大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
F1-Score相关概念
- F1分数(F1 Score),是统计学中用来衡量二分类(或多任务二分类)模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0,值越大意味着模型越好。假如有100个样本,其中1个正样本,99个负样本,如果模型的预测只输出0,那么正确率是99%,这时候用正确率来衡量模型的好坏显然是不对的。
| 真实 1 | 真实 0 | |
|---|---|---|
| 预测 1 | True Positive(TP)真阳性 | False Positive(FP)假阳性 |
| 预测 0 | False Negative(FN)假阴性 | True Negative(TN)真阴性 |
- 查准率(precision),指的是预测值为1且真实值也为1的样本在预测值为1的所有样本中所占的比例。以西瓜问题为例,算法挑出来的西瓜中有多少比例是好西瓜。
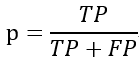

- 召回率(recall),也叫查全率,指的是预测值为1且真实值也为1的样本在真实值为1的所有样本中所占的比例。所有的好西瓜中有多少比例被算法挑了出来。
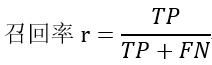
- F1分数(F1-Score),又称为平衡F分数(BalancedScore),它被定义为精确率和召回率的调和平均数。
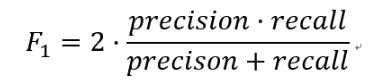
更一般的,我们定义Fβ分数为:
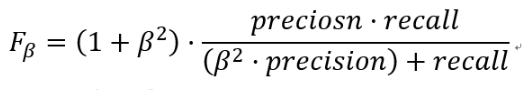
除了F1分数之外,F0.5分数和F2分数,在统计学中也得到了大量应用,其中,F2分数中,召回率的权重高于精确率,而F0.5分数中,精确率的权重高于召回率。
Macro-F1和Micro-F1
- Macro-F1和Micro-F1是相对于多标签分类而言的。
- Micro-F1,计算出所有类别总的Precision和Recall,然后计算F1。
- Macro-F1,计算出每一个类的Precison和Recall后计算F1,最后将F1平均。
tensorflow实现Macro-F1
import tensorflow as tf
def f1(y_hat, y_true, model='multi'):
''' 输入张量y_hat是输出层经过sigmoid激活的张量 y_true是label{0,1}的集和 model指的是如果是多任务分类,single会返回每个分类的f1分数,multi会返回所有类的平均f1分数(Marco-F1) 如果只是单个二分类任务,则可以忽略model '''
epsilon = 1e-7
y_hat = tf.round(y_hat)#将经过sigmoid激活的张量四舍五入变为0,1输出
tp = tf.reduce_sum(tf.cast(y_hat*y_true, 'float'), axis=0)
#tn = tf.sum(tf.cast((1-y_hat)*(1-y_true), 'float'), axis=0)
fp = tf.reduce_sum(tf.cast(y_hat*(1-y_true), 'float'), axis=0)
fn = tf.reduce_sum(tf.cast((1-y_hat)*y_true, 'float'), axis=0)
p = tp/(tp+fp+epsilon)#epsilon的意义在于防止分母为0,否则当分母为0时python会报错
r = tp/(tp+fn+epsilon)
f1 = 2*p*r/(p+r+epsilon)
f1 = tf.where(tf.is_nan(f1), tf.zeros_like(f1), f1)
if model == 'single':
return f1
if model == 'multi':
return tf.reduce_mean(f1)
测试
- 测试变量是多任务分类的输出
import tensorflow as tf
y_true = tf.constant([[1,1,0,0,1], [1,0,1,1,0], [0,1,1,0,0]])
y_hat = tf.constant([[0,1,1,1,1], [1,0,0,1,1], [1,0,1,0,0]])
with tf.Session() as sess:
f1 = f1(y_hat, y_true)
print('F1 score:', sess.run(f1))
F1 score: 0.5999999
numpy实现Macro-F1
(2019.1.12更新)
import numpy as np
def f1(y_hat, y_true, THRESHOLD=0.5):
''' y_hat是未经过sigmoid函数激活的 输出的f1为Marco-F1 '''
epsilon = 1e-7
y_hat = y_hat>THRESHOLD
y_hat = np.int8(y_hat)
tp = np.sum(y_hat*y_true, axis=0)
fp = np.sum(y_hat*(1-y_true), axis=0)
fn = np.sum((1-y_hat)*y_true, axis=0)
p = tp/(tp+fp+epsilon)#epsilon的意义在于防止分母为0,否则当分母为0时python会报错
r = tp/(tp+fn+epsilon)
f1 = 2*p*r/(p+r+epsilon)
f1 = np.where(np.isnan(f1), np.zeros_like(f1), f1)
return np.mean(f1)
参考资料
[1] https://baike.baidu.com/item/F1%E5%88%86%E6%95%B0/13864979?fr=aladdin
[2] https://www.kaggle.com/guglielmocamporese/macro-f1-score-keras
[3] 分类问题的几个评价指标(Precision、Recall、F1-Score、Micro-F1、Macro-F1)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181930.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
