大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
一、unittest测试框架
- unittest 是python 的单元测试框架, unittest 单元测试提供了创建测试用例,测试套件以及批量执行的方案。作为单元测试的框架, unittest 也是可以对程序最小模块的一种敏捷化的测试。
- unittest 和 Junit 都是单元测试?区别在于: unittest 是基于功能测试的单元测试,是基于 UI 界面的功能性测试,而 Junit 是白盒单元测试框架。
- 解决了单个脚本重复的操作(导包,获取浏览器驱动,关闭浏览器)。
1、测试固件
1.1 setUp()
- 在执行测试用例脚本之前进行初始化环境的方法。
1.2 tearDown()
- 测试用例执行后,进行清理环境工作。
2、unittest 基本使用
- 测试用例的命名: test_ 。
from selenium import webdriver
import time
import unittest
class TestUnit1(unittest.TestCase):
# 获取浏览器的驱动
def setUp(self):
# 1、self 就是类的引用/实例
# 2、全局变量的定义:self.变量名
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.url = "https://www.baidu.com/"
self.driver.get(self.url)
time.sleep(3)
# 在百度中搜索信息
# 测试用例的命名: test_
def test_search1(self):
self.driver.find_element_by_id("kw").send_keys("顾一野")
self.driver.find_element_by_id("su").click()
time.sleep(6)
def test_search2(self):
self.driver.find_element_by_id("kw").send_keys("account")
self.driver.find_element_by_id("su").click()
time.sleep(6)
# 关闭浏览器
def tearDowm(self):
self.driver.quit()
# 一个入口
if __name__ == "__main__":
unittest.main()
3、测试套件(suit)
- 把不同文件下的测试用例组织起来形成的测试用例组。
- 把需要一次性执行的测试用例,放在一个套件中,就可以一次性运行。
import unittest
from Test import testbaidu1
from Test import testbaidu2
def creatSuit():
# 1、要把不同测试脚本的类中的需要执行的方法放在一个测试套件中
# suit = unittest.TestSuite()
# suit.addTest(testbaidu1.Baidu1("test_hao"))
# suit.addTest(testbaidu2.Baidu2("test_hao"))
# suit.addTest(testbaidu2.Baidu2("test_baidusearch"))
# return suit
# 2、如果需要把一个测试脚本中年所有的测试用例都添加到suit中,怎么做?
# 第一种※:makeSuit
# suit = unittest.TestSuite()
# suit.addTest(unittest.makeSuite(testbaidu1.Baidu1))
# suit.addTest(unittest.makeSuite(testbaidu2.Baidu2))
# return suit
# 第二种:TestLoader
# suit1 = unittest.TestLoader().loadTestsFromTestCase(testbaidu1.Baidu1)
# suit2 = unittest.TestLoader().loadTestsFromTestCase(testbaidu2.Baidu2)
# suit = unittest.TestSuite([suit1, suit2])
# return suit
# 3、可以把一个文件夹下面所有的测试脚本中的测试用例放入测试套件
discover = unittest.defaultTestLoader.discover("../Test", pattern="testbaidu*.py", top_level_dir=None)
