大家好,又见面了,我是你们的朋友全栈君。
内容来自OpenCV-Python Tutorials 自己翻译整理
目标:
- 了解光流的概念,使用lucas-kanade估算方法
- 使用cv2.calcOpticalFlowPyrLK() 方法来追踪视频中的特征点
光流:
光流的概念是指在连续的两帧图像当中,由于图像中的物体移动或者摄像头的移动而使得图像中的目标的运动叫做光流。(说简单点,考虑摄像头不会动的情况,就是一个视频当中有一个运动目标,那么这个视频中的相邻两帧中运动的目标就是光流)
光流是个向量场,表示了一个点从第一帧运动到第二帧的移动。
如图:

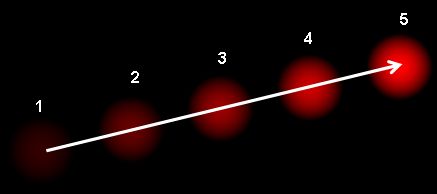
上面的图表示了一个球在连续的5帧图像中的运动。箭头表示了它的位移向量。
光流有很多应用场景如下:
- 运动恢复结构
- 视频压缩
- 视频防抖动
等等
光流法的工作原理基于如下假设:
1.连续的两帧图像之间,目标的像素亮度不改变。
2.相邻的像素之间有相似的运动。
考虑第一帧的像素 I(x,y,t) I ( x , y , t ) ,表示在时间t时像素 I(x,y) I ( x , y ) 的值。在经过时间 dt d t 后,此像素在下一帧移动了 (dx,dy) ( d x , d y ) 。
因为这些像素是相同的,而且亮度不变,我们可以表示成, I(x,y,t)=I(x+dx,y+dy,t+dt) I ( x , y , t ) = I ( x + d x , y + d y , t + d t ) 。
假设移动很小,使用泰勒公式可以表示成:
H.O.T是高阶无穷小。
由第一个假设和使用泰勒公式展开的式子可以得到:
改写成
这里设:
∂I∂x=fx ∂ I ∂ x = f x
同理y和t
ΔxΔt=u Δ x Δ t = u
ΔyΔt=v Δ y Δ t = v
fxu+fyv+ft=0 f x u + f y v + f t = 0
上面公式就叫做光流方程,其中 fx f x 和 fy f y 分别是图像的梯度, ft f t 是是图像沿着时间的梯度。但是u和v是未知的,我们没办法用一个方程解两个未知数,那么就有了lucas-kanade这个方法来解决这个问题。
Lucas-Kanade算法:
使用第二条假设,就是所有的相邻像素都有相同的移动。LK算法使用了一个3×3的窗口大小。所以,在这个窗口当中有9个像素点满足公式
fxu+fyv+ft=0 f x u + f y v + f t = 0 。将点代入方程,现在的问题就变成了使用9个点求解两个未知量。
解的个数大于未知数的个数,这是个超定方程,使用最小二乘的方法来求解最优值。如下为计算得到的结果。
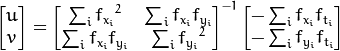
(图中的逆矩阵与Harris角点检测很像,说明角点是适合用来做跟踪的)
想法很简单,给出一些点用来追踪,从而获得点的光流向量。但是有另外一个问题需要解决,目前讨论的运动都是小步长的运动,如果有幅度大的运动出现,本算法就会失效。
使用的解决办法是利用图像金字塔。在金字塔顶端的小尺寸图片当中,大幅度的运动就变成了小幅度的运动。所以使用LK算法,可以得到尺度空间上的光流。
OpenCV中的LK光流:
在OpenCV库提供了一个完整的函数,cv2.calcOpticalFlowPyrLK()。
这里,我们可以创建一个简单的应用,用来追踪视频中的一些店。为了探测这些点,我们使用cv2.goodFeaturesToTrack()来实现。
首先选取第一帧,在第一帧图像中检测Shi-Tomasi角点,然后使用LK算法来迭代的跟踪这些特征点。迭代的方式就是不断向cv2.calcOpticalFlowPyrLK()中传入上一帧图片,其中的特征点以及当前帧的图片。函数会返回当前帧的点,这些点带有状态1或者0,如果在当前帧找到了上一帧中的点,那么这个点的状态就是1,否则就是0。
python的OpenCV 光流函数如下
该函数计算基于图像金字塔的稀疏光流
nextPts,status,err = cv.calcOpticalFlowPyrLK( prevImg, nextImg, prevPts, nextPts[, status[, err[, winSize[, maxLevel[, criteria[, flags[, minEigThreshold]]]]]]])返回值:
- nextPtrs 输出一个二维点的向量,这个向量可以是用来作为光流算法的输入特征点,也是光流算法在当前帧找到特征点的新位置(浮点数)
- status 标志,在当前帧当中发现的特征点标志status==1,否则为0
