ => throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " + s"$schedulingMode") } } schedulableBuilder.buildPools() }
-
TaskScheduler的启动
调用TaskScheduler#start方法来启动scheduler,实际调用TaskSchedulerImpl#start方法。
override def start() { // 启动SchedulerBackend, backend.start() // 如果不是本地模式且任务并发执行开关打开,则启动一个指定延时后周期调度执行的线程来执行并发任务 // 后台启动一个线程检查符合speculation条件的task if (!isLocal && conf.getBoolean("spark.speculation", false)) { logInfo("Starting speculative execution thread") speculationScheduler.scheduleWithFixedDelay(new Runnable { override def run(): Unit = Utils.tryOrStopSparkContext(sc) { checkSpeculatableTasks() } }, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS) } } -
TaskScheduler与SchedulerBackend的相互引用,TaskScheduler与DAGScheduler相互引用,具体实现的过程如下:
Task的提交
spark任务的操作分为两大类:transformation和action,而只有action操作才会触发真正的job执行。查看源码可以发现所有action操作实际是调用SparkContext.runJob来进行任务的提交,下面是以rdd的collect操作为例展示任务提交的整个调用过程:
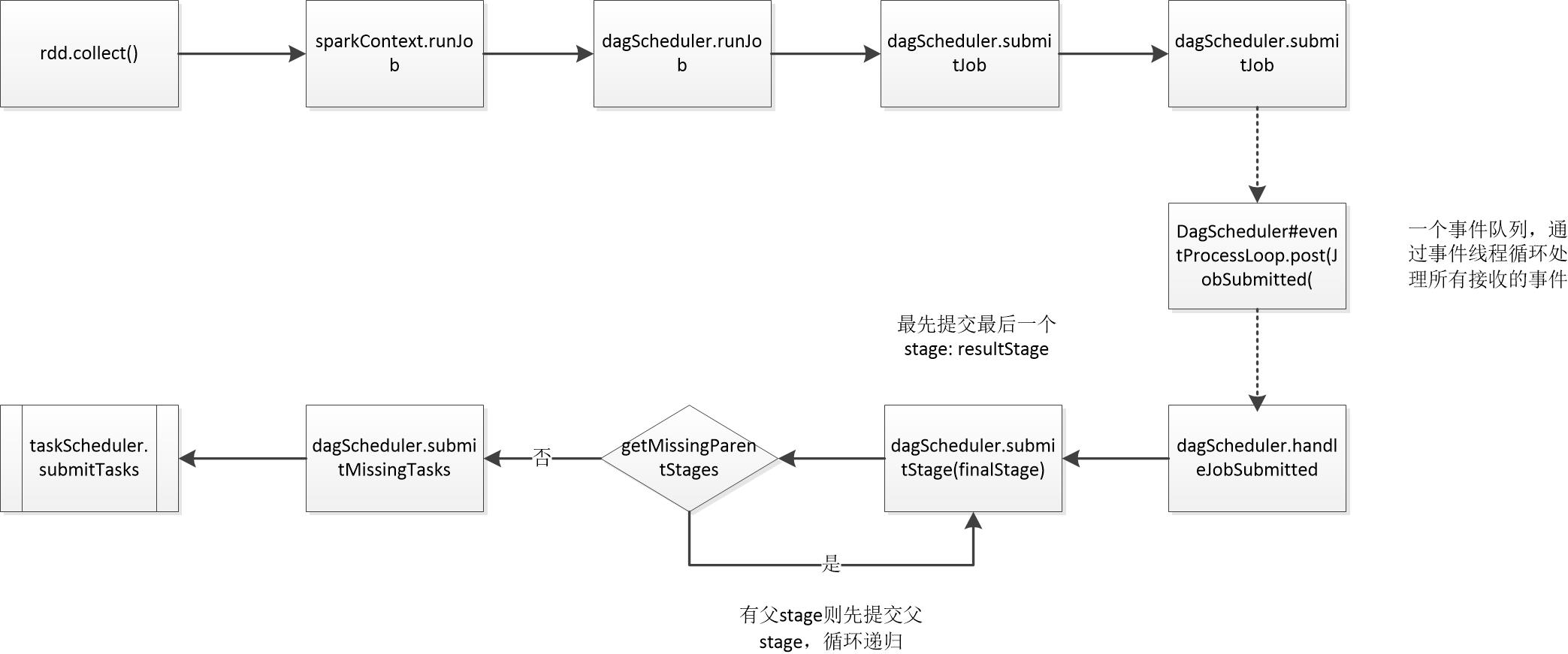
DAGScheduler将Stage打包成TaskSet交给TaskScheduler,TaskScheduler会将其封装为TaskSetManager加入到调度队列中(TaskSetManager负责监控管理同一个Stage中的Tasks,TaskScheduler就是以TaskSetManager为单元来调度任务)。TaskScheduler初始化后会启动SchedulerBackend,它负责跟外界打交道,接收Executor的注册信息,并维护Executor的状态。SchedulerBackend在启动后会定期地询问TaskScheduler有没有任务要运行,TaskScheduler会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行,Task提交流程如下图所示。
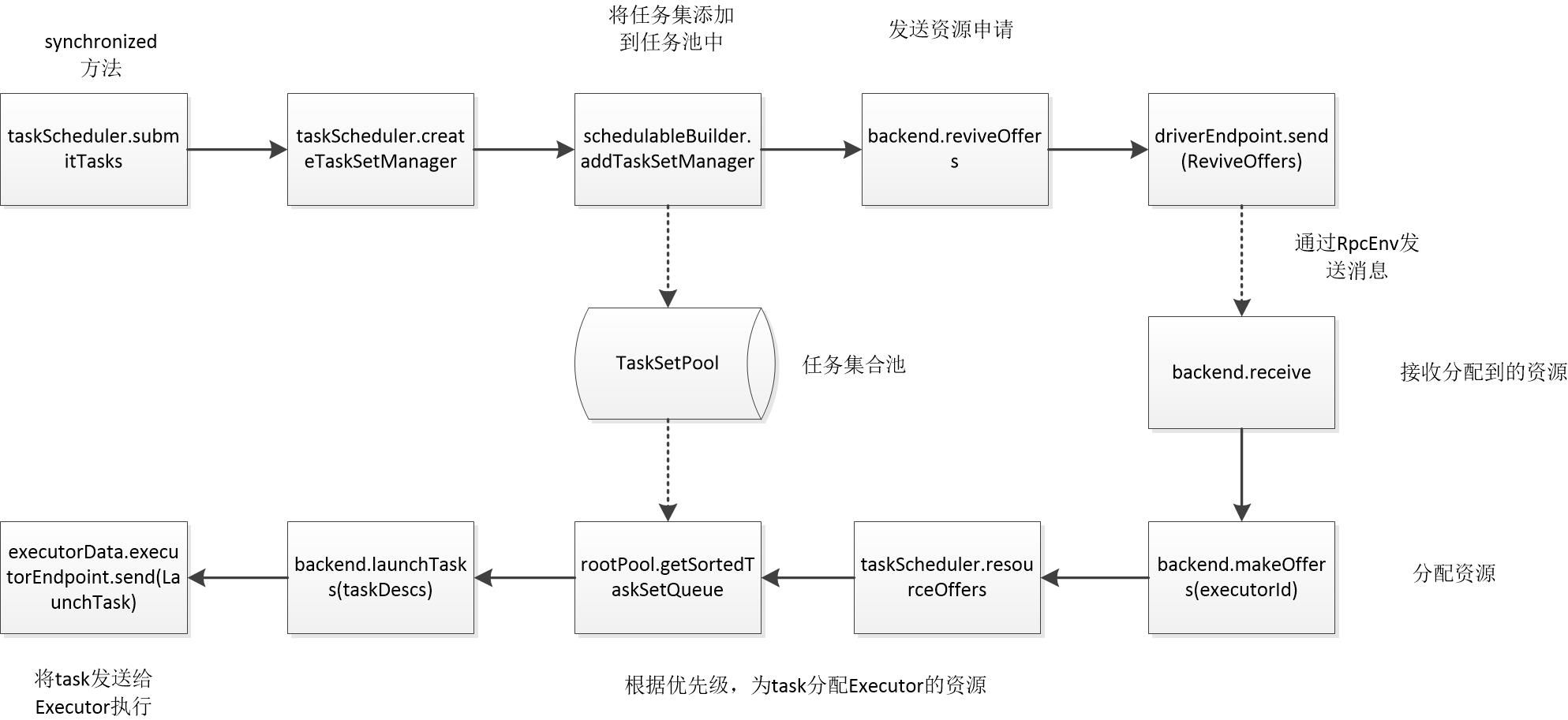
-
DAGScheduler将Stage打包成TaskSet交给TaskScheduler,TaskScheduler调用submitTasks方法进行任务调度。
// TaskSchedulerImpl.scala override def submitTasks(taskSet: TaskSet) { val tasks = taskSet.tasks // 同步代码块 this.synchronized { // 创建TaskSet管理器,对同一个TaskSet中的任务进行调度,跟踪每个task的状态, // 如果失败则重试(最大重试次数maxTaskFailures可通过spark.task.maxFailures设置,默认为4) // 通过延迟调度的方式为该TaskSet处理位置感知的调度 val manager = createTaskSetManager(taskSet, maxTaskFailures) val stage = taskSet.stageId // 获取stageId对应<stageAttemptId, TaskSetManager> val