大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Adversarial Attacks on Neural Networks for Graph Data
论文链接:https://arxiv.org/pdf/1805.07984.pdf
evasion attack & poisoning attack
Abstract
本文介绍了第一个在属性图上进行对抗攻击的研究,特别关注利用图卷积的思想模型。除了在测试阶段进行攻击,本文进行了更具挑战的poisoning attack(聚焦于机器学习模型的训练阶段)类别。在考虑实例间依赖关系的情况下,针对节点特征和图结构进行对抗扰动(adversarial perturbation)。通过保证重要的数据特征保证扰动是不可见的(unnoticeable)。为了解决底层的离散域(discrete domain),本文提出了一种利用增量计算的有效方法 NETTACK。本文实验研究表明,即使通过很小的扰动,也能够使节点分类的准确率产生明显的下降。此外,本文的方法是可迁移的,并且在即使只知道图的很少知识时也能成功。
1 Introduction
图数据上最频繁应用的任务是节点分类:给定一个大(带属性的)图和一些节点的标签,目标是预测其余节点的标签。
GCNs在节点分类任务中取得了巨大的成功。这些方法的优势超越了非线性、层次本质,依赖于图的关系信息来进行分类:不只是单独考虑实例(节点和特征),它们之间的关系(边)也被利用。也就是说实例没有被单独处理,要处理的是某种非独立同分布(non-i.i.d)的数据,其中如同质偏好(homophily)的网络效应支持了分类。
此前的一些文章表明用于分类学习任务的深度学习结构很容易被欺骗,即使是一些小的扰动也可以导致错误的预测。在本文之前,对图上的深度学习方法的对抗扰动问题还没有解决。这是至关重要的,因为在基于图学习的对抗是很普遍且错误数据容易被注入。
本文弥补了这一差距,并研究这种操作是否是可行的。Can deep learning models for attributed graphs be easily fooled? How reliable are their results?
这个问题的答案是不可预见的:一方面,由于预测不是基于单个实例而是基于不同实例的联合,关系效应可能提高鲁棒性。另一方面,信息传播可能导致级联效应,操作单个实例会影响其它实例。
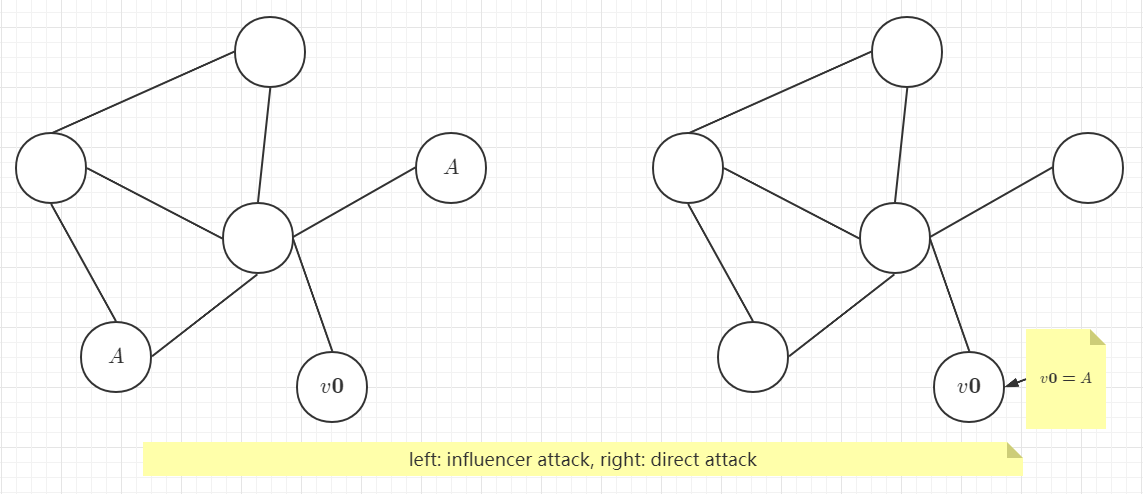
机遇:(1)由于在属性图上进行操作,对抗扰动会以两种方式呈现:改变节点特征或图结构。(2)关系效应给了我们更多能力:通过操纵一个实例,可能会对另一个实例的预测产生影响。这个场景是非常真实的。在基于图的学习场景中可以区分(i)要误分类的节点,称为 targets(ii)可以直接操作的节点,称为 attacker。下图展示了本工作的目标以及本方法在 Citeseer上的结果。与学习模型的经典攻击相比,图具有更大的扰动潜能。同样,构建它们很具有挑战性。
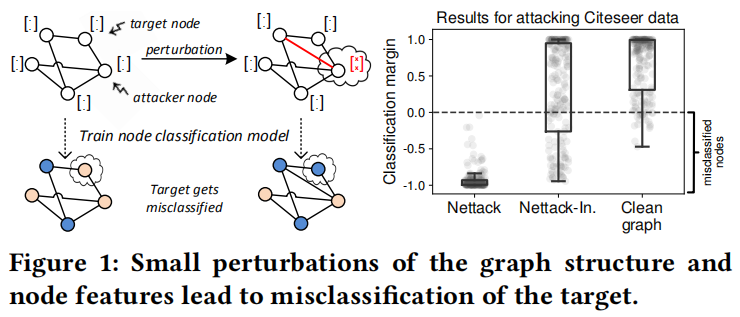

挑战:(1)与图像(image)有连续特征不同,图(graph)结构(通常也是节点的特征)是离散的。因此基于梯度的方法来查找扰动是不合适的。如何在离散域中找到对抗样例来设计有效的算法?(2)对抗扰动旨在不易被(人类)察觉。如何在(binary,attributed)图中捕获“不明显察觉”的概念?(3)节点分类通常以 transductive learning 设置的方式呈现。在对特定测试数据进行预测前训练和测试数据要联合学习一个新的分类模型。这就意味着主要执行的 evasion attack (分类模型的参数假设是静态的)是不现实的。模型必须对被操纵的数据(重新)训练。因此在 transductive 设置中的基于图的学习与具有挑战性的 poisoning attack 之间具有内在的联系。
