大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
与遗传算法的第一次接触
遗传算法是我进入研究生阶段接触的第一个智能算法,从刚开始接触,到后来具体去研究,再到后来利用遗传算法完成了水利水电的程序设计比赛,整个过程中对遗传算法有了更深刻的理解,在此基础上,便去学习和研究了粒子群算法,人工蜂群算法等等的群体智能算法。想利用这个时间,总结下我对于遗传算法的理解,主要还是些基本的知识点的理解。
##遗传算法的基本概念
遗传算法(Genetic Algorithm, GA)是由Holland提出来的,是受遗传学中的自然选择和遗传机制启发发展起来的一种优化算法,它的基本思想是模拟生物和人类进化的方法求解复杂的优化问题。
基本定义
- 个体(individual):在遗传学中表示的是基因编码,在优化问题中指的是每一个解。
- 适应值(fitness):评价个体好坏的标准,在优化问题中指的是优化函数。
- 群体(population): 由个体组成的集合
- 遗传操作:遗传操作的主要目的是用于在当前的群体中产生新的群体,主要的操作包括:选择(selection)、交叉(crossover)、变异(mutation)。
遗传算法的基本流程
遗传算法的过程中主要包括这样几个要素:1、参数的编码。2、初始群体的设定。3、适应度函数的设计。4、遗传操作设计。5、控制参数的设定。
基本遗传算法的具体过程如下:


遗传算法过程中的具体操作
参数的编码
遗传算法中的参数编码的方式主要有:1、二进制编码。2、Gray编码。3、实数编码。4、有序编码。
二进制编码
二进制编码是最原始的编码方式,遗传算法最初是在二进制编码的方式下进行运算的。二进制编码也是遗传算法中使用最为直接的运算编码方式。二进制编码是指利用 0 0 0和 1 1 1对问题的解向量进行编码。例如,对于如下的优化问题:
m a x f ( x 1 , x 2 ) = 21.5 + x 1 s i n ( 4 π x 1 ) + x 2 s i n ( 20 π x 2 ) max\; f\left ( x_1,x_2 \right )=21.5+x_1sin\left ( 4\pi x_1 \right )+x_2sin\left ( 20\pi x_2 \right ) maxf(x1,x2)=21.5+x1sin(4πx1)+x2sin(20πx2)
− 3.0 ≤ x 1 ≤ 12.1 ; 4.1 ≤ x 2 ≤ 5.8 -3.0\leq x_1\leq 12.1;4.1\leq x_2\leq 5.8 −3.0≤x1≤12.1;4.1≤x2≤5.8
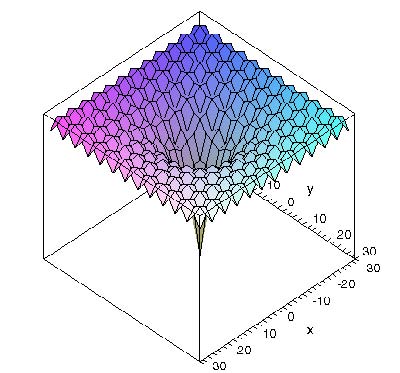
其三维图像如下图所示:
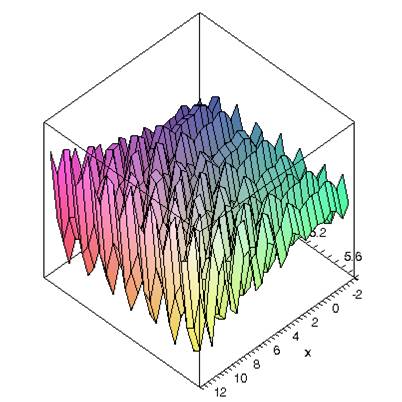
在对这样的优化问题进行二进制编码的过程中,是将问题的可能解编码为二进制位串,例如问题的可能解为实数对 ( x 1 , x 2 ) \left ( x_1,x_2 \right ) (x1,x2),首先必须将 x 1 x_1 x1和 x 2 x_2 x2分别使用二进制位串表示,然后将他们的二进制位串组合在一起。对于每一个变量的二进制位串的长度取决于变量的定义域所要求的精度。
二进制位串的长度的计算方法如下:
假设 a j ≤ x j ≤ b j a_j\leq x_j\leq b_j aj≤xj≤bj,所要求的精度是小数点后 t t t位。这要求将区间划分为至少 ( b j − a j ) 1 0 t \left ( b_j-a_j \right )10^t (bj−aj)10t份。假设表示变量 x j x_j xj的位串的长度用 l j l_j lj表示,则 l j l_j lj可取为满足下列不等式的最小数 m m m:
( b j − a j ) 1 0 t ≤ 2 m − 1 \left ( b_j-a_j \right )10^t\leq 2^m-1 (bj−aj)10t≤2m−1
即有:
2 l j − 1 − 1 < ( b j − a j ) 1 0 t ≤ 2 l j − 1 2^{l_j-1}-1<\left ( b_j-a_j \right )10^t\leq 2^{l_j}-1 2lj−1−1<(bj−aj)10t≤2lj−1
对于上述的优化问题,假设精度为小数点后 4 4 4位,则:
