大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
一、主题式网络爬虫设计设计方案
1.爬虫名称:2020年当下软件园软件下载总排行榜。
2.爬取内容:排名、软件类型、软件名称、用户评分、内存大小、评级。
3.爬虫设计方案概述:
(1)思路:找到要爬取的网页,按F12查看网页代码,找到所要爬取的数据及分析标签,导入相应库,然后开始对数据进行爬取,进行数据的清洗、处理、可视化和保存。
(2)技术难点:爬取内容多不好做数据可视化处理和回归方程,对python理解不够透彻,回归方程不是很理解。实在是不会;而且代码做不到400行。
二、主题页面的结构特征分析
1.主题页面的结构与特征分析
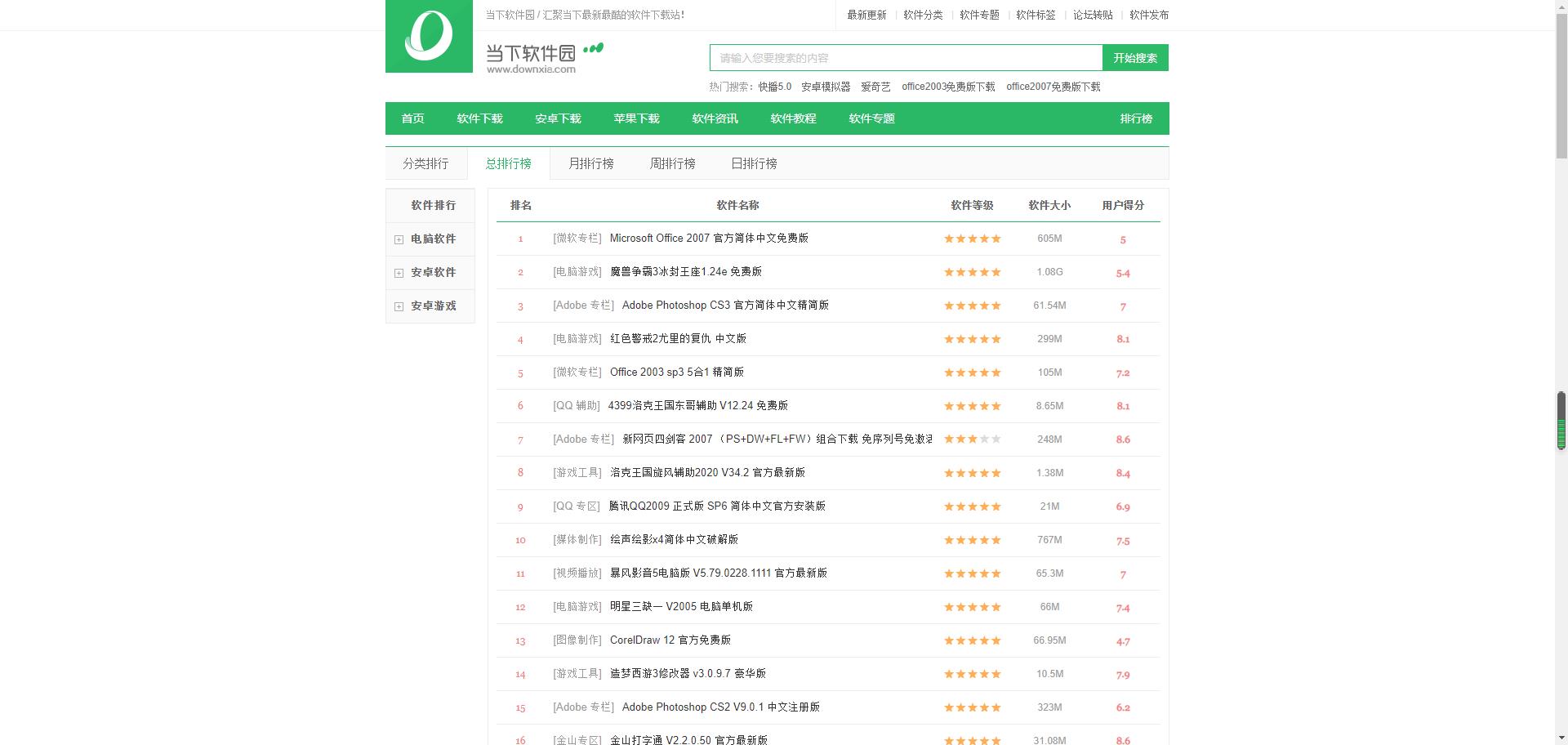

2.Htmls页面解析
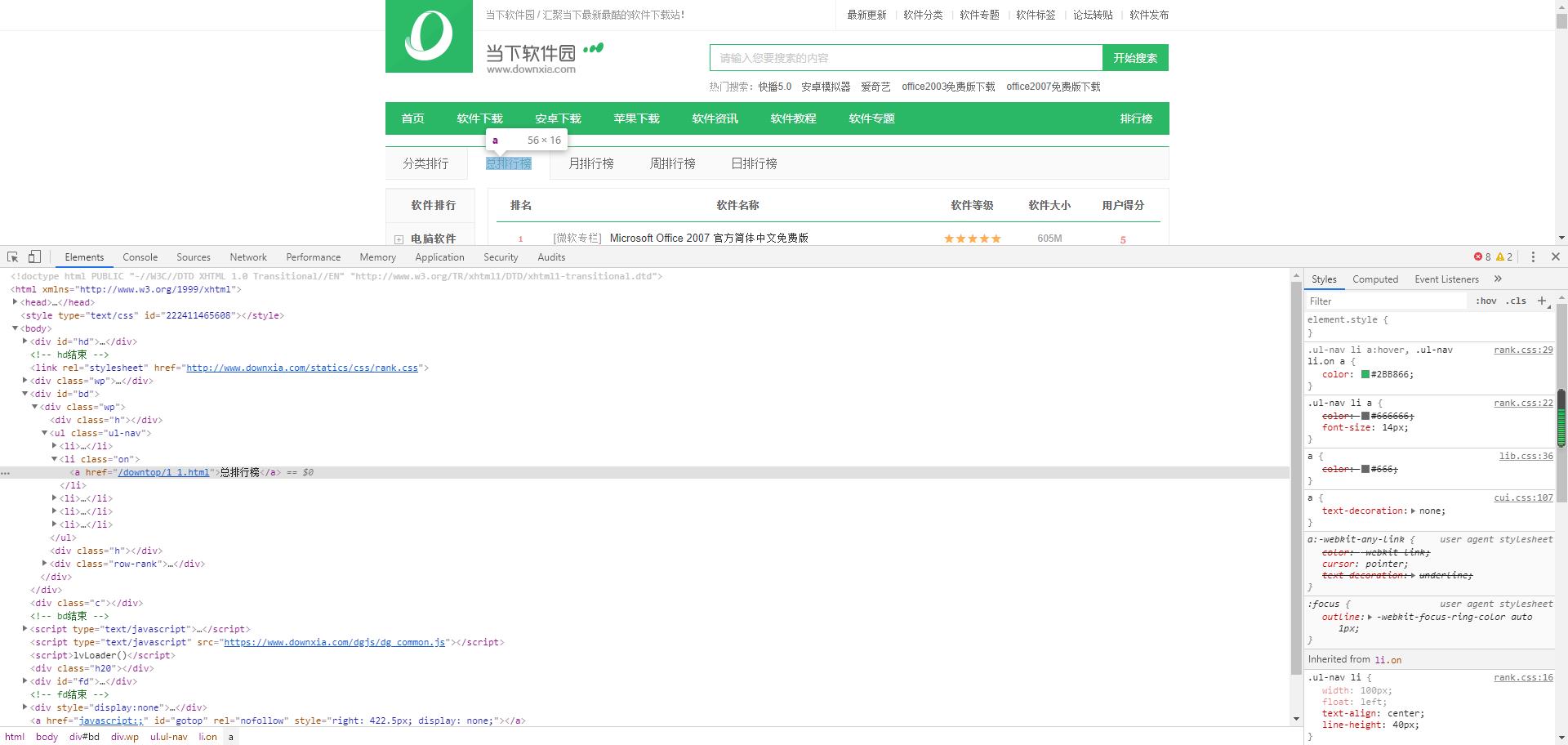
3.节点查找
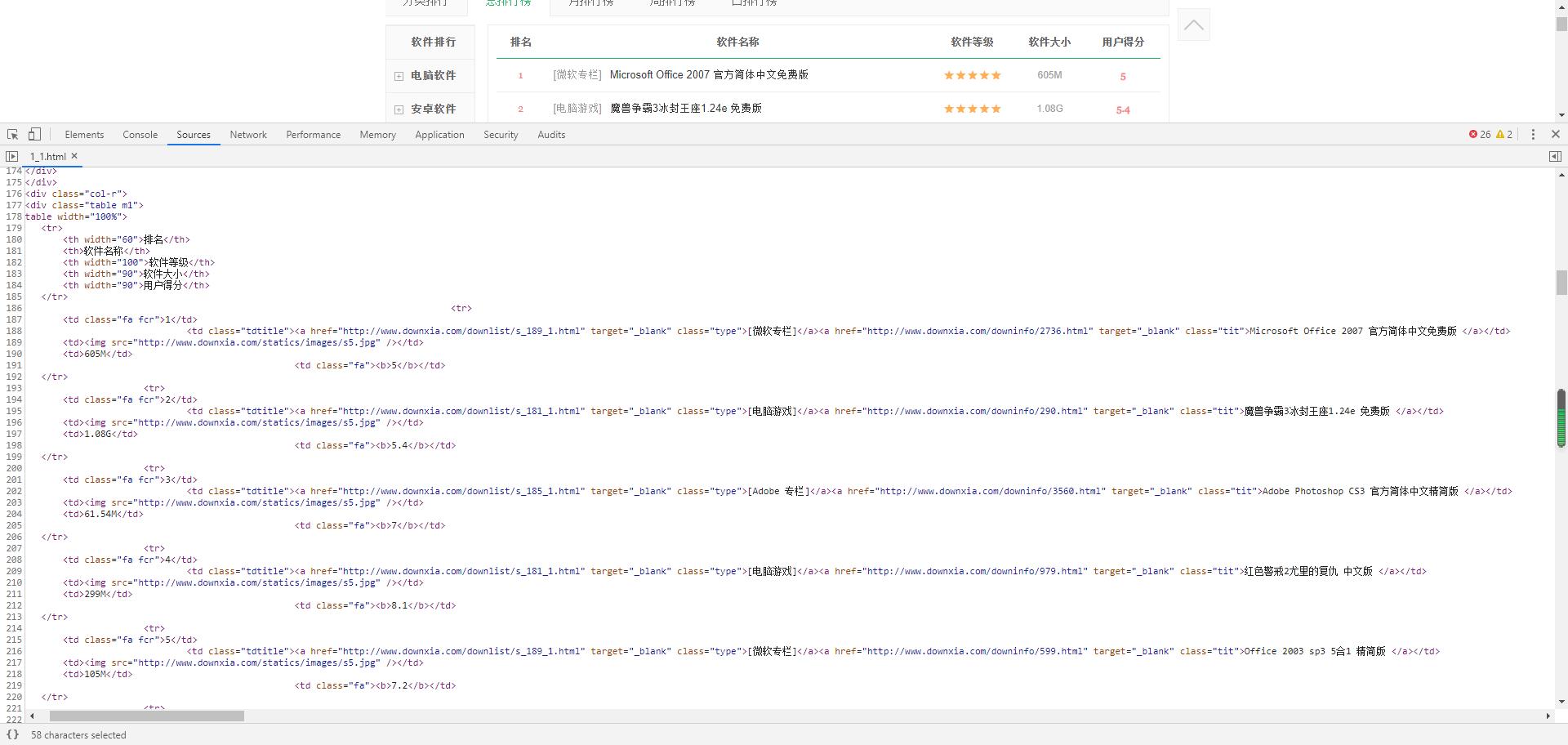
三、网络爬虫程序设计
1.数据爬取与采集
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 import pandas as pd 5 import matplotlib.pyplot as plt 6 import numpy as np 7 import re 8 import scipy as sp 9 from scipy.optimize import leastsq 10 import matplotlib as mpl 11 from numpy import genfromtxt 12 import seaborn as sns 13 url = 'http://www.downxia.com/downtop/1_1.html' 14 def f(s): 15 try: 16 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'} 17 r=requests.get(s,timeout=30,headers=headers) 18 r.raise_for_status() 19 r.encoding=r.apparent_encoding 20 soup=BeautifulSoup(r.text,'lxml') 21 return soup 