大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
拉链表
一丶什么是拉链表
拉链表是一种数据模型,主要是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。拉链表可以避免按每一天存储所有记录造成的海量存储问题,同时也是处理缓慢变化数据的一种常见方式。
百度百科的解释:拉链表是维护历史状态,以及最新状态数据的一种表,拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录,通过拉链表可以很方便的还原出拉链时点的客户记录。
二丶拉链表的产生背景
在数据仓库的数据模型设计过程中,经常会遇到这样的需求:
- 数据量比较大
- 表中的部分字段会被update,如用户的地址,产品的描述信息,订单的状态等等;
- 需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态,比如,查看某一个用户在过去某一段时间内,更新过几次等等;
- 变化的比例和频率不是很大,比如,总共有1000万的会员,每天新增和发生变化的有10万左右;
- 如果对这边表每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费;
对于这种表有几种方案可选:
方案一:每天只留最新的一份,比如我们每天用Sqoop抽取最新的一份全量数据到Hive中。
方案二:每天保留一份全量的切片数据。
方案三: 每天保存一份增量数据
方案四:使用拉链表。
以上方案对比
方案一
这种方案就不用多说了,实现起来很简单,每天drop掉前一天的数据,重新抽一份最新的。
优点很明显,节省空间,一些普通的使用也很方便,不用在选择表的时候加一个时间分区什么的。
缺点同样明显,没有历史数据,先翻翻旧账只能通过其它方式,比如从流水表里面抽。
方案二
每天一份全量的切片是一种比较稳妥的方案,而且历史数据也在。
缺点就是存储空间占用量太大太大了,如果对这边表每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费,这点我感触还是很深的…
当然我们也可以做一些取舍,比如只保留近一个月的数据?但是,需求是无耻的,数据的生命周期不是我们能完全左右的。
方案三
每天都保存增量数据,这种方案相比较方案一二的话,数据量变少了,也记录了每条数据的变化.但是数据量还是比拉链表多,同时它要求某天的历史数据查询效率比较低,比较繁琐.比如你要求2021年10月01号的在职人数,你就需要判断入职日期小于等于10月01号的,用lead函数获取下条数据,判断下条数据的离职日期是否大于2021年10月01号.
拉链表
拉链表在使用上基本兼顾了我们的需求。
首先它在空间上做了一个取舍,虽说不像方案一那样占用量那么小,但是它每日的增量可能只有方案二的千分之一甚至是万分之一。
其实它能满足方案二所能满足的需求,既能获取最新的数据,也能添加筛选条件也获取历史的数据。
所以我们还是很有必要来使用拉链表的。
三丶在Hive中实现拉链表
在现在的大数据场景下,大部分的公司都会选择以Hdfs和Hive为主的数据仓库架构。目前的Hdfs版本来讲,其文件系统中的文件是不能做改变的,也就是说Hive的表智能进行删除和添加操作,而不能进行update。基于这个前提,我们来实现拉链表。
还是以上面的用户表为例,我们要实现用户的拉链表。在实现它之前,我们需要先确定一下我们有哪些数据源可以用。
- 我们需要一张ODS层的用户全量表。至少需要用它来初始化。
- 每日的用户更新表。
而且我们要确定拉链表的时间粒度,比如说拉链表每天只取一个状态,也就是说如果一天有3个状态变更,我们只取最后一个状态,这种天粒度的表其实已经能解决大部分的问题了。
另外,补充一下每日的用户更新表该怎么获取,据笔者的经验,有3种方式拿到或者间接拿到每日的用户增量,因为它比较重要,所以详细说明:
- 我们可以监听Mysql数据的变化,比如说用Canal,最后合并每日的变化,获取到最后的一个状态。
- 假设我们每天都会获得一份切片数据,我们可以通过取两天切片数据的不同来作为每日更新表,这种情况下我们可以对所有的字段先进行concat,再取md5,这样就ok了。
- 流水表!有每日的变更流水表。
拉链表制作过程图解
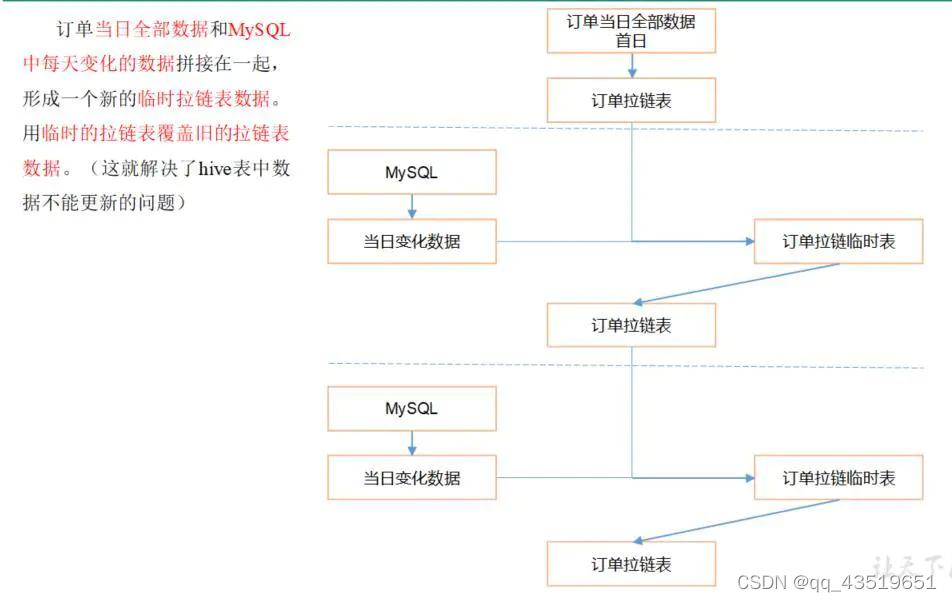

四丶实例讲解
需求:现在需要把一张每天存有全量数据的表制作成拉链表
步骤:
1.先把已有的全量分区表改造为拉链表①
--创建岗位状态表,在第一次执行脚本执行,这段sql,先在已有的数据上做拉链表,之后用拉链表去和每日新增及变化的数据进行合并
--注意:如果任务执行失败,那么可以重新执行这段sql制作拉链表,结束时间改为最新时间就好了
drop table if exists tmp.ems_base;
create table tmp.ems_base as
select
t3.*
,case when t3.hire_date >= t3.date_from and t3.cancel_flag <> 'Y' then '入职'
when t3.hire_date < t3.date_from and t3.cancel_flag <> 'Y' then '调岗'
when t3.cancel_flag = 'Y' then '离职'
else '其它' end as type --给每条数据标上一个状态类型,这里面的判断你们不用理解,只需要知道缓慢变化的维度是这个字段(入职,调岗,离职)三种类型
from
(select
t2.*
,row_number() over(partition by t2.emp_num,t2.date_from,t2.cancel_flag,t2.hire_date order by t2.inc_day) as rn