( 12.1 − ( − 3.0 ) ) × 10000 = 151000 \left ( 12.1-\left ( -3.0 \right ) \right )\times 10000=151000 (12.1−(−3.0))×10000=151000
2 17 − 1 < 151000 ≤ 2 18 − 1 2^{17}-1<151000\leq 2^{18}-1 217−1<151000≤218−1
那么表示变量 x 1 x_1 x1的二进制位串的长度为 l 1 = 18 l_1=18 l1=18。
同理,对于变量 x 2 x_2 x2:
( 5.8 − 4.1 ) × 10000 = 17000 \left ( 5.8-4.1 \right )\times 10000= 17000 (5.8−4.1)×10000=17000
2 14 − 1 < 17000 ≤ 2 15 − 1 2^{14}-1<17000\leq 2^{15}-1 214−1<17000≤215−1
表示变量 x 2 x_2 x2的二进制位串的长度为 l 2 − 15 l_2-15 l2−15。
此时,个体可以表示为:

其中,前 18 18 18位表示的是 x 1 x_1 x1,后 15 15 15位表示的是 x 2 x_2 x2。
Gray编码
这种编码方式在求解优化问题时,本人基本上没做过任何研究。
实数编码
在二进制编码的过程中存在这样的一个问题,即在计算适应值的时候需要将二进制编码转换成十进制的编码进行运算,这样,很显然会想到能否直接使用十进制编码直接进行运算,如上例中的 ( x 1 , x 2 ) \left ( x_1,x_2 \right ) (x1,x2)这样的编码方式。
有序编码
有序编码主要使用在TSP问题中,在本文中主要涉及二进制编码和实数编码。
初始群体的设定
在解决了个体的编码问题后,需要解决的问题是如何利用个体表示群体。在上述中,我们知道,群体是个体的集合。假设初始群体的大小为 N = 20 N=20 N=20。对于二进制编码方式与实数编码方式产生 20 20 20个初始解。如:
v 1 = ( 010001001011010000111110010100010 ) v_1=\left ( 010001001011010000111110010100010 \right ) v1=(010001001011010000111110010100010)
对应的实数编码的方式则为:
v 1 = ( 1.052426 , 5.755330 ) v_1=\left ( 1.052426,5.755330 \right ) v1=(1.052426,5.755330)
对于二进制编码则是随机初始化 20 20 20组这样的初始解,每组初始解随机初始化 33 33 33位的 0 − 1 0-1 0−1编码。而对于实数编码方式,则是在区间上随机初始化 20 20 20组初始解。
适应度函数的计算
适应度函数的目的是评价个体的好坏,如上面的优化问题中,即为最终的优化目标函数。对于二进制编码,则需要先将二进制编码转换成实数编码,再进行适应值函数的计算,对于实数编码方式,则直接进行适应值函数的计算。
遗传操作设计
遗传操作主要包括:选择(selection)、交叉(crossover)、变异(mutation),遗传操作的主要目的是从当前的群体中产生新的群体,这样便能使得产生新的更优的个体。
选择(selection)
选择操作的目的是选择出父体,用于参加交叉(crossover)和变异(mutation)操作。一般使用较多的方式是轮盘赌的选择策略(Roulette Wheel Selection)。根据每个个体的适应值,计算出相对适应值大小,即:
p i = f i ∑ f i p_i=\frac{f_i}{\sum f_i} pi=∑fifi
相对适应值又称为选择概率,将一个圆盘划分成 N N N份,即群体的大小。每个扇面的面积与其选择概率成正比。轮盘如下图所示:
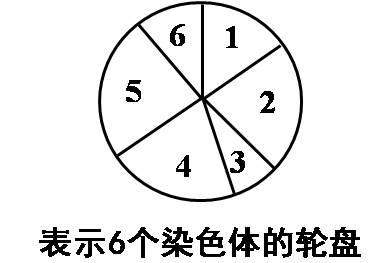
现在在 [ 0 , 1 ] \left [ 0,1 \right ] [0,1]上产生一个随机数 r r r,若:
p 1 + p 2 + ⋯ + p i − 1 < r ≤ p 1 + p 2 + ⋯ + p i p_1+p_2+\cdots+p_{i-1}<r\leq p_1+p_2+\cdots+p_i p1+p2+⋯+pi−1<r≤p1+p2+⋯+pi
则选择第 i i i个个体。
重复此操作 N N N次,选择出 N N N个父体。轮盘赌的算法过程如下所示:

交叉(crossover)
交叉操作也称为杂交,其目的是产生新的个体。
