大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
理论部分:
代码部分:
import random
import matplotlib.pyplot as plt
import numpy as np
position = 0
walk = [position]
steps = 1000
for i in range(steps):
step = 1 if random.randint(0, 1) else -1
position += step
walk.append(position)
#plt.plot(walk[:1000])
nsteps = 1000
draws = np.random.randint(0, 2, size=nsteps)
steps = np.where(draws > 0, 1, -1)
walk = steps.cumsum() # 一维向量就可以这样来
#plt.plot(walk[:1000])
print( "min:" + str(walk.min()) )
print( "max:" + str(walk.max()) )
# 需要多久才能距离初始0点至少10步远(任一方向均可)
print((np.abs(walk) >= 10).argmax())
nwalks = 5000
nsteps = 1000
#模拟多个随机漫步过程(比如5000个)
draws = np.random.randint(-1, 1, size=(nwalks, nsteps)) # 0 or 1
print(draws)
steps = np.where(draws >= 0, 1, -1)
print(steps)
walks = steps.cumsum(1)
print(walks)
print("max: " + str(walks.max()) )
print("min: " + str(walks.min()))
# 用any方法来对此进行检查 因为不是5000个过程都到达了30的距离
hits30 = (np.abs(walks) >= 30).any(1)
print("sum: " + str(hits30.sum()) ) # Number that hit 30 or -30
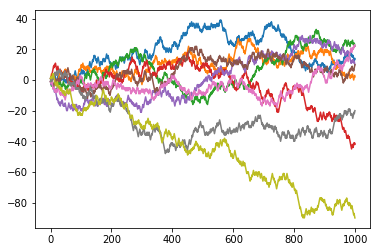
plt.plot(walks[0])
plt.plot(walks[1])
plt.plot(walks[2])
plt.plot(walks[3])
plt.plot(walks[4])
plt.plot(walks[5])
plt.plot(walks[6])
plt.plot(walks[7])
plt.plot(walks[8])


https://www.jianshu.com/p/numpy_test
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167028.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
