大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
20220502:已经很长时间不用 CSDN 写博客了,今天偶然看到自己以前写的这篇,发现存在一些错误和讲的不清楚的地方,修改一下以免误人子弟。(当然可能改后还是有错的,请读者不要尽信,如果实在不能理解我说的,很可能是我说错了
主要参考资料:
(1)https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test
(2)https://wenku.baidu.com/view/ccfa573a3968011ca30091d6.html


Kolmogorov–Smirnov statistic
- 累计分布函数:
其中 I [ − inf , x ] I_{[-\inf,x]} I[−inf,x] 为indicator function(指示函数),
I [ − inf , x ] ( X i ) = { 1 , X i ≤ x ; 0 , X i > x ; I_{[-\inf,x]}(X_i)=\left\{\begin{matrix} 1,X_i\leq x;\\ 0,X_i> x; \end{matrix}\right. I[−inf,x](Xi)={
1,Xi≤x;0,Xi>x; - Kolmogorov–Smirnov statistic:
对于一个样本集的累计分布函数 F n ( x ) F_n(x) Fn(x)和一个假设的理论分布 F ( x ) F(x) F(x),Kolmogorov–Smirnov statistic定义为:
s u p x sup_x supx是距离的上确界(supremum), 基于Glivenko–Cantelli theorem,若 X i X_i Xi服从理论分布 F ( x ) F(x) F(x),则当n趋于无穷时 D n D_n Dn趋于0。
##Kolmogorov distribution - 准备知识:
(1)独立增量过程
顾名思义,就是指其增量是相互独立的。严格定义如下:
(2)维纳过程(英语:Wiener process)
大概可以理解为一种数学化的布朗运动,严格定义如下:
(3)布朗桥(英文:Brownian bridge)
一种特殊的维纳过程,严格定义如下:
就是说一个在 [ 0 , T ] [0,T] [0,T]区间上,且 W T = 0 W_T=0 WT=0的维纳过程。
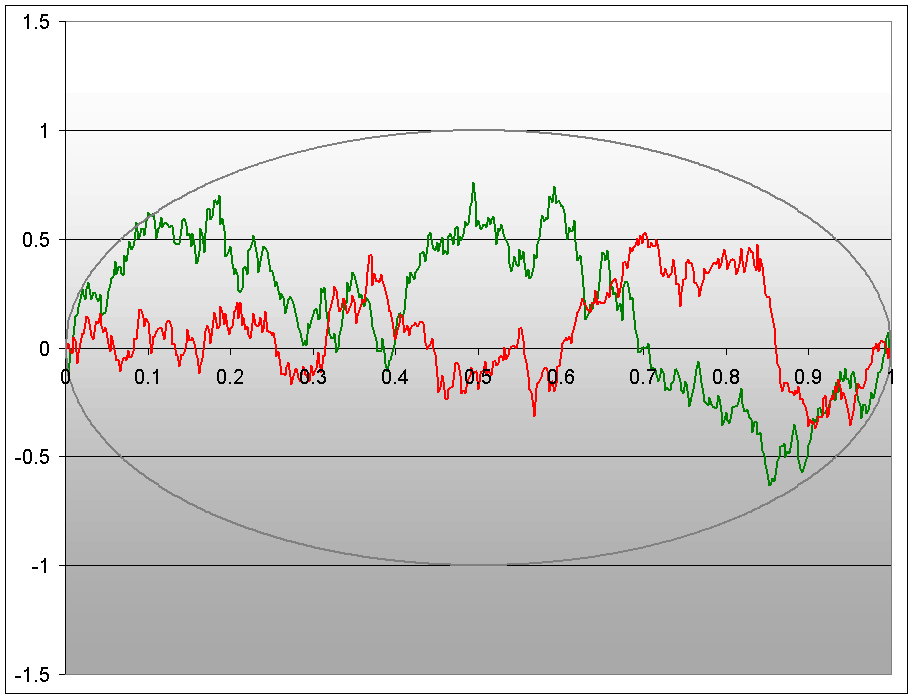
如图:
红色和绿色的都是“布朗桥”。 - Kolmogorov distribution
(1)Kolmogorov distribution
Kolmogorov distribution定义为:
即是通过求布朗运动上确界得到的随机变量的分布。
它的累积分布函数可以写为:
(2)单样本K-S检验
单样本K-S检验即是检验样本数据点是否满足某种理论分布。
注意!若该理论分布的参数是由样本点估计的,该方法无效!
20220502补充:有朋友在评论里提问这句话的理论依据,其实我也不清楚。我认为可能和自由度相关,用样本估计的参数(假设是极大似然估计)本身就是尽快可能“适合”现有样本的。
我们从零假设出发。(即假设样本点不满足理论分布20220502修改:零假设是样本点满足理论分布)
20220502补充:这涉及对假设检验这个框架的理解。假设检验是检验零假设是否能“自然”的解释观测结果。比如我们的抛硬币,我们的零假设是这个硬币是公平的,正反面出现的概率相同,如果抛十次 4 正 6 反,我们可以说是试验次数有限造成的,但要是10 正 0 反,再这么说就显得不自然了。如何精确的描述“自然”以及具体的严格理论请参考其他资料。
此时,若理论分布是一种连续分布,则有:
也就是说在有无限多的样本点的时候,不论F的具体形式, n D n \sqrt{n}D_n nDn将趋向于一个Kolmogorov distribution。(好像也叫做“依分布收敛”)
然而事实上,我们既不可能有无穷多样本点,也不是为了证明样本点和完全不满足理论分部。
K-S检验给出了零假设被拒绝的可能性的一种衡量方法(即样本点满足理论分布的可能性)α \alpha α:
20220502修改:还是以前对假设检验理解有误的锅,K-S检验给出的是现在从样本里看到的结果多大程度上能被零假设解释。直观上说就是累计分布和零假设预期的累计分布偏差越大就越不能被零假设解释,比如我们预期由于随机性的存在,即便在零假设成立的条件下,在当前样本容量下,出现大于等于当前看到的偏差的概率为 50%,那我们认为可以用零假设解释当前的情况。如果出现大于等于当前看到的偏差的概率为 10%,保守一些可能觉得还是可以用零假设解释当前的情况,激进一些可能就觉得不太能用零假设解释当前的情况。而下面给出的 α \alpha α 就是这个“零假设成立的条件下,在当前样本容量下,出现大于等于当前看到的偏差的概率”