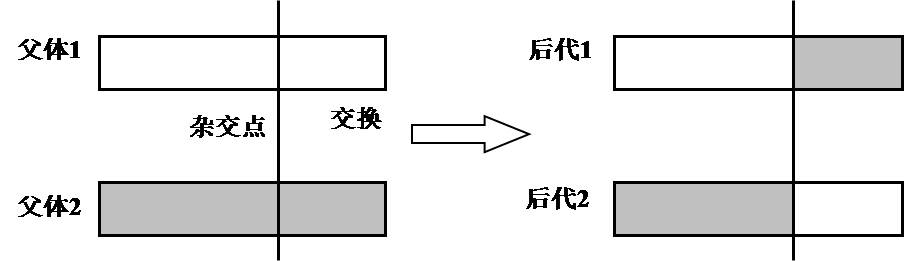
对于二进制编码方式,主要有单点杂交和多点杂交。单点杂交是指在二进制串中随机选择一位,交换两个父体中该位以后的二进制串,用以产生新的个体,操作如下图所示:
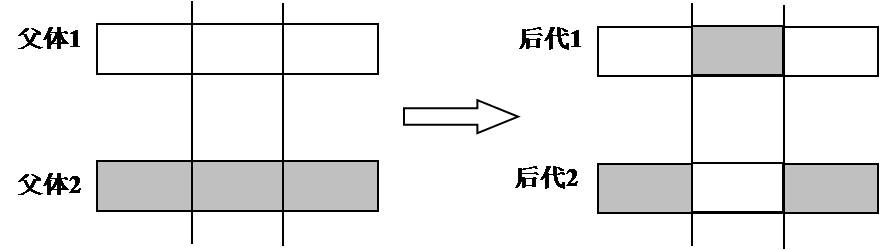
多点杂交是指在二进制串中选择某几位进行杂交,其中以两点杂交最为常见,其过程如下图所示:
具体的操作过程为:设定一个杂交的概率 p c p_c pc,对选择操作中产生的 N N N个父体,每个父体产生一个 [ 0 , 1 ] \left [ 0,1 \right ] [0,1]区间上的随机数 r k r_k rk,若 r k < p c r_k< p_c rk<pc,则将第 k k k个个体用于杂交,若选择出来的个体数目是奇数,则在父体集合中再随机挑选一个,以保证挑选出的是偶数个,之后进行两两杂交操作。
对于实数编码形式,可以将实数转换成二进制编码的形式进行杂交运算,但是这样同样存在效率的问题,在实数编码中,主要采用的是算术杂交方式,算术杂交分为:部分算术杂交和整体算术杂交。部分算术杂交是指在父体向量中选择一部分分量进行算术运算,而整体算术杂交是指全部的分量都进行算术运算。我们以整体算术杂交为例:先在 [ 0 , 1 ] \left [ 0,1 \right ] [0,1]生成 n n n个随机数 a 1 , a 2 , ⋯ , a n a_1,a_2,\cdots ,a_n a1,a2,⋯,an,经杂交算子后,所得到的两个后代为:
x ′ = ( a 1 x 1 + ( 1 − a 1 ) y 1 , a 2 x 2 + ( 1 − a 2 ) y 2 , ⋯ , a n x n + ( 1 − a n ) y n ) {x}’=\left ( a_1x_1+\left ( 1-a_1 \right )y_1,a_2x_2+\left ( 1-a_2 \right )y_2,\cdots ,a_nx_n+\left ( 1-a_n \right )y_n \right ) x′=(a1x1+(1−a1)y1,a2x2+(1−a2)y2,⋯,anxn+(1−an)yn)
y ′ = ( a 1 y 1 + ( 1 − a 1 ) x 1 , a 2 y 2 + ( 1 − a 2 ) x 2 , ⋯ , a n y n + ( 1 − a n ) x n ) {y}’=\left ( a_1y_1+\left ( 1-a_1 \right )x_1,a_2y_2+\left ( 1-a_2 \right )x_2,\cdots ,a_ny_n+\left ( 1-a_n \right )x_n \right ) y′=(a1y1+(1−a1)x1,a2y2+(1−a2)x2,⋯,anyn+(1−an)xn)
变异(mutation)
变异操作的目的是使得基因突变,在优化算法中,可以防止算法陷入局部最优,从而跳出局部最优,帮助算法找到全局最优解。
二进制编码时的变异算子非常简单,只是依一定的概率(称为变异概率)将所选个体的位取反。即若是 1 1 1,则取 0 0 0;若是 0 0 0,则取 1 1 1。
具体的操作为:设定一个变异概率 p m p_m pm,对杂交操作后的 N N N个父体,对父体中的每一个位产生一个 [ 0 , 1 ] \left [ 0,1 \right ] [0,1]区间上的随机数 r k , j r_{k,j} rk,j,若 r k , j < p m r_{k,j}< p_m rk,j<pm,则该位变异。
对于实数编码方式,可以采用均匀变异和非均匀变异方式,在均匀变异中,假设 x = ( x 1 , x 2 , ⋯ , x n ) x=\left ( x_1,x_2,\cdots ,x_n \right ) x=(x1,x2,⋯,xn)是要变异的个体,随机产生一个随机整数 k ∈ [ 1 , n ] k\in \left [ 1,n \right ] k∈[1,n],产生新的后代 x = ( x 1 , x 2 , ⋯ , x k ′ , ⋯ , x n ) x=\left ( x_1,x_2,\cdots ,{x}’_k,\cdots, x_n \right ) x=(x1,x2,⋯,xk′,⋯,xn),其中 x k ′ {x}’_k xk′是 [ l k , u k ] \left [ l_k, u_k \right ] [lk,uk]中服从均匀分布的一个随机数。
