大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
缓存穿透
数据库中没有这个数据,内存中也没有这个数据
简单场景
public class demoController {
public R selectOrderById(int id){
Object redisObj = ValueOperations.get(Strubg.valueof(id));
if(redisObj != null){
return new R().setCode(200).setData(redisObj).setMsg("OK"); //从缓存中取出数据
}
try{
Order order = orderMapper.selectObjectById(id); //如果缓存中没有则从数据库中取出数据
if(order != null){
ValueOperations.set(String.valueOf(id),order,10, TimeUnit.MINUTES); //如果数据库中存在,则存储到内存中
return new R().setCode(200).setData(order).setMsg("OK");
}
}
return new R().setCode(500).setData(new NullValueResultDO().setMsg("查询无果")); //返回数据
}
}
解决方案:
-
缓存空对象
优点: 方案简单,便于维护
缺点:会产生大量空对象在内存中,消耗内存
public class demoController {
public R selectOrderById(int id){
Object redisObj = ValueOperations.get(Strubg.valueof(id));
if(redisObj != null){
if(redisObj instanceof NullValueResultDO){
//如果是空数据 则从缓存中取出
return new R().setCode(500).setData(new NullValueResultDO()).setMsg("查询无果"); //
}
return new R().setCode(200).setData(redisObj).setMsg("OK"); //从缓存中取出数据
}
try{
Order order = orderMapper.selectObjectById(id); //如果缓存中没有则从数据库中取出数据
if(order != null){
ValueOperations.set(String.valueOf(id),order,10, TimeUnit.MINUTES); //如果数据库中存在,则存储到内存中
return new R().setCode(200).setData(order).setMsg("OK");
}else{
ValueOperations.set(String.valueOf(id),new NullValueResultDo(),10,TimeUnit.MINUTES); //如果数据库中没有数据,缓存中加入空数据,以防止缓存击穿
}
}
return new R().setCode(500).setData(new NullValueResultDO().setMsg("查询无果"));
}
}
- 布隆过滤器
布隆过滤器可以用来判断一个元素是否在一个集合中。它的优势是只需要占用很小的内存空间以及有着高效的查询效率。我们可以在查询数据库之前检查该值是否在布隆过滤器中
导入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
底层原理
布隆过滤器底层是一个数组


每一个put进来的值会经过几个hash函数运算(预测插入数据的数量和容错率,系统自动推断出来设置几个hash函数合适),然后映射到响应为位上,将响应位的bit置为1。当查询值是否在布隆过滤器中的时候,将该值与上述hash函数运算,如果各个位置的bit均为1,则判断该值极有可能在布隆过滤器中。
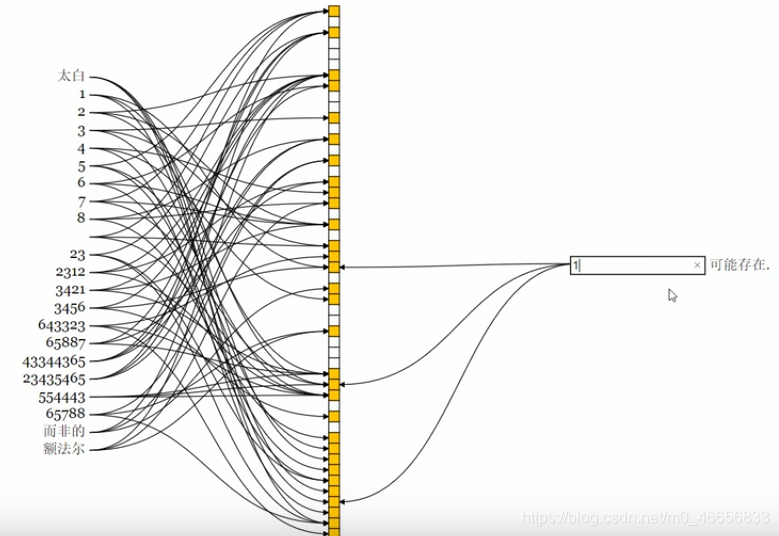
通过可能要插入的数据数量和容错率来估计设置多大的数组和多少个Hash函数合适

private static int size = 1000000; //可能要存入的数据
// 布隆过滤器
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(),size,0.01); //fpp为容错率
@Test
public void test() throws JsonProcessingException {
for(int i = 0;i < size;i ++){
bloomFilter.put(i);
}
int count = 0;
for(int i = size;i < 2 * size ;i ++){
if(bloomFilter.mightContain(i)) //判断布隆过滤器中是否存在值
count ++;
}
System.out.println(count);
}