return discover
if __name__ == "__main__":
suit = creatSuit()
# verbersity= 0 测试用例成功多少,失败多少, 1 会标注哪个成功/失败, 2 会标注
runner = unittest.TextTestRunner()
runner.run(suit)
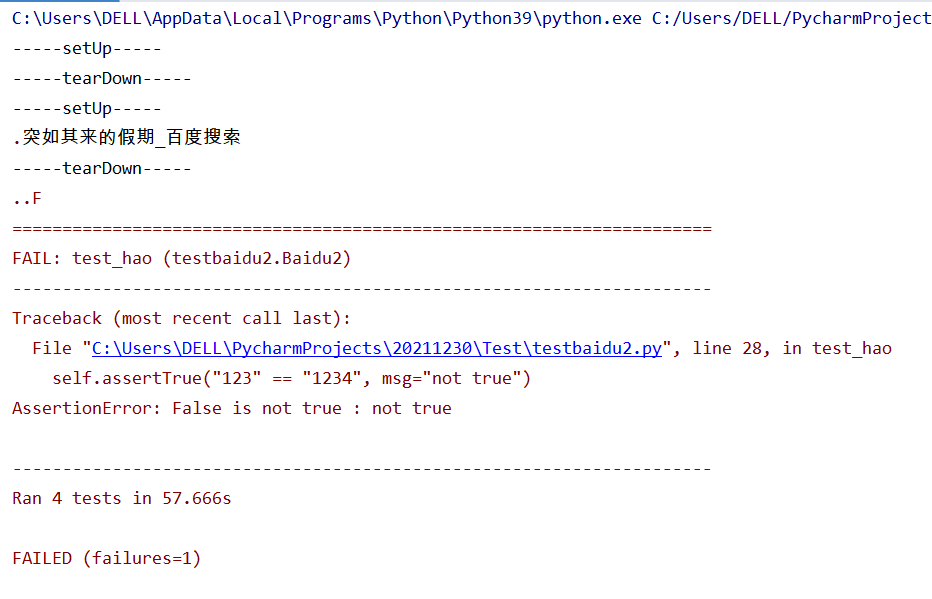

3.1 测试用例执行顺序
- 按照test_后面的名称排序,0 ~ 9, A ~ Z,a ~ z。如果第一个字母相同,就看第二个字母,依次执行。
3.2 忽略测试用例的执行
@unittest.skip("skipping")
4、断言
- 在自动化脚本中来判断实际结果和预期结果是否一致情况。
- 就百度为例,如何判断查询成功?网页标题是搜索信息,或者页面中出现某个元素。
- assertEqual(预期结果,实际结果,msg = “实际结果于预期结果不一致时输出的内容”)。

def test_hbaidu(self):
driver = self.driver
url = self.url
driver.get(url)
# self.assertEqual("突如其来的假期_百度搜索", driver.title, msg="实际结果和预期结果不一致" )
self.assertTrue("百度一下,你就知道" == driver.title, msg="不一致!!!")
driver.find_element_by_id("kw").send_keys("突如其来的假期")
driver.find_element_by_id("su").submit()
time.sleep(5)
print(driver.title)
# self.assertEqual(driver.title, "突如其来的假期_百度搜索", msg="实际结果和预期结果不一致" )
time.sleep(6)
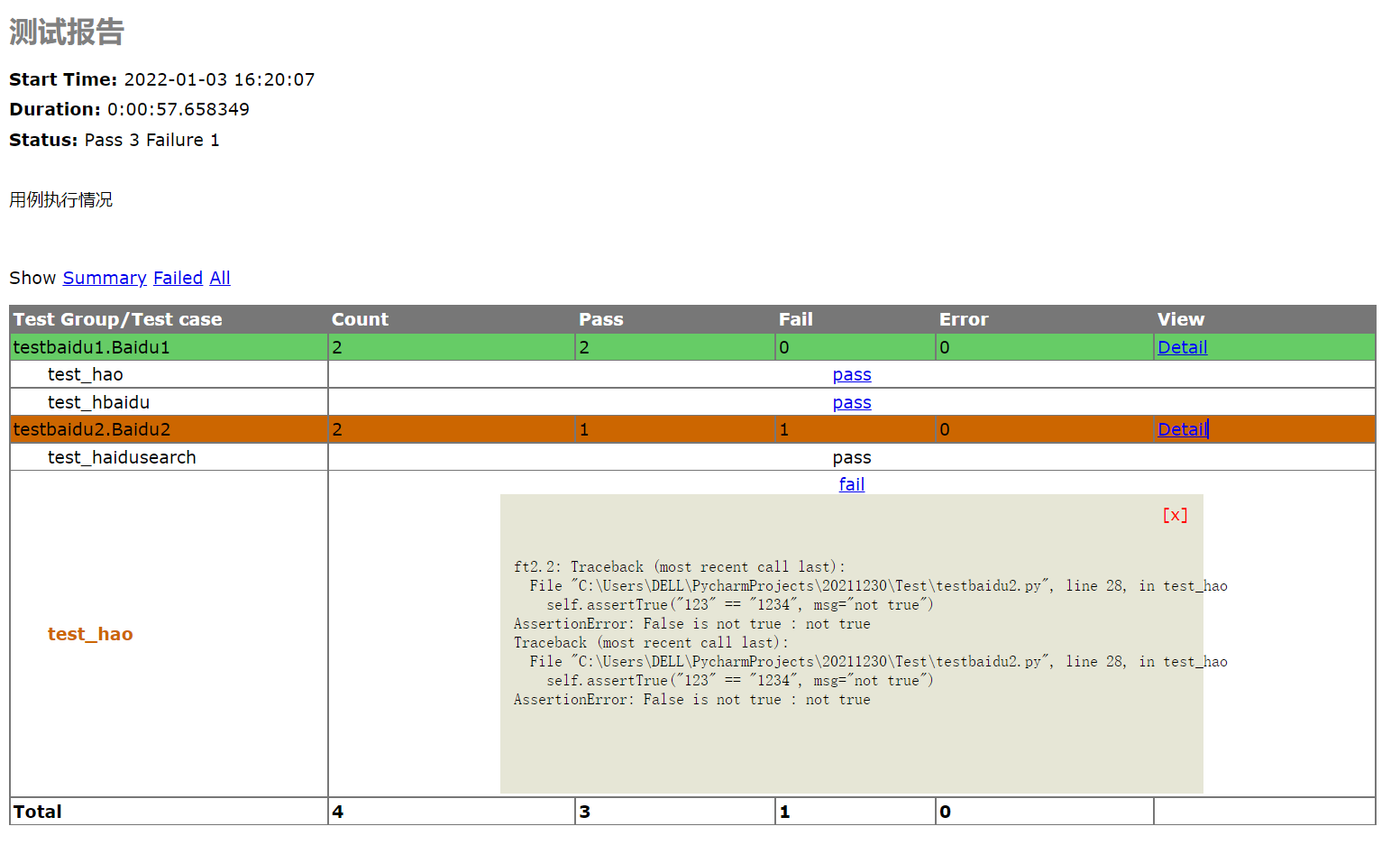
5、HTML 报告生成
- 在测试用例较多时,就需要统计测试用例的执行结果。
- HTML 报告和错误截图都是用来分析测试用例批量执行后的结果的,错误截图可以帮助我们更清晰的看到错误具体出现的页面以及错误状况。
5.1 测试报告
import HTMLTestRunner
import os
import sys
import time
import unittest
def createsuite():
discovers = unittest.defaultTestLoader.discover("../Test", pattern="testbaidu*.py", top_level_dir=None)
print(discovers)
return discovers
if __name__=="__main__":
# 文件夹要创建地址,脚本所在的目录,
curpath = sys.path[0]
# c 盘下所有的路径都被打开,相当于一个数组
print(sys.path)
# 只是需要第一个
print(sys.path[0])
# 1,创建文件夹,存放 HTML 报告
if not os.path.exists(curpath+'/resultreport'):
os.makedirs(curpath+'/resultreport')
# 2,文件夹的命名:时间 时分秒,名称绝对不会重复 time.time() 获取时间戳,local转换为当地时间。
# time.strftime() 把本地时间以某一种特定格式展示。
now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time()))
print(now)
print(time.time())
print(time.localtime(time.time()))
# 文件名
filename = curpath + '/resultreport/'+ now + 'resultreport.html'
# 打开文件,编写内容
with open(filename, 'wb') as fp:
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u"测试报告",
description=u"用例执行情况", verbosity=2)
suite = createsuite()
runner.run(suite)
5.2 异常捕捉与错误截图
- BUG 的要素:标题、版本号、测试环境、测试步骤(测试数据)、预期结果、实际结果、附件(错误日志、错误截图)
- BUG 复现:让 BUG 再次出现,使开发人员能更快的定位到 BUG。
- 可以捕捉到错误,并且把错误截图保存,给我们错误定位带来方便。
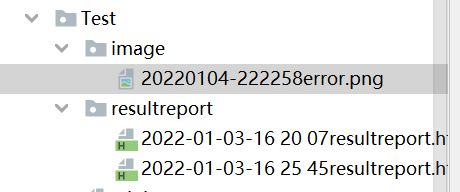
5.2.1 错误截图:get_screenshot_as_file()
def save_errorImage(self, driver,fileName):
# "./" 表示当前路径
if not os.path.exists("./image"):
os.makedirs("./image")
# 错误截图的名称要不一样
now = time.strftime("%Y%m%d-%H%M%S", time.localtime(time.time()))
driver.get_screenshot_as_file("./image/" + now + fileName)
5.2.2 异常捕捉
try:
self.assertEqual("肖战_百度搜索", self.driver.title, msg="和预期结果不一致")
except:
self.save_errorImage(self.driver, "error.png")
5.2.3 整体代码
from selenium import webdriver
import time
import unittest
import os
class TestUnit1(unittest.TestCase):
# 获取浏览器的驱动
def setUp(self):
# 1、self 就是类的引用/实例
# 2、全局变量的定义:self.变量名
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.url = "https://www.baidu.com/"
self.driver.get(self.url)
time.sleep(3)
# 在百度中搜索信息
# 测试用例的命名: test_
def test_search1(self):
self.driver.find_element_by_id("kw").send_keys("顾一野")
self.driver.find_element_by_id("su").click()
time.sleep(6)
# 在百度中搜索英文
def test_search2(self):
self.driver.find_element_by_id("kw").send_keys("Lisa")
self.driver.find_element_by_id("su").click()
time.sleep(6)
# 异常捕捉 再传参数时,没有传 self,实例也可以不用传。 在TestCase类下,只有test_ 才执行,其他的只有被调用才执行。
try:
self.assertEqual("肖战_百度搜索", self.driver.title, msg="和预期结果不一致")
except:
self.save_errorImage(self.driver, "error.png")
def save_errorImage(self, driver,fileName):
# "./" 表示当前路径
if not os.path.exists("./image"):
os.makedirs("./image")
# 错误截图的名称要不一样
now = time.strftime("%Y%m%d-%H%M%S", time.localtime(time.time()))
driver.get_screenshot_as_file("./image/" + now + fileName)
# 关闭浏览器
def tearDowm(self):
self.driver.quit()
# 一个入口
if __name__ == "__main__":
unittest.main()
二、数据驱动
- 例如一个搜索框,如何进行功能测试?
