大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
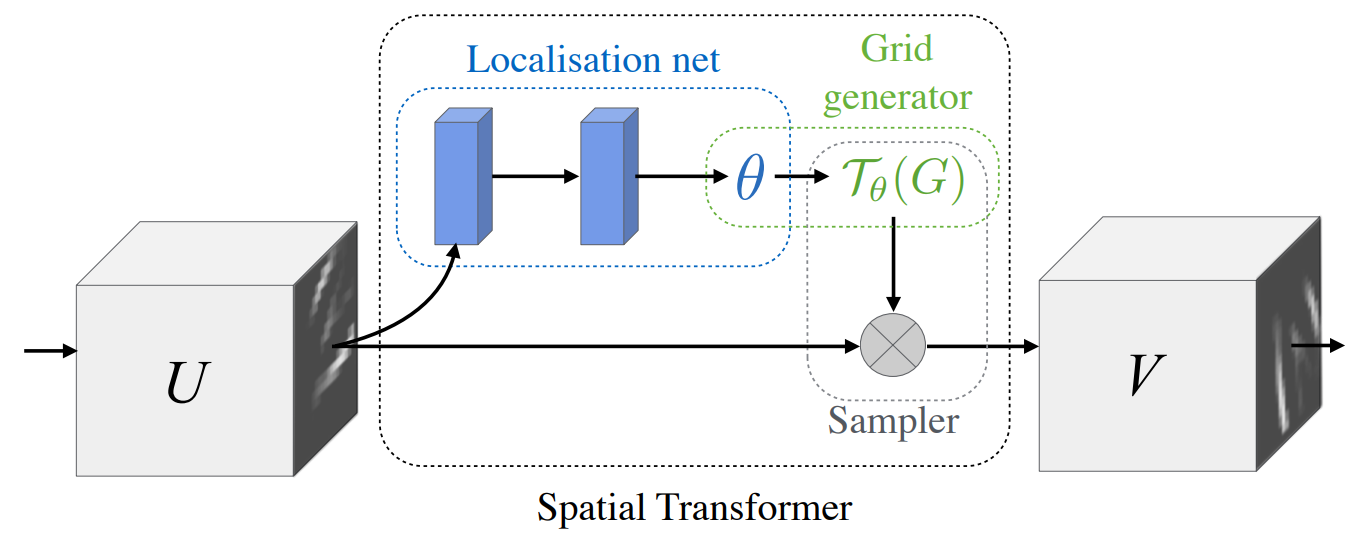

这篇文章是15年谷歌DeepMind团队推出的一个可以学习一种变换,这种变换可以将进行了仿射变换的目标进行校正的网络——Spatial Transformer Network(STN)。STN具有空间不变性特点,也就是说STN可以使图片经过各种变换后的识别效果和未变换前的识别效果保持不变。
Note:
- 空间不变性:旋转、平移、缩放、裁剪不变性。
- 仿射变换:平移、缩放、裁剪、旋转变换的集合,可以用Pytorch的仿射层(全连接层)来表示变换矩阵 θ \theta θ。
- 传统的池化方式(Max Pooling/Average Pooling)所带来卷积网络的位移不变性和旋转不变性只是局部的和固定的(池化的大小一般都很小,比如 3 × 3 3\times 3 3×3);而且池化并不擅长处理其它形式的仿射变换。
- STN提出的意义在于能够把变换后的图像校正成为NN想要的理想图像,然后喂入NN去识别。并且,STN可以根据不同变换的图像动态地进行空间变换。这个网络是一个独立于NN的模块,也就是说STN可以在NN的任何位置插入,这就是为什么STN的输入可以是feature map。
参考文档:
①Spatial Transformer Networks
②论文笔记:空间变换网络(Spatial Transformer Networks)
③理解Spatial Transformer Networks
④Spatial Transformer Networks
⑤STN的PyTorch实现
⑥次梯度Sub-Gradient
⑦STN论文补充材料
简单一句话,STN就是将经过变换后的输入图像进行矫正,使得后续的层可以更容易地去做一些task,如分类任务等。
Spatial Transformer Networks
Abstract
STN提出的必要性:
CNN网络在图片的分类任务上展现了很强的表现力,但是却无法解决图片因为一些空间变化而导致模型性能下降的问题;这些空间变换包括常见的仿射变换(Affine),比如平移、缩放、旋转、裁剪、另外还有诸如投影变换等各种变形(warp)方法。
STN的功能:
为了解决这个问题,谷歌DeepMind团队于2015年推出了Spatial Transformer Networks(以下简称STN),这是一个可插入在任何CNN网络中间的可学习网络,意味着STN也具有前向推断、反向传播(STN可导)、梯度更新参数的功能且输入输出可以都是feature map,而不一定非得是完整的原始图片。因此STN可以和整个CNN网络一起实现end-to-end的训练,像一个”插件“一样帮助CNN拥有空间不变性。插入STN后,CNN针对不同变化可以产生类似的结果,即不受图片变换带来的性能影响(下图来自于参考文档②):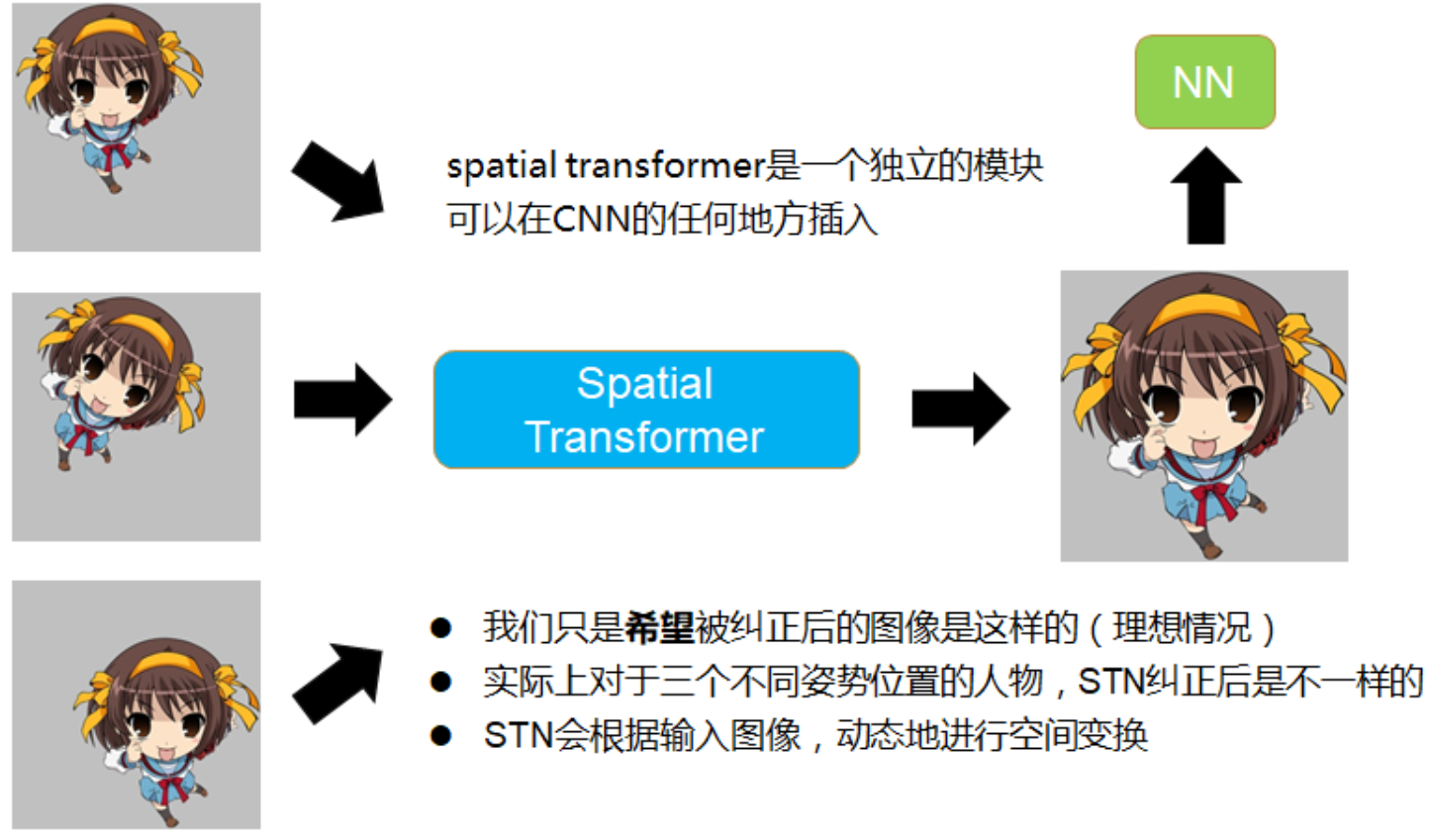
作者通过一系列实验表明,插入STN的CNN网络在一些数据集上达到了SOAT的水准。
1 Introduction
池化层(最大池化、平均池化)在一定程度上可以维持网络的空间不变性,但是由于其感受野往往都很小(如 2 × 2 2\times 2 2×2),因此只能在一些深度layer上使用,而对于浅层或者较大变化的图像来说,最大池化层是不满足我们想要的空间不变特性的,因为池化层他只是一种局部空间不变层,无法影响到较大范围空间的不变性。
鉴于此,本文提出了一种基于整张feature map范围的空间不变网络——STN,它有以下特性:
- 空间变换网络STN可以插入任意CNN网络的中间,当然也可以是网络的输入端,这就意味着STN的输入可以是feature map,也可以是原始图片。
