大家好,又见面了,我是你们的朋友全栈君。
前言
最近在研究深度学习中图像数据处理的细节,基于的平台是PyTorch。心血来潮,总结一下,好记性不如烂笔头。
Batch Normalization
对于2015年出现的Batch Normalization1,2018年的文章Group Normalization2在Abstract中总结得言简意赅,我直接copy过来。
Batch Normalization (BN) is a milestone technique in the development of deep learning, enabling various networks to train. However, normalizing along the batch dimension introduces problems — BN’s error increases rapidly when the batch size becomes smaller, caused by inaccurate batch statistics estimation. This limits BN’s usage for training larger models and transferring features to computer vision tasks including detection, segmentation, and video, which require small batches constrained by memory consumption.
机器学习中,进行模型训练之前,需对数据做归一化处理,使其分布一致。在深度神经网络训练过程中,通常一次训练是一个batch,而非全体数据。每个batch具有不同的分布产生了internal covarivate shift问题——在训练过程中,数据分布会发生变化,对下一层网络的学习带来困难。Batch Normalization强行将数据拉回到均值为0,方差为1的正太分布上,一方面使得数据分布一致,另一方面避免梯度消失。
结合图1,说明Batch Normalization的原理。假设在网络中间经过某些卷积操作之后的输出的feature maps的尺寸为N×C×W×H,5为batch size(N),3为channel(C),W×H为feature map的宽高,则Batch Normalization的计算过程如下。
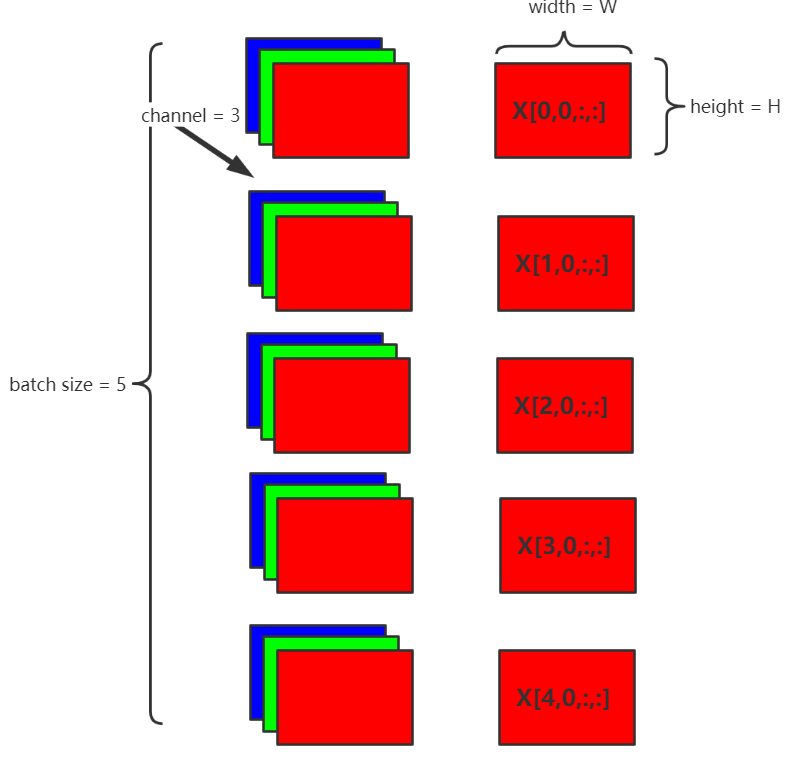

图 1
- 1.每个batch计算同一通道的均值 μ \mu μ,如图取channel 0,即 c = 0 c=0 c=0(红色表示)
μ = ∑ n = 0 N − 1 ∑ w = 0 W − 1 ∑ h = 0 H − 1 X [ n , c , w , h ] N × W × H \mu = \frac{\sum\limits_{n=0}^{N-1}\sum\limits_{w=0}^{W-1} \sum\limits_{h=0}^{H-1} X[n, c, w, h]}{N×W×H} μ=N×W×Hn=0∑N−1w=0∑W−1h=0∑H−1X[n,c,w,h] - 2.每个batch计算同一通道的方差 σ 2 σ^2 σ2
σ 2 = ∑ n = 0 N − 1 ∑ w = 0 W − 1 ∑ h = 0 H − 1 ( X [ n , c , w , h ] − μ ) 2 N × W × H σ^2 = \frac{\sum\limits_{n=0}^{N-1}\sum\limits_{w=0}^{W-1} \sum\limits_{h=0}^{H-1} (X[n, c, w, h]-\mu)^2}{N×W×H} σ2=N×W×Hn=0∑N−1w=0∑W−1h=0∑H−1(X[n,c,w,h]−μ)2 - 3.对当前channel下feature map中每个点 x x x,索引形式 X [ n , c , w , h ] X[n, c, w, h] X[n,c,w,h],做归一化
x ′ = ( x − μ ) σ 2 + ϵ x^{‘}=\frac{(x-\mu)}{\sqrt{σ^2+\epsilon}} x′=σ2+ϵ(x−μ) - 4.增加缩放和平移变量 γ \gamma γ和 β \beta β(可学习的仿射变换参数),归一化后的值
y = γ x ′ + β y=\gamma x^{‘}+\beta y=γx′+β
简化公式:
y = x − μ σ 2 + ϵ γ + β y=\frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}\gamma +\beta y=σ2+ϵx−μγ+β
原文中的算法描述如下,

注:上图1所示 m m m就是 N ∗ W ∗ H N*W*H N∗W∗H
PyTorch的nn.BatchNorm2d()函数
理解了Batch Normalization的过程,PyTorch里面的函数就参考其文档3用就好。
BatchNorm2d()内部的参数如下:
- num_features:一般情况下输入的数据格式为batch_size * num_features * height * width,即为特征数,channel数
- eps:分母中添加的一个值,目的是为了计算的稳定性,默认:1e-5
