大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源:
- 疯狂创客圈 经典图书 : 《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 + 涨薪必备
- 疯狂创客圈 经典图书 : 《SpringCloud、Nginx高并发核心编程》 面试必备 + 大厂必备 + 涨薪必备
- 疯狂创客圈 价值1000元 百度网盘资源大礼包 随便取 GO->【博客园总入口 】
- 独孤九剑 Netty灵魂实验 : 本地 100W连接 高并发实验,瞬间提升Java内力
文章目录
价值连城:2021春招月薪过5万 面试题 系列
| 搞定下面这些面试题,2021春招月薪过5万(猛!) | 阿里、京东、美团、头条… 随意挑、横着走!!! |
|---|---|
| Java基础 | |
| 1: JVM面试题(史上最强、持续更新、吐血推荐) | https://www.cnblogs.com/crazymakercircle/p/14365820.html |
| 2:Java基础面试题(史上最全、持续更新、吐血推荐) | https://www.cnblogs.com/crazymakercircle/p/14366081.html |
| 3:死锁面试题(史上最强、持续更新) | [https://www.cnblogs.com/crazymakercircle/p/14323919.html] |
| 4:设计模式面试题 (史上最全、持续更新、吐血推荐) | https://www.cnblogs.com/crazymakercircle/p/14367101.html |
| 5:架构设计面试题 (史上最全、持续更新、吐血推荐) | https://www.cnblogs.com/crazymakercircle/p/14367907.html |
| 还有 10 几篇 篇价值连城 的面试题 | 具体… 请参见【 疯狂创客圈 高并发 总目录 】 |
万字长文: 疯狂创客圈 springCloud 高并发系列
| springCloud 高质量 博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| springcloud + webflux 高并发实战 | Webflux(史上最全) |
| SpringCloud gateway (史上最全) | |
| 还有 10 几篇 万字长文 的高质量 博文 | 具体… 请参见【 疯狂创客圈 高并发 总目录 】 |
写在前面
大家好,我是作者尼恩。
为了完成了一个高性能的 Java 聊天程序,在前面的文章中,尼恩已经再一次的进行了通讯协议的重新选择。
这就是:放弃了大家非常熟悉的json 格式,选择了性能更佳的 Protobuf协议。
在上一篇文章中,并且完成了Netty 和 Protobuf协议整合实战。
具体的文章为: Netty+Protobuf 整合一:实战案例,带源码
另外,专门开出一篇文章,介绍了通讯消息数据包的几条设计准则。
具体的文章为: Netty +Protobuf 整合二:protobuf 消息通讯协议设计的几个准则
在开始聊天器实战开发之前,还有一个非常基础的问题,需要解决:这就是通讯的粘包和半包问题。
什么是粘包和半包?
先从数据包的发送和接收开始讲起。
我们知道, Netty 发送和读取数据的单位,可以形象的使用 ByteBuf 来充当。
每一次发送,就是向Channel 写入一个 ByteBuf ;每一次读取,就是从 Channel 读到一个 ByteBuf 。
发送一次数据,举例如下:
channel.writeAndFlush(buffer);
读取一次数据,举例如下:
public void channelRead(ChannelHandlerContext ctx, Object msg)
{
ByteBuf byteBuf = (ByteBuf) msg;
//....
}
我们的理想是:发送端每发送一个buffer,接收端就能接收到一个一模一样的buffer。
然而,理想很丰满,现实很骨感。
在实际的通讯过程中,并没有大家预料的那么完美。
一种意料之外的情况,如期而至。这就是粘包和半包。
那么,什么是粘包和半包?