- STN不像池化层只能维持局部区域的不变性,而可以保持整张输入feature map的空间不变性,针对包括平移、旋转、缩放、裁剪等变形情况。
- STN的加入使得后续的网络的训练变得更加容易,不再收到图像因为形变而导致性能下降的问题。
- STN的另一个好处就是它是可导的,意味着它的参数可以通过网络反向传播而学习得到,从而使得插入STN的整个CNN网络实现了端对端的模型训练。
STN可以适用于以下任务:
- Image-Classification。如果一个CNN网络用于图像分类任务,那么STN就可以插进这个CNN网络中取提升分类性能,具体如下所示:

如上图所示,输入图像a通过加入STN之后,输出的图像如c所示,相信对于网络来说,对c进行分类训练会比直接对a更加容易。个人认为如图c所示也是注意力机制的一种运用。 - Co-localisation。
- Spatial-Attention。STN可以利用在一些需要注意力机制的任务,STN可以加强STN后续网络对输入feature map的注意力,即将变形低分辨率图像转变成高分辨率图像,让后续网络能更有效的去工作。
2 Related Work
略
3 Spatial Transformers
这一节正式开始介绍空间变换网络STN。整个STN-CNN模型的前向过程就是将变换过的(conditioned)输入图像(大多都是多通道的)经过STN处理,输出一个变形(warped)过的feature map(一般和输入一样size,但也可以是不同的size)。
整个STN网络分为3部分:
Localisation network。将变换过的输入图像(或feature map)经过一系列隐藏层(或仿射层)输入一个变换矩阵 θ \theta θ。它是一个可学习的参数,它描述了变换的信息,比如如果是仿射变换,那么 θ \theta θ就是个 2 × 3 2\times 3 2×3的张量,这6个元素中取不同的值代表了不同的变换,例如平移、旋转、缩放和裁剪,具体对应点这里,这个 θ \theta θ就是仿射变换矩阵,它用一个张量就包含了4种变换,网络会根据Loss的表现通过反传来学习这个参数,迫使他复杂化去融合多种变化方式。Grid generator。利用变换矩阵 θ \theta θ和输出图像的坐标来求得输出图像各个格点坐标在输入图像中的位置坐标。比如输出图像 ( 2 , 4 ) (2,4) (2,4)这个格点, θ = 0.5 \theta=0.5 θ=0.5(这里暂时用标量来简单代替以下),那么该点对应到输入图像的位置就是 ( 1 , 2 ) (1,2) (1,2)。Sampler。第三部分就是将上一步取得的各个格点坐标在输入图像上对应的像素值取出来,作为输出图像的值。比如输出图像 ( i , j ) (i,j) (i,j)位置对应到输入图像某个坐标是 ( x , y ) (x,y) (x,y),那么 ( x , y ) (x,y) (x,y)点处的像素值就作为输出图像在 ( i , j ) (i,j) (i,j)处的值。拿上面的例子来说,输出图像在 ( 2 , 4 ) (2,4) (2,4)处的值就是输入图像在 ( 1 , 2 ) (1,2) (1,2)处的像素值。这里还有个问题就是,一般对应到输入图像的坐标不会是像 ( 1 , 2 ) (1,2) (1,2)这样的整数,因此一般要通过插值的方式来确定比如在输入图像 ( 1.2 , 3.6 ) (1.2,3.6) (1.2,3.6)处的像素值,然后再作为输出图像相对应点的像素。
接下来将分开来介绍上述3个部分。
3.1 Localisation Network
Localisation网络是将输入图像(feature map)经过全连接层(仿射层)或者CNN输出一个变换矩阵 θ \theta θ。变换矩阵 θ \theta θ可以表征任何现存的一些变换,比如仿射变换、投影变换等,不同的变换会产生不同size的 θ \theta θ。例如,如果是仿射变换,我们就用一个 2 × 3 2\times 3 2×3的张量来表示:
[ θ 11 θ 12 θ 13 θ 21 θ 22 θ 23 ] \begin{bmatrix} \theta_{11}\,\,\,\theta_{12}\,\,\,\theta_{13}\\ \theta_{21}\,\,\,\theta_{22}\,\,\,\theta_{23} \end{bmatrix} [θ11θ12θ13θ21θ22θ23]
该层用以下公式表达:
θ = f l o c ( U ) . \theta = f_{loc}(U). θ=floc(U).
其中 U U U是输入图像(或feature map); θ \theta θ是一个变换矩阵; f l o c ( ⋅ ) f_{loc}(\cdot) floc(⋅)表示全连接层、CNN层等形成的函数,但是不管以哪一种函数形式,最终都要回归到指定格式的 θ \theta θ上去,比如我们想要的是仿射变换矩阵 θ \theta θ,PyTorch中就是这样实现的;
self.fc_loc = nn.Sequential(
nn.Linear(10 * 3 * 3, 32),
nn.ReLU(True),
nn.Linear(32, 3 * 2)
)
theta = self.fc_loc(feature_map)
theta = theta.view(-1, 2, 3)
Note:
- 如上代码所示,一个STN网络只有1个变换矩阵 θ \theta θ,不同通道的feature map共享同一个变换矩阵。
3.2 Parameterised Sampling Grid
该层紧接着上一层之后,目的是生成输出feature map在输入图像上对应的坐标,这里需要注意的是输出feature map不需要知道各个格点的像素值是多少,只需要知道其特征图的大小。这一层的目的就是将输出feature map的各个格点映射到输入feature map上,从而保存在输入feature map上相应的坐标,因此在很多的代码实现中,你会看到这一层的输入只是输出特征图的size,而并不关心特征图的值是多少。
Sampling Grid层的输入是Localisation层的输出变换矩阵 θ \theta θ以及输出feature map的坐标点集合 G = { G ( i , j ) } = { ( x i t , y j t ) } G=\{G_{(i,j)}\}=\{(x_i^t,y_j^t)\} G={
G(i,j)}={
(xit,yjt)},我们设输出feature map的size为: V ∈ R H ′ × W ′ × C V\in\mathbb{R}^{H’\times W’\times C} V∈RH′×W′×C,其中 i ∈ [ 0 , W ′ − 1 ] , j ∈ [ 0 , H ′ − 1 ] i\in[0, W’-1],j\in[0,H’-1] i∈[0,W′−1],j∈[0,H′−1]。
Note:
- 该层的输出(格点Grid)具有和该层的输入(输出feature map)具有相同的size。
- H ′ , W ′ H’,W’ H′,W′也可以和输入feature map( U ∈ R H × W × C U\in \mathbb{R}^{H\times W\times C} U∈RH×W×C)相同的大小,即 H ′ = H , W ′ = W H’=H,W’=W H′=H,W′=W。
为了用公式清楚的表达该层所做的工作,我们假设变换矩阵 θ \theta θ描述的是仿射变换,即 T θ ( ⋅ ) = A θ ( ⋅ ) \mathcal{T}_\theta(\cdot)=A_{\theta}(\cdot) Tθ(⋅)=Aθ(⋅),则Sampling Grid可表示为:
( x i s y j s ) = T θ ( G ( i , j ) ) = A θ ( x i t y j t 1 ) = [ θ 11 θ 12 θ 13 θ 21 θ 22 θ 23 0 0 1 ] ( x i t y j t 1 ) . (1) \begin{pmatrix} x_i^s\\ y_j^s \end{pmatrix}=\mathcal{T}_\theta(G_{(i,j)}) = A_\theta \begin{pmatrix} x^t_i\\ y^t_j\\ 1 \end{pmatrix}=\begin{bmatrix} \theta_{11}\,\,\,\theta_{12}\,\,\,\theta_{13}\\\theta_{21}\,\,\,\theta_{22}\,\,\,\theta_{23}\\0\,\,\,\,\,\,\,\,0\,\,\,\,\,\,\,\,1 \end{bmatrix}\begin{pmatrix} x^t_i\\ y^t_j\\ 1 \end{pmatrix}.\tag{1} (xisyjs)=Tθ(G(i,j))=Aθ⎝⎛xityjt1⎠⎞=⎣⎡θ11θ12θ13θ21θ22θ23001⎦⎤⎝⎛xityjt1⎠⎞.(1)
Note:
- 其中坐标 ( x i t , y j t ) (x^t_i,y^t_j) (xit,yjt)遍历整个输出feature map。
- 在这里输入 ( x i t 、 y j t ) (x_i^t、y_j^t) (xit、yjt)是输出图像的各个网格坐标,输出是输出图像在输入图像上对应的网格坐标点 ( x i s , y j s ) (x_i^s,y_j^s) (xis,yjs)。
- 一般来说 ( x i s , y j s ) (x_i^s,y_j^s) (xis,yjs)都是小数,因此我们需要通过插值的方式来取得输入图像的像素值,从而作为相对应的输出feature map的坐标 ( x i t 、 y j t ) (x_i^t、y_j^t) (xit、yjt)上的像素值。
- 式(1)就是个坐标转换公式,且这里输入是整像素,输出是亚像素(即输出坐标是小数,不一定是整数)。
接下来我们用2个例子来说明该层的作用:
①如下图所示:
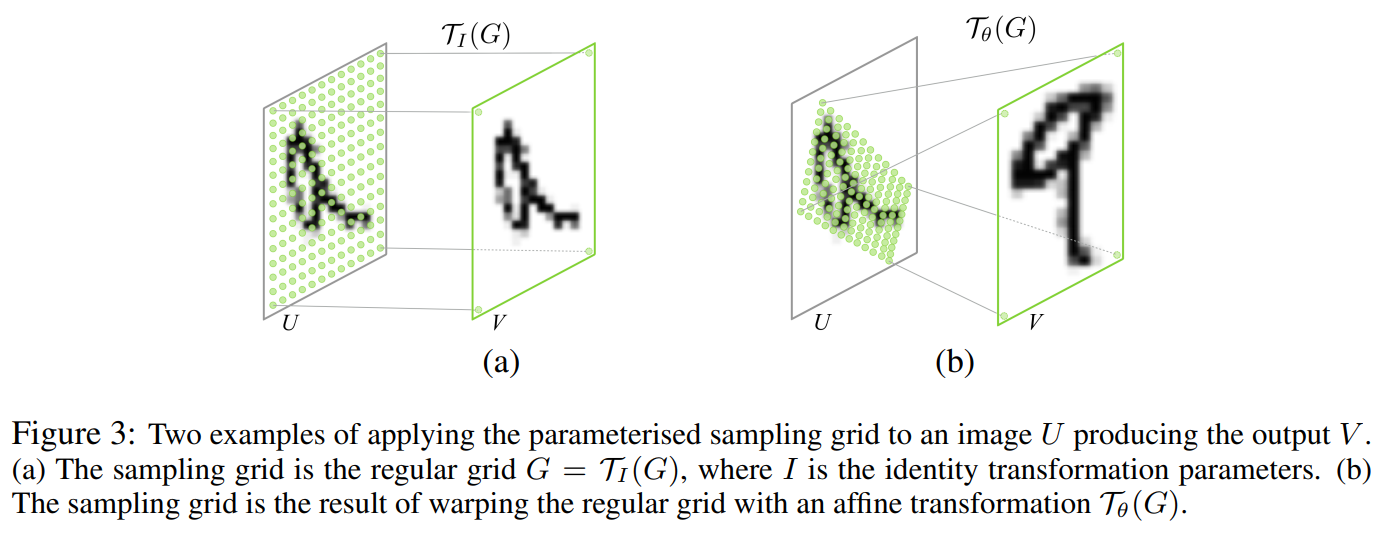
图(a)是当变换矩阵 θ \theta θ为单位矩阵 I I I的时候,即恒等变换过去,那么输出feature map对应在输入图像上的像素格点就是输出feature map自己本身的格点,两者是一一对应的,因此输入feature map的像素值也原样照抄到输出feature map上。
图(b)是当变换矩阵 θ \theta θ既有缩放又有旋转功能,可以通过训练得到。可以看到输出feature map对应到输入feature map上的格点是经过变换矩阵得到的,即 ( x i t , y j t ) (x_i^t,y_j^t) (xit,yjt)通过旋转、缩放获取坐标值 ( x i s , y j s ) (x^s_i,y_j^s) (xis,yjs)。
②假设Localisation层输出的变换矩阵如下(假设 s ∈ ( 0 , 1 ) s\in(0,1) s∈(0,1)):
A θ = [ s 0 t x 0 s t y ] A_\theta = \begin{bmatrix} s\,\,\,0\,\,\,t_x\\ 0\,\,\,s\,\,\,t_y \end{bmatrix} Aθ=[s0tx0sty]则这样的变换矩阵用于Sampling Grid层之后,输出的格点坐标一定是经过缩小和平移过的,缩小倍数为 s s s,横向平移 t x t_x tx,纵向平移 t y t_y ty。
3.3 Differentiable Image Sampling