为此,本文提出了一种属性图的对抗扰动方法。主要聚焦于基于 GCN 和 CLN(Column Network)的图卷积的半监督分类,也在无监督分类模型 DeepWalk 上展现了本方法的潜能。默认假设 attacker 知道整个图的所有知识,但只能操作图的一部分。该假设确保了在最坏情况下进行可靠的弱点分析。但即使只知道部分数据,实验证明该攻击依然有效。
本文贡献:
Model:本文提出了一种在属性图上考虑节点分类的对抗攻击模型。该攻击可以操纵图结构和节点特征,同时通过保留重要的数据特征(如度分布、特征同时出现)来确保不明显的改变。
Algorithm:设计了一个有效的算法来计算基于线性思想的攻击。本方法支持增量计算并应用图的稀疏性快速执行。
Experiments:本模型即使只需要对图进行很小的改变也能能够对目标节点的分类结果进行显著的恶化。
2 Preliminaries:
令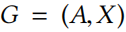 表示属性图, 是邻接矩阵, 表示节点属性。 表示节点 v 的 D 维特征向量。节点 id ,特征 id 。
表示属性图, 是邻接矩阵, 表示节点属性。 表示节点 v 的 D 维特征向量。节点 id ,特征 id 。
给定带标签节点的子集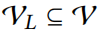 ,类标签。节点分类的目标就是要学习一个函数把节点集中的每个节点映射到类别 。由于预测是针对给定的测试实例进行的,这些实例在训练之前已经知道(也在训练期间使用),这对应于典型的 transductive learning 场景。
,类标签。节点分类的目标就是要学习一个函数把节点集中的每个节点映射到类别 。由于预测是针对给定的测试实例进行的,这些实例在训练之前已经知道(也在训练期间使用),这对应于典型的 transductive learning 场景。
本文聚焦于使用图卷积层进行节点分类。隐层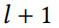 被定义为:
被定义为:
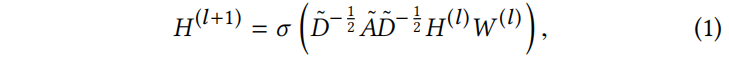
其中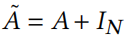 是通过单位阵增加自循环后的(无向)输入图 G 的邻接矩阵。是第 l 层的可训练权重矩阵,,是激活函数。第一层有,如用节点特征作为输入。由于潜在表示(递归地)依赖于临近表示(乘),所有的实例都耦合在一起。认为 GCNs 只有单个隐层:
是通过单位阵增加自循环后的(无向)输入图 G 的邻接矩阵。是第 l 层的可训练权重矩阵,,是激活函数。第一层有,如用节点特征作为输入。由于潜在表示(递归地)依赖于临近表示(乘),所有的实例都耦合在一起。认为 GCNs 只有单个隐层:
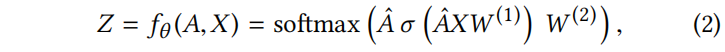
输出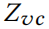 表示将节点 v 分为 c 类的概率。用 θ 表示所有参数,如
表示将节点 v 分为 c 类的概率。用 θ 表示所有参数,如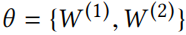 。通过最小化带标签样本输出的交叉熵,以半监督方式学习最优参数 θ。如,最小化
。通过最小化带标签样本输出的交叉熵,以半监督方式学习最优参数 θ。如,最小化
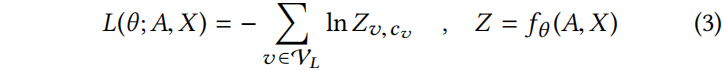
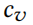 是训练集中 v 的标签。表示图中每个实例的类分布。
是训练集中 v 的标签。表示图中每个实例的类分布。
3 Related Work
Deep Learning for Graphs.
主要区分两大研究流派:(i)node embedding(通常在无监督环境中操作)(ii)architectures employing layers specifically designed for graphs(专门为图设计的层级架构)。本文工作将重点放在第二种原则上并表明本文的对抗攻击也可以迁移到 node embedding 中。
Adversarial Attacks.
