大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
前言
众所周知,随着用户量的增多,数据库操作往往会成为一个系统的瓶颈所在,而且一般的系统“读”的压力远远大于“写”,因此我们可以通过实现数据库的读写分离来提高系统的性能。
基础知识
要实现读写分离,就要解决主从数据库数据同步的问题,在主数据库写入数据后要保证从数据库的数据也要更新。
实现思路
一个主数据库用来写数据,一个或多个从数据库用来读数据,将主数据库的数据同步到从数据库中。
一,主从同步的原理
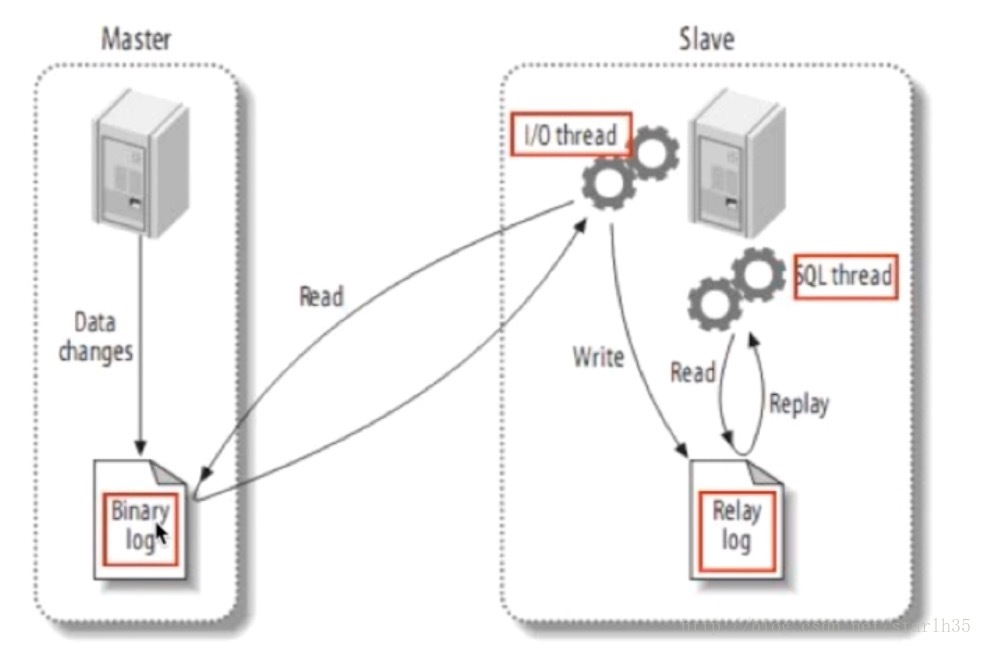

主服务器master记录数据库操作日志到Binary log,从服务器开启i/o线程将二进制日志记录的操作同步到relay log(存在从服务器的缓存中),另外sql线程将relay log日志记录的操作在从服务器执行。
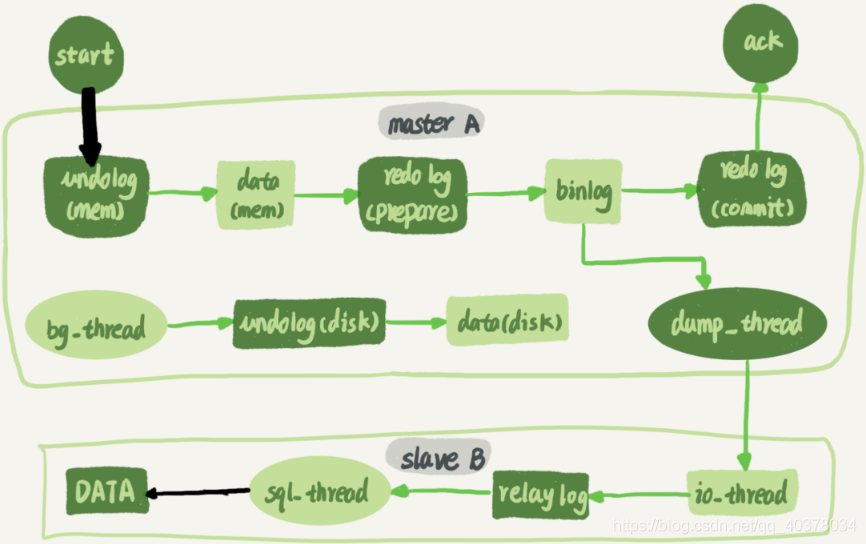
备库B和主库A之间维持了一个长连接。主库A内部有一个线程,专门用于服务备库B的这个长连接。一个事务日志同步的完整过程如下:
1.在备库B上通过change master命令,设置主库A的IP、端口、用户名、密码,以及要从哪个位置开始请求binlog,这个位置包含文件名和日志偏移量
2.在备库B上执行start slave命令,这时备库会启动两个线程,就是图中的io_thread和sql_thread。其中io_thread负责与主库建立连接
3.主库A校验完用户名、密码后,开始按照备库B传过来的位置,从本地读取binlog,发给B
4.备库B拿到binlog后,写到本地文件,称为中转日志
5.sql_thread读取中转日志,解析出日志里的命令,并执行
由于多线程复制方案的引入,sql_thread演化成了多个线程。主备的并行复制能力,要关注的就是上图中黑色的两个箭头。一个代表客户端写入主库,另一个代表备库上sql_thread执行中转日志
在MySQL5.6版本之前,MySQL只支持单线程复制,由此在主库并发高、TPS高时就会出现严重的主备延迟问题,多线程复制机制都是把只有一个线程的sql_thread拆成多个线程,都符合下面这个模型:
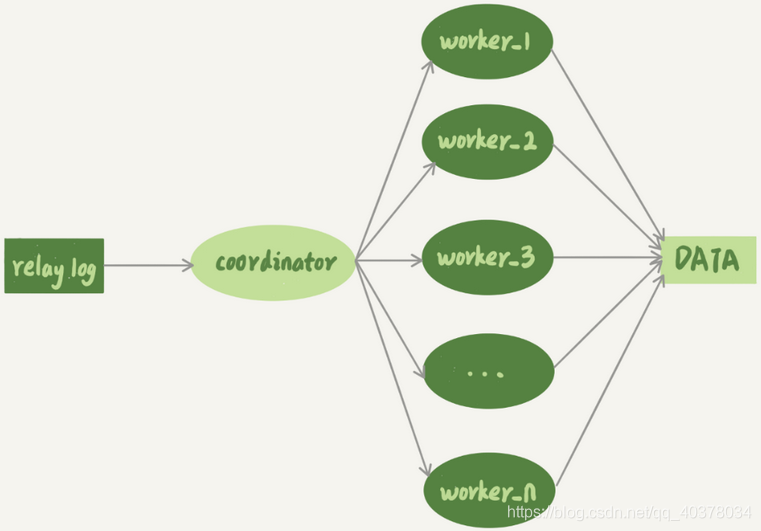
coordinator就是原来的sql_thread,不过现在它不再直接更新数据了,只负责读取中转日志和分发事务。真正更新日志的,变成了worker线程。而worker线程的个数就是由参数slave_parallel_workers决定的。
本部分参考《MySQL主备、主从、读写分离详解》,关于循环复制,主备延迟,切换策略等更多内容可参考此文章。
二,主从同步实现
1,修改主库配置
1,修改my.ini配置文件
2.在主服务器master上配置开启Binary log,主要是在[mysqld]下面添加:
server-id=1
log-bin=master-bin
log-bin-index=master-bin.index
3.重启mysql服务
4.检查配置效果,进入主数据库并执行
mysql> SHOW MASTER STATUS;
输出如下图,记录下file的名字,这个就是log文件的名字,配置从服务器时需要使用

2,修改从库配置
1.配置从服务器的 my.ini