stageTaskSets = taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager]) // 更新stageAttemptId对应的TaskSetManager关系 stageTaskSets(taskSet.stageAttemptId) = manager // 检测冲突,如果同一stageAttemptId对应多个taskSet且当前这个TaskSetManager是僵尸进程,则抛出异常 val conflictingTaskSet = stageTaskSets.exists { case (_, ts) => ts.taskSet != taskSet && !ts.isZombie } if (conflictingTaskSet) { throw new IllegalStateException(s"more than one active taskSet for stage $stage:" + s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}") } // 将当前TaskSetManager提交到调度器的调度池Pool中 schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) if (!isLocal && !hasReceivedTask) { starvationTimer.scheduleAtFixedRate(new TimerTask() { override def run() { if (!hasLaunchedTask) { logWarning("Initial job has not accepted any resources; " + "check your cluster UI to ensure that workers are registered " + "and have sufficient resources") } else { this.cancel() } } }, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS) } hasReceivedTask = true } // 向SchedulerBackend申请资源 backend.reviveOffers() } -
通过RpcEnv发送一个请求资源的消息后,CoarseGrainedSchedulerBackend的receive方法则会接收分配到的资源。在该方法中,由于接收到的是ReviveOffers,会调用makeOffers方法开始分配资源。
override def receive: PartialFunction[Any, Unit] = { case ReviveOffers => // 分配资源 makeOffers() ... } -
为所有executors提供资源分配:CoarseGrainedSchedulerBackend#makeOffers。
private def makeOffers() { // Make sure no executor is killed while some task is launching on it // 使用同步块,保证在executor上分配任务时executor不会被kill掉 val taskDescs = CoarseGrainedSchedulerBackend.this.synchronized { // Filter out executors under killing // 过滤掉正在被kill的executor,得到所有可用的executors val activeExecutors = executorDataMap.filterKeys(executorIsAlive) val workOffers = activeExecutors.map { case (id, executorData) => new WorkerOffer(id, executorData.executorHost, executorData.freeCores) }.toIndexedSeq // 根据优先级,为task分配Executor上的资源 scheduler.resourceOffers(workOffers) } if (!taskDescs.isEmpty) { // 将分配的任务发送到相应的Executor上去执行 launchTasks(taskDescs) } } -