这是STN的第三部分——重采样(或差分采样)。输出像素点 ( x i t , y j t ) (x^t_i,y^t_j) (xit,yjt)通过Sampling Grid生成在输入feature map( U U U)的坐标点 ( x i s , y j s ) (x^s_i,y^s_j) (xis,yjs),获取对应 U U U中的像素值来作为输出feature map( V V V)在 ( i , j ) (i,j) (i,j)处的像素值。理想状态是这样的,但是一般来说 T ( G ) \mathcal{T}(G) T(G)产生的坐标都是小数,因此不能直接取 U U U中的像素值来输出给 V V V,作者使用一些插值,如双线性插值来解决这个问题,利用小数坐标周围的整格点像素值计算得到最终的输出,用公式表示如下:
V i , j c = ∑ n H ∑ m W U n , m c ⋅ k ( x i s − m ; Φ x ) k ( y j s − n ; Φ y ) ∀ i , j ∈ [ 1 ⋯ H ′ W ′ ] , ∀ c ∈ [ 1 ⋯ C ] . (2) V_{i,j}^c = \sum^H_n\sum^W_m U^c_{n,m}\cdot k(x_i^s-m;\Phi_x)k(y_j^s-n;\Phi_y)\\ \forall i,j\in[1\cdots H’W’],\forall c\in[1\cdots C]. \tag{2} Vi,jc=n∑Hm∑WUn,mc⋅k(xis−m;Φx)k(yjs−n;Φy)∀i,j∈[1⋯H′W′],∀c∈[1⋯C].(2)其中 V i , j c V_{i,j}^c Vi,jc是输出feature map在通道 c c c,坐标 ( x i t , y j t ) (x^t_i,y^t_j) (xit,yjt)上的像素值; U n , m c U_{n,m}^c Un,mc是输入feature map在通道 c c c,坐标 ( n , m ) (n,m) (n,m)(一般来说 ( n , m ) ≠ ( x n s , y m s ) (n,m)\ne (x^s_n, y^s_m) (n,m)=(xns,yms))的像素值( ( n , m ) (n,m) (n,m)是 U U U中整格点像素坐标); Φ \Phi Φ是插值核函数 k ( ⋅ ) k(\cdot) k(⋅)的参数,其定义了插值的方式。
Note:
- 不同通道的采样都使用同样的方法,如式(2)所示。
理论上任意的插值方式都可以在式(2)中使用,当然为了网络的学习考虑,插值的方式需要是可导的(最差也要是可次导的)作者在文中主要介绍了2种插值方式,接下来分别介绍:
①最近邻插值
V i , j c = ∑ n H ∑ m W U n , m c ⋅ δ ( ⌊ x i s + 0.5 ⌋ − m ) δ ( ⌊ y j s + 0.5 ⌋ − n ) . (3) V_{i,j}^c = \sum^H_n\sum^W_m U^c_{n,m}\cdot \delta(\lfloor x_i^s+0.5\rfloor -m) \delta(\lfloor y_j^s +0.5\rfloor -n).\tag{3} Vi,jc=n∑Hm∑WUn,mc⋅δ(⌊xis+0.5⌋−m)δ(⌊yjs+0.5⌋−n).(3)其中 ⌊ ⋅ ⌋ \lfloor\cdot\rfloor ⌊⋅⌋表示取下限整数,整个式子表达的就是取STN第二阶段产生的非整数格点坐标 ( x i s , y j s ) (x^s_i,y_j^s) (xis,yjs)周围最近的几个整数格点坐标的值; δ ( ⋅ ) \delta(\cdot) δ(⋅)是克罗内克函数,或者就是冲激函数。
②双线性插值
双线性插值简单理解如下图所示:
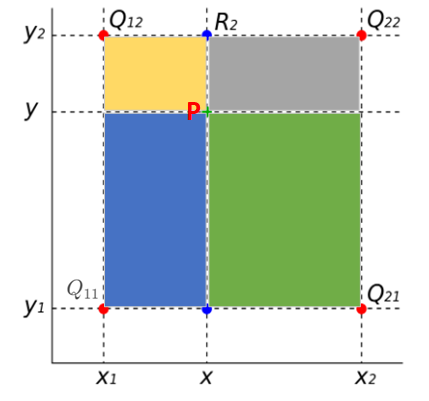