server-id=2
relay-log-index=slave-relay-bin.index
relay-log=slave-relay-bin
注:这里面的server-id 一定要和主库的不同
2.完成后重启从mysql服务
3,配置两个数据库的关联
1,连接主数据库执行以下操作:
//1,在主库创建账号,用于从库的连接
//2,赋予新建的账户从库权限(不同版本设置方式不同,此处为mysql8)
mysql> CREATE USER qiao IDENTIFIED BY '123456';
mysql> grant replication slave on *.* to 'qiao'@'%';
mysql> flush privileges;
2,连接从库执行以下操作
change master to master_host='127.0.0.1',
master_port=3307,
master_user='qiao',
master_password='123456',
master_log_file='master-bin.000001',
master_log_pos=0;
master_host:主库的ip
master_port:主库的端口,
master_user:连接主库的账号’,
master_password:账号的密码,
master_log_file:log文件名,
master_log_pos=0;//写0会赋予默认值
4,查看从库状态
mysql> start slave ;//启动同步
mysql> show slave status\G //查看启动状态,注意不要加分号
mysql> stop slave ; //停止同步
查看状态后如下图所示,当Slave_Log_Running和Slave_SQL_Running都为Yes时表示同步启动成功。
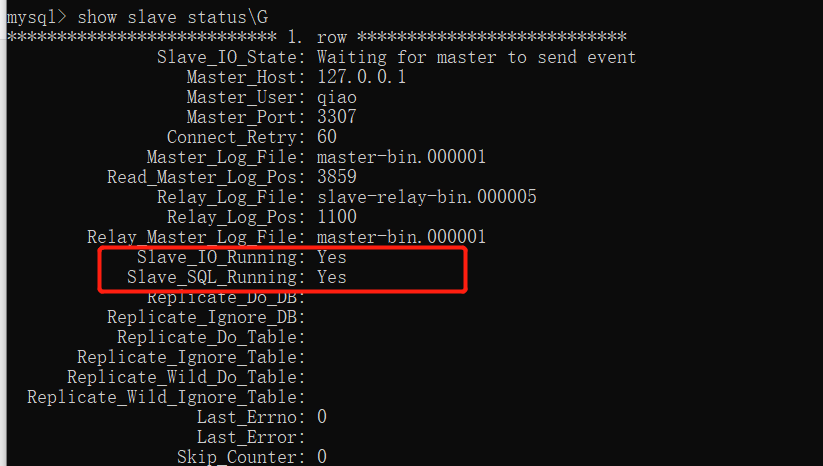
这里看到从数据库已经在等待主库的消息了,接下来在主库的操作,在从库都会执行了。我们可以主库负责写,从库负责读(不要在从库进行写操作),达到读写分离的效果。
三,实现读写分离
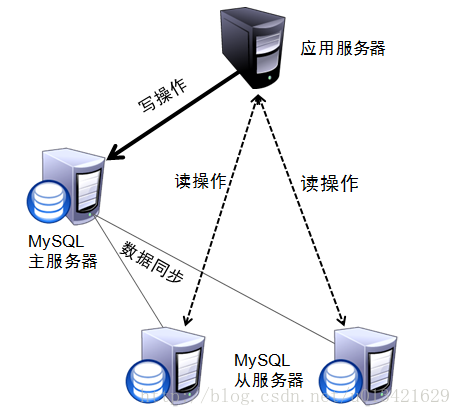
添加mycat中间件,可屏蔽读写分离,数据源选择等业务,减小代码量。
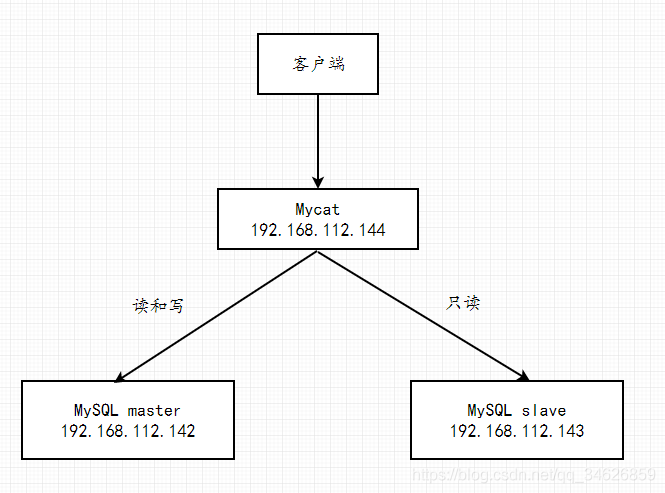
1,读写分离实现方式
1,应用本身通过代码实现,例如基于动态数据源、AOP的原理来实现写操作时用主数据库,读操作时用从数据库。此方法可参考《MySQL:MyCat中间件实现动态数据源、读写分离,分库分表》
2,通过中间件的方式实现,例如通过Mycat,即中间件会分析对应的SQL,写操作时会连接主数据库,读操作时连接从数据库。
3,配置多数据源,获取不同的DAO。
2,mycat安装(windous)
注:linux下安装配置可参考《linux安装mycat》
1,下载
https://github.com/MyCATApache/Mycat-Server/releases
2,解压
3,配置环境变量
%MYCAT_HOME%/bin
4.接下来要修改mycat/conf下面的几个配置文件
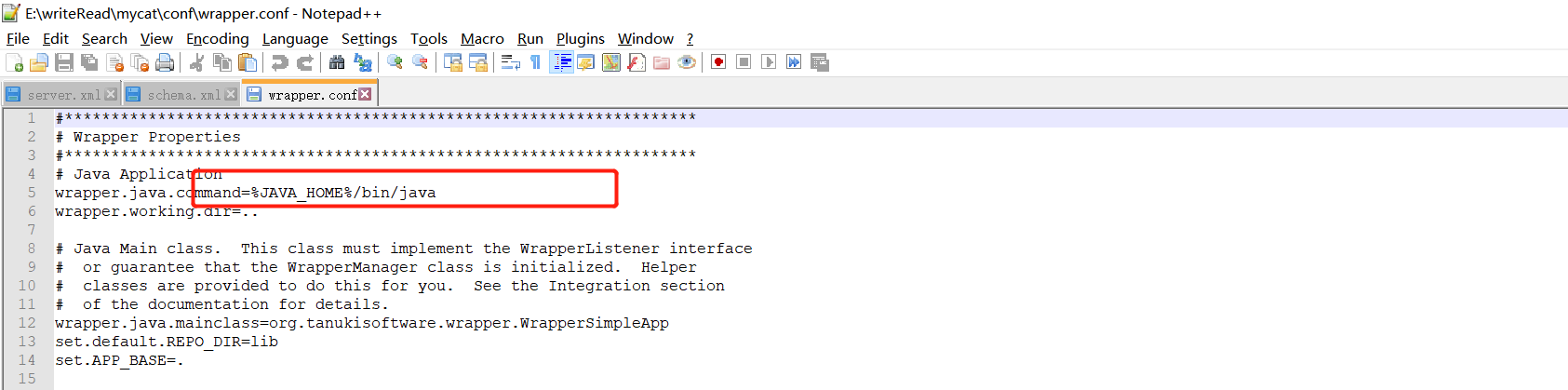
wrapper.conf 红字修改为自己的jdk的路径
