大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、数据场景
在数据仓库的数据模型设计过程中,经常会遇到下面这种表的设计:
- 有一些表的数据量很大,比如一张用户表,大约10亿条记录,50个字段,这种表,即使使用ORC压缩,单张表的存储也会超过100G,在HDFS使用双备份或者三备份的话就更大一些。
- 表中的部分字段会被update更新操作,如用户联系方式,产品的描述信息,订单的状态等等。
- 需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态。
- 表中的记录变化的比例和频率不是很大,比如,总共有10亿的用户,每天新增和发生变化的有200万左右,变化的比例占的很小。
二、方案实现分析
方案一:只保留一份最新的全量数据
优点:
- 实现简单,每天drop掉前一天的数据,重新抽一份最新的全量
- 节省空间,不用多分区。
缺点:无历史数据。
方案二:每天保留一份最新的全量数据
优点:
- 实现简单,基于方案一,不drop前一天的数据,每天一个分区保存最新全量
- 可以查历史数据
缺点:存储空间占用太大
方案三:使用拉链表
优点:兼顾了历史数据和存储空间,既能获取历史数据也能筛选最新数据。
缺点:在数据量较大且资源有限的情况下对数据的合并耗时且表的设计有一定的要求(分区)
三、分区拉链表实现流程
(1)、拉链表总过程
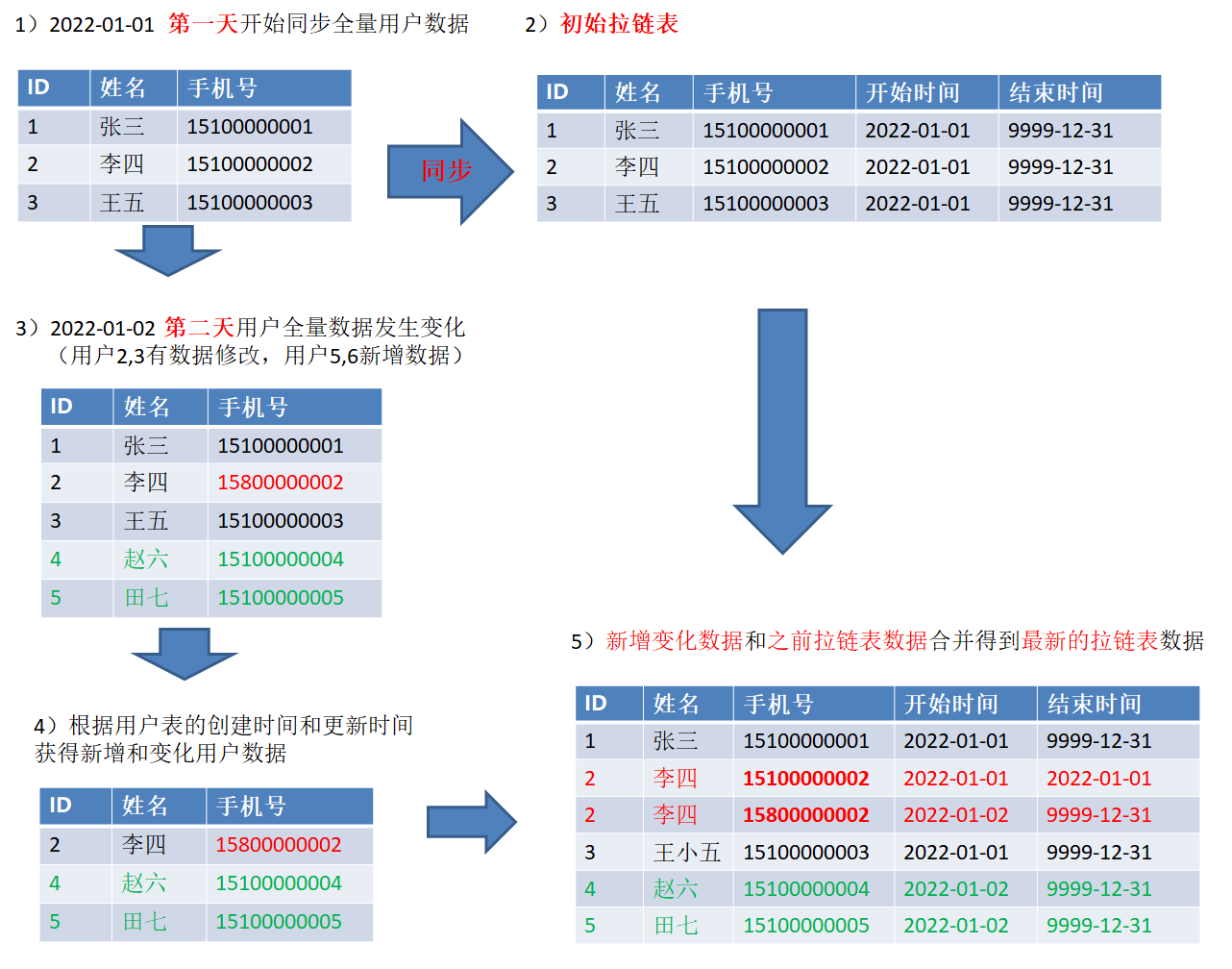

(2)、分区规划

(3)、数据流向
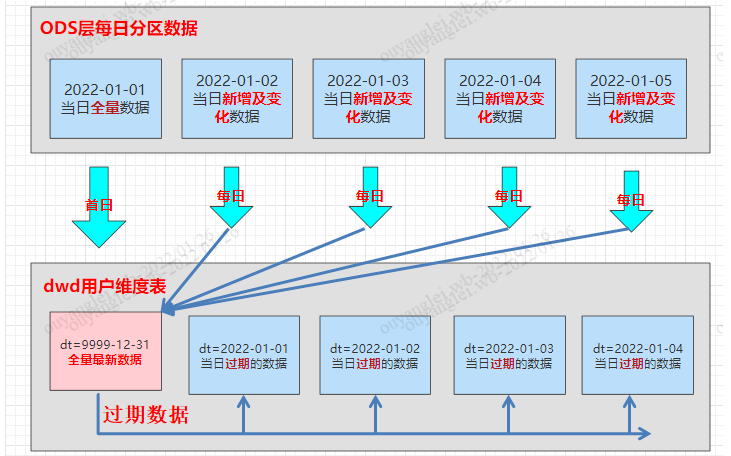
四、分区拉链表sql实现
(1)建表
- ods层 建表 ods_user_info_inc (分区表,每天一个分区,存储的是新增和修改的数据)
drop table if exists ods_user_info_inc;
create external table if not exists ods_user_info_inc(
id string comment '主键',
name string comment '用户名',
phone_num string comment '手机号码',
create_time string comment '创建日期',
operate_time string comment '修改日期'
)
PARTITIONED BY (dt STRING)
ROW FORMAT delimited fields terminated by ','
LOCATION '/tmp/hive_test/ods/ods_user_info_inc/';
- 层建表 dwd_user_info_zip (分区表拉链表,每天一个分区,每天分区存储过期数据,9999-12-31分区存储最新数据)