22 except: 23 return "" 24 soup=f(url) 25 type1=[] 26 name=[] 27 fraction=[] 28 size_=[] 29 grade_=[] 30 for link1 in soup.find_all(class_='type'): 31 type1.append(link1.get_text()) 32 for link2 in soup.find_all(class_='tit'): 33 name.append(link2.get_text().strip()) 34 35 for link3 in soup.find_all('td',class_='fa'): 36 fraction.append(link3.get_text().strip()) 37 for i in range(0,200): 38 if i%2==0: 39 del fraction[0] 40 else: 41 fraction.append(fraction[0]) 42 del fraction[0] 43 44 for link4 in soup.find_all("img"): 45 grade_.append(link4) 46 grade_s=re.findall("s[0-5]",str(grade_)) 47 grade=re.findall("\d",str(grade_s)) 48 #print(len(grade),grade) 49 50 size_= re.findall("<td>[A-Za-z0-9|.]+[A-Z]</td>",str(soup)) 51 size=re.findall("[0-9|.]+[A-Z]",str(size_)) 52 #print(len(size),size) 53 paiming=[] 54 for i in range(len(name)): 55 paiming.append("第{:}名".format(i+1)) 56 data=pd.DataFrame([paiming,type1,name,fraction,size,grade],index=["排名","软件类型","软件名称","用户评分","内存大小","评级"]).T 57 print(data.loc[0:100,]) 58 59 index=range(0,len(type1)) 60 