- err 向量中的每个特征对应的错误率
输入值:
- prevImg 上一帧图片
- nextImg 当前帧图片
- prevPts 上一帧找到的特征点向量
- nextPts 与返回值中的nextPtrs相同
- status 与返回的status相同
- err 与返回的err相同
- winSize 在计算局部连续运动的窗口尺寸(在图像金字塔中)
- maxLevel 图像金字塔层数,0表示不使用金字塔
- criteria 寻找光流迭代终止的条件
- flags 有两个宏,表示两种计算方法,分别是OPTFLOW_USE_INITIAL_FLOW表示使用估计值作为寻找到的初始光流,OPTFLOW_LK_GET_MIN_EIGENVALS表示使用最小特征值作为误差测量
- minEigThreshold 该算法计算光流方程的2×2规范化矩阵的最小特征值,除以窗口中的像素数; 如果此值小于minEigThreshold,则会过滤掉相应的功能并且不会处理该光流,因此它允许删除坏点并获得性能提升。
大致流程就是,首先获取视频或者摄像头的第一帧图像。用goodFeaturesToTrack函数获取初始化的角点,然后开始无限循环获取视频图像帧,将新图像和上一帧图像放入calcOpticalFlowPyrLK函数当中,从而获取新图像的光流。
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
# ShiTomasi 角点检测参数
feature_params = dict( maxCorners = 100,
qualityLevel = 0.3,
minDistance = 7,
blockSize = 7 )
# lucas kanade光流法参数
lk_params = dict( winSize = (15,15),
maxLevel = 2,
criteria = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 创建随机颜色
color = np.random.randint(0,255,(100,3))
# 获取第一帧,找到角点
ret, old_frame = cap.read()
#找到原始灰度图
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
#获取图像中的角点,返回到p0中
p0 = cv2.goodFeaturesToTrack(old_gray, mask = None, **feature_params)
# 创建一个蒙版用来画轨迹
mask = np.zeros_like(old_frame)
while(1):
ret,frame = cap.read()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 选取好的跟踪点
good_new = p1[st==1]
good_old = p0[st==1]
# 画出轨迹
for i,(new,old) in enumerate(zip(good_new,good_old)):
a,b = new.ravel()
c,d = old.ravel()
mask = cv2.line(mask, (a,b),(c,d), color[i].tolist(), 2)
frame = cv2.circle(frame,(a,b),5,color[i].tolist(),-1)
img = cv2.add(frame,mask)
cv2.imshow('frame',img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
# 更新上一帧的图像和追踪点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2)
cv2.destroyAllWindows()
cap.release()源代码是使用一个视频,我这里面改成了摄像头了。
OpenCV中的稠密光流:
LK算法计算的是稀疏的特征点光流,如样例当中计算的是使用 Shi-Tomasi算法得到的特征点。opencv当总提供了查找稠密光流的方法。该方法计算一帧图像当中的所有点。该方法是基于Gunner Farneback提出的一篇论文Two-Frame Motion Estimation Based on Polynomial Expansion。
Farneback稠密光流的主要思想是利用多项式对每个像素的邻域信息进行近似表示,例如考虑二次多项式。
A是对称矩阵,b是向量,c为标量,~表示像素邻域信息的近似
