大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
现在很多文章开始出现这样的一种情况,在绘制火山图中,显示我们所关注的基因,那么如何去显示呢?很多人可能会这么做,在绘制普通的火山图之后,使用AI对图进行修改,添加部分基因,但是现在我要介绍的是如何用R绘制
library(ggpubr)
library(ggthemes)
data <- read.csv(“easy_input_limma.csv”, head=T,sep=’,’)
#绘制基本热图
data l o g p < − − l o g 10 ( d a t a logp <- -log10(data logp<−−log10(dataadj.P.Val)
ggscatter(data,x=“logFC”,y=“logp”)+theme_base()
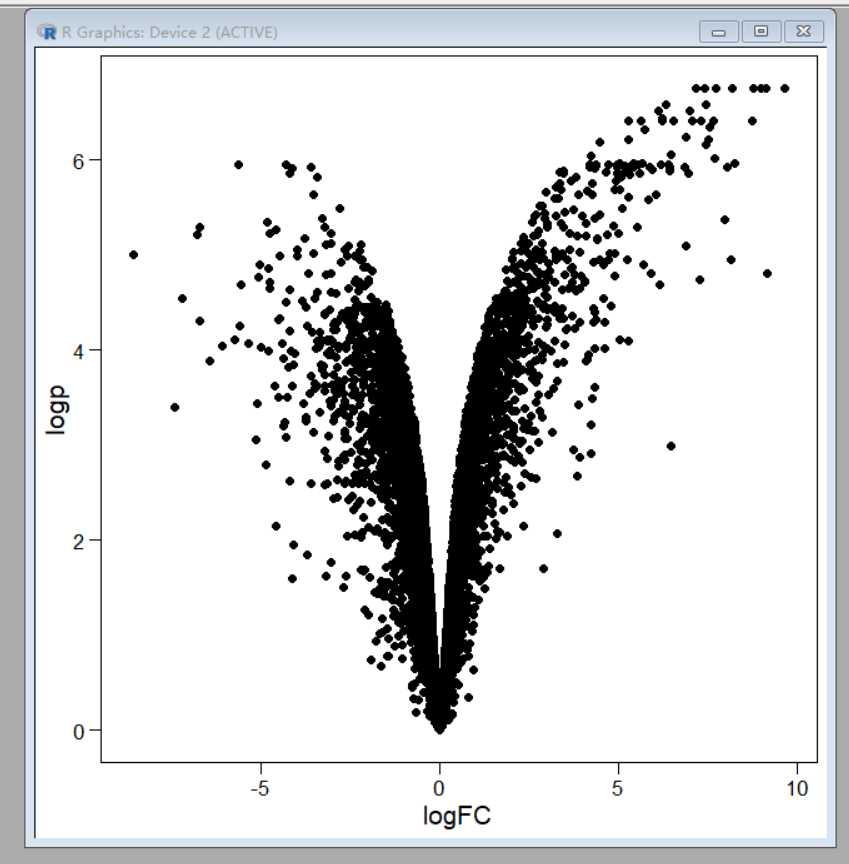

#新增一列,选出上调和下调
data G r o u p = " n o t − s i g n i f i c a n t " d a t a Group="not-significant" data Group=“not−significant“dataGroup[which((dataKaTeX parse error: Expected ‘EOF’, got ‘&’ at position 16: adj.P.Val<0.05)&̲(datalogFC > 2))]=“up-regulated”
data G r o u p [ w h i c h ( ( d a t a Group[which((data Group[which((dataadj.P.Val<0.05)&(dataKaTeX parse error: Expected ‘EOF’, got ‘#’ at position 32: …own-regulated” #̲查看上调和下调的基因个数 ta…Group)
#绘制新的火山图
ggscatter(data,x=“logFC”,y=“logp”,color=“Group”)+theme_base()
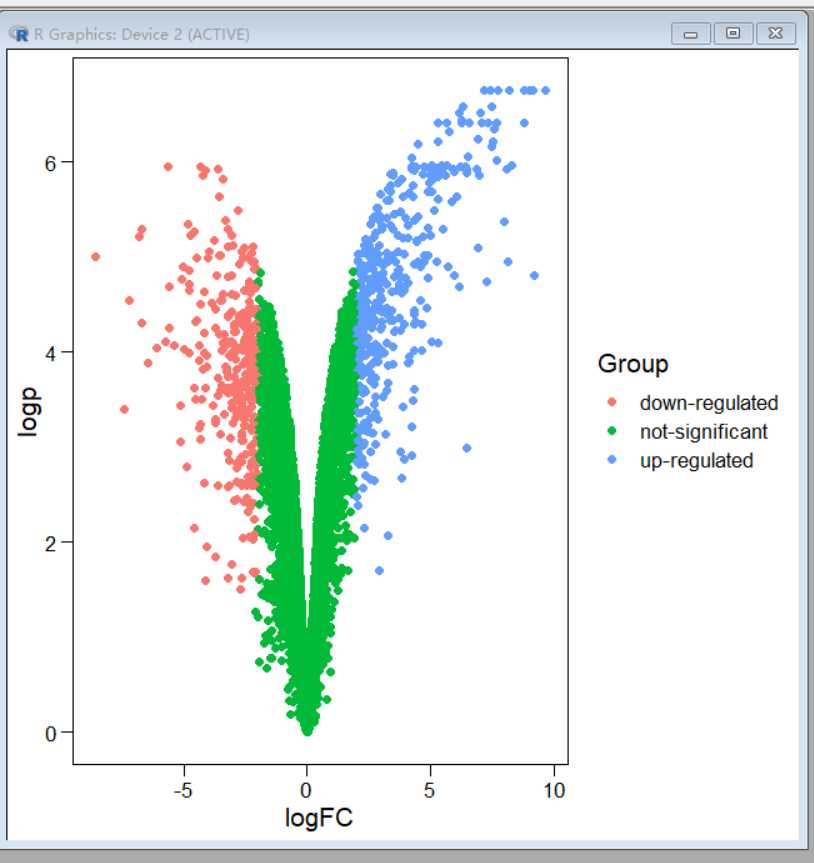
#添加颜色和点的大小
ggscatter(data,x=“logFC”,y=“logp”,color=“Group”,palette=c(
