大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Redis主从复制
主从复制简介
主从复制是为了达成高可用
- 为了避免单点Redis服务器故障,准备多台服务器,互相连通。将数据复制多个副本保存在不同的服
务器上,连接在一起,并保证数据是同步的。 - 即使有其中一台服务器宕机,其他服务器依然可以继续提供服务,实现Redis的高可用,同时实现数据冗余备份。

-
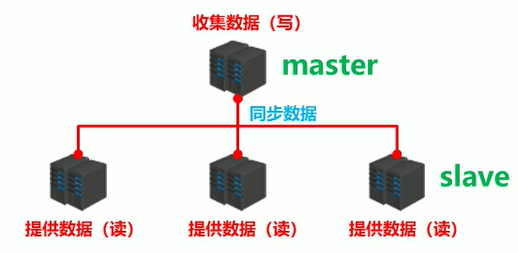
提供数据方:master
- 主服务器,主节点,主库
主客户端
- 主服务器,主节点,主库
-
接收数据方:slave
- 从服务器,从节点,从库
从客户端
- 从服务器,从节点,从库
-
需要解决的问题
- 数据同步
-
核心工作
- master的数据复制到slave中
主从复制
-
主从复制即将master中的数据即时、有效的复制到slave中
-
一个master可以拥有多个slave,一个slave只对应一个master
-
职责
-
master:
- 写数据
- 执行写操作时,将出现变化的数据自动同步到slave
- 读数据(可忽略)
-
slave:
- 读数据
- 写数据(禁止)
-
主从复制的概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower) ; 数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave以读为主。
默认情况下,每台Redis服务器都是主节点 ;
且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用
-
读写分离:主节点写,从节点读,提高服务器的读写负载能力
-
数据冗余︰主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
-
故障恢复︰当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复 ; 实际上是一种服务的冗余。
-
负载均衡︰在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载 ; 尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
-
高可用(集群)基石︰除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从复制工作流程
总述
- 主从复制过程大体可以分为3个阶段
- 建立连接阶段(即准备阶段)
- 数据同步阶段
- 命令传播阶段
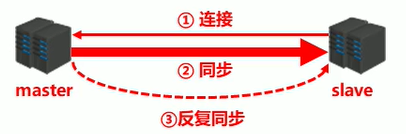
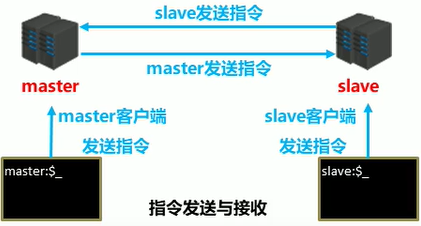
阶段一:建立连接阶段
- 建立slave到master的连接,使master能够识别slave,并保存slave端口号
- 设置master的地址和端口,保存master信息
- 建立socket连接
- 发送ping命令(定时器任务)
- 身份验证
- 发送slave端口信息
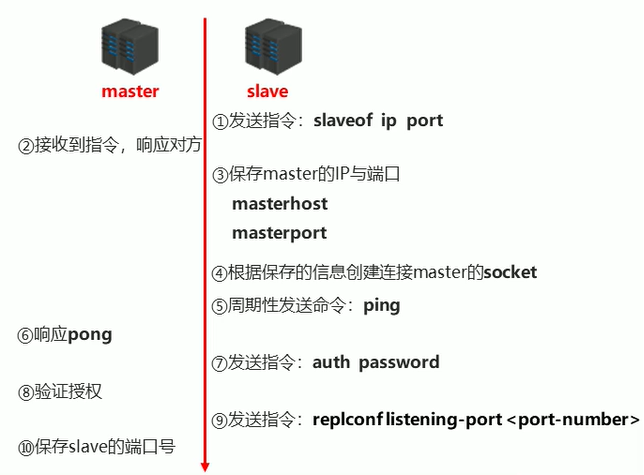
slave:保存master的地址和端口
master:保存slave的端口
总体:之间创建了socket连接
主从连接(slave连接master)
-
方式一:客户端发送命令
slaveof <masterip> <masterport> -
方式二:启动服务器参数
redis-server -slaveof <masterip> <masterport> -
方式三:服务器配置
vim redis.conf slaveof <masterip> <masterport>
第一种方式
打开redis服务端
redis-server redis_config/redis-6379.conf # 主机
redis-server redis_config/redis-6380.conf # 从机
进入从机
[root@maomao bin]# redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379
查看主机日志信息
Synchronization with replica 127.0.0.1:6380 succeeded
查看从机日志信息
MASTER <-> REPLICA sync: receiving 361 bytes from master to disk
2125:S 18 Apr 2021 09:27:01.525 * MASTER <-> REPLICA sync: Flushing old data
2125:S 18 Apr 2021 09:27:01.525 * MASTER <-> REPLICA sync: Loading DB in memory
说明主从已经配置完毕
测试
在主节点创建一个key
127.0.0.1:6379> set master maomao
OK
在从节点查看
127.0.0.1:6380> get master
"maomao"
还可以通过 info replication 命令查看
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