根据优先级,为task分配Executor上的资源:TaskSchedulerImpl#resourceOffers。
/** * Called by cluster manager to offer resources on slaves. We respond by asking our active task * sets for tasks in order of priority. We fill each node with tasks in a round-robin manner so * that tasks are balanced across the cluster. * 由cluster manager来调用,为task分配slave节点上的资源 * 根据优先级为task分配资源 * 采用round-robin方式使task均匀分布到集群的各个节点上 */ def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized { // Mark each slave as alive and remember its hostname // Also track if new executor is added // 标记每个salve为活跃,并保存它的hostname // 如果有新executor加入同样也进行跟踪标记 var newExecAvail = false for (o <- offers) { if (!hostToExecutors.contains(o.host)) { hostToExecutors(o.host) = new HashSet[String]() } if (!executorIdToRunningTaskIds.contains(o.executorId)) { hostToExecutors(o.host) += o.executorId executorAdded(o.executorId, o.host) executorIdToHost(o.executorId) = o.host executorIdToRunningTaskIds(o.executorId) = HashSet[Long]() newExecAvail = true } for (rack <- getRackForHost(o.host)) { hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host } } // Before making any offers, remove any nodes from the blacklist whose blacklist has expired. Do // this here to avoid a separate thread and added synchronization overhead, and also because // updating the blacklist is only relevant when task offers are being made. // 在做任何分配之前,请从已过期的黑名单中删除黑名单的任何节点 // 此操作是为了避免单独的线程和增加的同步开销,还因为只有在提出任务时更新黑名单才有意义 blacklistTrackerOpt.foreach(_.applyBlacklistTimeout()) val filteredOffers = blacklistTrackerOpt.map { blacklistTracker => offers.filter { offer => !blacklistTracker.isNodeBlacklisted(offer.host) && !blacklistTracker.isExecutorBlacklisted(offer.executorId) } }.getOrElse(offers) // 