粘包和半包定义如下:
-
粘包和半包,指的都不是一次是正常的 ByteBuf 缓存区接收。
-
粘包,就是接收端读取的时候,多个发送过来的 ByteBuf “粘”在了一起。
换句话说,接收端读取一次的 ByteBuf ,读到了多个发送端的 ByteBuf ,是为粘包。
-
半包,就是接收端将一个发送端的ByteBuf “拆”开了,形成一个破碎的包,我们定义这种 ByteBuf 为半包。
换句话说,接收端读取一次的 ByteBuf ,读到了发送端的一个 ByteBuf的一部分,是为半包。
粘包和半包 图解
上面的理论比较抽象,下面用一幅图来形象说明。
下图中,发送端发出4个数据包,接受端也接受到了4个数据包。但是,通讯过程中,接收端出现了 粘包和半包。
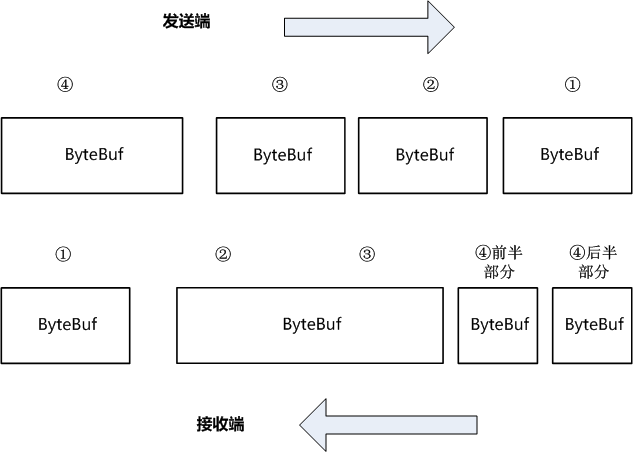

接收端收到的第一个包,正常。
接收端收到的第二个包,就是一个粘包。 将发送端的第二个包、第三个包,粘在一起了。
接收端收到的第三个包,第四个包,就是半包。将发送端的的第四个包,分开成了两个了。
半包的实验
由于在前文 Netty+Protobuf 整合一:实战案例,带源码 的源码中,没有看到异常的现象。是因为代码屏蔽了半包的输出,所以看到的都是正常的数据包。
稍微调整一下,在前文解码器的代码,加上半包的提示信息输出,就可以看到半包的提示。
示意图如下:
调整过的半包警告的代码,如下:
/**
* 解码器
*
*/
public class ProtobufDecoder extends ByteToMessageDecoder {
//....
protected void decode(ChannelHandlerContext ctx, ByteBuf in,
List<Object> out) throws Exception {
//...
// 读取传送过来的消息的长度。
int length = in.readUnsignedShort();
//...
if (length > in.readableBytes()) {
// 读到的半包
// ...
LOG.error("告警:读到的消息体长度小于传送过来的消息长度");
return;
}
//... 省略了正常包的处理
}
}
具体的源码,请参见本文的源码工程:Netty 粘包/半包原理与拆包实战 源码
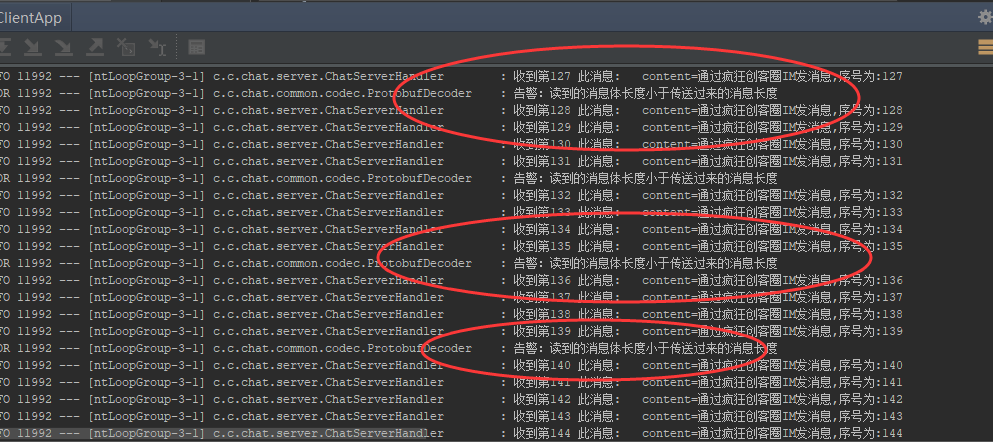
源码中,客户端向服务器循环发了1000个数据包,服务器接收端,出现了很多的半包的场景。
可以下载源码,进行实验。
实验时,服务器端运行 ChatServerApp 的main方法,客户端运行 ChatClientApp 的main方法,就可以看到上面图片中所示的半包的结果。
粘包和半包更全实验
上面的实例,只能看到半包的结果,看不到粘包的结果。
为了看到粘包的场景,这里,不使用protobuf 协议,直接使用缓冲区进行读写通讯,设计了一个的简单的演示实验案例。
案例已经设计好,可以下载源码,进行实验。
运行实例,不仅可以看到半包的提示信息输出,而且可以看到粘包的提示信息输出,示意图如下:
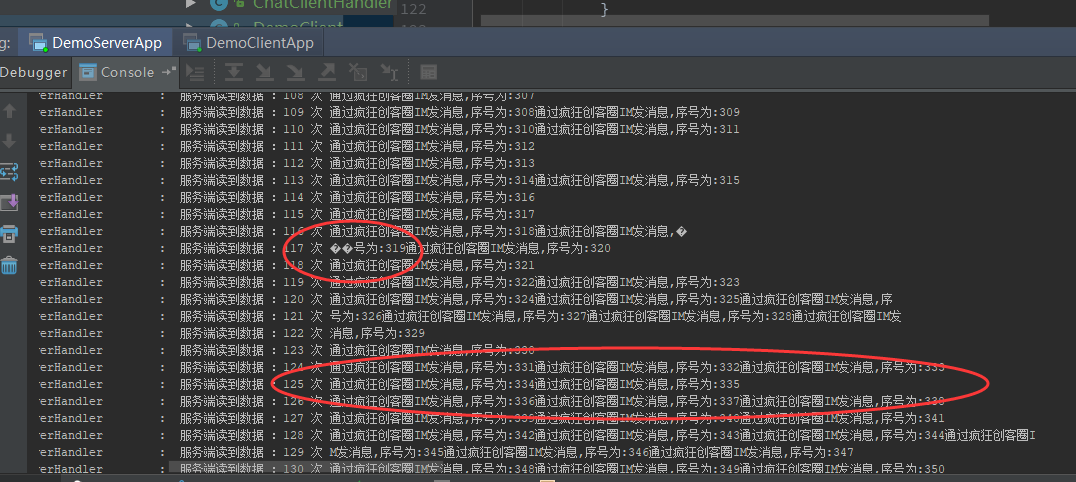
我们可以看到,服务器收到的数据包,有包含多个发送端数据包的,这就是粘包了。
另外,接收端还有出现乱码的数据包,就是只包含部分发送端数据,这就是半包了。
这个实例的源码,直接简化了前面的基于Protobuf协议通讯的实例源码。代码的逻辑结构,是一样的。
源码中,客户端向服务器循环发了1000个数据包,服务器接收端,收到数据包,直接在屏幕输出。
服务器端运行:DemoServerApp 的main方法,客户端运行 DemoClientApp的main方法,就可以看到上面图片中所示的半包的结果。
本实验的具体的源码,还是请参见本文的源码工程:Netty 粘包/半包原理与拆包实战 源码
粘包和半包原理
这得从底层说起。
在操作系统层面来说,我们使用了 TCP 协议。