第二种方式
在命令行直接连接
[root@maomao bin]# redis-server redis_config/redis-6380.conf --slaveof 127.0.0.1 6379
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
第三种方式
[root@maomao redis_config]# vim redis-6380.conf
添加
slaveof 127.0.0.1 6379
启动redis
[root@maomao bin]# redis-server redis_config/redis-6380.conf
[root@maomao bin]# redis-cli -p 6380
127.0.0.1:6380> get slave
"xiaotian"
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
-
主从断开连接
客户端发送命令
slaveof no one -
slave断开连接后,不会删除已有数据,只是不再接受master发送的数据
在从机上
127.0.0.1:6380> slaveof no one
OK
127.0.0.1:6379> set slave maomao
OK
127.0.0.1:6380> get slave
"xiaotian"
授权访问
-
master客户端发送命令设置密码
requirepass <password> -
master配置文件设置密码
config set requirepass <password> config get requirepass -
slave客户端发送命令设置密码
auth <password> -
slave配置文件设置密码
masterauth <password> -
slave启动服务器设置密码
redis-server –a <password>
阶段二:数据同步阶段工作流程
- 在slave初次连接master后,复制master中的所有数据到slave
- 将slave的数据库状态更新成master当前的数据库状态
部分复制就是增量复制
增量复制需要在全量复制成功之后才能执行
- 请求同步数据
- 创建RDB同步数据
- 恢复RDB同步数据
- 请求部分同步数据
- 恢复部分同步数据
至此,数据同步工作完成!
状态:
- slave:
具有master端全部数据,包含RDB过程接收的数据 - master:
保存slave当前数据同步的位置 - 总体:
之间完成了数据克隆
数据同步阶段master说明
- 如果master数据量巨大,数据同步阶段应避开流量高峰期,避免造成master阻塞,影响业务正常执行
- 复制缓冲区大小设定不合理,会导致数据溢出。如进行全量复制周期太长,进行部分复制时发现数据已
经存在丢失的情况,必须进行第二次全量复制,致使slave陷入死循环状态。
修改复制缓冲区大小
repl-backlog-size 1mb # 默认1mb
- master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,留下30%-50%的内存用于执行bgsave命令和创建复制缓冲区
数据同步阶段slave说明
-
为避免slave进行全量复制、部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
slave-serve-stale-data yes|no -
数据同步阶段,master发送给slave信息可以理解master是slave的一个客户端,主动向slave发送命令
-
多个slave同时对master请求数据同步,master发送的RDB文件增多,会对带宽造成巨大冲击,如果master带宽不足,因此数据同步需要根据业务需求,适量错峰
-
slave过多时,建议调整拓扑结构,由一主多从结构变为树状结构,中间的节点既是master,也是slave。注意使用树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟较大,数据一致性变差,应谨慎选择
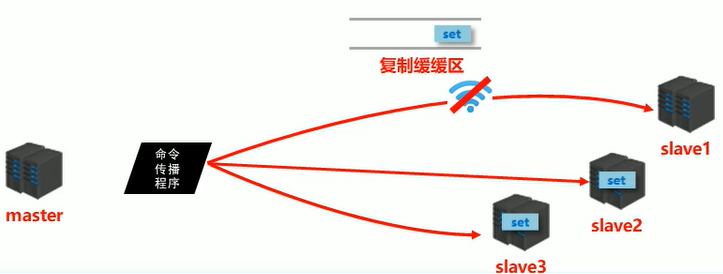
阶段三:命令传播阶段
-
当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作称为命令传播
-
master将接收到的数据变更命令发送给slave,slave接收命令后执行命令
-
主从复制过程大体可以分为3个阶段
- 建立连接阶段(即准备阶段)
- 数据同步阶段
- 命令传播阶段
命令传播阶段的部分复制
- 命令传播阶段出现了断网现象
- 网络闪断闪连 …忽略
- 短时间网络中断 …部分复制
- 长时间网络中断 …全量复制
- 部分复制的三个核心要素
- 服务器的运行 id(run id)
- 主服务器的复制积压缓冲区
- 主从服务器的复制偏移量
服务器的运行 id
- 概念:服务器运行ID是每一台服务器每次运行的身份识别码,一台服务器多次运行可以生成多个运行id
- 组成:运行id由40位字符组成,是一个随机的十六进制字符
- 例如:0eab876073ab904a4b357000dc8f231f553c20a7
- 作用:运行id被用于在服务器间进行传输,识别身份
- 如果想两次操作均对同一台服务器进行,必须每次操作携带对应的运行id,用于对方识别
