大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、基本概念
Kafka™用于构建实时数据流水线和流媒体应用,具有水平可扩展性,容错性,并在数千家公司得到了应用。
流媒体平台(streaming platform)有三个关键功能:
1. 发布和订阅记录流。 在这方面,类似于消息队列或企业消息系统。
2. 以容错方式存储记录流。
3. 实时处理记录流。
Kafka被用于两大类应用程序:
1. 构建可在系统或应用程序之间可靠获取数据的实时流数据流水线;
2. 构建对数据流进行变换或反应的实时流应用程序
重要定义:
1. Kafka以集群方式运行,包含一个或多个服务器上。
2. Kafka以topic形式保存记录。
3. 每条记录由一个键key,一个值value和一个时间戳timestamp组成。
Kafka有4个核心API:
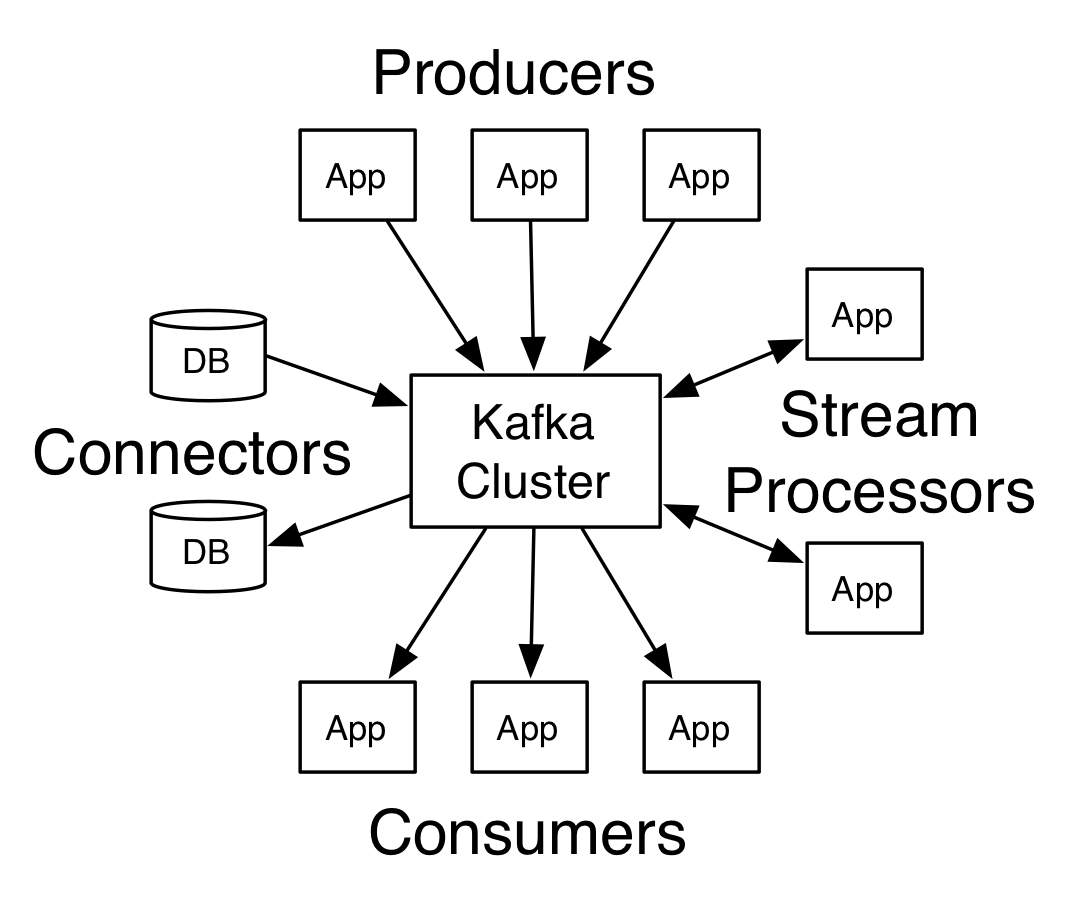
1. Producer API允许应用程序将记录流发布到一个或多个Kafka主题。
2. Consumer API允许应用程序订阅一个或多个主题并处理为其生成的记录流。
3. Streams API允许应用程序充当流处理器,从一个或多个主题消耗输入流,并产生输出流到一个或多个输出主题,有效地将输入流转换为输出流。
4. Connector API允许构建和运行将Kafka主题与现有应用程序或数据系统相连接的可重复使用的生产者或消费者。 例如和关系数据库的连接器可能会捕获表的每个更改。

Kafka中客户端与服务器之间的通信使用TCP协议
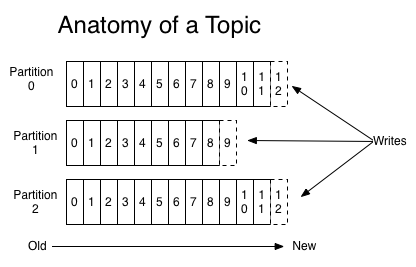
Topics and Logs
Topic是记录的类别或Feed名称。 Kafka的主题总是多用户的; 也就是说,每个主题可以有零个,一个或多个消费者订阅订阅的数据。
对于每个主题,Kafka集群都会维护一个如下所示的分区日志。
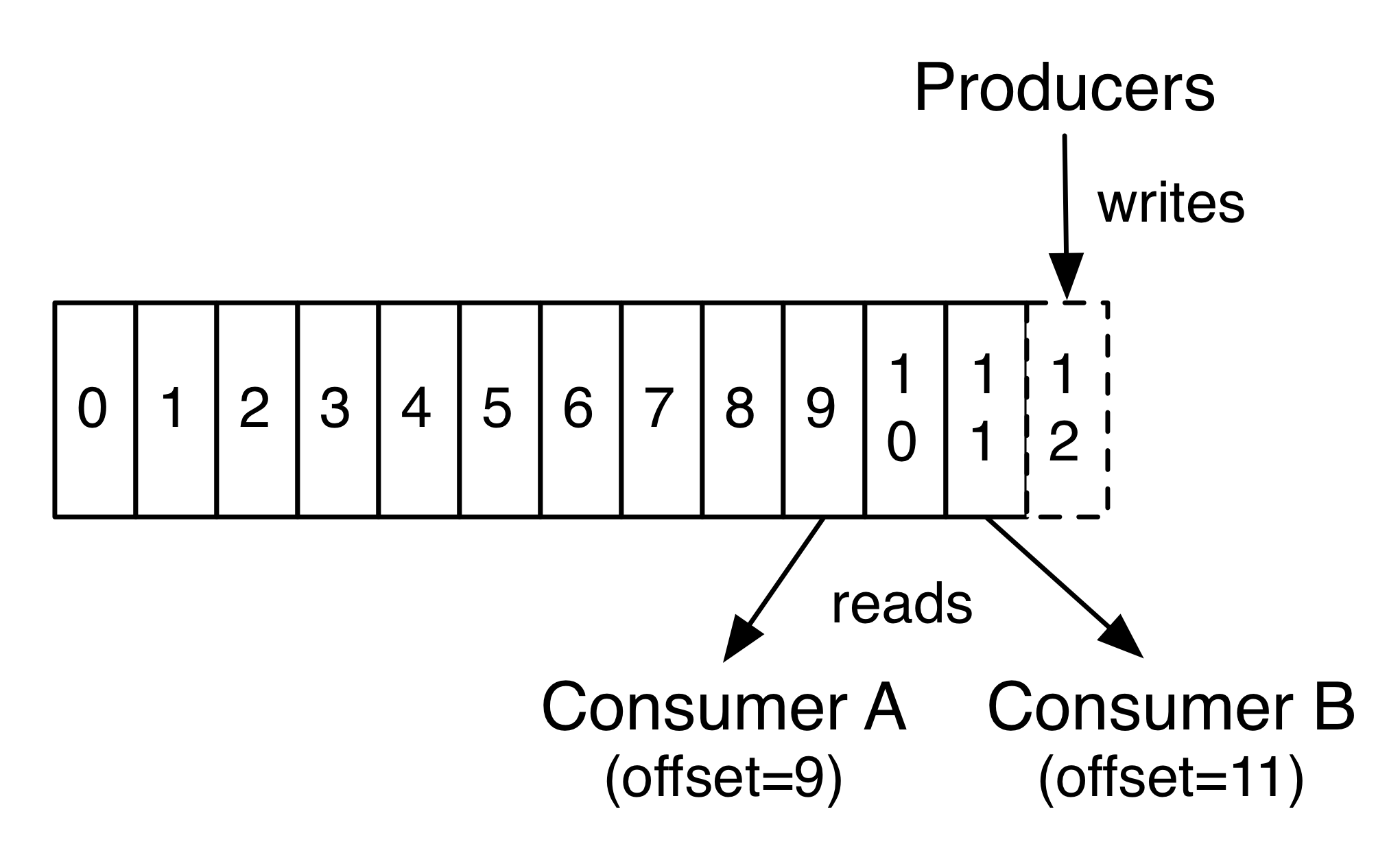
