大家好,又见面了,我是你们的朋友全栈君。
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影。下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数据工具。
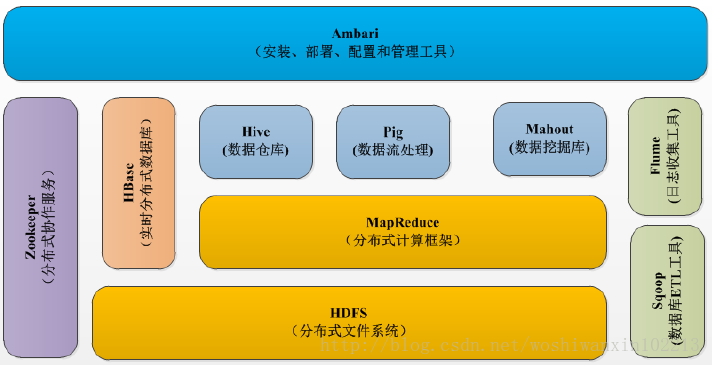

这一切,都起源自 Web 数据爆炸时代的来临。Hadoop 生态系统的功能以及对应的开源工具说明如下。
MapReduce

HDFS

Pig和Hive
 、
、
Pig:是一种编程语言,它简化了Hadoop常见的工作任务。Pig可加载数据、表达转换数据以及存储最终结果。Pig内置的操作使得半结构化数据变得有意义(如日志文件)。同时Pig可扩展使用Java中添加的自定义数据类型并支持数据转换。
Hive:在Hadoop中扮演数据仓库的角色。Hive添加数据的结构在HDFS(hive superimposes structure on data in HDFS),并允许使用类似于SQL语法进行数据查询。与Pig一样,Hive的核心功能是可扩展的。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144324.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