在Netty的应用层,按照 ByteBuf 为 单位来发送数据,但是到了底层操作系统仍然是按照字节流发送数据,因此,从底层到应用层,需要进行二次拼装。
操作系统底层,是按照字节流的方式读入,到了 Netty 应用层面,需要二次拼装成 ByteBuf。
这就是粘包和半包的根源。
在Netty 层面,拼装成ByteBuf时,就是对底层缓冲的读取,这里就有问题了。
首先,上层应用层每次读取底层缓冲的数据容量是有限制的,当TCP底层缓冲数据包比较大时,将被分成多次读取,造成断包,在应用层来说,就是半包。
其次,如果上层应用层一次读到多个底层缓冲数据包,就是粘包。
如何解决呢?
基本思路是,在接收端,需要根据自定义协议来,来读取底层的数据包,重新组装我们应用层的数据包,这个过程通常在接收端称为拆包。
拆包的原理
拆包基本原理,简单来说:
-
接收端应用层不断从底层的TCP 缓冲区中读取数据。
-
每次读取完,判断一下是否为一个完整的应用层数据包。如果是,上层应用层数据包读取完成。
-
如果不是,那就保留该数据在应用层缓冲区,然后继续从 TCP 缓冲区中读取,直到得到一个完整的应用层数据包为止。
-
至此,半包问题得以解决。
-
如果从TCP底层读到了多个应用层数据包,则将整个应用层缓冲区,拆成一个一个的独立的应用层数据包,返回给调用程序。
-
至此,粘包问题得以解决。
Netty 中的拆包器
拆包这个工作,Netty 已经为大家备好了很多不同的拆包器。本着不重复发明轮子的原则,我们直接使用Netty现成的拆包器。
Netty 中的拆包器大致如下:
-
固定长度的拆包器 FixedLengthFrameDecoder
每个应用层数据包的都拆分成都是固定长度的大小,比如 1024字节。
这个显然不大适应在 Java 聊天程序 进行实际应用。
-
行拆包器 LineBasedFrameDecoder
每个应用层数据包,都以换行符作为分隔符,进行分割拆分。
这个显然不大适应在 Java 聊天程序 进行实际应用。
-
分隔符拆包器 DelimiterBasedFrameDecoder
每个应用层数据包,都通过自定义的分隔符,进行分割拆分。
这个版本,是LineBasedFrameDecoder 的通用版本,本质上是一样的。
这个显然不大适应在 Java 聊天程序 进行实际应用。
-
基于数据包长度的拆包器 LengthFieldBasedFrameDecoder
将应用层数据包的长度,作为接收端应用层数据包的拆分依据。按照应用层数据包的大小,拆包。这个拆包器,有一个要求,就是应用层协议中包含数据包的长度。
这个显然比较适和在 Java 聊天程序 进行实际应用。下面我们来应用这个拆分器。
拆包之前的消息包装
在使用LengthFieldBasedFrameDecoder 拆包器之前 ,在发送端需要对protobuf 的消息包进行一轮包装。
发送端包装的方法是:
在实际的protobuf 二进制消息包的前面,加上四个字节。
前两个字节为版本号,后两个字节为实际发送的 protobuf 的消息长度。

强调一下,二进制消息包装,在发送端进行。
修改发送端的编码器 ProtobufEncoder ,代码如下:
/**
* 编码器
*/
public class ProtobufEncoder extends MessageToByteEncoder<ProtoMsg.Message>
{
@Override
protected void encode(ChannelHandlerContext ctx, ProtoMsg.Message msg, ByteBuf out)
throws Exception
{
byte[] bytes = msg.toByteArray();// 将对象转换为byte
int length = bytes.length;// 读取 ProtoMsg 消息的长度
ByteBuf buf = Unpooled.buffer(2 + length);
// 先将消息协议的版本写入,也就是消息头