“blue”,“gray”,“red”),size=1)+theme_base()
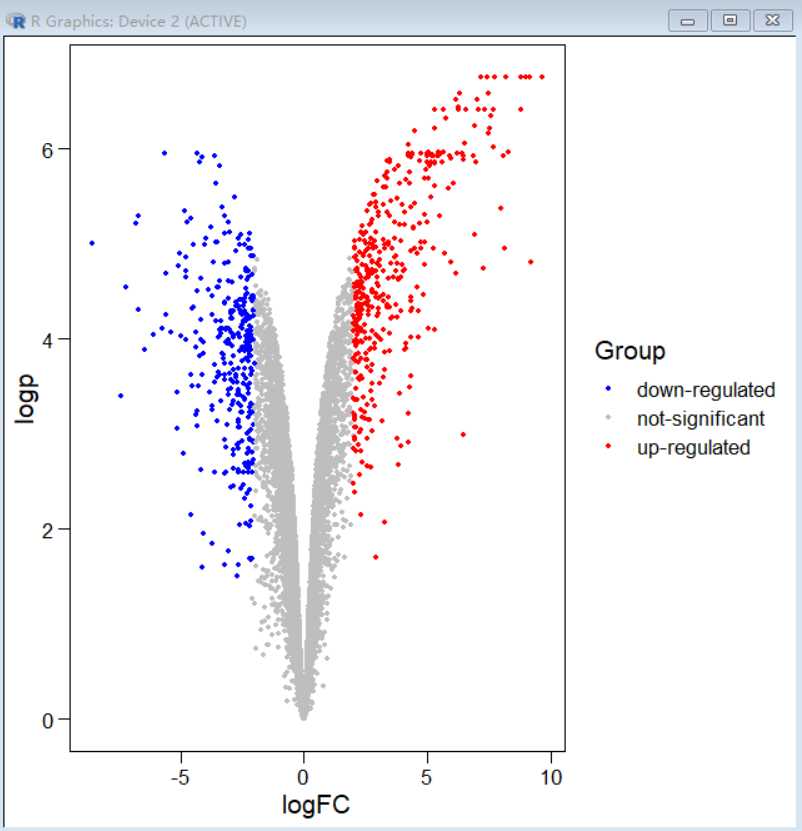
ggscatter(data,x=“logFC”,y=“logp”,color=“Group”,palette=c(
“blue”,“gray”,“red”),size=1)+theme_base()+geom_hline(yintercept=1.3,
linetype=“dashed”)+geom_vline(xintercept=c(-2,2),linetype=“dashed”)
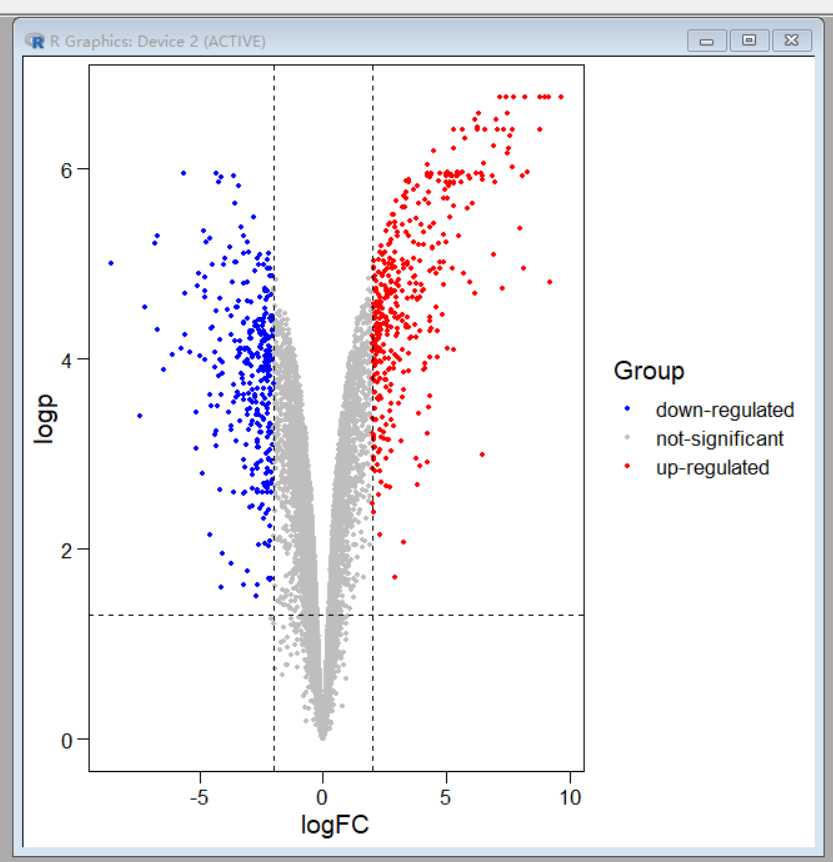
#新增一列,这一列是需要展示的基因名在这里我展示前10
data l a b e l = " " d a t a < − d a t a [ o r d e r ( d a t a label="" data<-data[order(data label=““data<−data[order(datalogp),]
#data S y m b o l < − r o w n a m e s ( d a t a ) u p . g e n e < − h e a d ( d a t a Symbol<-rownames(data) up.gene<-head(data Symbol<−rownames(data)up.gene<−head(dataSymbol[which(data G r o u p = = " u p − r e g u l a t e d " ) ] , 10 ) d o w n . g e n e < − h e a d ( d a t a Group=="up-regulated")],10) down.gene<-head(data Group==“up−regulated“)],10)down.gene<−head(dataSymbol[which(dataKaTeX parse error: Expected ‘EOF’, got ‘#’ at position 31: …gulated”)],10) #̲将up.gene和down.g…label[match(data.top.genes,dataKaTeX parse error: Expected ‘EOF’, got ‘#’ at position 26: …data.top.genes #̲重新绘制 ggscatter(…label,font_label=8,repel=T)+theme_base()+geom_hline(yintercept=0.05,