s=pd.Series(type1,index) 61 #print(s.value_counts().iloc[0:3]) 62 63 fraction.sort(reverse=True) 64 #正常显示中文文字 65 mpl.rcParams['font.sans-serif'] = ['KaiTi'] 66 mpl.rcParams['font.serif'] = ['KaiTi'] 67 mpl.rcParams['axes.unicode_minus'] = False 68 69 70 #print(soup) 71 # print(fraction) 72 # print(type1) 73 # print(name) 74 # print(fraction) 75 76 # plt.figure(figsize=(10,6)) 77 # plt.scatter(str(type1),fraction.color="green",label="样本数据",linewidth=2) 78 # plt.grid() 79 # plt.show() 80 81 # a=type1[0:100] 82 # b=fraction[0:100] 83 # print(a,b) 84 # print(len(type1),len(fraction)) 85 # sns.regplot(str(a),b)



2.对数据进行清洗和处理
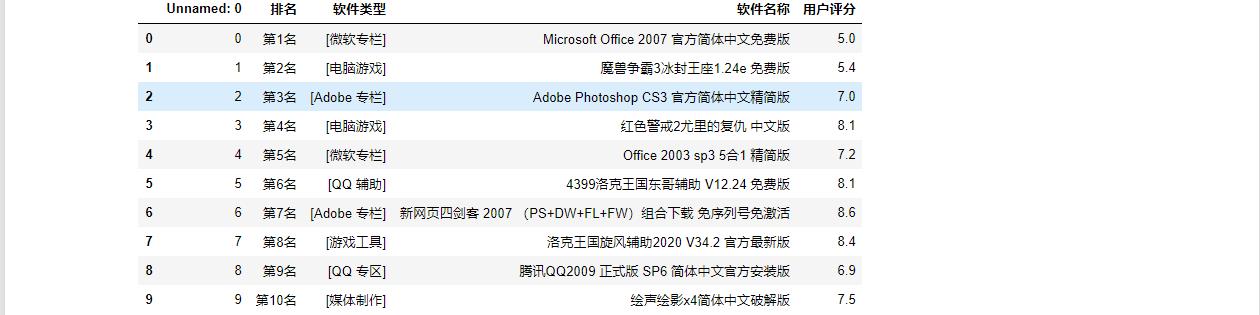
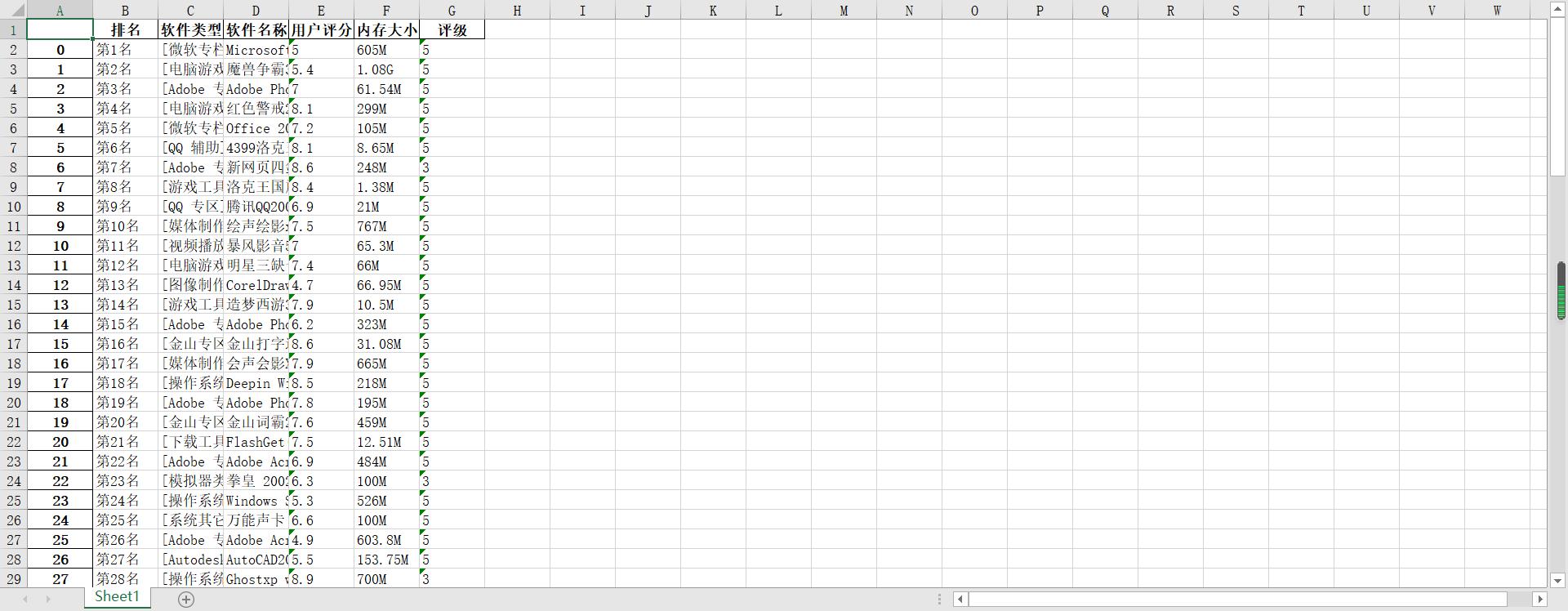
1 #读取文件显示前10行 2 3 wb = pd.DataFrame(pd.read_excel('D:\\2020年当下软件园总排行榜.xlsx')) 4 wb.head(10)
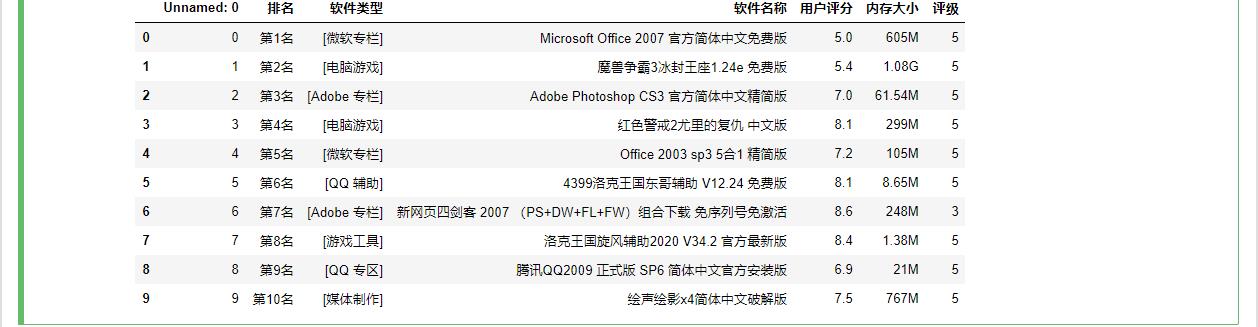
1 #检查是否有空值 2 3 4 5 wb.isnull().sum()

#检查是否有缺失值 wb.isnull()

1 删除无效行和列 2 3 wb.drop('内存大小', axis=1, inplace = True) 4 wb.drop('评级', axis=1, inplace = True) 5 wb.head(10)
3,数据分析和可视化
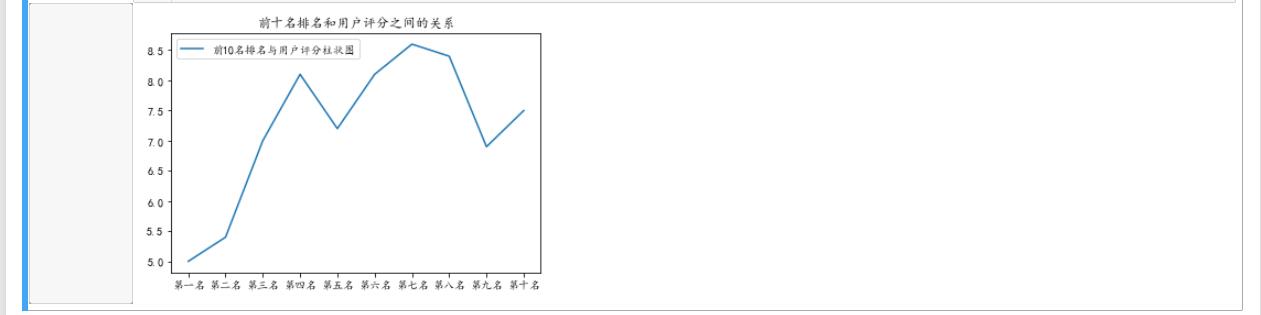