例如在新闻方面,在输入人名(中文。英文)等等,看是否搜索出对应信息。等等信息。 - 自动化测试用例:
- 1、定位输入框 “kw” ,在输入框中输入内容。
- 2、定位百度一下按钮 “su”,点击按钮。
- 3、判断搜索内容。
- 上述方法太过冗杂,可以使用数据驱动,一次性完成需要多次执行的测试用例。
1、ddt 安装
- 1、查看是否安装 ddt,在 cmd 中输入 pip show ddt 出现版本号就说明安装成功。
- 2、没有安装,在 cmd 中输入 pip install ddt 安装。
2、ddt 使用
- 参考文档:http://ddt.readthedocs.io/en/latest/
- 1、导入from ddt import ddt, unpack, data, file_data 和 import sys, csv
- 2、在类前面一定要加上 @ddt
from selenium import webdriver
import time
import unittest
from ddt import ddt, unpack, data, file_data
import sys, csv, os
# 如何读取 TXT 文件中的数据形成数组
def getTxt(file_name):
rows = []
path = sys.path[0]
with open(path + "/" + file_name, 'rt') as f:
readers = csv.reader(f, delimiter=",", quotechar="|")
next(readers, None)
for row in readers:
temprows=[]
for i in row:
temprows.append(i)
rows.append(temprows)
print(rows)
return rows
@ddt
class Search(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.url = "https://www.baidu.com/"
self.driver.maximize_window()
self.driver.get(self.url)
time.sleep(6)
@unittest.skip("skipping")
# 1、一次性传一个参数
@data("肖战", "Lisa", "顾一野", "党章")
def test_find1(self, value):
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(value)
self.driver.find_element_by_id("su").click()
time.sleep(5)
@unittest.skip("skipping")
# 2、一次性传两个参数 u:utf-8,防止中文乱码 需要 unpack 来一一对应参数
@data(['Lisa', u"Lisa_百度搜索"], [u'肖战', u"顾一野_百度搜索"])
@unpack
def test_find2(self, value, expected_value):
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(value)
self.driver.find_element_by_id("su").click()
time.sleep(6)
try:
self.assertEqual(expected_value, self.driver.title, msg="与预期结果不一致")
except:
self.save_errorImage(self.driver, "error.png")
time.sleep(5)
@unittest.skip("skipping")
# 3、使用 json 文件(一次传一个数据) ,测试数据在文件里,整洁、保存多
@file_data('test_baidu_data.json')
def test_find3(self, value):
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(value)
self.driver.find_element_by_id("su").click()
time.sleep(5)
# 4、传入一个 txt 文件(可以传多组数据)
@data(*getTxt('test_baidu_data.txt'))
@unpack
def test_find4(self, value, expected_value):
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(value)
self.driver.find_element_by_id("su").click()
time.sleep(5)
# 断言
self.assertEqual(expected_value, self.driver.title, msg="与预期结果不一致")
print(expected_value)
print(self.driver.title)
time.sleep(5)
def save_errorImage(self, driver, fileName):
if not os.path.exists("./image"):
os.makedirs("./image")
now = time.strftime("%Y%m%d-%H%M%S",time.localtime(time.time()))
driver.get_screenshot_as_file("./image/" + now + "-"+ fileName)
# 关闭浏览器
def tearDown(self):
self.driver.quit()
# 一个入口
if __name__ == "__main__":
unittest.main()
test_baidu_data.txt
data
周迅, 周迅_百度搜索
肖战, 肖战_百度搜索
test_baidu_data.json
[
"jolin",
"林俊杰"
]
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181842.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