离插值点 P P P较远的 Q 11 Q_{11} Q11给它分配一个较小的值,就是灰色矩形的面积; Q 22 Q_{22} Q22离 P P P较近,就给他分配一个较大的权重,就是蓝色矩阵的面积,同理 Q 12 、 Q 21 Q_{12}、Q_{21} Q12、Q21也是一样。经过四个点的加权和之后形成的结果就是点 P P P的像素值。
V i , j c = ∑ n H ∑ m W U n , m c ⋅ m a x ( 0 , 1 − ∣ x i s − m ∣ ) m a x ( 0 , 1 − ∣ y j s − n ∣ ) . (4) V_{i,j}^c = \sum^H_n\sum^W_m U^c_{n,m}\cdot max(0,1-|x_i^s-m|)max(0,1-|y_j^s-n|).\tag{4} Vi,jc=n∑Hm∑WUn,mc⋅max(0,1−∣xis−m∣)max(0,1−∣yjs−n∣).(4)式(4)表达的意思就是双线性插值的思想,具体来说,遍历输入feature map上的整形格点,离 ( x i s , y j s ) (x^s_i,y_j^s) (xis,yjs)较远的值一律不考虑(赋予0值,对 V i , j c V^c_{i,j} Vi,jc不作贡献),式(4)中的距离”1“就是为了控制待插值点 ( x i s , y j s ) (x^s_i,y_j^s) (xis,yjs)像素值只用周围4个点来控制,当 ( x i s , y j s ) → ( n , m ) (x^s_i,y_j^s)\to(n,m) (xis,yjs)→(n,m)的距离都在1个格点之内的时候,我们取它的值,且离得越远权值越小,最终会得到4个整数格点以及他们对应的权值,经过加权和之后输出 V i , j c V^c_{i,j} Vi,jc,其实这就是和双线性插值的形式是一样的。
Note:
- 非插值部分一律取 0 0 0,显示出来就是黑色像素块。
- m a x ( ⋅ ) max(\cdot) max(⋅)函数是可导的,也就促成了该采样层是可导的,从而使得整个STN都是可导的,这样就可以通过梯度反传来更新STN的参数。
- STN的可导带来的好处是其可以和整个卷积网络一起端到端的训练,能够以layer的形式直接插入到卷积网络中。
- 因为这种采样方式可以促使网络通过反向传播和梯度下降学习到网络的参数,故STN的该层是一种重采样。
接下来我们可以计算以下STN网络的3种可学习参数:
①关于 U n , m c U_{n,m}^c Un,mc的导数:
∂ V i c ∂ U n , m c = ∑ n H ∑ m W m a x ( 0 , 1 − ∣ x i s − m ∣ ) m a x ( 0 , 1 − ∣ y j s − n ∣ ) . (5) \frac{\partial{V_i^c}}{\partial{U^c_{n,m}}} = \sum^H_n\sum^W_m max(0,1-|x_i^s-m|)max(0,1-|y_j^s-n|).\tag{5} ∂Un,mc∂Vic=n∑Hm∑Wmax(0,1−∣xis−m∣)max(0,1−∣yjs−n∣).(5)
②关于输入feature map中坐标格点的导数:
∂ V i , j c ∂ x i s = ∑ n H ∑ m W U n , m c ⋅ m a x ( 0 , 1 − ∣ y j s − n ∣ ) ⋅ { 0 , i f ∣ m − x i s ∣ ≥ 1 1 , i f m ≥ x i s , − 1 , i f m ≤ x i s . (6) \frac{\partial{V_{i,j}^c}}{\partial{x_i^s}} = \sum^H_n\sum^W_m U^c_{n,m}\cdot max(0,1-|y_j^s-n|)\cdot \begin{cases}0, \,\,\,if |m-x^s_i|\ge 1\\1,\,\,\,if m\ge x^s_i,\\-1 ,\,\,\,ifm\leq x^s_i. \end{cases}\tag{6} ∂xis∂Vi,jc=n∑Hm∑WUn,mc⋅max(0,1−∣yjs−n∣)⋅⎩⎪⎨⎪⎧0,if∣m−xis∣≥11,ifm≥xis,−1,ifm≤xis.