- 实现方式:运行id在每台服务器启动时自动生成的,master在首次连接slave时,会将自己的运行ID发送给slave,slave保存此ID,通过
info Server命令,可以查看节点的runid
复制缓冲区
- 概念:复制缓冲区,又名复制积压缓冲区,是一个==先进先出(FIFO)==的队列,用于存储服务器执行过的命令,每次传播命令,master都会将传播的命令记录下来,并存储在复制缓冲区
复制缓冲区内部工作原理
-
组成
- 偏移量
- 字节值
-
工作原理
- 通过offset区分不同的slave当前数据传播的差异
- master记录已发送的信息对应的offset
- slave记录已接收的信息对应的offset
set name maomao
以这种格式
$3 \r\n
set \r\n
$4 \r\n
name \r\n
$6 \r\n
maomao \r\n
到复制缓冲区

复制缓冲区
- 概念:复制缓冲区,又名复制积压缓冲区,是一个==先进先出(FIFO)==的队列,用于存储服务器执行过的命令,每次传播命令,master都会将传播的命令记录下来,并存储在复制缓冲区
- 复制缓冲区默认数据存储空间大小是1M,由于存储空间大小是固定的,当入队元素的数量大于队列长度时,最先入队的元素会被弹出,而新元素会被放入队列
- 由来:每台服务器启动时,如果开启有AOF或被连接成为master节点,即创建复制缓冲区
- 作用:用于保存master收到的所有指令(仅影响数据变更的指令,例如set,select)
- 数据来源:当master接收到主客户端的指令时,除了将指令执行,会将该指令存储到缓冲区中
主从服务器复制偏移量(offset)
- 概念:一个数字,描述复制缓冲区中的指令字节位置
- 分类:
- master复制偏移量:记录发送给所有slave的指令字节对应的位置(多个)
- slave复制偏移量:记录slave接收master发送过来的指令字节对应的位置(一个)
- 数据来源:
- master端:发送一次记录一次
slave端:接收一次记录一次
- master端:发送一次记录一次
- 作用:同步信息,比对master与slave的差异,当slave断线后,恢复数据使用
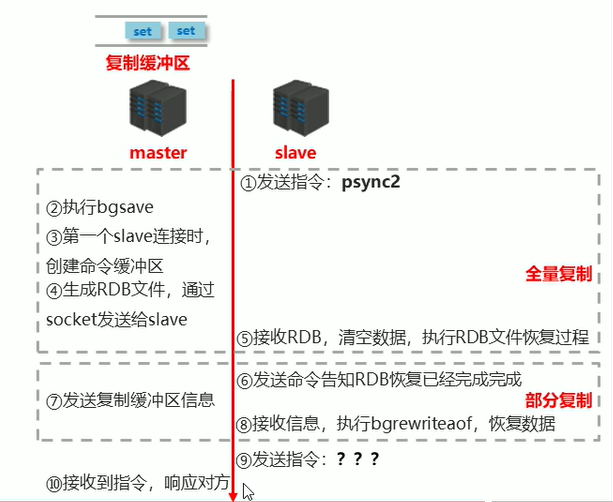
数据同步+命令传播阶段工作流程
主从连接之后
- master生成复制缓冲区
- slave发送指令:psync2 ? -1 (意思需要全部信息)
- master接收到指令,执行bgsave生成RDB文件,记录当前的复制偏移量
offset但是因为第一次slave发送的是空白。 - 于是master将runid 和offset发给slave。发送 +FULLRESYNC
runidoffset,(全量复制),通过socket发送RDB文件给slave - slave收到 +FULLRESYNC(全量复制),保存master的
runid和offset,清空当前全部数据,通过socket接收RDB文件,恢复RDB数据 - 在整个过程中有一些指令要进入复制缓冲区,master接收这些客户端指令,offset发生了变化
- slave 发送命令:psync2 runid offset
- master 接收命令,判断runid是否匹配,判定offset是否在复制缓冲区中
- 如果runid或offset有一个不满足,执行全量复制(循环之前的全量复制)
- 如果runid或offset校验通过,offset与
offset相同,则忽略 - 如果如果runid或offset校验通过,offset与
offset不相同。
就发送 +CONTINUEoffset。
通过socket发送复制缓冲区中offset到offset的数据 - slave 收到 +CONTINE
保存master的offset
接收到信息后,执行bgrewriteaof,恢复数据

心跳机制
-
进入命令传播阶段候,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线
-
master心跳:
- 指令:PING
- 周期:由repl-ping-slave-period决定,默认10秒
- 作用:判断slave是否在线
- 查询:INFO replication 获取slave最后一次连接时间间隔,lag项维持在0或1视为正常
-
slave心跳任务
- 指令:REPLCONF ACK {offset}
- 周期:1秒
- 作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令
- 作用2:判断master是否在线
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=927,lag=1
心跳阶段注意事项
-
当slave多数掉线,或延迟过高时,master为保障数据稳定性,将拒绝所有信息同步操作
min-slaves-to-write 2 min-slaves-max-lag 8- slave数量少于2个,或者所有slave的延迟都大于等于10秒时,强制关闭master写功能,停止数据同步
-
slave数量由slave发送REPLCONF ACK命令做确认
-
slave延迟由slave发送REPLCONF ACK命令做确认
主从复制常见问题
引发频繁的全量复制1
