大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
不知道各位童鞋们是否遇到过需要使用python下载大文件的需求,或者需要从一些网速很慢的网站上下载文件。如果你在实际下载过程碰到下载不稳定经常失败的情况,本文的方法将会给你带来一些解决思路和方案。
本文会给大家演示如何使用python对单个大文件进行多线程下载或协程形式下载,基于此还提供了断点续传的实现思路,想使用python开发下载器的朋友都可以拿本文作为参考,期待各位大佬的大作。
下面我们以知乎视频《
【AI混血】人工智能一键生成角色全身立绘?!【大谷纽约实验室】》为例进行演示,链接:
https://www.zhihu.com/zvideo/1387830268154195968
下面首先看一下最基础的直接下载文件的方法:
⭐单线程直接下载⭐
只需要在开发者工具的元素选项卡搜索video标签,即可找到视频的MP4下载链接:
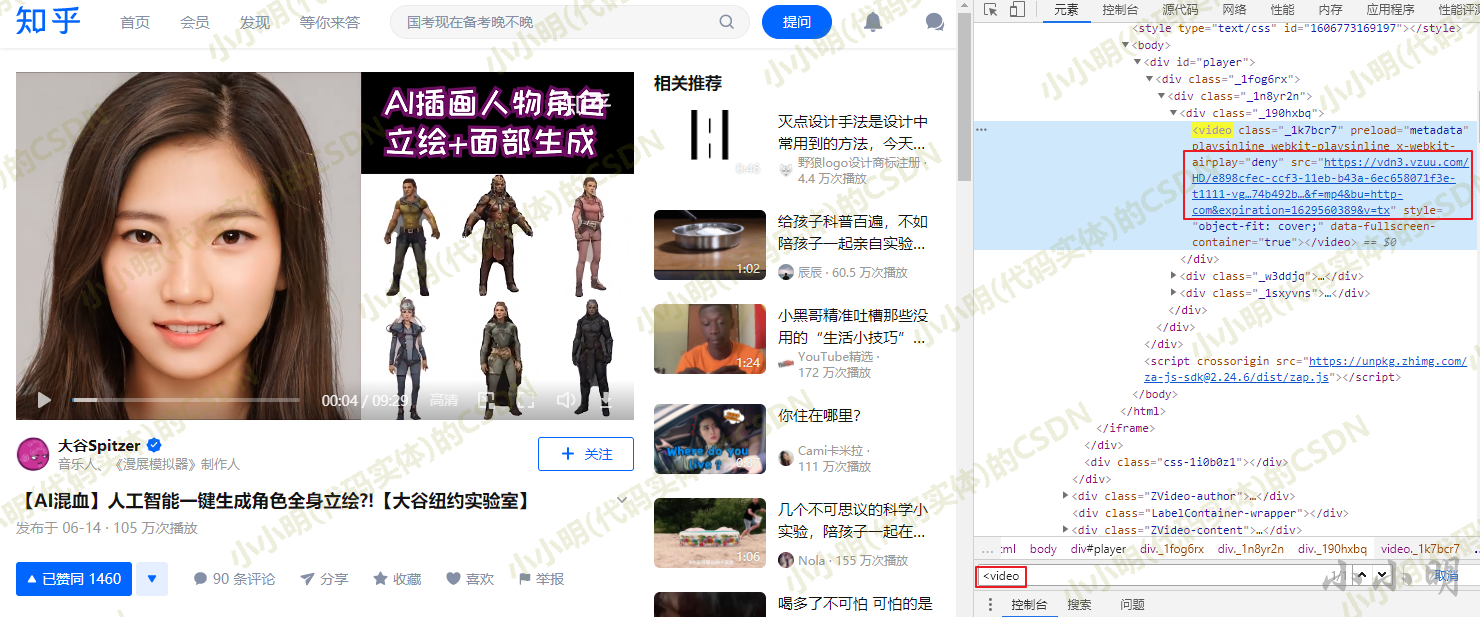

当然这个操作也完全可以借助idm的嗅探功能获取下载链接。
idm下载地址:https://www.lanzoui.com/ia51jqb
idm插件安装地址:https://chrome.google.com/webstore/detail/idm-integration-module/ngpampappnmepgilojfohadhhmbhlaek
复制出该链接后即可直接下载该视频:
import requests
url = "https://vdn3.vzuu.com/HD/e898cfec-ccf3-11eb-b43a-6ec658071f3e-t1111-vgodrDABRC.mp4?disable_local_cache=1&auth_key=1629560389-0-0-05874b492bec9be924c7da35aa619536&f=mp4&bu=http-com&expiration=1629560389&v=tx"
save_name = "单线程直接下载.mp4"
with open(save_name, "wb") as f, requests.get(url) as res:
f.write(res.content)
下载后视频正常播放:
这种下载方式对于知乎这种网络快的网站自然是没有问题,但是有些网络不好的网站就很可能下载中途网络中断,等了很久最终却下载失败。下面我们看看相对稳定很多的下载方法:
?单线程流式下载?