(6) ∂ V i , j c ∂ y j s \frac{\partial{V_{i,j}^c}}{\partial{y_j^s}} ∂yjs∂Vi,jc也是同理,可以看出式(6)所求的是次梯度,虽然在收敛过程中会较慢,但是总归是可以通过次梯度下降方法去优化网络参数的。
③关于变换矩阵 θ \theta θ:
根据式(1):
( x i s y j s ) = T θ ( G i , j ) \begin{pmatrix} x^s_i\\y_j^s \end{pmatrix}=\mathcal{T}_\theta(G_{i,j}) (xisyjs)=Tθ(Gi,j)可以很容易求得 ∂ x i s ∂ θ 、 ∂ y j s ∂ θ \frac{\partial{x_i^s}}{\partial{\theta}}、\frac{\partial{y_j^s}}{\partial{\theta}} ∂θ∂xis、∂θ∂yjs,然后通过链式求导法则就可以求出 ∂ V i , j c ∂ θ \frac{\partial{V_{i,j}^c}}{\partial{\theta}} ∂θ∂Vi,jc,然后根据次梯度下降就可以更新变换网络 θ \theta θ。
3.4 Spatial Transformer Networks
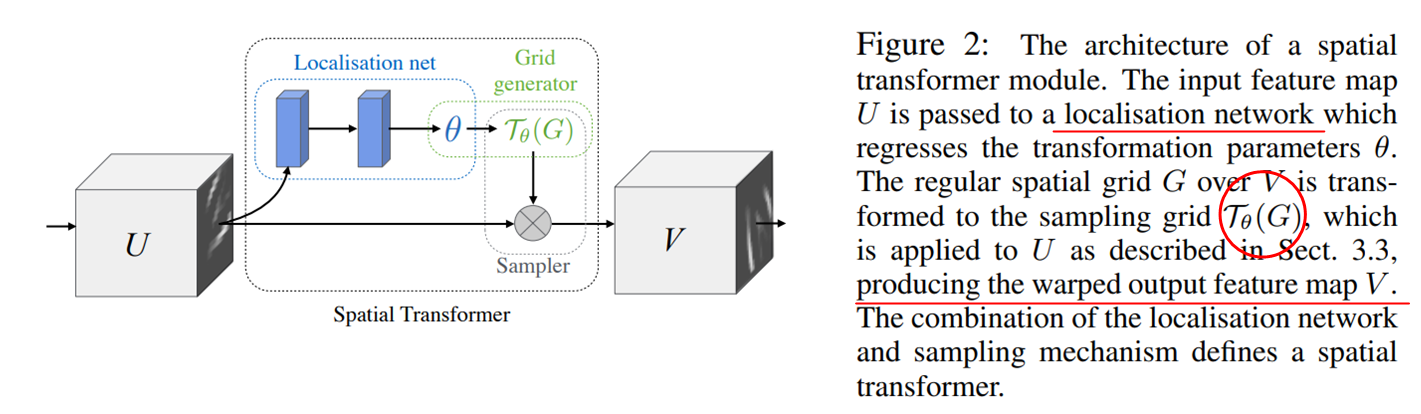
如上图所示就是整个STN网络的架构,它由3部分构成,分别是Localisation network、Parameterised Sampling Grid以及Differentiable Sampling。STN网络有以下几个特点:
- 它可以作为一个”插件“作为任何网络的一部分,意味着他的输入可以是Image/feature map,输出也可以是Image/feature map。
- STN是可导的网络,所以插入CNN后它可以实现端对端的训练。
- 插入STN网络后,新的重组网络具备了空间不变性,这让STN之后的网络的训练变得更加容易并提升了网络整体的表现力。
- 整个STN网络是十分轻量的,比如变换网络的参数大多时候都只是个位数,因此STN并不会伤害到到待插入网络的训练速度。
- STN也可以作为降采样或者上采样,正如3.2节所说, V ∈ R H ′ × W ′ × c V\in \mathbb{R}^{H’\times W’\times c} V∈RH′×W′×c,因此这个 H ′ , W ′ H’,W’ H′,W′可选择比 H × W H\times W H×W更大或者更小来实现feature map的放大和缩小。
作者还介绍2中multi-STN的结构,分别是多个不同的STN串联以及多个不同的STN并联。
①STN串联结构:
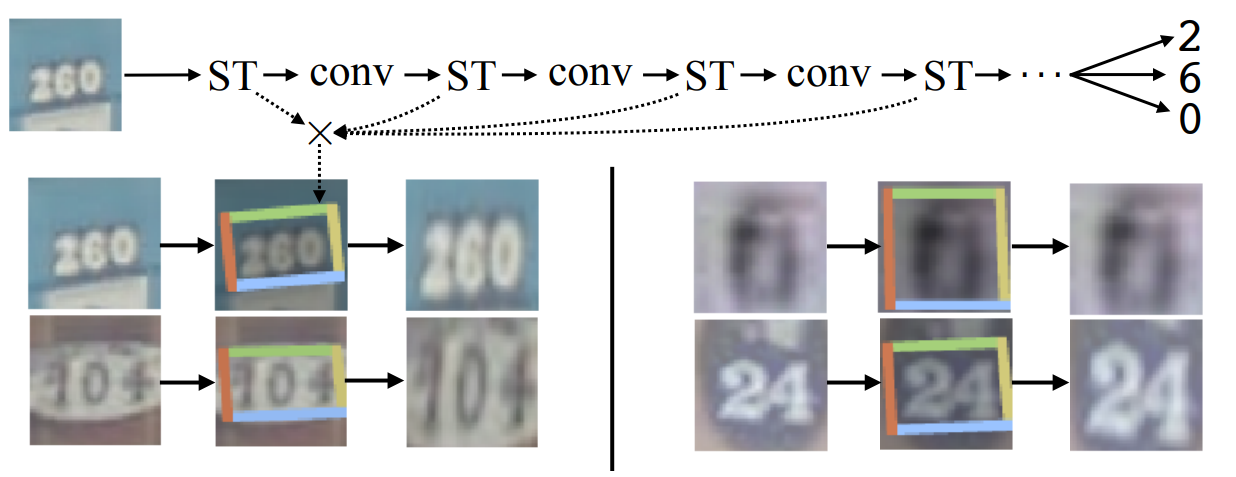
从上图中可以看出,不同level的STN会去处理不同输入的feature map,从而学习到网络不同深度下的变换信息 θ \theta θ。
②STN并联结构:
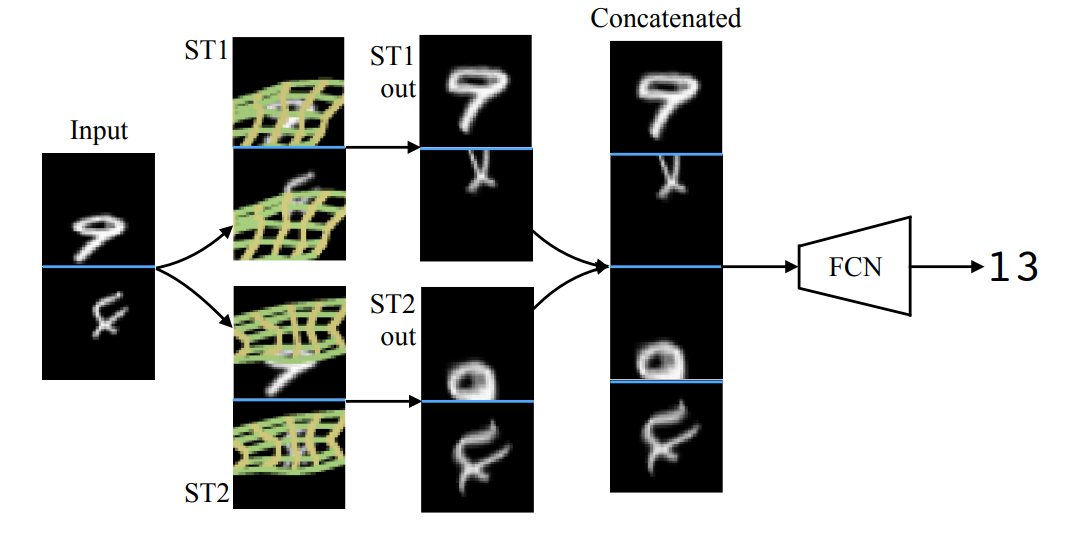
这个结构是这样的,ST1去处理图片9和图片4,由于ST1学习到的变换信息 θ \theta θ是向上平移,所以图片9和4都会往上移动,本来位置偏下的9就会被校正到图片中央,但由于 θ \theta θ只有一个故为共享参数,所以本来位置偏上的4就会往上拉一点,可以看出来ST1的 θ \theta θ更加偏重图片9;而ST2则相反,它更加偏重图片4多一点,它的 θ \theta θ更注重往下平移去校正位置偏上的图片。