buf.writeShort(Constants.PROTOCOL_VERSION);
// 再将 ProtoMsg 消息的长度写入
buf.writeShort(length);
// 写入 ProtoMsg 消息的消息体
buf.writeBytes(bytes);
//发送
out.writeBytes(buf);
}
}
发送端的步骤是:
- 先将消息协议的版本写入,也就是消息头
buf.writeShort(Constants.PROTOCOL_VERSION);
-
再将 ProtoMsg 消息的长度写入
buf.writeShort(length); -
最后,写入 ProtoMsg 消息的消息体
buf.writeBytes(bytes);
开发一个接收端的自定义拆包器
使用Netty中,基于长度域拆包器 LengthFieldBasedFrameDecoder,按照实际的应用层数据包长度来拆分。
需要做两个工作:
- 设置长度信息(长度域)在数据包中的位置。
- 设置长度信息(长度域)自身的长度,也就是占用的字节数。
在前面的小节中,我们的长度信息(长度域)的占用字节数为 2个字节; 在报文中的所处的位置,长度信息(长度域)处于版本号之后。
版本号是2个字节,从0开始数,长度信息(长度域)的在数据包中的位置为2。
这些数据定义在Constansts常量类中。
public class Constants
{
//协议版本号
public static final short PROTOCOL_VERSION = 1;
//头部的长度: 版本号 + 报文长度
public static final short PROTOCOL_HEADLENGTH = 4;
//长度的偏移
public static final short LENGTH_OFFSET = 2;
//长度的字节数
public static final short LENGTH_BYTES_COUNT = 2;
}
有了这些数据之后,可以基于Netty 的长度拆包器 LengthFieldBasedFrameDecoder, 开发自己的长度分割器。
新开发的分割器为PackageSpliter,代码如下:
package com.crazymakercircle.chat.common.codec;
public class PackageSpliter extends LengthFieldBasedFrameDecoder
{
public PackageSpliter() {
super(Integer.MAX_VALUE, Constants.LENGTH_OFFSET,Constants.LENGTH_BYTES_COUNT);
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
return super.decode(ctx, in);
}
}
分割器 PackageSpliter 继承了 LengthFieldBasedFrameDecoder,传入了三个参数。
- 长度的偏移量 ,这里是 Constants.LENGTH_OFFSET,值为 2
- 长度的字节数,这里是 Constants.LENGTH_BYTES_COUNT,值为 2
- 最大的应用包长度,这里是 Integer.MAX_VALUE,表示不限制
分割器 写好之后,只需要在 pipeline 的最前面加上这个分割器,就可以使用这个分割器(自定义的拆包器)。
自定义拆包器的实际应用
在服务器端的 pipeline 的最前面加上这个分割器,代码如下:
package com.crazymakercircle.chat.server;
//...
@Service("ChatServer")
public class ChatServer
{
static final Logger LOGGER = LoggerFactory.getLogger(ChatServer.class);
//...
