大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
PR曲线
混淆矩阵
| 预测 \真实 | P | N |
|---|---|---|
| P | TP | FP |
| N | FN | TN |
查准率和查全率
查准率,表示所有被预测为正类的样本(TP+FP)是真正类(TP)的比例:
P = T P T P + F P P= \frac{TP}{TP+FP} P=TP+FPTP
查全率,表示所有真正类的样本(TP+FN)中被预测为真正类(TP)的比例:
R = T P T P + F N R= \frac{TP}{TP+FN} R=TP+FNTP
PR曲线绘制
PR曲线的横坐标为召回率R,纵坐标为查准率P
- 将预测结果按照预测为正类概率值排序
- 将阈值由1开始逐渐降低,按此顺序逐个把样本作为正例进行预测,每次可以计算出当前的P,R值
- 以P为纵坐标,R为横坐标绘制图像
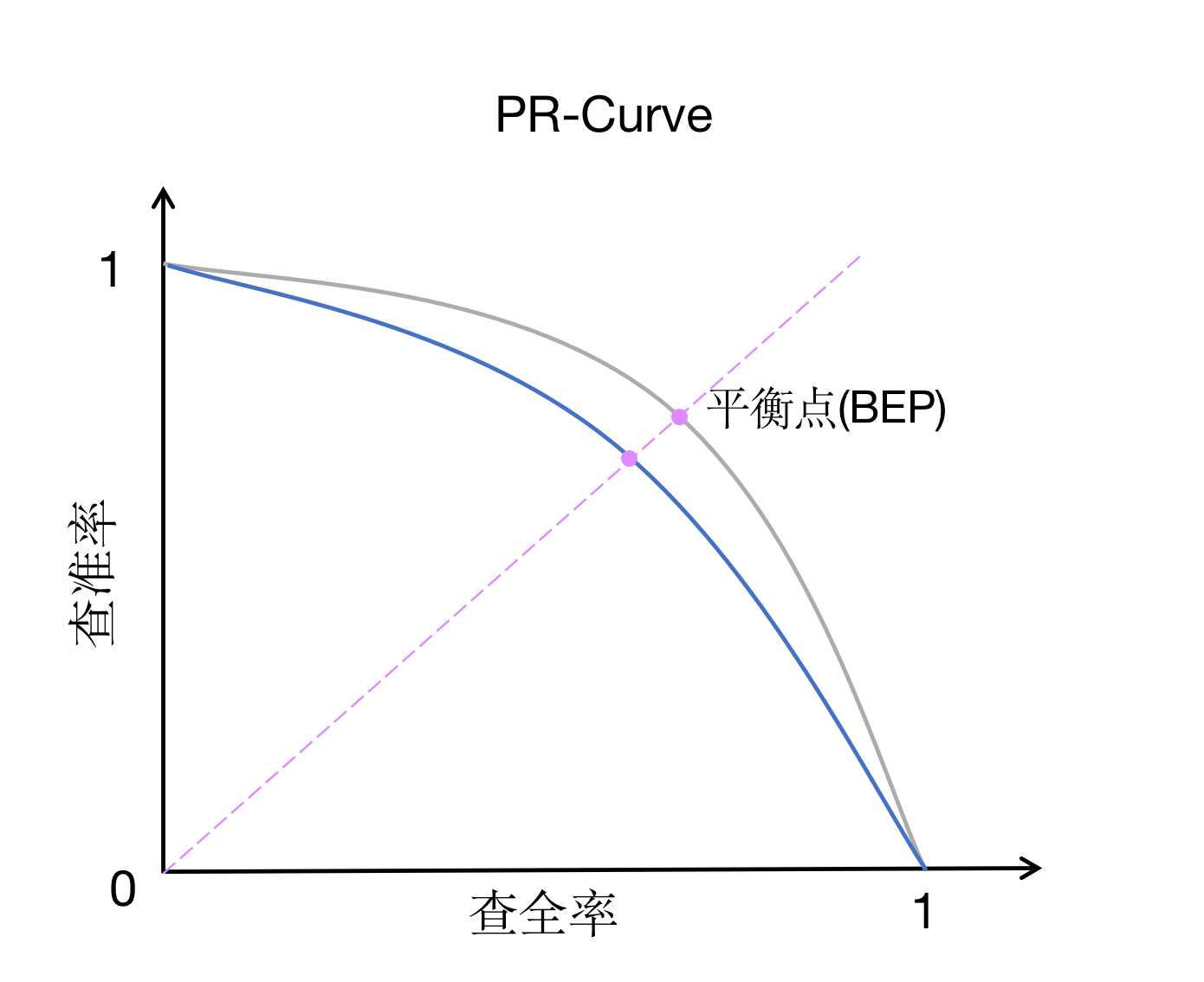

如何利用PR曲线对比性能:
- 如果一条曲线完全“包住”另一条曲线,则前者性能优于另一条曲线。
- PR曲线发生了交叉时:以PR曲线下的面积作为衡量指标,但这个指标通常难以计算
- 使用 “平衡点”(Break-Even Point),他是查准率=查全率时的取值,值越大代表效果越优
- BEP过于简化,更常用的是F1度量:
F 1 = 2 ∗ P ∗ R P + R = 2 ∗ T P 样 本 总 数 + T P − T N F1= \frac{2*P*R}{P+R}=\frac{2*TP}{样本总数+TP-TN} F1=P+R2∗P∗R=样本总数+TP−TN2∗TP
ROC曲线
AUC就是衡量学习器优劣的一种性能指标。从定义可知,AUC可通过对ROC曲线下各部分的面积求和而得。
TPR和FPR
真阳性率: T P R = T P T P + F N TPR= \frac{TP}{TP+FN} TPR=TP+FNTP
假阳性率: F P R = F P F P + T N FPR= \frac{FP}{FP+TN} FPR=FP+TNFP
ROC曲线绘制
ROC曲线的横坐标为FPR,纵坐标为TPR
- 将预测结果按照预测为正类概率值排序