两个主要的攻击类型是针对训练数据的 poisoning/causative attacks(模型的训练阶段在攻击之后)和针对测试数据/应用程序阶段的 evasion/exploratory attacks(假设学习模型是固定的)。考虑到 poisoning attack 通常计算上更困难,因为还必须考虑模型的后续学习。这种类别并不适合本文的设置。
Generating Adversarial Perturbations.
通常来说,由于找到对抗扰动通常归结为非凸(bi-level)优化问题,因此引入了不同的近似原理。几乎所有的工作利用给定可微(代理)损失函数的梯度或其它矩(moment)来指导在合理扰动邻域内的研究。对于没有定义梯度的离散数据,这种方法是次优的。
4 Attack Model
给定前面节点分类的设置,本文的目标是在图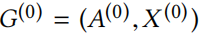 上进行小的扰动来导致,使得分类性能降低。改变称为结构攻击,改变
上进行小的扰动来导致,使得分类性能降低。改变称为结构攻击,改变 称为特征攻击。
称为特征攻击。
Target vs. Attackers.
目标是要攻击特定的目标节点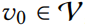 ,比如改变的预测。由于数据非独立同分布(non-i.i.d)的本质,的输出不仅依赖于其自身,还依赖于图中的其它节点。因此我们不限于扰动,通过改变其它节点也可以实现目标。在目标节点(target node)之外,引入攻击者节点(attacker nodes)。在上的扰动必须受限于这些节点,如必须保证下式成立
,比如改变的预测。由于数据非独立同分布(non-i.i.d)的本质,的输出不仅依赖于其自身,还依赖于图中的其它节点。因此我们不限于扰动,通过改变其它节点也可以实现目标。在目标节点(target node)之外,引入攻击者节点(attacker nodes)。在上的扰动必须受限于这些节点,如必须保证下式成立
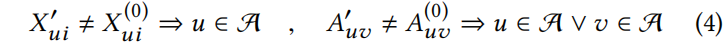
如果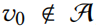 ,称该攻击为影响者攻击(influencer attacker),因为
,称该攻击为影响者攻击(influencer attacker),因为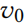 并不是被直接操纵的,而是间接通过影响者操纵的。如果,称为直接攻击(direct attack)(直接对目标节点进行操作)。
并不是被直接操纵的,而是间接通过影响者操纵的。如果,称为直接攻击(direct attack)(直接对目标节点进行操作)。
Notes:Eq(4):修改后图的特征(特征矩阵)和图结构(邻接矩阵)要与原图不同。节点 u 的第 i 个特征要改变,节点 u 和节点 v 之间的边要改变。
为了确保 attacker 不能完全修改图,通过一个预算(budget)Δ 限制允许改变的数量:
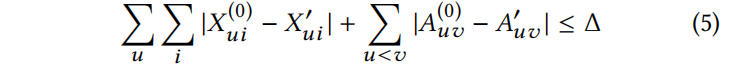
用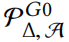 表示所有满足 Eq(4) 和 Eq(5) 的图的集合。
表示所有满足 Eq(4) 和 Eq(5) 的图的集合。
Notes:Eq.(5):更改的图的特征和结构要限制在一定范围内。对于 u < v 的解释,因为是对无向图的操作,所以只需修改一半,Auv = Avu。于是约束的意思就是要发生改变,且改变要限制在一定范围内。
给定上面的基础设置,问题定义为:
给定一个图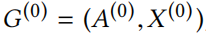 ,一个目标节点和攻击者节点。表示节点基于原图的类别(预测的或真实值)。定义
,一个目标节点和攻击者节点。表示节点基于原图的类别(预测的或真实值)。定义
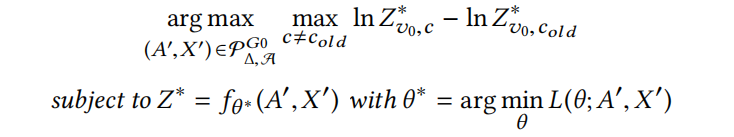
原文如下:

目的是要找到一个扰动的图 把分类为并与有最大的“距离”(用 log-probabilities/logits 表示)。对于被扰动的图,使用了最优参数,这与在给定数据上学习模型的 transductive learning 的设置相匹配。因此有了一个双层优化问题。做为简化的版本,也可以考虑参数是静态的、基于旧图学习的 evasion attack,。
把分类为并与有最大的“距离”(用 log-probabilities/logits 表示)。对于被扰动的图,使用了最优参数,这与在给定数据上学习模型的 transductive learning 的设置相匹配。因此有了一个双层优化问题。做为简化的版本,也可以考虑参数是静态的、基于旧图学习的 evasion attack,。
Notes:上式使用对数概率的原因可能是对于比较小的概率,使用对数概率是更合适的。(guess)
4.1 Unnoticeable Perturbations
在图数据的对抗攻击场景中,要使得变化是不明显的比图像数据的攻击场景更难。主要有两个原因:(i)图结构是离散的阻碍了无穷小变化的使用。(ii)足够大的图不适合视觉检查(图像数据可以通过可视化验证)。
How can we ensure unnoticeable perturbations in our setting?只考虑 budget Δ 是不够的。特别是由于复杂的数据需要很大的 Δ,我们依然想要看起来更真实地被扰动的图。因此,核心思想是允许那些保持输入图特定内在属性的扰动(也就是原图中的原有属性)。
Graph structure preserving perturbations. 图结构最显著的特征是度分布(degree distribution),在真实网络中它类似于幂定律(power law)。如果两个网络具有不同的度分布则很容易区分。目标是只产生像幂定律行为一样的扰动作为输入。