//有连接到达时会创建一个channel
protected void initChannel(SocketChannel ch) throws Exception
{ //应用自定义拆包器
ch.pipeline().addLast(new PackageSpliter());
ch.pipeline().addLast(new ProtobufDecoder());
ch.pipeline().addLast(new ProtobufEncoder());
// pipeline管理channel中的Handler
// 在channel队列中添加一个handler来处理业务
ch.pipeline().addLast("serverHandler", serverHandler);
}
});
//....
}
在发送端的 pipeline 的最前面加上这个分割器,代码也是类似的, 这里不再赘述。大家可以下载源码查看。
为什么拆包器要加在pipeline 的最前面
这一点,需要从PackageSpliter 的根源讲起。
下面是自定义分割器 PackageSpliter 的继承关系图。
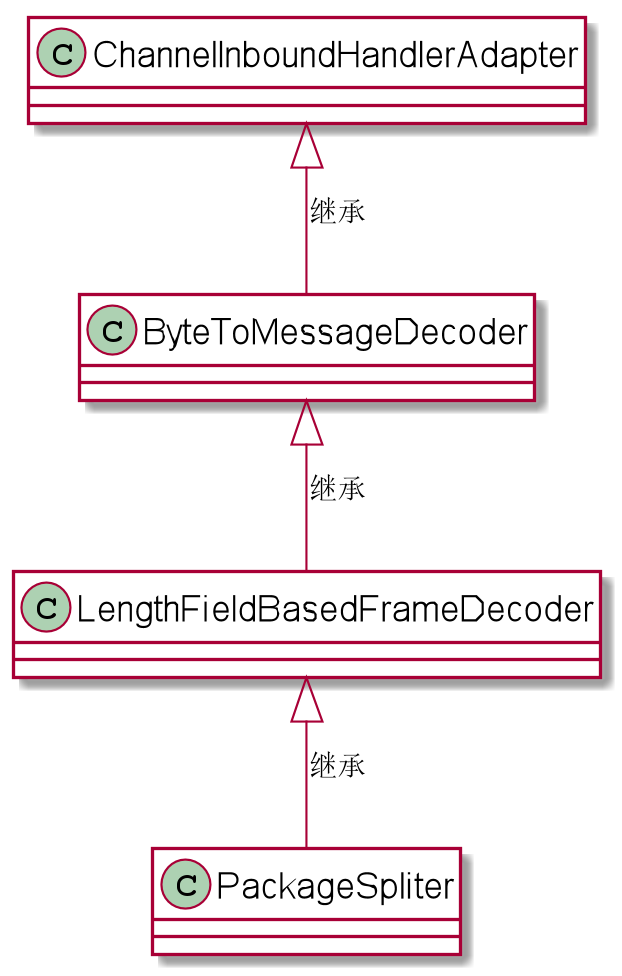
由此可见,分割器 PackageSpliter 继承了ChannelInboundHandlerAdapter。
本质上,它是一个入站处理器。
在 关于Netty的入站处理流程一文 Pipeline inbound 中, 我们已经知道,Netty的入站处理的顺序,是从pipelin 流水线的前面到后面。
由于在入站过程中,解码器 ProtobufDecoder 进行应用层 protobuf 的数据包的解码,而在此之前,必须完成应用包的正确分割。
所以, 分割器 PackageSpliter 必须处于入站流水线处理的第一站,放在最前面。
题外话, PackageSpliter 分割器 和 ProtobufEncoder 编码器 是否有关系呢?
从流水线处理的角度来说,是没有次序关系的。
PackageSpliter 是入站处理器。 在入站流程中用到。
ProtobufEncoder 是出站处理器,在出站流程中用到。
特别提示一下: 发送端不存在粘包和半包问题。这是接收端的事情。
总之,在出站和入站处理流程上,分割器 PackageSpliter 和 编码器ProtobufEncoder , 没有半毛钱关系的。
写在最后
至此为止,终于完成了 Java 聊天程序【 亿级流量】实战的一些基础开发工作。
包括了协议的编码解码。包括了粘包和半包的拆包处理。
大家好,我是作者尼恩。 为大家预告一下接下来的工作:
下一步,基本上可以开始[ 疯狂创客圈 IM] 聊天器的正式设计和开发的详细讲解了。
疯狂创客圈 实战计划
- Java (Netty) 聊天程序【 亿级流量】实战 开源项目实战
- Netty 源码、原理、JAVA NIO 原理
- Java 面试题 一网打尽
- 疯狂创客圈 【 博客园 总入口 】
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/169705.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