from
(select
lpad(t1.emp_num ,8,'0') as emp_num --工号(没有8位的用0补齐)
,t1.curr_org_id --当前部门组织id
,t1.org_code --组织编码
,t1.curr_org_name --组织名称
,t1.hire_date --入职日期
,if(t1.date_from < t1.hire_date,t1.hire_date,t1.date_from) as date_from --调入当前网络时间
,if(t1.cancel_flag = 'Y',t1.cancel_date,'00000000') as cancel_date --离职日期
,t1.cancel_flag --离职标识
,t1.zhrlzlx --离职类型
,t1.inc_day
from
(select
*
from ods.etl_ems --人员全量分区表
where inc_day between 开始时间 and 结束时间
) t1
) t2
)t3
where rn = 1
;
--创建拉链表
drop table if exists ods.ems_zipper;
create table ods.ems_zipper as
select
t1.emp_num --工号
,t1.curr_org_id --当前部门组织id
,t1.org_code --组织编码
,t1.curr_org_name --组织名称
,t1.hire_date --入职日期
,t1.date_from --入网时间
,t1.cancel_date --离职时间
,t1.cancel_flag --离职标识
,t1.type --(入职,调岗,离职)
,t1.zhrlzlx --离职类型
,from_unixtime(unix_timestamp(case when t1.type = '调岗' then t1.date_from
when t1.type = '入职' then t1.hire_date
when t1.type = '离职' then t1.cancel_date --因为这三种状态的时间存储在不同字段当中,所以需要去判断是哪种状态,然后获取哪个时间字段作为开始时间
end
,'yyyyMMdd'),'yyyy-MM-dd') as begin_date --开始日期
,case when lead(t1.type,1,'无') over(partition by t1.emp_num order by t1.inc_day) = '调岗' then date_sub(from_unixtime(unix_timestamp(lead(t1.date_from,1,'99991231') over(partition by t1.emp_num order by t1.inc_day),'yyyyMMdd'),'yyyy-MM-dd'),1)
when lead(t1.type,1,'无') over(partition by t1.emp_num order by t1.inc_day) = '离职' then date_sub(from_unixtime(unix_timestamp(lead(t1.cancel_date,1,'99991231') over(partition by t1.emp_num order by t1.inc_day),'yyyyMMdd'),'yyyy-MM-dd'),1)
when lead(t1.type,1,'无') over(partition by t1.emp_num order by t1.inc_day) = '入职' then date_sub(from_unixtime(unix_timestamp(lead(t1.hire_date,1,'99991231') over(partition by t1.emp_num order by t1.inc_day),'yyyyMMdd'),'yyyy-MM-dd'),1)
else '9999-12-30' end as end_date --结束日期
from tmp.ems_base t1
;
2.通过昨天的全量数据和前天的全量数据比较,获取新增及变化的临时表②
-----创建每日新增及变化的表
drop table if exists tmp.ems_change;
create table tmp.ems_change as
select
lpad(t2.emp_num,8,'0') as emp_num --工号
,t2.curr_org_id --当前部门组织id
,t2.org_code --组织编码
,t2.curr_org_name --组织名称
,t2.hire_date --入职日期
,if(t2.date_from < t2.hire_date,t2.hire_date,t2.date_from) as date_from --调入当前网络时间
,if(t2.cancel_flag = 'Y',t2.cancel_date,'00000000') as cancel_date --离职日期
,t2.cancel_flag --离职标识
,t2.zhrlzlx --离职类型
,case when t2.hire_date >= t2.date_from and t2.cancel_flag <> 'Y' then '入职'
when t2.hire_date < t2.date_from and t2.cancel_flag <> 'Y' then '调岗'
when t2.cancel_flag = 'Y' then '离职'
else '其它' end as type
from
(select
t1.emp_num --工号