5,在打开的cmd命令行窗口中,执行如下命令安装mycat(注意需要管理员账户登录,如果不是请使用管理员身份运行cmd打开命令行窗口):
mycat.bat install
6、启动和停止
可以使用如下命令启动mycat服务
mycat.bat start
启动后可以通过如下命令查看mycat的运行状态:
mycat.bat status
可以使用如下命令停止mycat服务
mycat.bat stop
3,mycat配置读写分离
1,修改server.xml
最主要的看下面的配置,这是连接mycat的时候的用户名和密码
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
2,修改schema.xml
详细配置可参考《schema.xml配置详解》
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<!-- auto sharding by id (long) -->
<!--splitTableNames 启用<table name 属性使用逗号分割配置多个表,即多个表使用这个配置-->
<!--fetchStoreNodeByJdbc 启用ER表使用JDBC方式获取DataNode rule="sharding-by-intfile" autoIncrement="true" fetchStoreNodeByJdbc="true"-->
<table name="testtable" primaryKey="id" dataNode="dn1" ruleRequired="fasle">
<!-- <childTable name="customer_addr" primaryKey="id" joinKey="customer_id" parentKey="id"> </childTable> -->
</table>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate" /> -->
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743" /> -->
<dataNode name="dn1" dataHost="localhost1" database="test" />
<!-- <dataNode name="dn2" dataHost="localhost1" database="test" /> <dataNode name="dn3" dataHost="localhost1" database="test" /> <dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" /> <dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" /> <dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" /> <dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://localhost:3307?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=UTC" user="root" password="123456">