4 Experiments
略,有兴趣可以去看实验部分和补充材料部分。
5 Conclusion
- 本文推出一种可插入到网络任意2个层之间,使得整体网络具有空间不变性的可导网络——
STN,STN作为”插件“的加入,不仅保持了端对端的训练方式,也让STN后续的网络更容易去训练学习。 - STN分为三部分,分别是:①
Localisation network②Parameterised Sampling Grid③Differentiable Image Sampling,分别是为了产生变换矩阵 θ \theta θ;产生格点坐标 ( x i s , y j s ) (x^s_i,y^s_j) (xis,yjs);对照 ( x i s , y j s ) (x^s_i,y^s_j) (xis,yjs)在 U U U中采样获得 V V V。 - 经过STN得到的输出feature map一般都是正立的,比如手写数字集中的数字都是朝上放置,那是因为一般标签(Ground-Truth)都是朝上直立的,那么由于nn会朝着缩小Loss的方向更新可变换参数 θ \theta θ,故最终会迫使网络将图片中的数字朝上正立放置。
- 插入STN的之后的重组网络会有一定的表现力提升,总体而言STN带来的变换校正还是值得去使用的,并且STN本身是个轻量级网络,也不会太损害原本网络的训练速度。
6 Pytorch实现
PyTorch提供了STN层的实现方式,具体点这里。
简单解释一下:

如上图所示:
①:浅层特征提取:这部分就是STN之前的处理过程,将输入图像转换为feature map。
②:这就是Localisation network:通过设置2个全连接层来学习输入future map的变换信息(注意输入是经过特征提取之后的,而不是 U U U),输出一个变换矩阵 θ \theta θ,显然这里只做了仿射变换,是个 3 × 2 3\times 2 3×2的张量。
③:将self.fc_loc回归出的 θ \theta θ进行reshape成 2 × 3 2\times 3 2×3的标准仿射变换矩阵。
④:这就是Parameterised Sampling Grid:输入为变换矩阵和输出feature map的坐标(用x.size()也是一样的,都是为了获取 V V V的大小),输出一个grid,这个grid记录了输出feature map在坐标 ( x i t , y j t ) (x_i^t,y_j^t) (xit,yjt)对应到输入feature map(注意是对应到 U U U,即上述代码中的输入变量x,而不是对应到经过特征提取之后的feature map,即上述代码中的xs)上的坐标 ( x i s , y j s ) (x_i^s,y_j^s) (xis,yjs)。并且这里是令 ( H ′ , W ′ ) = ( H , W ) (H’,W’) = (H,W) (H′,W′)=(H,W),所以写 x . s i z e ( ) x.size() x.size()也能表示输出feature map的大小。
⑤:这就是Differentiable Sampling:通过上一步的grid,找出在输入 V V V上相应坐标下的像素值,如果不是整像素格点,就通过内部实现的插值(PyTorch默认是双线性插值)去填充到输出 V V V上去,最后输出 V V V即可。
⑥:这部分就是STN后续处理的过程,这里是进行深层特征提取然后做分类,可以预测出STN的加入会使得这部分的训练更加容易,提取到更好的特征。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180376.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
