大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
利用mysql explain来对sql语句进行优化,你需要懂这些关键字各表示的含义,这样优化才有的放矢。
语法格式如下:
EXPLAIN SELECT SQL语法格式说明:
EXPLAIN:分析查询语句的关键字。
SELECT:执行查询语句的关键字。
SQL:查询语句。
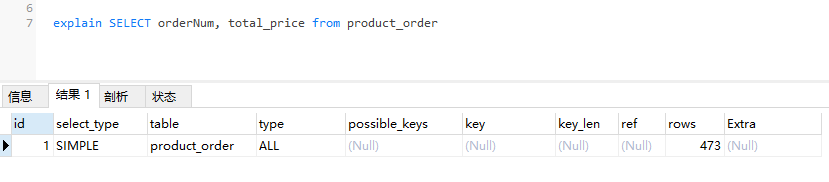

接下来对输出结果进行简单的解释。
(1)id:表示SELECT语句的序列号,有多少个SELECT语句就有多少个序列号。如果当前行的结果数据中引用了其他行的结果数据,则该值为NULL。
(2)select_type:查询类型,表示当前SQL语句是简单查询还是复杂查询。常见取值如下:
SIMPLE:简单查询,不包含任何连接查询和子查询。
PRIMARY:主查询或者包含子查询时最外层的查询语句。
UNION:当前SQL语句是连接查询时,表示连接查询的第二个SELECT语句或者第二个后面的SELECT语句。
DEPENDENT UNION:含义与UNION几乎相同,但是DEPENDENT UNION取决于外层的查询语句。
UNION RESULT:表示连接查询的结果信息。
SUBQUERY:表示子查询中的第一个查询语句。
DEPENDENT SUBQUERY:含义与SUBQUERY几乎相同,但是DEPENDENTSUBQUERY取决于外层的查询语句。
DERIVED:表示FROM子句中的子查询。
MATERIALIZED:表示实例化子查询。
UNCACHEABLE SUBQUERY:表示不缓存子查询的结果数据,重新计算外部查询的每一行数据。
UNCACHEABLE UNION:表示不缓存连接查询的结果数据,每次执行连接查询时都会重新计算数据结果。
(3)table:当前查询(连接查询、子查询)所在的数据表。
(4)partitions:如果当前数据表是分区表,则表示查询结果匹配的分区。
(5)type:当前SQL语句所使用的关联类型或者访问类型,
其取值从最优到最差依次为
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge> unique_subquery > index_subquery > range > index > ALL
system:查询的数据表中只有一行数据,是const类型的特例。
const:数据表中最多只有一行数据符合查询条件,当查询或连接的字段为主键或唯一索引时,则type的取值为const。简单示例如下:
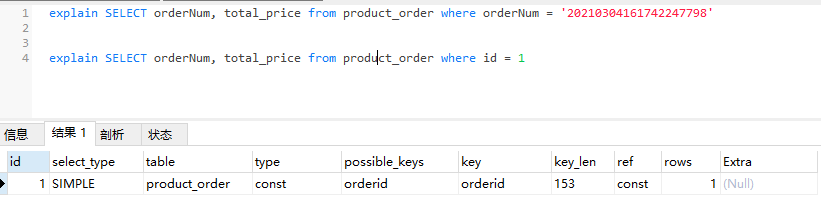