- momentum:一个用于运行过程中均值和方差的一个估计参数,默认值为 0.1 0.1 0.1; x ^ n e w = ( 1 − m o m e n t u m ) × x ^ + m o m e n t u m × x t \hat{x}_{new} =(1−momentum) × \hat{x} +momentum×x_t x^new=(1−momentum)×x^+momentum×xt,其中 x ^ \hat{x} x^是估计值, x t x_t xt是新的观测值
- affine:当设为true时,给定可以学习的系数矩阵 γ \gamma γ和 β \beta β
Show me the codes
import torch
import torch.nn as nn
def checkBN(debug = False):
# parameters
N = 5 # batch size
C = 3 # channel
W = 2 # width of feature map
H = 2 # height of feature map
# batch normalization layer
BN = nn.BatchNorm2d(C,affine=True) #gamma和beta, 其维度与channel数相同
# input and output
featuremaps = torch.randn(N,C,W,H)
output = BN(featuremaps)
# checkout
###########################################
if debug:
print("input feature maps:\n",featuremaps)
print("normalized feature maps: \n",output)
###########################################
# manually operation, the first channel
X = featuremaps[:,0,:,:]
firstDimenMean = torch.Tensor.mean(X)
firstDimenVar = torch.Tensor.var(X,False) #Bessel's Correction贝塞尔校正不被使用
BN_one = ((input[0,0,0,0] - firstDimenMean)/(torch.pow(firstDimenVar+BN.eps,0.5) )) * BN.weight[0] + BN.bias[0]
print('+++'*15,'\n','manually operation: ', BN_one)
print('==='*15,'\n','pytorch result: ', output[0,0,0,0])
if __name__=="__main__":
checkBN()
可以看出手算的结果和PyTorch的nn.BatchNorm2d的计算结果一致。
+++++++++++++++++++++++++++++++++++++++++++++
manually operation: tensor(-0.0327, grad_fn=<AddBackward0>)
=============================================
pytorch result: tensor(-0.0327, grad_fn=<SelectBackward>)
贝塞尔校正
代码中出现,求方差时是否需要贝塞尔校正,即从样本方差到总体方差的校正。
方差公式从,
σ 2 = ∑ i = 0 N − 1 ( x i − m e a n ( x ) ) 2 N \sigma^2 = \frac{\sum\limits_{i=0}^{N-1} (x_i-mean(x))^2}{N} σ2=Ni=0∑N−1(xi−mean(x))2
变成(基于样本的总体方差的无偏估计),
σ 2 = ∑ i = 0 N − 1 ( x i − m e a n ( x ) ) 2 N − 1 \sigma^2 = \frac{\sum\limits_{i=0}^{N-1} (x_i-mean(x))^2}{N-1} σ2=N−1i=0∑N−1(xi−mean(x))2
Reference
-
Ioffe, Sergey, and Christian Szegedy. “Batch normalization: Accelerating deep network training by reducing internal covariate shift.” arXiv preprint arXiv:1502.03167 (2015). ↩︎ ↩︎
-
Wu, Yuxin, and Kaiming He. “Group normalization.” Proceedings of the European Conference on Computer Vision (ECCV). 2018. ↩︎
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134016.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