- 将阈值由1开始逐渐降低,按此顺序逐个把样本作为正例进行预测,每次可以计算出当前的FPR,TPR值
- 以TPR为纵坐标,FPR为横坐标绘制图像
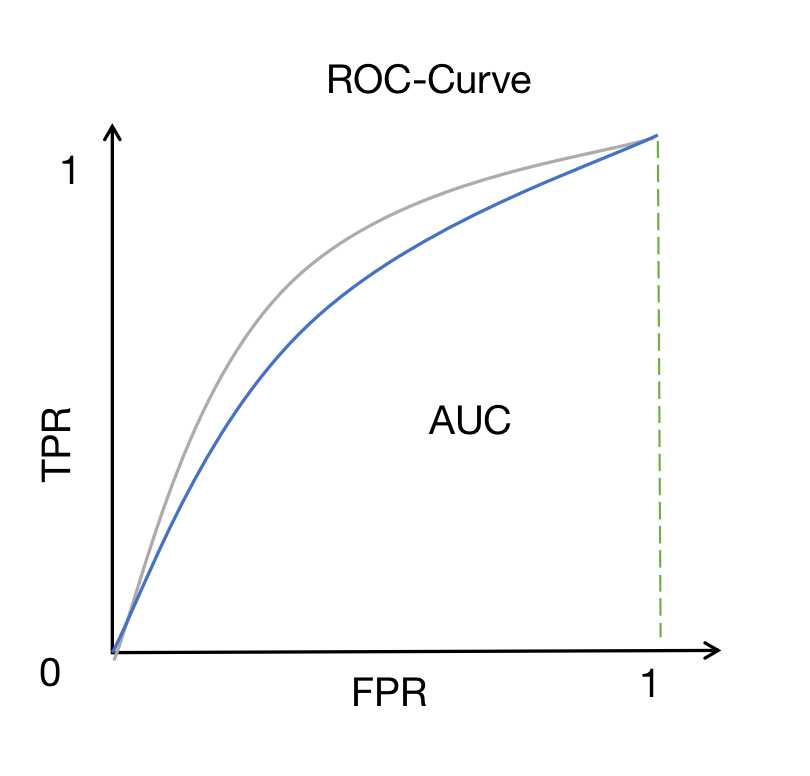
如何利用ROC曲线对比性能:
ROC曲线下的面积(AUC)作为衡量指标,面积越大,性能越好
AUC的计算
AUC就是衡量学习器优劣的一种性能指标。从定义可知,AUC可通过对ROC曲线下各部分的面积求和而得。 AUC的统计意义是从所有正样本随机抽取一个正样本,从所有负样本随机抽取一个负样本,对应的预测probability中该正样本排在负样本前面的概率。
计算原理:所有的样本对中被正确排序的样本对(正类排在负类前面)的比例。
- 设正样本M个,负样本N个,样本总量n。
- 计算预测结果中每个样本的rank值,及升序排列后的位置,probability最大的样本rank为n。
- 当一个正样本在正类预测结果的升序排列中排在第k位,则证明它与排在其后面的负样本构成了正确排序对,则所有正确排序的样本对的总和为:
举个例子:
例如 ( r a n k 0 − 1 ) (rank_0-1) (rank0−1)表示rank最小的正例可以和 r a n k 0 − 1 rank_0-1 rank0−1个负样本构成正确样本对。
C o r r e c t P a i r = ( r a n k 0 − 1 ) + ( r a n k 1 − 2 ) + . . . + ( r a n k i − ( i + 1 ) ) + . . + ( r a n k M − 1 − M ) = ∑ i ∈ 正 样 本 集 合 r a n k i − ∑ ( M + ( M − 1 ) + . . . + 1 ) = ∑ i ∈ 正 样 本 集 合 r a n k i − M ∗ ( M + 1 ) 2 CorrectPair = (rank_0-1) + (rank_1-2)+…\\ +(rank_i-(i+1))+..+(rank_{M-1}-M)\\ = \sum_{i\in 正样本集合}{rank_i}-\sum(M+(M-1)+…+1)\\ =\sum_{i\in 正样本集合}{rank_i}-\frac{M*(M+1)}{2} CorrectPair=(rank0−1)+(rank1−2)+...+(ranki−(i+1))+..+(rankM−1−M)=i∈正样本集合∑ranki−∑(M+(M−1)+...+1)=i∈正样本集合∑ranki−2M∗(M+1)