为此引入幂定律分布的统计双样本检验(statistical two-sample test for power-law distributions)。即使用似然比检验(likelihood ratio test)来评估 和的两个度分布是否来自相同的分布或来自独立的分布。
和的两个度分布是否来自相同的分布或来自独立的分布。
步骤如下:首先参考的度分布(也一样)来评估幂律分布的尺度参数 α。尽管在离散数据下,没有精确的闭式解来评估 α,但已有推导出的近似表达式,为了本文的目的,将图 转换为:
转换为:
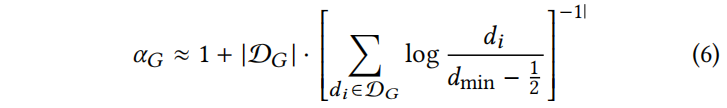
其中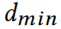 表示幂律检验中需要考虑的节点的最小度,是包含节点度数列表的多集,是图中节点的度数。利用该方法,得到了和的估计值。可以用组合样本估计。
表示幂律检验中需要考虑的节点的最小度,是包含节点度数列表的多集,是图中节点的度数。利用该方法,得到了和的估计值。可以用组合样本估计。
Notes:Eq.(6) 中的存在的原因是原来的幂律分布中的限制,可查看幂律原文。
给定尺度参数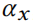 ,样本的对数似然可以容易被评估为:
,样本的对数似然可以容易被评估为:
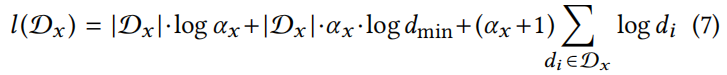
使用这些对数似然得分,建立重要的检验。评估两个样本 和是否来自相同的幂律分布(空假设),而不是来自单个的幂律分布()。于是提出两个相互竞争的假设:
和是否来自相同的幂律分布(空假设),而不是来自单个的幂律分布()。于是提出两个相互竞争的假设:
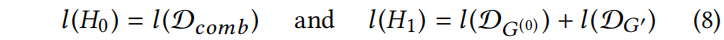
经过似然比检验后,最终的检验统计量为:
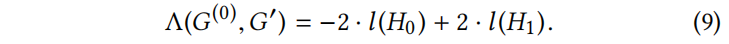
对于大样本容量,其遵循自由度的卡方(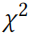 )分布。
)分布。
Notes: Eq(7)、Eq.(9) 就是通过上文的幂律分布的统计双样本检验得到的,所以作者才说“很容易”得到。


拒绝原假设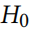 (即得出两个样本来自不同分布的结论)的典型的 p 值(P值(P value)就是当为真时,比所得到的样本观察结果更极端的结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。总之,P值越小,表明结果越显著。但是检验的结果究竟是“显著的”、“中度显著的”还是“高度显著的”需要我们自己根据P值的大小和实际问题来解决。)是0.05。即,在统计上,在二十分之一的情况下拒绝零假设,尽管它成立(第一类错误)。在我们的对抗攻击场景中,我们认为试图找出数据是否被操纵的人会更保守,,并提出另一种方式:鉴于数据被操纵,测试错误地不拒绝零假设的概率是多少(第二类错误)。
(即得出两个样本来自不同分布的结论)的典型的 p 值(P值(P value)就是当为真时,比所得到的样本观察结果更极端的结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。总之,P值越小,表明结果越显著。但是检验的结果究竟是“显著的”、“中度显著的”还是“高度显著的”需要我们自己根据P值的大小和实际问题来解决。)是0.05。即,在统计上,在二十分之一的情况下拒绝零假设,尽管它成立(第一类错误)。在我们的对抗攻击场景中,我们认为试图找出数据是否被操纵的人会更保守,,并提出另一种方式:鉴于数据被操纵,测试错误地不拒绝零假设的概率是多少(第二类错误)。
虽然在我们的例子中,不能很容易地计算第二类误差,但一般来说,第一类和第二类误差概率呈反比关系。因此,通过选择一个非常保守的对应于高一类错误的 p 值,我们可以减少二类错误的概率。因此,我们将临界 p 值设为0.95,也就是说,如果我们从相同的幂律分布中抽样二度序列,我们将在95%的情况下拒绝零假设,然后可以根据最初的怀疑来调查数据是否已经受损。另一方面,如果我们修改的图的度序列通过了这个非常保守的检验,我们可以得出这样的结论:度分布的变化是不明显的(unnoticeable)。
使用 χ2 分布中的上述 p 值,我们只接受度分布满足的扰动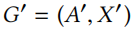 :
:
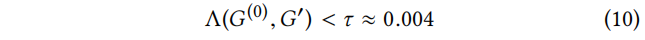
Feature statistics preserving perturbations. 虽然上述原则也可以应用于节点的特征(例如,保持特征出现的分布),但我们认为这样的过程太有限了。特别是,这样的测试不能很好地反映不同特征的相关性/共现性:如果两个特征在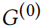 中从未同时出现,但在中同时出现时,其特征出现的分布仍然非常相似。然而,这种变化很容易被注意到。例如,考虑两个从未在一起使用的词,但突然在
中从未同时出现,但在中同时出现时,其特征出现的分布仍然非常相似。然而,这种变化很容易被注意到。例如,考虑两个从未在一起使用的词,但突然在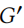 中被使用。因此,我们称之为基于特征共现的检验。
中被使用。因此,我们称之为基于特征共现的检验。
由于设计基于共现的统计检验需要对特征上的联合分布进行建模(这对于相关的多元二进制数据是难以处理的)因此使用确定性检验。在这方面,将特征设置为0是不重要的,因为它不会引入新的共现。问题:Which features of a node u can be set to 1 to be regarded unnoticable?
