大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Motivation
题目中的Internal Covariate Shift指的是在训练过程中各层输入数据的分布随前一层网络参数的变化而变化的现象,这种现象会使训练深度神经网络变得更加复杂,需要耗费更多的时间和资源去调参。为了解决这个问题,文章提出了BN层。
主要内容
本文设计了一种BN层,在每个输入层前加入一个BN层为每层的输入数据做一个改进了的归一化预处理,由于普通的归一化处理会影响网络层所学习的特征,因此BN层中引入了两个可学习的参数对归一化操作进行了改进使得网络可以恢复出原始网络所要学习的特征分布,经实验证明BN层的使用可以有效抑制Internal Covariate Shift现象。
BN层
普通的归一化操作(Z-score标准化)归一化到均值为0方差为1的公式如下,即每个样本减去样本数据的平均值后再除以样本数据的标准差
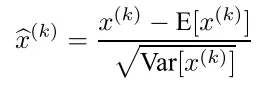

因为这种归一化操作会使得处理过后的数据符合标准的正态分布,所以会影响网络层所学习的特征。在BN层中提出了一种对其进行改进的方法,即对进行Z-score标准化后的数据再进行一次变换,用来恢复原始所要学习的特征分布,公式如下:
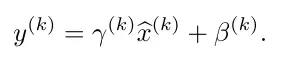
其中γ和β是一对需要学习的参数。
整个BN层的计算流程如下:

文中将BN层放在激活函数之前,在训练结束时每个BN层中的γ和β的参数将不变。
原来的网络前向传导的计算公式如下,其中g为激活函数,z为网络输出。

加入BN层后的网络前向传导的计算公式如下,由于归一化的作用,偏置b可以省去。
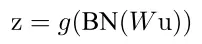
测试及实验
测试时BN层使用的计算公式为
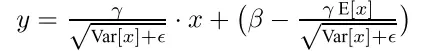
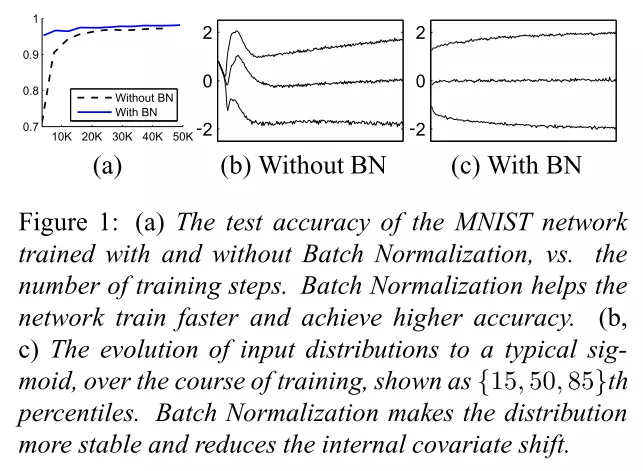
从实验结果可以看出,图a中有BN层的网络更快且准确率更高;图b、c中有BN层的网络分布更加平稳,有效抑制了ICS现象。

文章同时还在图像分类研究中对BN层进行了实验。文中不仅仅给网络加入了BN层,还改变了以下几点:增加学习率;删除Dropout;去掉L2正则项;加快学习率衰减;删除LRN;打乱训练样本。
实验表明BN-x30的效果最好,这是一个使用了上述改变,并且加入了BN层的网络,其初始学习率为0.045.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182053.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