另一种是非均匀变异,,假设 x = ( x 1 , x 2 , ⋯ , x n ) x=\left ( x_1,x_2,\cdots ,x_n \right ) x=(x1,x2,⋯,xn)是要变异的个体,随机产生一个随机整数 k ∈ [ 1 , n ] k\in \left [ 1,n \right ] k∈[1,n],产生新的后代 x = ( x 1 , x 2 , ⋯ , x k ′ , ⋯ , x n ) x=\left ( x_1,x_2,\cdots ,{x}’_k,\cdots, x_n \right ) x=(x1,x2,⋯,xk′,⋯,xn),其中:
x k ′ = { x k + Δ ( t , u k − x k ) if R a n d o m ( 2 ) = 0 x k − Δ ( t , x k − l k ) if R a n d o m ( 2 ) = 1 {x}’_k=\begin{cases} x_k+\Delta \left ( t,u_k-x_k \right ) & \text{ if } Random(2)=0 \\ x_k-\Delta \left ( t,x_k-l_k \right ) & \text{ if } Random(2)=1 \end{cases} xk′={
xk+Δ(t,uk−xk)xk−Δ(t,xk−lk) if Random(2)=0 if Random(2)=1
这里 t t t是当前演化代数,函数 Δ ( t , y ) \Delta \left ( t,y \right ) Δ(t,y)返回 [ 0 , y ] \left [ 0,y \right ] [0,y]中的一个值,并且 Δ ( t , y ) \Delta \left ( t,y \right ) Δ(t,y)随 t t t的增加而趋于 0 0 0的概率增大。函数 Δ ( t , y ) \Delta \left ( t,y \right ) Δ(t,y)具体形式为:
Δ ( t , y ) = y ⋅ ( 1 − r ( 1 − t / T ) b ) \Delta \left ( t,y \right )=y\cdot \left ( 1-r^{\left ( 1-t/T \right )^b} \right ) Δ(t,y)=y⋅(1−r(1−t/T)b)
或者
Δ ( t , y ) = y ⋅ r ⋅ ( 1 − t T ) b \Delta \left ( t,y \right )=y\cdot r\cdot \left ( 1-\frac{t}{T} \right )^b Δ(t,y)=y⋅r⋅(1−Tt)b
其中, r r r是 [ 0 , 1 ] \left [ 0,1 \right ] [0,1]上的一个随机数, T T T表示最大演化代数。 b b b是确定非均匀度的一个参数,通常取 2 ∼ 5 2\sim 5 2∼5。
控制参数的设定
控制参数主要包括种群的规模 N N N,演化代数 T T T,杂交概率 p c p_c pc,变异概率 p m p_m pm等等。
在实现遗传算法时,一个常用的方法是将到当前代为止演化的最好个体单独存放起来,在遗传算法结束后,将演化过程中发现的最好个体作为问题的最优解或近似最优解。
求解优化问题的实例
问题描述
m i n f ( x 1 , x 2 , ⋯ , x n ) = − 20 ⋅ e x p ( − 0.2 1 n ∑ i = 1 n x i 2 ) − e x p ( 1 n ∑ i = 1 n c o s ( 2 π ⋅ x i ) ) + 20 + e min\; f\left ( x_1,x_2,\cdots ,x_n \right )=-20\cdot exp\left ( -0.2\sqrt{\frac{1}{n}\sum_{i=1}^{n}x^2_i} \right )-exp\left ( \frac{1}{n}\sum_{i=1}^{n}cos\left ( 2\pi \cdot x_i \right ) \right )+20+e minf(x1,x2,⋯,xn)=−20⋅exp(−0.2n1i=1∑nxi2)−exp(n1i=1∑ncos(2π⋅xi))+20+e
其中, − 30 ≤ x i ≤ 30 , i = 1 , 2 , ⋯ , n ; e = 2.71828 -30\leq x_i\leq 30,i=1,2,\cdots ,n;e=2.71828 −30≤xi≤30,i=1,2,⋯,n;e=2.71828
问题分析