eq_ref:如果查询语句中的连接条件或查询条件使用了主键或者非空唯一索引包含的全部字段,则type的取值为eq_ref,典型的场景为使用“=”操作符比较带索引的列。
ref:当查询语句中的连接条件或者查询条件使用的索引不是主键和非空唯一索引,或者只是一个索引的一部分,则type的取值为ref,典型的场景为使用“=”带索引的列。简单示例如下:
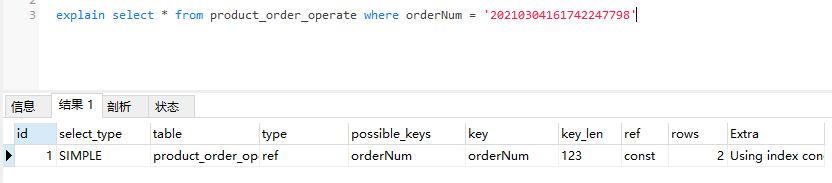
此时,product_order_operate表orderNum字段上添加有普通索引
fulltext:当查询条件使用了全文索引时,type的取值为fulltext。
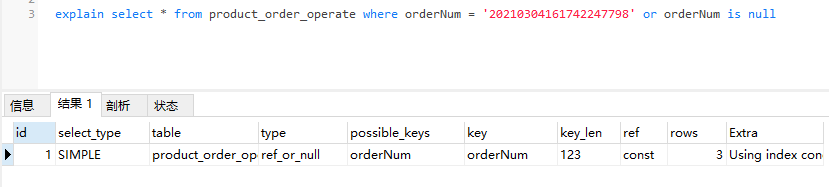
ref_or_null:类似于ref,但是当查询语句的连接条件或者查询条件包含的列有NULL值时,MySQL会进行额外查询,经常被用于解析子查询。简单示例如下:
index_merge:当查询语句使用索引合并优化时,type的取值为index_merge。此时,key列会显示使用到的所有索引,key_len显示使用到的索引的最长键长值。简单示例如下:
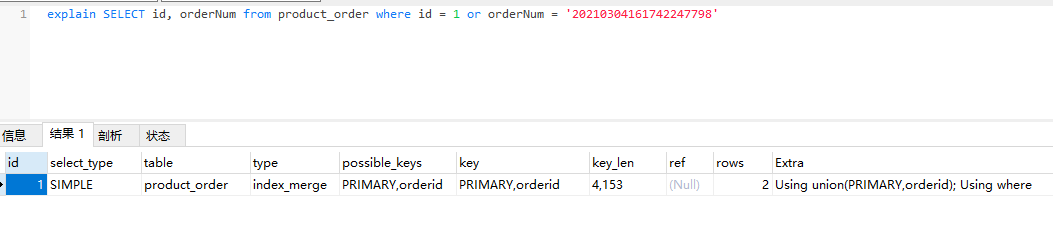
此时,orderNum字段上添加有唯一索引。
unique_subquery:当查询语句的查询条件为IN的语句,并且IN语句中的查询字段为数据表的主键或者非空唯一索引字段时,type的取值为unique_subquery。
index_subquery:与unique_subquery类似,但是IN语句中的查询字段为数据表中的非唯一索引字段。
range:当查询语句的查询条件为某个范围的记录时,type的取值为range。key列会显示使用的索引,key_len显示使用索引的最长键长值。典型的场景为使用=、<>、>、>=、<、<=、IS [NOT] NULL、<=>、BETWEEN AND或者IN操作符时,用常量比较关键字的列。简单示例如下:
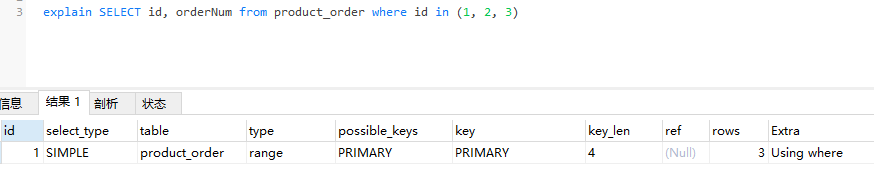
index:当查询语句中的查询条件使用的是覆盖索引,也就是说查询条件中的字段包含索引中的全部字段,并且按照索引中字段的顺序进行条件匹配,此时只需要扫描索引树即可。另外,当查询语句的条件只是按照索引顺序查找数据行时,也只需要扫描索引树即可。简单示例如下:

ALL:每次进行连接查询时,都会进行完整的表扫描。查询性能最差,需要添加索引来避免此类型的查询。简单示例如下:

(6)possible_keys:执行查询语句时可能用到的索引,但是在实际查询中未必会用到。当此列为NULL时,说明没有可使用的索引,此时可以通过建立索引来提高查询的性能。
(7)key:执行查询语句时MySQL实际会使用到的索引。如果MySQL实际没有使用索引,则此列为NULL。
(8)key_len:执行查询语句时实际用到的索引按照字节计算的长度值,可以通过此字段计算MySQL实际上使用了复合索引中的多少字段。如果key列值为NULL,则key_len列值也为NULL。
(9)ref:数据表中的哪个列或者哪个常量用来和key列中的索引做比较来检索数据。如果此列的值为func,则说明使用了某些函数的结果数据与key列中的索引做比较来检索数据。
(10)rows:查询数据时必须查找的数据行数,当数据表的存储引擎为InnoDB时,值为MySQL的预估值。
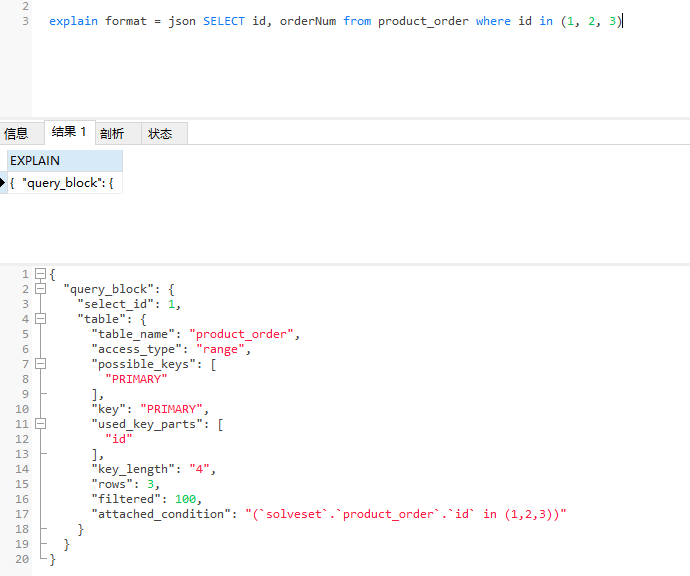
(11)Extra:在执行查询语句时额外的详细信息。EXPLAIN语句支持使用JSON格式输出结果信息,例如:
using filesort(性能非常差):说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。mysql中无法利用索引完成的排序称为文件排序。
using temporary(性能非常差):新建了内部临时表,使用了临时表保存中间结果。常见于order by、group by,所以分组和排序一定要按照锁建立的索引的名字和顺序。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180996.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