为回答该问题,要考虑一个在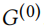 的特征的共现图上的概率随机游走(probabilistic random walker),如是特征集,表示目前哪些特征共同出现。我们认为,如果从节点 u 最初呈现的特征开始的随机游走到达特征 i 的概率非常大,那么添加特征 i 是不明显的。形式上,让
的特征的共现图上的概率随机游走(probabilistic random walker),如是特征集,表示目前哪些特征共同出现。我们认为,如果从节点 u 最初呈现的特征开始的随机游走到达特征 i 的概率非常大,那么添加特征 i 是不明显的。形式上,让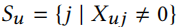 节点 u 最初存在的所有节点特征的集合。我们认为如果满足下式,则把特征添加到节点 u 是不明显的
节点 u 最初存在的所有节点特征的集合。我们认为如果满足下式,则把特征添加到节点 u 是不明显的
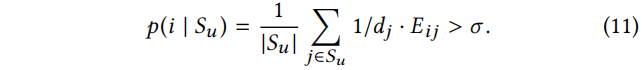
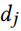 表示共现图 C 的度。即,假设概率随机游走在任意特征处开始,执行一步后,它至少以概率 σ 达到特征 i。在本实验中,我们简单地选择σ为最大可达到的可能的一半,即
表示共现图 C 的度。即,假设概率随机游走在任意特征处开始,执行一步后,它至少以概率 σ 达到特征 i。在本实验中,我们简单地选择σ为最大可达到的可能的一半,即
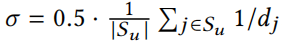
上述原则有两个可取的效果:首先,特征 i 与 u 的许多特征同时出现(即在其他节点中)的概率很高,当它们被添加时,就不那么明显了。其次,仅与非特定节点 u 的特征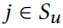 共现的特征 i(例如,与几乎所有其他特征同时出现的特征 j;停用词)的概率较低,添加 i 会很明显。因此,我们得到了预期的结果。
共现的特征 i(例如,与几乎所有其他特征同时出现的特征 j;停用词)的概率较低,添加 i 会很明显。因此,我们得到了预期的结果。
使用上述检验,只接受特征值满足下式的扰动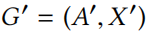
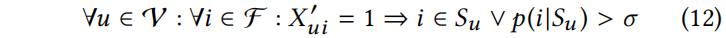
Notes:该公式就是对上面问题(Which features of a node u can be set to 1 to be regarded unnoticable?)的解。
综上所述,为了确保不被注意到的扰动,将问题定义更新为:
问题 2. 与问题 1 相同但把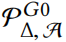 替换成了更受限的图的集合,它额外增加了度分布 Eq.10 和特征共现 Eq.12 。
替换成了更受限的图的集合,它额外增加了度分布 Eq.10 和特征共现 Eq.12 。

5 Graph Adversarial Graphs
解决问题1/2是非常具有挑战性的。因此,我们提出了一种顺序方法,首先攻击代理模型(surrogate model),从而导致被攻击的图。这个图随后被用来训练最终的模型。实际上,这种方法可以直接被认为是对可迁移性的检查,因为我们并不特别关注所使用的模型,而是只关注代理模型。
Surrogate model.