伴随着系统的运行,master的数据量会越来越大,一旦master重启,runid将发生变化,会导致全部slave的全量复制操作
- 内部优化调整方案:
- master内部创建master_replid变量,使用runid相同的策略生成,长度41位,并发送给所有slave
- 在master关闭时执行命令 shutdown save,进行RDB持久化,将runid与offset保存到RDB文件中
- repl-id repl-offset
- 通过redis-check-rdb命令可以查看该信息
- master重启后加载RDB文件,恢复数据
重启后,将RDB文件中保存的repl-id与repl-offset加载到内存中- master_repl_id = repl master_repl_offset = repl-offset
- 通过info命令可以查看该信息
- 作用:
本机保存上次runid,重启后恢复该值,使所有slave认为还是之前的master
[root@maomao redis_config]# cd /usr/local/redis/data/
[root@maomao data]# ls
6379.log 6380.log appendonly-6379.aof dump-6379.rdb dump.rdb
[root@maomao data]# redis-check-rdb dump-6379.rdb
[offset 0] Checking RDB file dump-6379.rdb
[offset 26] AUX FIELD redis-ver = '6.2.1'
[offset 40] AUX FIELD redis-bits = '64'
[offset 52] AUX FIELD ctime = '1618763025'
[offset 67] AUX FIELD used-mem = '1942304'
[offset 85] AUX FIELD repl-stream-db = '0'
[offset 135] AUX FIELD repl-id = '2d82ff022e405afb883753f4d0c52f8ceb36d740' # runid
[offset 151] AUX FIELD repl-offset = '885' #offset
[offset 167] AUX FIELD aof-preamble = '0'
[offset 169] Selecting DB ID 0
[offset 391] Checksum OK
[offset 391] \o/ RDB looks OK! \o/
[info] 5 keys read
[info] 0 expires
[info] 0 already expired
引发频繁的全量复制2
-
问题现象
- 网络环境不佳,出现网络中断,slave不提供服务
-
问题原因
- 复制缓冲区过小,断网后slave的offset越界,触发全量复制
-
最终结果
- slave反复进行全量复制
-
解决方案
- 修改复制缓冲区大小
repl-backlog-size
- 修改复制缓冲区大小
-
建议设置如下:
- 测算从master到slave的重连平均时长second
- 获取master平均每秒产生写命令数据总量write_size_per_second
- 最优复制缓冲区空间 = 2 * second * write_size_per_second
频繁的网络中断1
- 问题现象
- master的CPU占用过高 或 slave频繁断开连接
- 问题原因
- slave每1秒发送REPLCONF ACK命令到master
- 当slave接到了慢查询时(keys * ,hgetall等),会大量占用CPU性能
- master每1秒调用复制定时函数replicationCron(),比对slave发现长时间没有进行响应
- 最终结果
- master各种资源(输出缓冲区、带宽、连接等)被严重占用
- 解决方案
- 通过设置合理的超时时间,确认是否释放slave
repl-timeout
该参数定义了超时时间的阈值(默认60秒),超过该值,释放slave
- 通过设置合理的超时时间,确认是否释放slave
频繁的网络中断2
- 问题现象
- slave与master连接断开
- 问题原因
- master发送ping指令频度较低
- master设定超时时间较短
- ping指令在网络中存在丢包
- 解决方案
- 提高ping指令发送的频度
repl-ping-slave-period
超时时间repl-time的时间至少是ping指令频度的5到10倍,否则slave很容易判定超时
- 提高ping指令发送的频度
数据不一致
- 问题现象
- 多个slave获取相同数据不同步
- 问题原因
- 网络信息不同步,数据发送有延迟
- 解决方案
- 优化主从间的网络环境,通常放置在同一个机房部署,如使用阿里云等云服务器时要注意此现象
- 监控主从节点延迟(通过offset)判断,如果slave延迟过大,暂时屏蔽程序对该slave的数据访问
slave-serve-stale-data yes|no
开启后仅响应info、slaveof等少数命令(慎用,除非对数据一致性要求很高)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/170323.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