A是通过像素的邻域信息的最小二乘加权拟合得到的,权重系数与邻域的像素大小和位置有关。
如前一帧图像用
f1(x)=xTA1x+bT1x+c1 f 1 ( x ) = x T A 1 x + b 1 T x + c 1
表示,两帧图像唯一用d表示
那么
f2(x)=f1(x−d)=(x−d)TA1(x−d)+bT1(x−d)+c1 f 2 ( x ) = f 1 ( x − d ) = ( x − d ) T A 1 ( x − d ) + b 1 T ( x − d ) + c 1
等价于
xTA1x+(b1−2A1d)Tx+dTA1d−bT1d+c1=xTA2x+bT2x+c2 x T A 1 x + ( b 1 − 2 A 1 d ) T x + d T A 1 d − b 1 T d + c 1 = x T A 2 x + b 2 T x + c 2
因为图像场景中像素的外观信息在帧间运动不变,可以得到对应系数相同,如果
A1 A 1
非奇异,则
再经过对误差的优化和调整结合图像金字塔对图像中的特征点进行跟踪,稠密光流的大致流程就算完事了。
下面样例显示如何找到稠密光流,我们得到的一个两个通道的向量(u,v)。得到的该向量的大小和方向。用不同的颜色编码来使其可视化。
方向与Hue值相关,大小与Value值相关。
使用calcOpticalFlowFarneback函数得到
flow=cv.calcOpticalFlowFarneback(prev, next, flow, pyr_scale, levels, winsize, iterations, poly_n, poly_sigma, flags)返回值是每个像素点的位移
参数
- prev 输入8位单通道图片
- next 下一帧图片,格式与prev相同
- flow 与返回值相同,得到一个CV_32FC2格式的光流图,与prev大小相同
- pyr_scale 构建图像金字塔尺度
- levels 图像金字塔层数
- winsize 窗口尺寸,值越大探测高速运动的物体越容易,但是越模糊,同时对噪声的容错性越强
- iterations 对每层金字塔的迭代次数
- poly_n 每个像素中找到多项式展开的邻域像素的大小。越大越光滑,也越稳定
- poly_sigma 高斯标准差,用来平滑倒数
- flags 光流的方式,有OPTFLOW_USE_INITIAL_FLOW 和OPTFLOW_FARNEBACK_GAUSSIAN 两种
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
#获取第一帧
ret, frame1 = cap.read()
prvs = cv2.cvtColor(frame1,cv2.COLOR_BGR2GRAY)
hsv = np.zeros_like(frame1)
#遍历每一行的第1列
hsv[...,1] = 255
while(1):
ret, frame2 = cap.read()
next = cv2.cvtColor(frame2,cv2.COLOR_BGR2GRAY)
#返回一个两通道的光流向量,实际上是每个点的像素位移值
flow = cv2.calcOpticalFlowFarneback(prvs,next, None, 0.5, 3, 15, 3, 5, 1.2, 0)
#print(flow.shape)
print(flow)
#笛卡尔坐标转换为极坐标,获得极轴和极角
mag, ang = cv2.cartToPolar(flow[...,0], flow[...,1])
hsv[...,0] = ang*180/np.pi/2
hsv[...,2] = cv2.normalize(mag,None,0,255,cv2.NORM_MINMAX)
rgb = cv2.cvtColor(hsv,cv2.COLOR_HSV2BGR)
cv2.imshow('frame2',rgb)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
elif k == ord('s'):
cv2.imwrite('opticalfb.png',frame2)
cv2.imwrite('opticalhsv.png',rgb)
prvs = next
cap.release()
cv2.destroyAllWindows()

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/163515.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