则AUC计算公式为:
A U C = C o r r e c t P a i r M ∗ N AUC=\frac{CorrectPair}{M*N} AUC=M∗NCorrectPair
python 代码实现及注解
def cacu_auc(label, prob):
''' :param label: 样本的真实标签 :param prob: 分类模型的预测概率值,表示该样本为正类的概率 :return: 分类结果的AUC '''
# 将label 和 prob组合,这样使用一个key排序时另一个也会跟着移动
temp = list(zip(label, prob))
# 将temp根据prob的概率大小进行升序排序
rank = [val1 for val1, val2 in sorted(temp, key=lambda x: x[1])]
# 将排序后的正样本的rank值记录下来
rank_list = [i+1 for i in range(len(rank)) if rank[i]==1]
# 计算正样本个数m
M = sum(label)
# 计算负样本个数N
N=len(label)-M
return (sum(rank_list)-M*(M+1)/2)/(M*N)
类别不平衡问题
这里特指负样本数量远大于正样本时,在这类问题中,我们往往更关注正样本是否被正确分类,即TP的值。PR曲线更适合度量类别不平衡问题中:
- 因为在PR曲线中TPR和FPR的计算都会关注TP,PR曲线对正样本更敏感。
- 而ROC曲线正样本和负样本一视同仁,在类别不平衡时ROC曲线往往会给出一个乐观的结果。
参考
[1]: https://blog.csdn.net/ft_sunshine/article/details/108833761
[2]: 《机器学习》周志华
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179653.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