drop table if exists dim_user_info_zip;
create external table if not exists dim_user_info_zip(
id string comment '主键',
name string comment '用户名',
phone_num string comment '手机号码',
create_time string comment '创建日期',
operate_time string comment '修改日期',
start_time string comment '开始时间',
end_time string comment '结束时间'
)
PARTITIONED BY (dt STRING)
stored as orc
LOCATION '/tmp/hive_test/dim/dim_user_info_zip/'
TBLPROPERTIES ('orc.compress' = 'snappy');
(2)、第一天全量导入数据
- 全部数据都是导入到9999-12-31分区
- 每条数据的开始时间是2022-01-01,结束时间是9999-12-31
insert overwrite table dim_user_info_zip partition (dt='9999-12-31')
select
id ,
name ,
phone_num ,
create_time,
operate_time,
"2022-01-01" as start_time,
"9999-12-31" as end_time
from ods_user_info_inc
where dt='2022-01-01';
(3)每日加载数据
-
加载思路
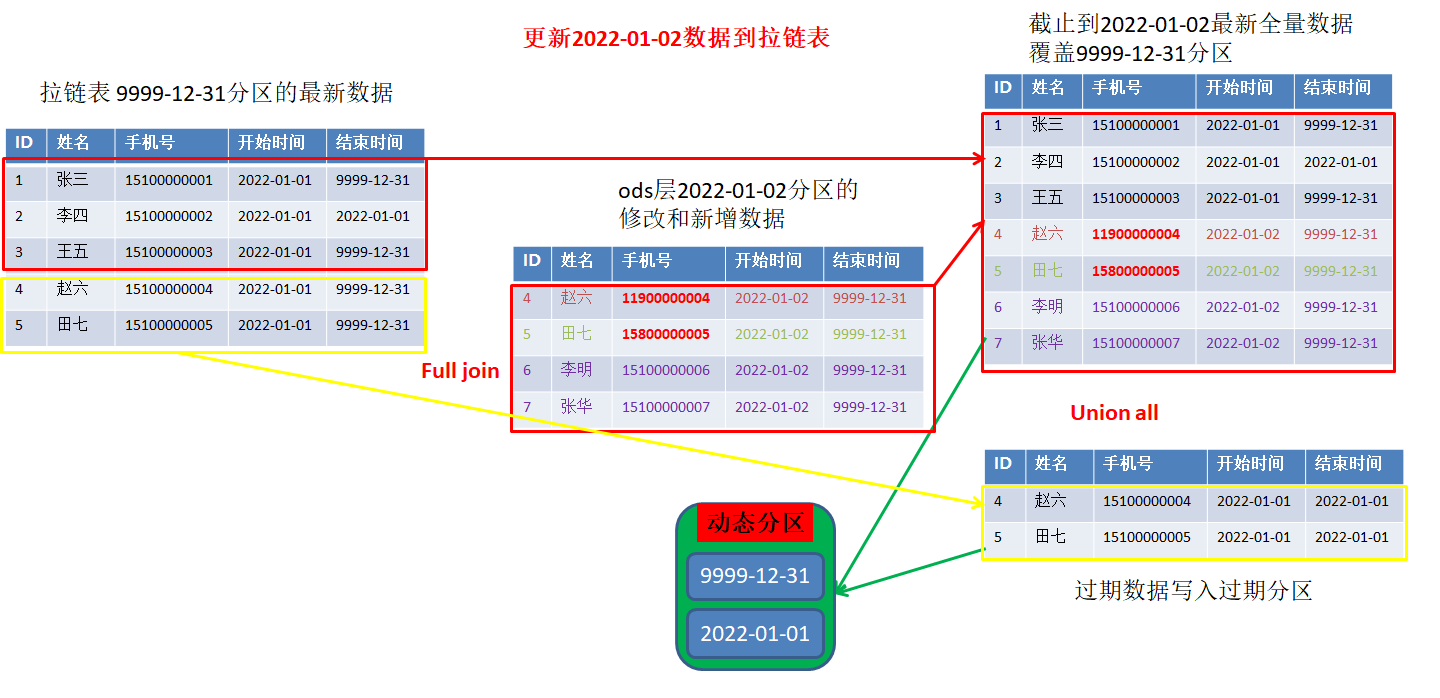
-
最终sql
with tmp as (
select
old.id as old_id,
old.name as old_name,
old.phone_num as phone_num ,
old.create_time as old_create_time,
old.operate_time as old_operate_time,
old.start_time as old_start_time,
old.end_time as old_end_time,
new.id as new_id,
new.name as new_name,
new.phone_num as phone_num ,
new.create_time as new_create_time,
new.operate_time as new_operate_time,
new.start_time as new_start_time,
new.end_time as new_end_time
from
(select
id ,
name ,
phone_num ,
create_time,
operate_time,
start_time,
end_time
from dim_user_info_zip where dt='9999-12-31') old
full join
(select
id ,
name ,
phone_num ,
create_time,
operate_time,
'2022-01-02' as start_time,
'9999-12-31' as end_time
from ods_user_info_inc where dt='2022-01-02') new
on old.id = new.id
)
insert overwrite table dim_user_info_zip partition (dt)
select
if(new_id is not null,new_id,old_id),
if(new_id is not null,new_name,old_name),
if(new_id is not null,new_name,phone_num ),
if(new_id is not null,new_create_time,old_create_time),
if(new_id is not null,new_operate_time,old_operate_time),
if(new_id is not null,new_start_time,old_start_time),
if(new_id is not null,new_end_time,old_end_time),
if(new_id is not null,new_end_time,old_end_time) dt
from tmp
union all
select
old_id,
old_name,
old.phone_num ,
old_create_time,
old_operate_time,
old_start_time,
cast(date_sub('2022-01-02',1) as string) as old_end_time,
cast(date_sub('2022-01-02',1) as string) as dt
from tmp
where old_id is not null and new_id is not null;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181340.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