,t1.curr_org_id --当前部门组织id
,t1.org_code --组织编码
,t1.curr_org_name --组织名称
,t1.hire_date --入职日期
,t1.date_from --调入当前网络时间
,t1.cancel_date --离职日期
,t1.cancel_flag --离职标识
,t1.zhrlzlx --离职类型
from ods.etl_ems t1
where t1.inc_day = '${v_day_1ago}'
) t2
left join
(select
t4.emp_num --工号
,t4.curr_org_id --当前部门组织id
,t4.org_code --组织名称
,t4.curr_org_name --组织代码
,t4.hire_date --入职日期
,t4.date_from --调入当前网络时间
,t4.cancel_date --离职日期
,t4.cancel_flag --离职标识
,t4.zhrlzlx --离职类型
from ods.etl_ems t4
where t4.inc_day = '${v_day_2ago}'
) t3
on
t2.emp_num = t3.emp_num
--注意用concat时,只要有一个字段为null那么,拼接的结果就是null,所以需要nvl把空值先转换为字符串
where concat(nvl(t2.date_from,''),nvl(t2.hire_date,''),nvl(t2.cancel_flag,'')) <> concat(nvl(t3.date_from,''),nvl(t3.hire_date,''),nvl(t3.cancel_flag,''))
;
3.拉链表和临时表②合并获取临时拉链表,用临时拉链表覆盖拉链表,得到新的拉链表
----拉链表去和每日新增及变化的数据合并
drop table if exists tmp.ems_zipper_tmp;
create table tmp.ems_zipper_tmp as
select
t1.emp_num --工号
,t1.curr_org_id --当前部门组织id
,t1.org_code --组织名称
,t1.curr_org_name --组织代码
,t1.hire_date --入职日期
,t1.date_from --调入当前网络时间
,t1.cancel_date --离职日期
,t1.cancel_flag --离职标识
,t1.zhrlzlx --离职类型
,t1.type
,from_unixtime(unix_timestamp(case when t1.type = '调岗' then t1.date_from
when t1.type = '入职' then t1.hire_date
when t1.type = '离职' then t1.cancel_date
end
,'yyyyMMdd'),'yyyy-MM-dd') as begin_date
,'9999-12-30' as end_date
from tmp.ems_change t1
union all
select
a.emp_num --工号
,a.curr_org_id --当前部门组织id
,a.org_code --组织名称
,a.curr_org_name --组织代码
,a.hire_date --入职日期
,a.date_from --调入当前网络时间
,a.cancel_date --离职日期
,a.cancel_flag --离职标识
,a.zhrlzlx --离职类型
,a.type --(入职,调岗,离职)
,a.begin_date --开始日期
,if(b.emp_num is not null and a.end_date = '9999-12-30',case when b.type = '调岗' then date_sub(from_unixtime(unix_timestamp(b.date_from,'yyyyMMdd'),'yyyy-MM-dd'),1)
when b.type = '离职' then date_sub(from_unixtime(unix_timestamp(b.cancel_date,'yyyyMMdd'),'yyyy-MM-dd'),1)
when b.type = '入职' then date_sub(from_unixtime(unix_timestamp(b.hire_date,'yyyyMMdd'),'yyyy-MM-dd'),1)
else '9999-12-30' end ,a.end_date) as end_date
from ods.ems_zipper a --拉链表
left join tmp.ems_change b --新增及其变化表
on a.emp_num = b.emp_num
;
----用临时拉链表覆盖拉链表
insert overwrite table ods.ems_zipper
select
t1.emp_num
,t1.curr_org_id
,t1.org_code
,t1.curr_org_name
,t1.hire_date --入职日期
,t1.date_from --入网时间
,t1.cancel_date --离职时间
,t1.cancel_flag --离职标识
,t1.type --(入职,调岗,离职)
,t1.zhrlzlx --离职类型
,t1.begin_date
,t1.end_date
from tmp.ems_zipper_tmp t1
;
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181283.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