这是一道不带约束条件的函数优化的问题,既可以采用二进制编码方式,也可以采用十进制的编码方式,在本题的解决过程中,采用十进制的编码方式。首先通过Matlab得到的函数图像大致如下,从图像中可以观察到当 n = 2 n=2 n=2时,我们可以在 ( 0 , 0 ) (0,0) (0,0)附近取得函数的最小值。
算法设计
基于以上的分析,当 n = 2 n=2 n=2时,以下分别从个体的编码、适应值函数、选择策略、杂交算子、变异算子、参数设置、初始化以及终止条件这八个方面对程序的设计作简要的描述:
个体编码
采用实数向量编码,每一个个体是一实数对 ( x 1 , x 2 ) \left ( x_1,x_2 \right ) (x1,x2)。
适应值函数
该优化问题是一个极小化问题,可对目标函数作简单变换,同时考虑到在选择策略时选择的是轮盘赌的选择策略,轮盘赌的选择策略有一个要求就是个体的适应值要为正数,因此,可以作如下的变换: F = 30 − f ( x 1 , x 2 ) F=30-f\left ( x_1,x_2 \right ) F=30−f(x1,x2),这里的 30 30 30是取的一个上界。这样,既保证了变换后的适应值函数式中为正,而且我们可以将极小化问题转换成一个极大值问题考虑。
选择策略
采用轮盘赌的选择策略,因为在计算适应值时已经作了处理,即适应值始终为正,这样就可以使用轮盘赌的选择策略。轮盘赌的选择策略是一种基于适应值比例的选择策略,适应值越大被选择到下一代的概率也会越大。
杂交算子
采用整体算术杂交,即给定两个父体,产生一个随机数,经杂交后得到两个后代个体, v 1 = ( x 1 , x 2 ) v_1=\left ( x_1,x_2 \right ) v1=(x1,x2), v 2 = ( y 1 , y 2 ) v_2=\left ( y_1,y_2 \right ) v2=(y1,y2),产生一个随机数 α ∈ [ 0 , 1 ] \alpha \in \left [ 0,1 \right ] α∈[0,1],经杂交后得到两个后代个体: v 1 ′ = ( α x 1 + ( 1 − α ) y 1 , α x 2 + ( 1 − α ) y 2 ) {v}’_1=\left ( \alpha x_1+\left ( 1-\alpha \right )y_1,\alpha x_2+\left ( 1-\alpha \right )y_2 \right ) v1′=(αx1+(1−α)y1,αx2+(1−α)y2), v 2 ′ = ( α y 1 + ( 1 − α ) x 1 , α y 2 + ( 1 − α ) x 2 ) {v}’_2=\left ( \alpha y_1+\left ( 1-\alpha \right )x_1,\alpha y_2+\left ( 1-\alpha \right )x_2 \right ) v2′=(αy1+(1−α)x1,αy2+(1−α)x2)。
变异算子
采用非均匀变异,即对于要变异的个体 x = ( x 1 , x 2 ) x=\left ( x_1,x_2 \right ) x=(x1,x2),随机产生整数 k ∈ { 1 , 2 } k\in \left \{ 1,2 \right \} k∈{
1,2},例如 k = 1 k=1 k=1,然后产生后代 x ′ = ( x 1 ′ , x 2 ) {x}’=\left ( {x}’_1,x_2 \right ) x′=(x1′,x2),其中
x 1 ′ = { x 1 + Δ ( t , u 1 − x 1 ) if R a n d o m ( 2 ) = 0 x 1 − Δ ( t , x 1 − l 1 ) if R a n d o m ( 2 ) = 1 {x}’_1=\begin{cases} x_1+\Delta \left ( t,u_1-x_1 \right ) & \text{ if } Random(2)= 0\\ x_1-\Delta \left ( t,x_1-l_1 \right ) & \text{ if } Random(2)= 1 \end{cases} x1′={
x1+Δ(t,u1−x1)x1−Δ(t,x1−l1) if Random(2)=0 if Random(2)=1
参数设置
- 种群规模 N = 100 N=100 N=100
- 个体长度 S i z e = 2 Size=2 Size=2
- 演化代数 T = 3000 T=3000 T=3000
- 杂交概率 p c = 0.7 p_c=0.7 pc=0.7