可以看出结果大概等于 查询次数 x 容错率
以上为谷歌布隆过滤器
优缺点
但是谷歌布隆过滤器是单机版的,如果我们用分布式的话,不会为每个集群都创建一个布隆过滤器,这样相当于数据多了几份。而且谷歌布隆过滤器使用的是JVM内存,掉电即丢失。而Redis布隆过滤器是具有持久化功能,可以存到本地。
自定义Redis布隆过滤器
package com.config;
import com.google.common.base.Preconditions;
import com.google.common.hash.Funnel;
import com.google.common.hash.Hashing;
import org.springframework.beans.factory.annotation.Configurable;
@Configurable
public class BloomFilterHelper<T> {
private int numHashFunctions; //Hash函数的个数
private int bitSize; //数组长度
private Funnel<T> funnel;
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
bitSize = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/** * 计算bit数组长度 */
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/** * 计算hash方法执行次数 */
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}
package com.redislock;
import com.config.BloomFilterHelper;
import com.google.common.base.Preconditions;
import org.springframework.stereotype.Component;
import redis.clients.jedis.JedisCluster;
@Component
public class RedisBloomFilter<T> {
private JedisCluster cluster;
public RedisBloomFilter(JedisCluster jedisCluster) {
this.cluster = jedisCluster;
}
/** * 根据给定的布隆过滤器添加值 */
public <T> void addByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
//redisTemplate.opsForValue().setBit(key, i, true);
cluster.setbit(key, i, true);
}
}
/** * 根据给定的布隆过滤器判断值是否存在 */
public <T> boolean includeByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
//if (!redisTemplate.opsForValue().getBit(key, i)) {
if (!cluster.getbit(key, i)) {
return false;
}
}
return true;
}
}
缓存击穿
缓存击穿是指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到数据库。
解决方案:
可以使用双重缓存解决
//方法3
public List<String> getData03() {
List<String> result = new ArrayList<String>();
// 从缓存读取数据
result = getDataFromCache();
if (result.isEmpty()) {
synchronized (lock) {
//双重判断,第二个以及之后的请求不必去找数据库,直接命中缓存
// 查询缓存
result = getDataFromCache();
if (result.isEmpty()) {
// 从数据库查询数据
result = getDataFromDB();
// 将查询到的数据写入缓存
setDataToCache(result);
}
}
}
return result;
}
可以用一下方实来实现并发
static Lock reenLock = new ReentrantLock();
public List<String> getData04() throws InterruptedException {
List<String> result = new ArrayList<String>();
// 从缓存读取数据
result = getDataFromCache();
if (result.isEmpty()) {
if (reenLock.tryLock()) {
try {
System.out.println("我拿到锁了,从DB获取数据库后写入缓存");
// 从数据库查询数据
result = getDataFromDB();
// 将查询到的数据写入缓存
setDataToCache(result);
} finally {
reenLock.unlock();// 释放锁
}
} else {
result = getDataFromCache();// 先查一下缓存
if (result.isEmpty()) {
System.out.println("我没拿到锁,缓存也没数据,先小憩一下");
Thread.sleep(100);// 小憩一会儿
return getData04();// 重试
}
}
}
return result;
}
当然,在实际分布式场景中,我们还可以使用 redis、tair、zookeeper 等提供的分布式锁来实现。
缓存雪崩
所谓缓存雪崩就是在某一个时刻,缓存集大量失效或者机器Down机。所有流量直接打到数据库上,对数据库造成巨大压力;
缓存雪崩是由于原有缓存失效(过期),新缓存未到期间。所有请求都去查询数据库,而对数v据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
导致这种现象可能的原因:
1、例如 “缓存并发”,“缓存穿透”,“缓存颠簸” 等问题,这些问题也可能会被恶意攻击者所利用。
2、例如 某个时间点内,系统预加载的缓存周期性集中失效了。解决方法:可以通过设置不同的过期时间,来错开缓存过期,从而避免缓存集中失效
解决方案
- 可以给缓存设置过期时间时加上一个随机值时间,使得每个key的过期时间分布开来,不会集中在同一时刻失效。
- :尽量保证整个redis集群的高可用性,发现机器宕机尽快补上
- 如果缓存数据库时分布式部署,将热点数据均匀分布在不同缓存数据库中
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/168968.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