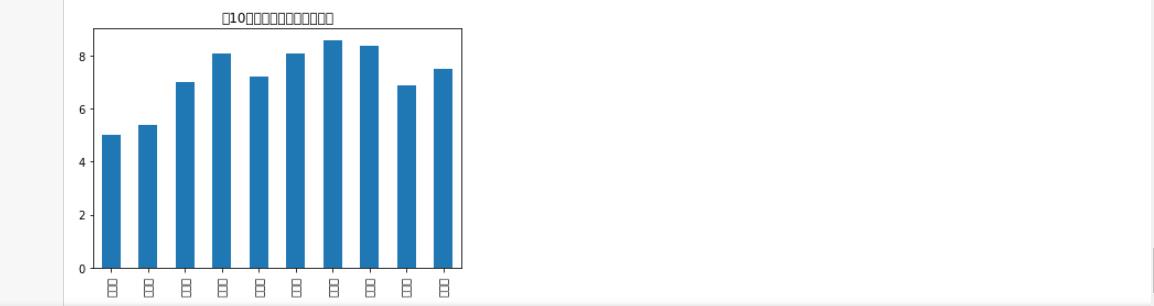
1 #绘制折线图 2 3 4 plt.plot(['第一名','第二名','第三名','第四名','第五名','第六名','第七名','第八名','第九名','第十名'], 5 [5,5.4,7,8.1,7.2,8.1,8.6,8.4,6.9,7.5],label="前10名排名与用户评分柱状图") 6 plt.title("前十名排名和用户评分之间的关系") 7 plt.legend() 8 plt.show()
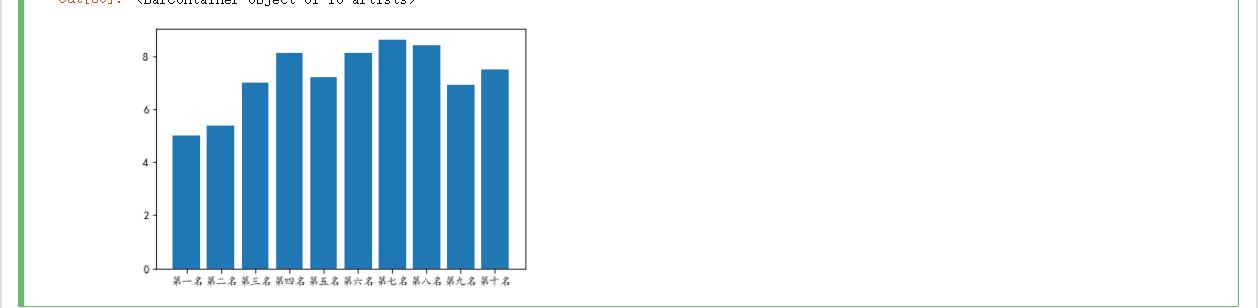
1 绘制垂直柱状图 2 3 plt.bar(['第一名','第二名','第三名','第四名','第五名','第六名','第七名','第八名','第九名','第十名'], 4 [5,5.4,7,8.1,7.2,8.1,8.6,8.4,6.9,7.5],label="前10名排名与用户评分柱状图")
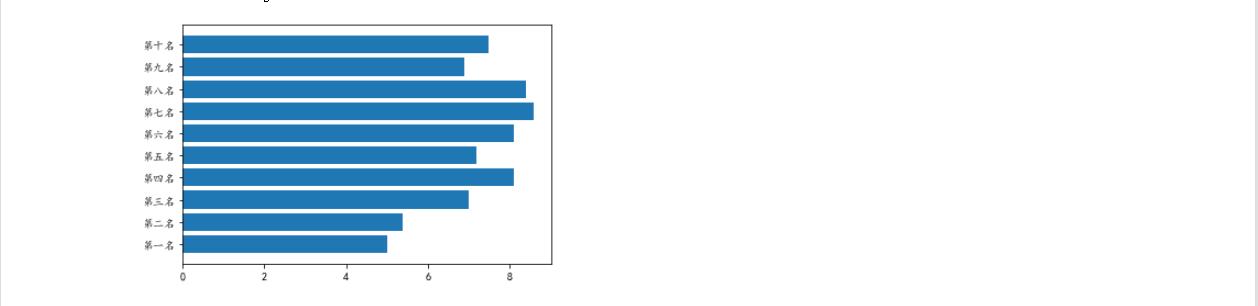
1 #水平柱状图 2 3 plt.barh(['第一名','第二名','第三名','第四名','第五名','第六名','第七名','第八名','第九名','第十名'], 4 [5,5.4,7,8.1,7.2,8.1,8.6,8.4,6.9,7.5],label="前10名排名与用户评分柱状图")
1 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] #用来正常显示中文标签 2 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 3 data=np.array([5,5.4,7,8.1,7.2,8.1,8.6,8.4,6.9,7.5]) 4 index=['第一名','第二名','第三名','第四名','第五名','第六名','第七名','第八名','第九名','第十名'] 5 s = pd.Series(data, index) 6 s.name='前10名排名与用户评分柱状图' 7 s.plot(kind='bar',title='前10名排名与用户评分柱状图') 8 plt.show()
5.持久化
1 #创建文件名 2 3 wb ='D:\\2020年当下软件园总排行榜.xlsx' 4 #将数据保存 5 6 data.to_excel(wb)