linetype=“dashed”)+geom_vline(xintercept=c(-2,2),linetype=“dashed”)
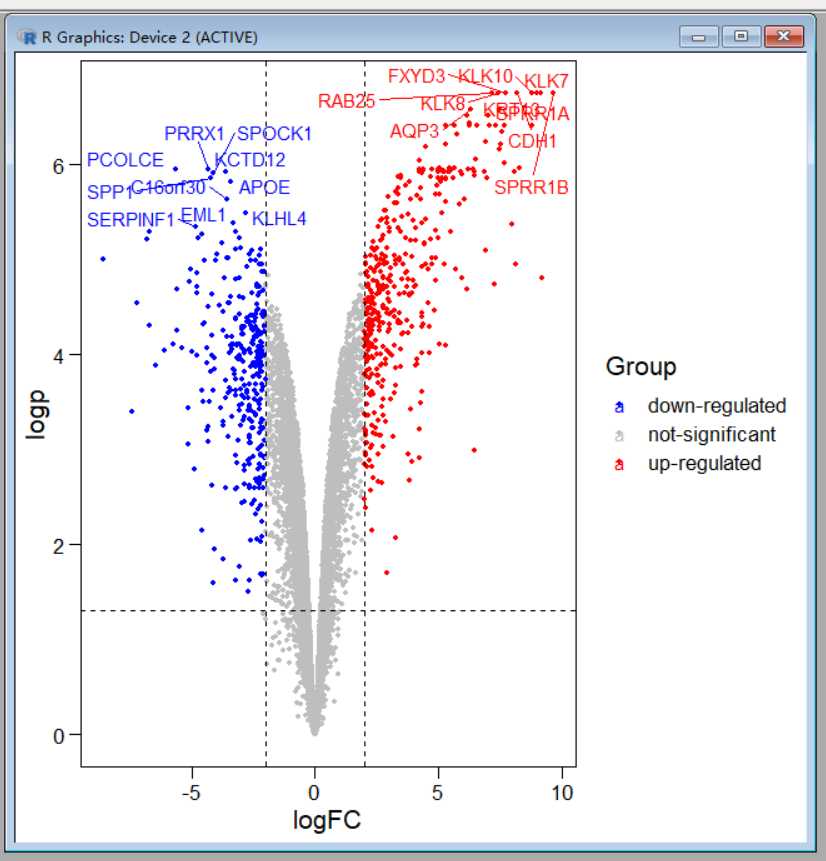
很多人会说,这样的终究不太分明,我想让点的大小来反映FC,这样可以做到吗?当然可以了!如果有想了解的,可以试试,其实很简单的。
最近看到一个更加强大的包,绘制的火山图更加好看
EnhancedVolcano包
1、首先安装这个包
if (!requireNamespace(‘devtools’, quietly = TRUE))
install.packages(‘devtools’)
devtools::install_github(‘kevinblighe/EnhancedVolcano’)
加载包
library(EnhancedVolcano)
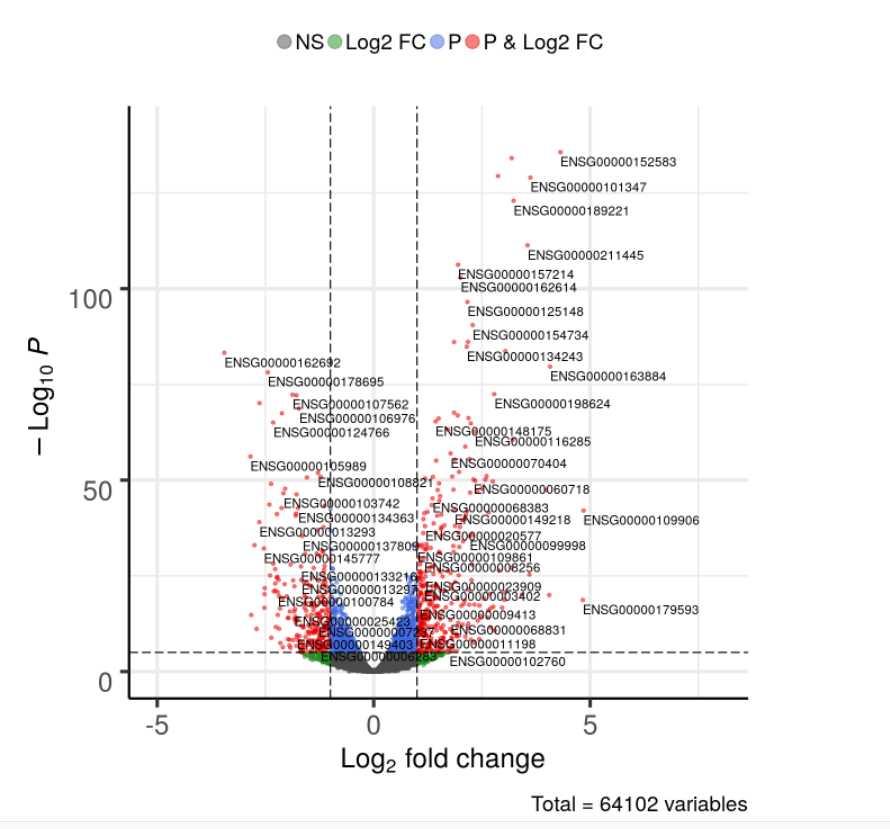
#res1是带有基因ID的列名,log2FoldChange是去过对数的差异倍数的列名,pvalue可以选择是校正前和校正后的,xlim是对log2FoldChange的范围进行限定
EnhancedVolcano(res1, lab = rownames(res1), x = ‘log2FoldChange’, y = ‘pvalue’,xlim = c(-5, 8))
绘制之后就是这样了
2、 还可以通过这个包直接修改点的大小和标签的大小
#title图片的名称, transcriptPointSize点的大小, transcriptLabSize标签的大小
EnhancedVolcano(res2,lab = rownames(res2), x = ‘log2FoldChange’,y = ‘pvalue’,
xlim = c(-8, 8),title = ‘N061011 versus N61311’,pCutoff = 10e-16,
FCcutoff = 1.5, transcriptPointSize = 1.5,transcriptLabSize = 3.0)
3、调整点的颜色和透明度
