大家好,又见面了,我是你们的朋友全栈君。
写在前面
本文隶属于专栏《100个问题搞定大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和文献引用请见100个问题搞定大数据理论体系
解答
大数据处理流程主要分为3步:
1.数据抽取和集成
2.数据分析
3.数据解释


补充
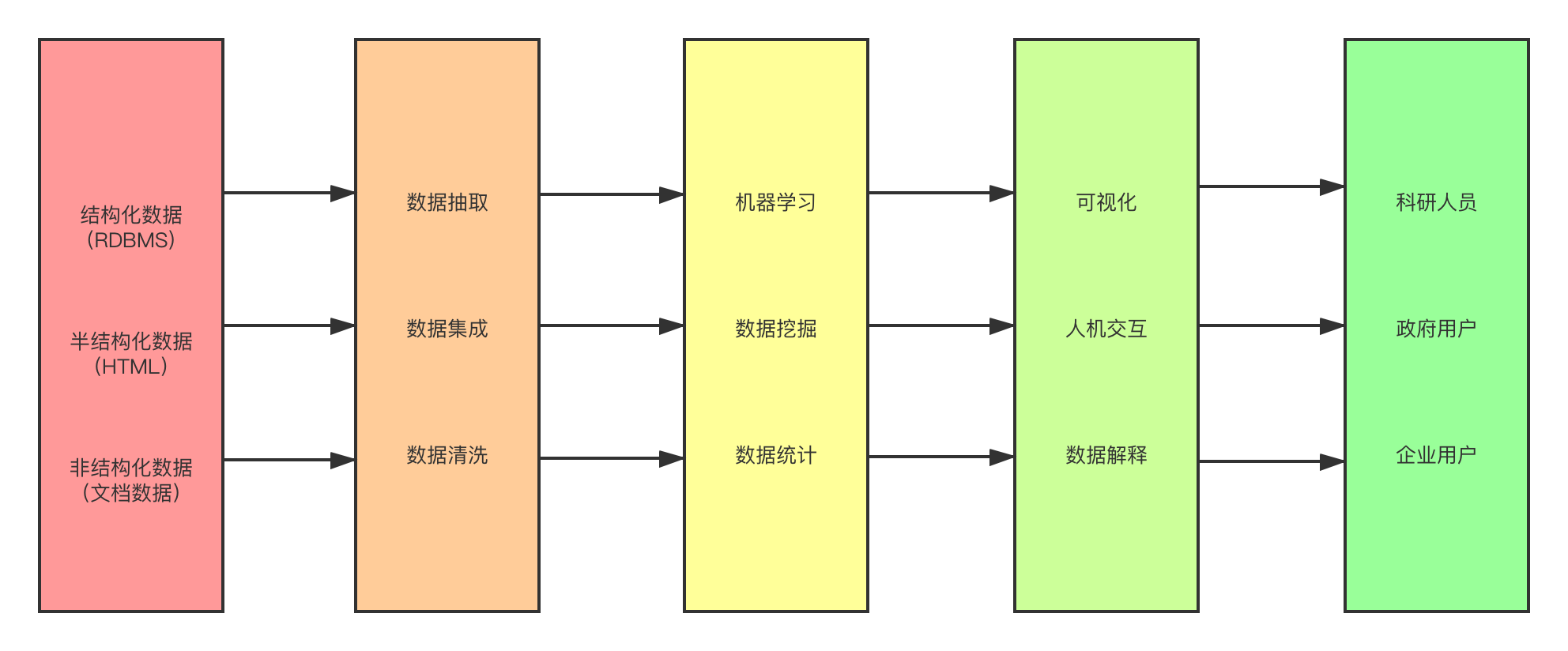
1.数据抽取与集成
由于大数据处理的数据来源类型丰富,利用多个数据库来接收来自客户端的数据, 包括企业内部数据库、互联网数据和物联网数据,所以需要从数据中提取关系和实体, 经过关联和聚合等操作,按照统一定义的格式对数据进行存储。 用户可以通过上述数据库来进行简单的查询和处理。
在大数据的采集过程中,并发数高是其主要的特点和挑战,因为成千上万的用户可能同时来进行访问和操作,比如火车票售票网站和新浪微博,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑,如何在这些数据库之间进行负载均衡和分片更是需要深入思考和设计的问题。
2.数据分析
待获取数据后,用户可以根据自己的需求对这些数据进行分析处理,如数据挖掘、机器学习、数据统计等。统计与挖掘主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求。分析涉及的数据量大是统计与分析这部分的主要特点和挑战,统计与分析对系统资源会有极大的占用。数据挖掘一般没有预先设定好的主题,主要是对现有数据进行各种算法的计算,从而起到预测的效果,然后实现高级别数据分析的需求。挖掘大数据价值的关键是数据分析环节。
3.数据解释
数据处理的结果是大数据处理流程中用户最关心的问题,正确的数据处理结果需要通过合适的展示方式被终端用户正确理解。数据解释的主要技术是可视化和人机交互。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127132.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