6.附上完整代码
1 #导入相应库 2 3 import requests 4 from bs4 import BeautifulSoup 5 import bs4 6 import pandas as pd 7 import matplotlib.pyplot as plt 8 import numpy as np 9 import re 10 import scipy as sp 11 from scipy.optimize import leastsq 12 import matplotlib as mpl 13 from numpy import genfromtxt 14 import seaborn as sns 15 url = 'http://www.downxia.com/downtop/1_1.html'#网站网址 16 def f(s): 17 try: #伪装爬虫 18 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'} 19 r=requests.get(s,timeout=30,headers=headers) 20 r.raise_for_status() 21 r.encoding=r.apparent_encoding 22 soup=BeautifulSoup(r.text,'lxml') 23 return soup 24 except: 25 return "" 26 soup=f(url) #设置空列表 27 #储存软件类型 28 type1=[] 29 #储存软件名称 30 name=[] 31 #储存用户评分 32 fraction=[] 33 #储存内存大小 34 size_=[] 35 #储存评级 36 grade_=[] 37 38 #用for循环爬取需要的数据 39 40 for link1 in soup.find_all(class_='type'): 41 type1.append(link1.get_text()) 42 for link2 in soup.find_all(class_='tit'): 43 name.append(link2.get_text().strip()) 44 45 for link3 in soup.find_all('td',class_='fa'): 46 fraction.append(link3.get_text().strip()) 