#colAlpha点的透明度,col是点的颜色,默认第一个是NS,第二个是log2FC,第三个是P,第四个是p&log2FC
EnhancedVolcano(res2, lab = rownames(res2),x = ‘log2FoldChange’,
y = ‘pvalue’,xlim = c(-8, 8),title = ‘N061011 versus N61311’, pCutoff = 10e-16,
FCcutoff = 1.5, transcriptPointSize = 1.5, transcriptLabSize = 3.0,
col=c(“grey30”, “forestgreen”, “royalblue”, “red2”), colAlpha = 1)
4、修改点的形状
shape点的形状,可以选择一个,也可以选择多个
选择一个形状
EnhancedVolcano(res2, lab = rownames(res2),x = ‘log2FoldChange’,
y = ‘pvalue’,xlim = c(-8, 8),title = ‘N061011 versus N61311’, pCutoff = 10e-16,
FCcutoff = 1.5, transcriptPointSize = 1.5, transcriptLabSize = 3.0,shape=4,
col=c(“grey30”, “forestgreen”, “royalblue”, “red2”), colAlpha = 1)
选择多个形状
EnhancedVolcano(res2, lab = rownames(res2),x = ‘log2FoldChange’,
y = ‘pvalue’,xlim = c(-8, 8),title = ‘N061011 versus N61311’, pCutoff = 10e-16,
FCcutoff = 1.5, transcriptPointSize = 1.5, transcriptLabSize = 3.0,shape=c(1,4,23,25),col=c(“grey30”, “forestgreen”, “royalblue”, “red2”), colAlpha = 1)
5、添加额外的阈值线,自定义阈值线,可以自己查看文档
hlineType线条的类型(平行于x轴),vline—是平行于Y轴的
cutoffLineCol线条的颜色,cutoffLineWidth线条的粗细