为了获得一个仍能捕捉图卷积思想的易于处理的代理模型,根据 Eq.2 对模型进行线性化。即用一个简单的线性激活函数代替非线性 σ(.),得到:
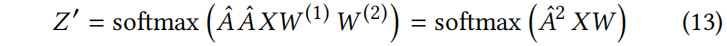
由于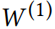 和是要学习的(自由)参数,可以被吸收进一个单一矩阵。
和是要学习的(自由)参数,可以被吸收进一个单一矩阵。
由于目标是最大化目标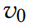 的对数概率的差异(给定特定的 budget ∆),因此可以忽略由 softmax 引起的与实例相关的归一化。因此,对数概率可被简化为
的对数概率的差异(给定特定的 budget ∆),因此可以忽略由 softmax 引起的与实例相关的归一化。因此,对数概率可被简化为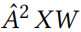 。因此,给定具有学习的参数 W 的(未损坏的)输入数据上的经过训练的代理模型,定义代理损失
。因此,给定具有学习的参数 W 的(未损坏的)输入数据上的经过训练的代理模型,定义代理损失
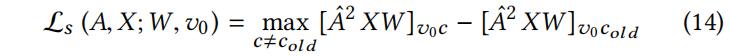
旨在解决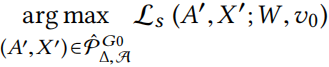
该问题虽然简单得多,但由于离散域和约束条件,仍然难以精确求解。因此,在下面介绍一个可扩展的贪婪近似方案。为此,定义评分函数来评估从 Eq.(14) 中对任意图形 添加/删除特征或边后得到的替代损失:
添加/删除特征或边后得到的替代损失:
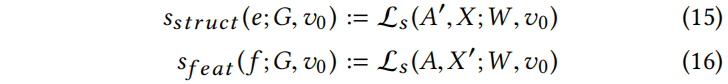
其中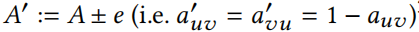 (在无向图上进行操作)、
(在无向图上进行操作)、
Approximate Solution.
算法 1 展示了伪代码。具体来说,遵循局部最优策略,依次“操纵”最有希望的元素:要么是邻接矩阵中的一个条目,要么是特征条目(考虑到约束条件)。即,给定图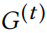 的当前状态,计算从 0 到 1(反之亦然,因此为代码中有± )改变不违反
的当前状态,计算从 0 到 1(反之亦然,因此为代码中有± )改变不违反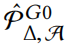 的限制的允许元素的候选集。在这些元素中,选择在对数概率上差异最大的那个,用评分函数表示。类似地,对于每个允许的特征 i 和节点 u 的特征操作,计算候选集和得分函数。选择能使得更高分数的任何更改,并且将图相应地更新为。 重复此过程,直到超出 budget Δ。
的限制的允许元素的候选集。在这些元素中,选择在对数概率上差异最大的那个,用评分函数表示。类似地,对于每个允许的特征 i 和节点 u 的特征操作,计算候选集和得分函数。选择能使得更高分数的任何更改,并且将图相应地更新为。 重复此过程,直到超出 budget Δ。
为了使算法1易于处理,必须保持两个核心方面:(i)有效计算评分函数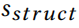 和,有效检查哪些边和特征符合约束,因此,形成集合和。下面,详细描述这两个部分。
和,有效检查哪些边和特征符合约束,因此,形成集合和。下面,详细描述这两个部分。

5.1 Fast computation of score functions
Structural attacks. 从描述如何计算开始。为此,必须计算在添加/删除一条边后节点 u 的类别预测(在代理模型中)。由于是对 A 进行优化,Eq.14 中的是一个常数,用代替。节点的对数概率可以由表示,其中表示行向量。因此,只需要检查行向量如何变化,就可以确定最佳的边操作。
然而,为候选集中的每个元素重新计算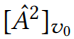 是不可行的。缓解这个问题的一个重要观察是,在使用的两层 GCN 中,每个节点的预测仅受其两跳(two hop)邻域的影响。也就是说,上面的行向量对于大多数元素来说都是零。更重要的是,可以导出增量更新——不需要从头开始重新计算已经更新的