47 for i in range(0,200): 48 if i%2==0: 49 del fraction[0] 50 else: 51 fraction.append(fraction[0]) 52 del fraction[0] 53 54 for link4 in soup.find_all("img"): 55 grade_.append(link4) 56 grade_s=re.findall("s[0-5]",str(grade_)) 57 grade=re.findall("\d",str(grade_s)) 58 #print(len(grade),grade) 59 60 size_= re.findall("<td>[A-Za-z0-9|.]+[A-Z]</td>",str(soup)) 61 size=re.findall("[0-9|.]+[A-Z]",str(size_)) 62 #print(len(size),size) 63 paiming=[] 64 for i in range(len(name)): 65 paiming.append("第{:}名".format(i+1)) 66 data=pd.DataFrame([paiming,type1,name,fraction,size,grade],index=["排名","软件类型","软件名称","用户评分","内存大小","评级"]).T 67 print(data.loc[0:100,]) 68 69 index=range(0,len(type1)) 70 s=pd.Series(type1,index) 71 #print(s.value_counts().iloc[0:3]) 72 73 fraction.sort(reverse=True) 74 #正常显示中文文字 75 mpl.rcParams['font.sans-serif'] = ['KaiTi'] 76 mpl.rcParams['font.serif'] = ['KaiTi'] 77 mpl.rcParams['axes.unicode_minus'] = False 78 79 #数据清洗和处理 80 81 #读取文件显示前10行 82 wb = pd.DataFrame(pd.read_excel('D:\\2020年当下软件园总排行榜.xlsx')) 83 wb.head(10) 84 