- 变异概率 p m = 0.1 p_m=0.1 pm=0.1
- 函数上界 U p p = 30.0 Upp = 30.0 Upp=30.0
初始化
在区间内随机初始化种群的个体,并置个体的适应值,适应值之和以及相对适应值比例为 0 0 0。
终止条件
采用代数作为终止条件,当算法运行到指定的最大代数时,程序停止。
实验代码
#include<iostream>
#include<time.h>
#include<stdlib.h>
#include<cmath>
#include<fstream>
using namespace std;
const int COLONY_SIZE=100; //个体数目
const int Size=2;//个体的长度
const int Generation=3000;//代数
const double OVER=0.7;//杂交的概率
const double MUTATE=0.1;//变异的概率
const double UPPER=30.0;//函数的上界
struct Indival
{
double code[Size];
double fitness;
double cfitness;
double rfitness;
}Group[COLONY_SIZE];
Indival newGroup[COLONY_SIZE];
Indival bestChrom;//记录最好的个体
int GenNum=0;
double random(double, double);
void initiate();
void calvalue();
void select();
void crossOver();
void xOver(int,int);
void mutate();
double delta(int,double,double,double);
void sort();
/*****************主函数***************/
int main()
{
ofstream output;
srand((unsigned)time(NULL));
initiate();
calvalue();
output.open("data.txt");
while(GenNum<=Generation)
{
GenNum++;
select();
crossOver();
mutate();
calvalue();
sort();
if (bestChrom.fitness<Group[0].fitness)
{
bestChrom.code[0]=Group[0].code[0];
bestChrom.code[1]=Group[0].code[1];
bestChrom.fitness=Group[0].fitness;
}
// output<<"gen: "<<GenNum<<"最优解为:"<<endl;
// output<<"x1: "<<bestChrom.code[0]<<" x2: "<<bestChrom.code[1]<<" 函数值为: "<<(30-bestChrom.fitness)<<endl;
output<<GenNum<<" "<<(30-bestChrom.fitness)<<endl;
}
output.close();
cout<<"运行结束!"<<endl;//提示运行结束
return 0;
}
/******************************函数的实现*****************************************/
double random(double start, double end){//随机产生区间内的随机数
return start+(end-start)*rand()/(RAND_MAX + 1.0);
}
void initiate()//初始化
{
for(int i=0;i<COLONY_SIZE;i++)
{
Group[i].code[0]=random(-30,30);
Group[i].code[1]=random(-30,30);
Group[i].fitness=0;//适应值
Group[i].cfitness=0;//相对适应值比例之和
Group[i].rfitness=0;//相对适应值比例
}
}
void calvalue()//计算适应值
{
double x1,x2;
double sum=0;
double part1,part2;//将函数分成几个部分
for(int i=0;i<COLONY_SIZE;i++)