是不可行的。缓解这个问题的一个重要观察是,在使用的两层 GCN 中,每个节点的预测仅受其两跳(two hop)邻域的影响。也就是说,上面的行向量对于大多数元素来说都是零。更重要的是,可以导出增量更新——不需要从头开始重新计算已经更新的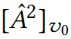 。
。
定理5.1 给定一个邻接矩阵 A 和相应的矩阵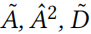 。用表示从 A 中添加或删除元素时的邻接矩阵。有:
。用表示从 A 中添加或删除元素时的邻接矩阵。有:
原文:

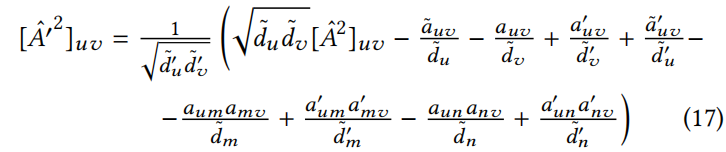
其中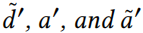 (使用 Iverson 括号——满足括号内的条件则值为1, 不满足条件则值为0)定义为
(使用 Iverson 括号——满足括号内的条件则值为1, 不满足条件则值为0)定义为
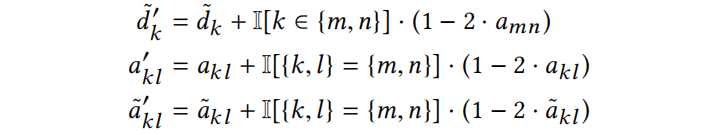
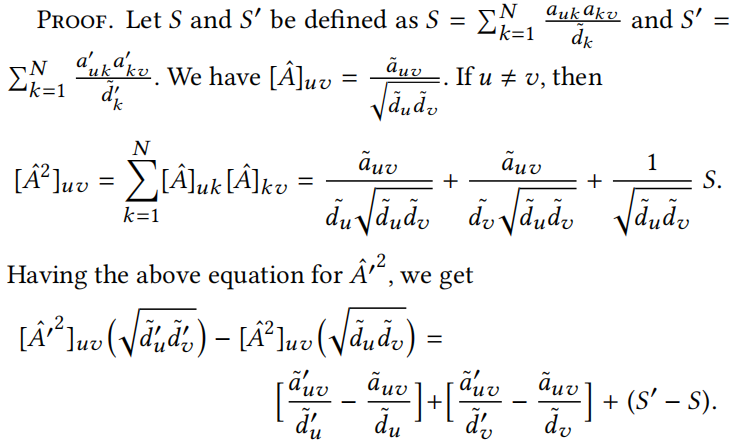
在替换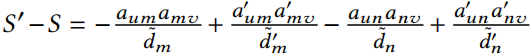 后,就可直接得到 Eq.17。在 u = v 的情况下推导这个方程是相似的。式17包含了这两种情况。
后,就可直接得到 Eq.17。在 u = v 的情况下推导这个方程是相似的。式17包含了这两种情况。
Notes:Eq.17 公式
# Update 2022/01/03
关于 Eq.17,之前的一些小细节没注意到,问了作者后豁然开朗。
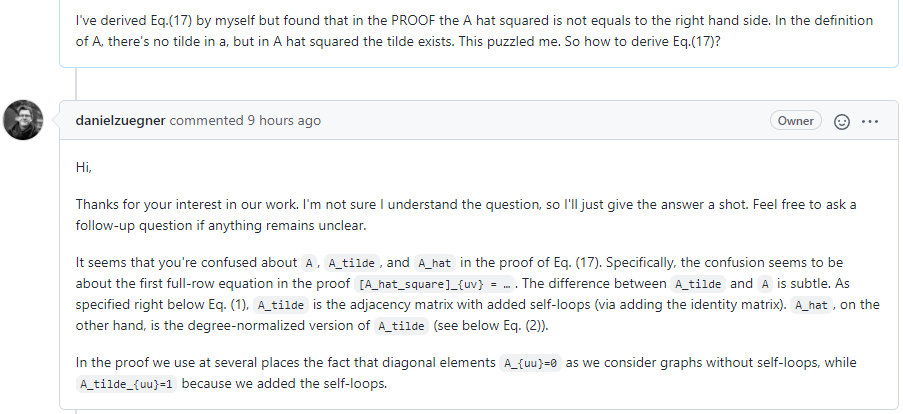
# Update end.
Eq.17 允许我们在常数时间内以一种稀疏和增量的方式更新整个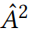 。所有的
。所有的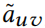 ,和都是非0即1的,并且它们相应的矩阵都是稀疏的。考虑到到的高效更新,更新后的对数概率,因此最终根据 Eq.15 的得分可以很容易计算。
,和都是非0即1的,并且它们相应的矩阵都是稀疏的。考虑到到的高效更新,更新后的对数概率,因此最终根据 Eq.15 的得分可以很容易计算。
Feature attacks. 特征攻击更容易实现。通过最大对数概率得分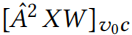 固定类,该问题在 X 中是线性的,且 X 中的每一个条目都独立运行。因此,为了找到最好的节点和特征,只需计算梯度:
固定类,该问题在 X 中是线性的,且 X 中的每一个条目都独立运行。因此,为了找到最好的节点和特征,只需计算梯度:
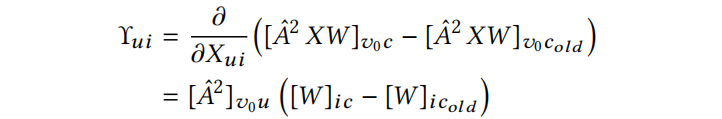
随后选择指向允许方向的绝对值最高的一个(如果特征是0,梯度需要指定正方向)。最佳元素的得分函数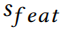 的值只需在 loss 函数的当前值加上即可:
的值只需在 loss 函数的当前值加上即可:
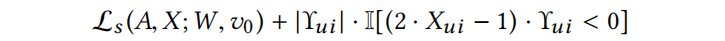
所有这些都可以在每个特征的常数时间内完成。梯度点在允许方向之外的元素不应该被干扰,因为它们只会阻碍攻击——因此,旧的分数保持不变。
5.2 Fast computation of candidate sets
最后,必须保证所有扰动都符合限制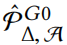 。为此,定义集合和。Eq.4 和 Eq.5 中的限制容易保证。通过贪婪逼近的过程来满足预算约束 ∆,而根据 Eq.4 可以扰动的元素可以预先计算出来。同样,可以预先计算满足 Eq.12 共现检验的节点特征组合。因此,集合只需被实例化一次。