85 #检查是否有空值 86 wb.isnull().sum() 87 88 #检查是否有缺失值 89 wb.isnull() 90 91 #删除无效行和列 92 wb.drop('内存大小', axis=1, inplace = True) 93 wb.drop('评级', axis=1, inplace = True) 94 wb.head(10) 95 96 #绘制前十名折线图 97 98 import matplotlib as mpl 99 plt.plot(['第一名','第二名','第三名','第四名','第五名','第六名','第七名','第八名','第九名','第十名'], 100 [5,5.4,7,8.1,7.2,8.1,8.6,8.4,6.9,7.5],label="前10名排名与用户评分柱状图") 101 plt.title("前十名排名和用户评分之间的关系") 102 plt.legend() 103 plt.show() 104 105 #绘制前十名垂直柱状图 106 107 plt.bar(['第一名','第二名','第三名','第四名','第五名','第六名','第七名','第八名','第九名','第十名'], 108 [5,5.4,7,8.1,7.2,8.1,8.6,8.4,6.9,7.5],label="前10名排名与用户评分柱状图") 109 110 #绘制前十名水平柱状图 111 112 plt.barh(['第一名','第二名','第三名','第四名','第五名','第六名','第七名','第八名','第九名','第十名'], 113 [5,5.4,7,8.1,7.2,8.1,8.6,8.4,6.9,7.5],label="前10名排名与用户评分柱状图") 114 115 #绘制前十名散点图 116 117 plt.scatter(['第一名','第二名','第三名','第四名','第五名','第六名','第七名','第八名','第九名','第十名'], 118 [5,5.4,7,8.1,7.2,8.1,8.6,8.4,6.9,7.5],label="前10名排名与用户评分柱状图") 119 plt.title("前十名排名和用户评分之间的关系") 120 plt.legend() 121 plt.show() 122 123 124 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] #用来正常显示中文标签 