大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
- ? 版权: 本文由【墨理学AI】原创、在CSDN首发、各位大佬、感谢查阅、感谢三连、感谢关注
基础参考资料
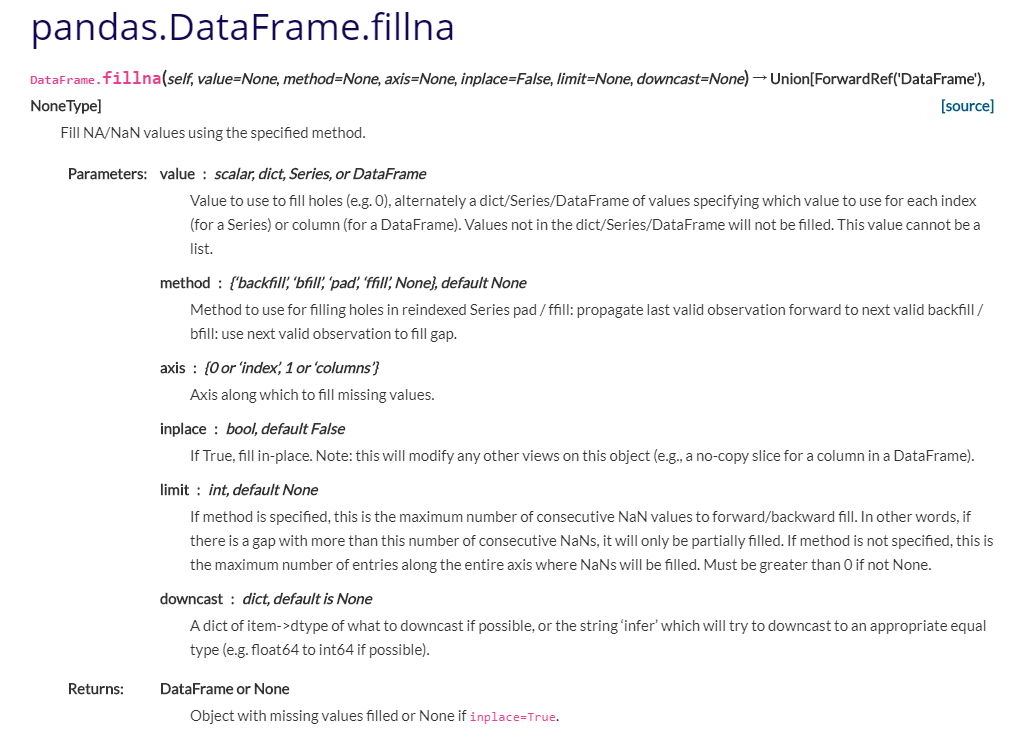

pandas中fillna()方法,能够使用指定的方法填充NA/NaN值。
函数详解
函数形式:fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
参数:
value:用于填充的空值的值。
method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
downcast:dict, default is None,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
返回值:
DataFrame or None
Object with missing values filled or None if inplace=True.
- 用均值进行填充:
for column in list(df.columns[df.isnull().sum() > 0]):
mean_val = df[column].mean()
df[column].fillna(mean_val, inplace=True)
- 用后一行的值进行填充NaN
print(df.fillna(method='backfill', axis=0, inplace=False))
- 我的测试代码如下:
import numpy as np
import pandas as pd
a = np.arange(100, dtype=float).reshape((10, 10))
a[0, 1] = np.nan
a[0, 3] = np.nan
a[0, 4] = np.nan
a[0, 6] = np.nan
a[3, 1] = np.nan
a[3, 3] = np.nan
a[3, 4] = np.nan
a[3, 6] = np.nan
df = pd.DataFrame(data=a)
# 重命名列名
df.columns = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
print(df)
# 筛选需要填充的列
print(df.columns[df.isnull().sum() > 0])
# 用列均值进行填充NaN
for column in list(df.columns[df.isnull().sum() > 0]):
mean_val = df[column].mean()
df[column].fillna(mean_val, inplace=True)
# 用后一行的值进行填充NaN
# print(df.fillna(method='backfill', axis=0, inplace=True))
# 筛选需要填充的列 发现没有这样的列了
print(df.columns[df.isnull().sum() > 0])
print(df)

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/169999.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