EnhancedVolcano(res2,lab = rownames(res2), x = ‘log2FoldChange’,y = ‘pvalue’,
xlim = c(-6, 6),title = ‘N061011 versus N61311’,pCutoff = 10e-12,FCcutoff = 1.5,transcriptPointSize = 1.5,transcriptLabSize = 3.0,colAlpha = 1,
cutoffLineType = ‘blank’,cutoffLineCol = ‘black’, cutoffLineWidth = 0.8,
hline = c(10e-12, 10e-36, 10e-60, 10e-84),
hlineCol = c(‘grey0’, ‘grey25’,‘grey50’,‘grey75’),
hlineType = ‘longdash’,hlineWidth = 0.8,gridlines.major = FALSE,gridlines.minor = FALSE)
6、调整图例
#legend图例内容,legendPosition图例的位置,legendLabSize文字的大小
legendIconSize标签的大小
EnhancedVolcano(res2,lab = rownames(res2),x = ‘log2FoldChange’,y = ‘pvalue’,
xlim = c(-6, 6),pCutoff = 10e-12, FCcutoff = 1.5,cutoffLineType = ‘twodash’,cutoffLineWidth = 0.8,transcriptPointSize = 3.0,transcriptLabSize = 4.0,
colAlpha = 1,legend=c(‘NS’,‘Log (base 2) fold-change’,‘P value’, ‘P value & Log (base 2) fold-change’), legendPosition = ‘right’,legendLabSize = 16,legendIconSize = 5.0)
详细的请查看说明文档
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179441.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