125 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 126 data=np.array([5,5.4,7,8.1,7.2,8.1,8.6,8.4,6.9,7.5]) 127 index=['第一名','第二名','第三名','第四名','第五名','第六名','第七名','第八名','第九名','第十名'] 128 s = pd.Series(data, index) 129 s.name='前10名排名与用户评分柱状图' 130 s.plot(kind='bar',title='前10名排名与用户评分柱状图') 131 plt.show() 132 133 134 135 136 #数据持久化 137 138 #创建文件名 139 wb ='D:\\2020年当下软件园总排行榜.xlsx' 140 #将数据保存 141 data.to_excel(wb) 142 143 #print(soup) 144 # print(fraction) 145 # print(type1) 146 # print(name) 147 # print(fraction) 148 149 # plt.figure(figsize=(10,6)) 150 # plt.scatter(str(type1),fraction.color="green",label="样本数据",linewidth=2) 151 # plt.grid() 152 # plt.show() 153 154 # a=type1[0:100] 155 # b=fraction[0:100] 156 # print(a,b) 157 # print(len(type1),len(fraction)) 158 # sns.regplot(str(a),b)
四、结论
1.结论:用户评分和排名并无多大关系,数据可视化后看起来更直观和明了。
2.小结:通过此次作业,让自己对python爬虫工具和数据可视化有了更全面和更深的了解,同时也认知到自己的许多不足之处和使用爬虫工具的简便性和全面性,今后会非常用心去学习和了解python。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167943.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