使用方法是get方法指定参数stream=True:
save_name = "单线程流式下载.mp4"
num = 0
with open(save_name, "wb") as f, requests.get(url, stream=True) as res:
for chunk in res.iter_content(chunk_size=64*1024):
if not chunk:
break
f.write(chunk)
num += 1
print(f"\r迭代次数:{
num}", end=" ")
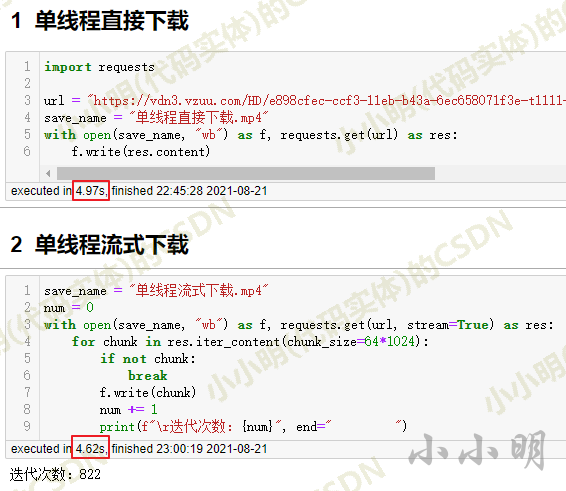
上述代码,以64KB为一组进行流式数据传输,最终速度显然比普通的下载更快一些:
使用shutil库可以简化代码编写:
import requests
import shutil
url = "https://vdn6.vzuu.com/HD/e898cfec-ccf3-11eb-b43a-6ec658071f3e-t1111-vgodrDABRC.mp4?pkey=AAVKDIgZuES50oUNCBq-nUpHoBmaVfAyhuDeSf9v2szjq3tuG83GsKISZBIU7-i2OyTlNR3IYADmdKI_hcRIouRc&c=avc.0.0&f=mp4&pu=da4bec50&bu=http-da4bec50&expiration=1659059784&v=ks6"
save_name = "单线程流式下载2.mp4"
with open(save_name, "wb") as f, requests.get(url, stream=True) as res:
shutil.copyfileobj(res.raw, f)
☀️单线程分片流式下载☀️
那么我们如何做到文件的断点续传呢?这时候就需要通过请求头修改需要读取的字节范围,当然也需要先检查目标服务器是否支持范围请求。
如果请求一个资源时, HTTP响应中出现Accept-Ranges且其值不是none, 那么服务器支持范围请求。
我们看看head这种请求方式:
res = requests.head(url)
head = res.headers
data = res.content
print(head)
print(data)
{'Server': 'NWSs', 'Date': 'Sat, 21 Aug 2021 15:25:19 GMT', 'Content-Type': 'video/mp4', 'Content-Length': '53825263', 'Connection': 'keep-alive', 'Cache-Control': 'max-age=600', 'Expires': 'Sat, 21 Aug 2021 15:35:19 GMT', 'Last-Modified': 'Mon, 14 Jun 2021 10:06:22 GMT', 'X-NWS-LOG-UUID': '8fcf387e-7bab-44fb-8cf0-e96f5def3b1c', 'Access-Control-Allow-Origin': '*', 'Access-Control-Max-Age': '31536000', 'x-cdn-provider': 'tencent', 'X-Cache-Lookup': 'Hit From Disktank3, Hit From Inner Cluster', 'Accept-Ranges': 'bytes', 'ETag': '"bfd7937656505a8ab9a05bc373745a8b"', 'x-cos-hash-crc64ecma': '5809002519149120115', 'x-cos-replication-status': 'Complete', 'x-cos-request-id': 'NjEwOTM5MzZfNWM0ZTQ0MGJfNDc2MV8xZmQ3YmZj', 'x-cos-storage-class': 'STANDARD_IA', 'x-cos-version-id': 'MTg0NDUxMjA0MDg1MjcxMDk4MTA', 'X-Daa-Tunnel': 'hop_count=1'}
b''
可以看到head请求只返回的响应头,未返回任何数据。上面的响应头中,'Accept-Ranges': 'bytes' 代表可以使用字节作为单位来定义请求范围。Content-Length 则代表该资源的完整大小。
于是我们可以通过Content-Length 响应头获取文件的大小:
filesize = int(res.headers['Content-Length'])
filesize
53825263
这就是当前文件的总大小。
这时我们就可以根据总大小对文件进行分片,例如总共分几部分或者多大的部分作为一个分片。这里我以个数进行分片,下面方法默认对文件分成10个小部分:
def calc_divisional_range(filesize, chuck=10):
step = filesize//chuck
arr = list(range(0, filesize, step))
result = []
for i in range(len(arr)-1):
s_pos, e_pos = arr[i], arr[i+1]-1
result.append([s_pos, e_pos])
result[-1][-1] = filesize-1
return result
divisional_ranges = calc_divisional_range(filesize)
divisional_ranges
[[0, 5382525],
[5382526, 10765051],
[10765052, 16147577],
[16147578, 21530103],
[21530104, 26912629],
[26912630, 32295155],
[32295156, 37677681],
[37677682, 43060207],
[43060208, 48442733],
[48442734, 53825262]]
Range 请求头的语法:Range: bytes=start-end
Range头域可以请求一个或者多个子范围。例如:
- 表示头500个字节:bytes=0-499
- 表示第二个500字节:bytes=500-999
- 表示最后500个字节:bytes=-500
- 表示500字节以后的范围:bytes=500-
- 第一个和最后一个字节:bytes=0-0,-1
- 同时指定几个范围:bytes=500-600,601-999
需要注意一下各种文件模式的区别:
| 模式 | 描述 |
|---|---|
| r | 默认模式:以只读文本形式打开文件,文件的指针将会放在文件的开头。 |
| rb | 以二进制格式打开一个文件用于只读,文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于文本读写,文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写,文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于文本写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写,如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于文本追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
可以看到:
wb+、rb+和ab+均以二进制格式读写文件,但wb+会覆盖已经存在的文件,只有rb+或ab+能够允许多个文件句柄操作同一个文件。最终我选择打开后文件指针在文件开头的rb+模式来完成多线程对同一文件的读写。
首先需要先创建空文件,保证rb+模式读取文件前,文件已经存在:
save_name = "单线程分片流式下载.mp4"
with open(save_name, "wb") as f:
pass
将范围下载的过程封装到以下方法中:
def range_download(save_name, s_pos, e_pos):
headers = {
"Range": f"bytes={
s_pos}-{
e_pos}"}
res = requests.get(url, headers=headers, stream=True)
with open(save_name, "rb+") as f:
f.seek(s_pos)
for chunk in res.iter_content(chunk_size=64*1024):
if chunk:
f.write(chunk)
然后就可以分片进行下载:
for s_pos, e_pos in divisional_ranges:
range_download(save_name, s_pos, e_pos)
循环每一次都打开一个文件句柄写入指定范围的数据。
基于此,我们就可以很简单的转换为多线程的实现:
?多线程下载大文件?
关于多线程、协程和多进程可以参考前面的示例:
结合前面已有代码,实现多线程下载的完整代码为:
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
def calc_divisional_range(filesize, chuck=10):
step = filesize//chuck
arr = list(range(0, filesize, step))
result = []
for i in range(len(arr)-1):
s_pos, e_pos = arr[i], arr[i+1]-1
result.append([s_pos, e_pos])
result[-1][-1] = filesize-1
return result
# 下载方法
def range_download(save_name, s_pos, e_pos):
headers = {
"Range": f"bytes={
s_pos}-{
e_pos}"}
res = requests.get(url, headers=headers, stream=True)
with open(save_name, "rb+") as f:
f.seek(s_pos)
for chunk in res.iter_content(chunk_size=64*1024):
if chunk:
f.write(chunk)
url = "https://vdn3.vzuu.com/HD/e898cfec-ccf3-11eb-b43a-6ec658071f3e-t1111-vgodrDABRC.mp4?disable_local_cache=1&auth_key=1629707188-0-0-8e6fe4e1e29621664c71e2b95fc3bdb9&f=mp4&bu=http-com&expiration=1629707188&v=tx"
res = requests.head(url)
filesize = int(res.headers['Content-Length'])
divisional_ranges = calc_divisional_range(filesize)
save_name = "多线程流式下载.mp4"
# 先创建空文件
with open(save_name, "wb") as f:
pass
with ThreadPoolExecutor() as p:
futures = []
for s_pos, e_pos in divisional_ranges:
print(s_pos, e_pos)
futures.append(p.submit(range_download, save_name, s_pos, e_pos))
# 等待所有任务执行完毕
as_completed(futures)
0 5382525
5382526 10765051
10765052 16147577
16147578 21530103
21530104 26912629
26912630 32295155
32295156 37677681
37677682 43060207
43060208 48442733
48442734 53825262
这样我们就实现了Python多线程下载大文件。
从结果看,四种下载方法得到的文件都完全一致:

这样我们就实现了大文件的多线程下载。
?协程分片下载大文件?