每个分区是一个有序的,不可变的记录序列,不断附加到结构化的提交日志中。 每个分区中的记录都被分配一个顺序的id号,称为唯一标识分区内每个记录的偏移量offset。
Kafka集群保留所有已发布的记录(无论它们是否已被使用 ), 使用可配置的保留期限。 例如,如果保留策略设置为两天,则在发布记录后的两天内,它可以消费,之后它将被丢弃以释放空间。
log的分区有几个目的:
1. 它们允许日志扩展到适合单个服务器的大小。 每个单独的分区必须适合托管它的服务器,但主题可能有很多分区,因此它可以处理任意数量的数据。
2. 一个分区作为并行计算的单位,有利于并行计算
Distribution
日志的分区分布在Kafka集群中的服务器上,每个服务器处理数据并请求共享的分区。 每个分区都跨可配置数量的服务器进行复制,以实现容错。
每个分区有一个服务器充当“leader”,零个或多个服务器充当“followers”。 leader处理分区的所有读取和写入请求,而followers做备份。 如果leader失败,其中一个follower将自动成为新的leader。 每个服务器作为其一些分区的leader,并且其他分支的followers,因此在集群内负载平衡良好。
Producers
生产者将数据发布到他们选择的主题。 生产者负责选择分配哪些记录在主题中哪个分区。 这可以通过循环方式简单地平衡负载,或者可以根据某些语义分区功能(例如基于记录中的某些关键字)来完成。 第二种方式使用地较多!
Consumers
Kafka总结起来就是:
1. Kafka as a Messaging System,与传统的消息队列和企业消息系统的对比
2. Kafka as a Storage System
3. Kafka for Stream Processing
参考文献:
Kafka官网:https://kafka.apache.org/intro.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181247.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