为避免多个Task集中分配到某些机器上,对这些Task进行随机打散 val shuffledOffers = shuffleOffers(filteredOffers) // Build a list of tasks to assign to each worker. // 构建要分配给每个Worker的Task列表 val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores)) val availableCpus = shuffledOffers.map(o => o.cores).toArray // 从调度池中获取排好序的TaskSetManager,由调度池确定TaskSet的执行优先级顺序 val sortedTaskSets = rootPool.getSortedTaskSetQueue for (taskSet <- sortedTaskSets) { logDebug("parentName: %s, name: %s, runningTasks: %s".format( taskSet.parent.name, taskSet.name, taskSet.runningTasks)) // 如果该executor是新分配来的,则重新计算TaskSetManager的就近原则 if (newExecAvail) { taskSet.executorAdded() } } // Take each TaskSet in our scheduling order, and then offer it each node in increasing order // of locality levels so that it gets a chance to launch local tasks on all of them. // NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY // 以我们的调度顺序执行每个TaskSet,然后按照升序的本地性级别为每个节点分配资源, // 以便有机会在所有节点上启动本地任务 // 本地性优先级顺序:PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY for (taskSet <- sortedTaskSets) { var launchedAnyTask = false var launchedTaskAtCurrentMaxLocality = false for (currentMaxLocality <- taskSet.myLocalityLevels) { do { // 在分配的executor资源上,执行TaskSet中包含的所有task launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet( taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks) launchedAnyTask |= launchedTaskAtCurrentMaxLocality } while (launchedTaskAtCurrentMaxLocality) } if (!launchedAnyTask) { taskSet.abortIfCompletelyBlacklisted(hostToExecutors) } } if (tasks.size > 0) { hasLaunchedTask = true } return tasks }
参考文章
- http://www.cnblogs.com/tovin/p/3879151.html
- http://sharkdtu.com/posts/spark-scheduler.html
- https://blog.csdn.net/dabokele/article/details/51932102
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183135.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