那么能否以协程形式分片下载大文件呢?
在之前的协程爬虫的文章中,我使用了aiohttp完成了数据的异常爬虫,这次我们尝试使用最近一个新的支持异步爬取的库httpx,而且该库支持http2.0能够爬取http2.0协议的网页。
要爬取http2.0的站点只需要:
import httpx client = httpx.Client(http2=True)之后client对象与request库的API几乎完全一致,只需把之前代码中使用的requests改成这个client对象即可。
协程不需要支持stream流式下载,最终封装的下载方法为:
async def async_range_download(save_name, s_pos, e_pos):
headers = {
"Range": f"bytes={
s_pos}-{
e_pos}"}
res = await client.get(url, headers=headers)
with open(save_name, "rb+") as f:
f.seek(s_pos)
f.write(res.content)
完整下载代码为:
import asyncio
import httpx
import requests
import nest_asyncio
nest_asyncio.apply()
def calc_divisional_range(filesize, chuck=10):
step = filesize//chuck
arr = list(range(0, filesize, step))
result = []
for i in range(len(arr)-1):
s_pos, e_pos = arr[i], arr[i+1]-1
result.append([s_pos, e_pos])
result[-1][-1] = filesize-1
return result
# 下载方法
async def async_range_download(save_name, s_pos, e_pos):
headers = {
"Range": f"bytes={
s_pos}-{
e_pos}"}
res = await client.get(url, headers=headers)
with open(save_name, "rb+") as f:
f.seek(s_pos)
f.write(res.content)
client = httpx.AsyncClient()
url = "https://vdn1.vzuu.com/HD/e898cfec-ccf3-11eb-b43a-6ec658071f3e-t1111-vgodrDABRC.mp4?disable_local_cache=1&auth_key=1629718189-0-0-2e4eceee29e2d17a92c77fd49911d39a&f=mp4&bu=http-com&expiration=1629718189&v=hw"
res = httpx.head(url)
filesize = int(res.headers['Content-Length'])
divisional_ranges = calc_divisional_range(filesize, 20)
save_name = "协程分片下载.mp4"
# 先创建空文件
with open(save_name, "wb") as f:
pass
loop = asyncio.get_event_loop()
tasks = [async_range_download(save_name, s_pos, e_pos)
for s_pos, e_pos in divisional_ranges]
# 等待所有协程执行完毕
loop.run_until_complete(asyncio.wait(tasks))
上述代码中:
import nest_asyncio
nest_asyncio.apply()
这两行的目的是为了兼容协程程序能够在Jupyter notebook环境中运行,对于普通的py文件中运行,可以直接删除。
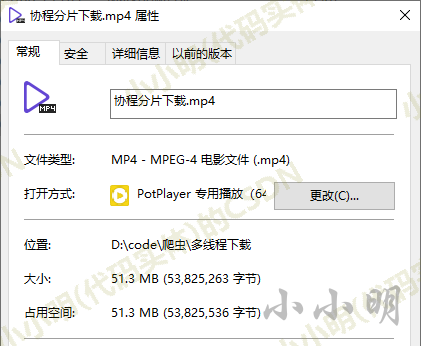
最终下载结果:
?实现断点续传的思路?
那么如何通过python实现断点续传呢?
粗粒度的方法就是以分片为校验单位,某个分片下载失败则重新下载。
细粒度一点的方法是每个分片内部校验已下载的范围,对于下载失败的分布,重新定位起始位置继续下载。
?总结?
本文非常浅层的演示了python如何实现多线程文件下载,核心取决于现代服务器基本都支持范围下载的前提下。关于断点续传,文章已提供基本理论和实现思路,有兴趣通过python实现下载器的朋友都可以专门去实现一下。
我是小小明,咱们下期再见~
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/181305.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