。为此,定义集合和。Eq.4 和 Eq.5 中的限制容易保证。通过贪婪逼近的过程来满足预算约束 ∆,而根据 Eq.4 可以扰动的元素可以预先计算出来。同样,可以预先计算满足 Eq.12 共现检验的节点特征组合。因此,集合只需被实例化一次。
但是,度分布的重要性检验不允许这样的预先计算,因为底层的度分布是动态变化的。如何有效地检查边 (m,n) 的潜在扰动是否仍然保持相似的度分布?由于各个度数仅相加交互,可以再次推导出测试统计量 Λ 的恒定时间增量更新。
定理5.2 给定图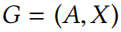 和多重集(见 Eq.6)。用表示对数度的和。设是侯选边扰动,和是中节点的度。对于,有:
和多重集(见 Eq.6)。用表示对数度的和。设是侯选边扰动,和是中节点的度。对于,有:
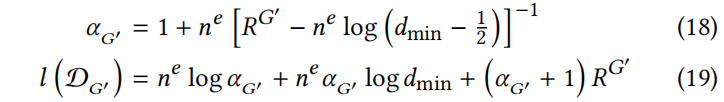
其中
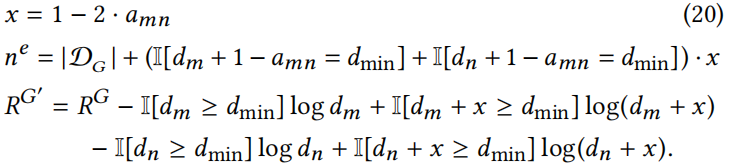
原文:
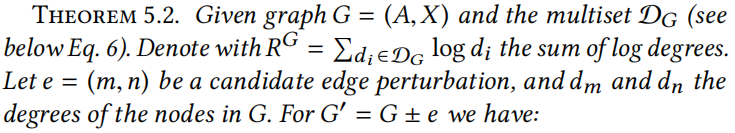
证明:首先,证明如果根据定理 5.2 的更新方程,增量计算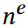 ,将会等价于。项只有在两种情况下被激活(即,非零):1) (即,)且,那么且更新等式实际是从中删除节点 m。2)(即,)且,那么且更新等式实际是从中添加节点 m。同样的增量可以应用到节点 n。因此,有。
,将会等价于。项只有在两种情况下被激活(即,非零):1) (即,)且,那么且更新等式实际是从中删除节点 m。2)(即,)且,那么且更新等式实际是从中添加节点 m。同样的增量可以应用到节点 n。因此,有。
同样,考虑到仅考虑度数大于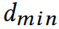 的节点并且是新度数,可以显示的有效增量更新。在增量更新和后,对于和的更新很容易遵循定义。
的节点并且是新度数,可以显示的有效增量更新。在增量更新和后,对于和的更新很容易遵循定义。
给定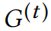 ,现在可以增量计算,其中。等价地,在边扰动后,得到的增量更新。上面等式右手边可以在常数时间内计算,也可以在常数时间内计算。在迭代 t 的合理候选边扰动集合是。因此一旦进行了最佳边扰动,可以增量更新到,整个方法是非常有效的。
,现在可以增量计算,其中。等价地,在边扰动后,得到的增量更新。上面等式右手边可以在常数时间内计算,也可以在常数时间内计算。在迭代 t 的合理候选边扰动集合是。因此一旦进行了最佳边扰动,可以增量更新到,整个方法是非常有效的。
Notes:上面这些是得到候选边的集合。对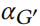 和的计算是要在满足前面的 Eq.6 时得到合格的侯选边。
和的计算是要在满足前面的 Eq.6 时得到合格的侯选边。
5.3 Complexity
候选集的生成(即哪些边/特征允许改变)和评分函数可以递增计算,并利用图的稀疏性,从而确保可扩展性。算法的运行时复杂度可以很容易地确定为:
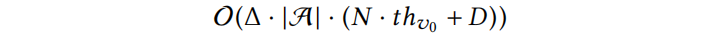
其中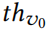 表示算法运行过程中节点的两跳邻域。
表示算法运行过程中节点的两跳邻域。
在每个 Δ 次迭代中,每个攻击者评估潜在的边扰动(最多N)和特征扰动(最多D)。对于前者,由于有两个卷积层,需要更新目标的两跳邻域。假设图是稀疏的,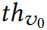 远小于 N。每个特征在恒定的时间内进行特征扰动。因为所有的约束都可以在常数时间内检查,所以它们不会影响复杂度。
远小于 N。每个特征在恒定的时间内进行特征扰动。因为所有的约束都可以在常数时间内检查,所以它们不会影响复杂度。
思考
这篇文章作为图对抗的第一篇文章,对后来的工作是启发式的(如属性比结构更重要等的结论)。
欢迎讨论和指教。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/169752.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