α = m i n ( [ α ′ ∣ n D n > K α ′ ] ) \alpha =min([\alpha^\prime|\sqrt{n}D_n>K_{\alpha^\prime}]) α=min([α′∣nDn>Kα′])
其中, K α ′ K_{\alpha^\prime} Kα′由以下方式给出:
P r ( K ≤ K α ′ ) = 1 − α ′ Pr(K \le K_{\alpha^\prime}) = 1 – \alpha^\prime Pr(K≤Kα′)=1−α′
20220502补充:关于 α \alpha α 的式子比较绕,这里再说一下。先看 α \alpha α 的定义,就是在 n D n > K α ′ \sqrt{n}D_n>K_{\alpha^\prime} nDn>Kα′ 的约束下,最小的那个 α ′ \alpha^\prime α′,再看 K α ′ K_{\alpha^\prime} Kα′ 是怎么来的,就是 K α ′ K_{\alpha^\prime} Kα′ 使得 K K K 小于等于它的概率为 1 − α 1-\alpha 1−α(所以大于它的概率为 α \alpha α)。至于为啥要有个取最小值这还是假设检验框架下的惯用做法。还是用抛硬币的例子,我们用|正-反|来作为衡量是否公平的统计量,假设我们现在看到 8 正 2 反,那统计量为 6,那么 0,2,4 都小于 6,数字越大对应的正反面概率相等的硬币抛 10 次得到大于这个数字的概率 α ′ \alpha^\prime α′ 越小,我们必须找最小的那个 α ′ \alpha^\prime α′(即大于 |正-反|=4 的概率,也就是我们想要的“大于等于当前看到的偏差(6)的概率”)才行。
可以这样定性的理解,样本点越偏离理论分布,它的Kolmogorov–Smirnov statistic就会越大,那么我们找到的 K α K_\alpha Kα就越大, α \alpha α就越小,理论分布就越难解释现在的样本,反之亦然。
PS:
wiki上给出的并不是这样,而是:
但按照我的理解这种提法有些问题。因为我们知道 K 1 = 0 K_1=0 K1=0;而 n D n > 0 \sqrt{n}D_n>0 nDn>0几乎总是成立的。那岂不是对于任何样本点,总有 α = 1 \alpha=1 α=1?
20220502补充:这没什么问题,“The null hypothesis is rejected at level α \alpha α” 其实就是说“零假设成立的条件下,在当前样本容量下,出现大于等于当前看到的偏差的概率小于等于 α \alpha α”,那任何时候出现大于等于当前看到的偏差的概率都小于等于 100%(但这样说没意思,任何一个概率都小于等于 100%,等于没说,也正是因为这个原因我们要找最小的 α ′ \alpha^\prime α′) - 当理论分布函数非连续时
这里直接引用wiki上的内容
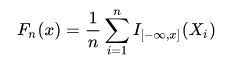
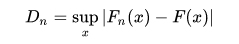


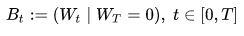
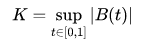
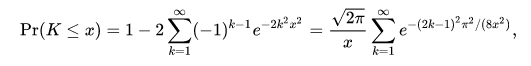
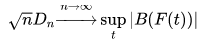
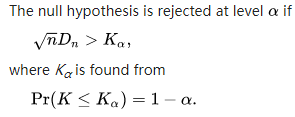

双样本集K-S检验
双样本K-S检验即是检验两个样本集是否满足同样的潜在分布。
其零假设被否定的可能性仍然以 α \alpha α给出:
α = m i n ( [ α ∣ D n , m > c ( α ) n + m n m ] ) , \alpha =min([\alpha|D_{n,m}>c(\alpha)\sqrt{\frac{n+m}{nm}}]), α=min([α∣Dn,m>c(α)nmn+m]),
其中:
PS:
wiki上的提法与此不同,此处采用此种提法的原因与单样本K-S检验相同。
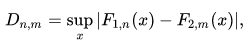
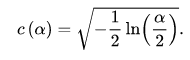
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180543.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