<readHost host="hostS1" url="jdbc:mysql://localhost:3308?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=UTC" user="root" password="123456"/>
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
</mycat:schema>
- schema 标签用于定义MyCat 实例中的逻辑库,MyCat 可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用schema 标签来划分这些不同的逻辑库。
- dataNode 标签定义了MyCat 中的数据节点,也就是我们通常说所的数据分片。一个dataNode 标签就是一个独立的数据分片(几个DataNode就是把一个表分成几部分存储)。
- dataHost标签直接定义了具体的数据库实例、读写分离配置和心跳语句。其中有几个重要的属性:
balance属性
负载均衡类型,目前的取值有3 种:
balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的writeHost 上。
balance="1",全部的readHost 与stand by writeHost 参与select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1 与M2 互为主备),正常情况下,M2,S1,S2 都参与select 语句的负载均衡。
balance="2",所有读操作都随机的在writeHost、readhost 上分发。
balance="3",所有读请求随机的分发到wiriterHost 对应的readhost 执行,writerHost 不负担读压
力,注意balance=3 只在1.4 及其以后版本有,1.3 没有。
writeType 属性
负载均衡类型,目前的取值有3 种:
writeType="0", 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个
writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
writeType="1",所有写操作都随机的发送到配置的writeHost,1.5 以后废弃不推荐。
4,启动mycat
mycat.bat start
5,连接mycat测试
读库,写库,mycat对应的表结构

测试结果
当关闭主从同步后,在mycat的testTable中插入一条记录,write数据库的testTable中出现新添加的记录,刷新mycat的testTable表记录消失。
以下情况不建议用Mycat分库分表
1.非分片字段查询,
2.分页排序
3.任意表JOIN
4.分布式事务
具体参考《mycat从入门到放弃》
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182386.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