{
x1=Group[i].code[0];
x2=Group[i].code[1];
part1=-0.2*sqrt((x1*x1+x2*x2)/Size);
part2=(cos(2*3.1415926*x1)+cos(2*3.1415926*x2))/Size;
Group[i].fitness=UPPER-(-20*exp(part1)-exp(part2)+20+2.71828);//适应值
sum+=Group[i].fitness;//计算适应值之和
}
for(int mem=0;mem<COLONY_SIZE;mem++)//轮盘赌选择机制里所要求的几个参数
{
Group[mem].rfitness=Group[mem].fitness/sum;//适应值的比例
}
Group[0].cfitness=Group[0].rfitness;
for(mem=1;mem<COLONY_SIZE;mem++)
{
Group[mem].cfitness=Group[mem-1].cfitness+Group[mem].rfitness;//模拟轮盘
}
}
void select()
{
double p;
for(int i=0;i<COLONY_SIZE;i++)//挑选出N个个体
{
p=random(0,1);//随机产生0到1之间的随机数
if(p<Group[0].cfitness)
newGroup[i]=Group[0];
else
{
for(int j=1;j<COLONY_SIZE;j++)//往轮盘后走
{
if(p>=Group[j-1].cfitness&&p<Group[j].cfitness)
{
newGroup[i]=Group[j];
break;
}
}
}
}
for(i=0;i<COLONY_SIZE;i++)//从newGroup复制到Group中
Group[i]=newGroup[i];
}
void crossOver()
{
int mem,one;
int first=0;//记录杂交的数目
double x;
for(mem=0;mem<COLONY_SIZE;mem++)
{
x=random(0,1);
if(x<OVER)
{
++first;
if(first%2==0)//若为偶数
xOver(one,mem);
else
one=mem;
}
}
}
void xOver(int one,int two)
{
double point;
point=random(0,1);
Group[one].code[0]=Group[one].code[0]*point+Group[two].code[0]*(1-point);
Group[one].code[1]=Group[one].code[1]*point+Group[two].code[1]*(1-point);
Group[two].code[0]=Group[one].code[0]*(1-point)+Group[two].code[0]*point;
Group[two].code[1]=Group[one].code[1]*(1-point)+Group[two].code[1]*point;
}
void mutate()
{
double x;
for(int i=0;i<COLONY_SIZE;i++)
{
for(int j=0;j<Size;j++)
{
x=random(0,1);
if (x<MUTATE)
{
Group[i].code[j]=delta(GenNum,Group[i].code[0],30,-30);
}
}
}
}
double delta(int t,double x,double u,double l)
{
double temp1;
double temp2;
double y;
double r=random(0,1);
temp1=pow((1-t/Generation),4);
temp2=pow(r,temp1);
int a=(int)random(0,2);
if(a==0)
{
y=u-x;
return (x+y*(1-temp2));
}else
{
y=x-l;
return (x-y*(1-temp2));
}
}
void sort()//排序
{
Indival temp;
for(int i=0;i<COLONY_SIZE-1;i++)
{
for(int j=i+1;j<COLONY_SIZE;j++)
{
if(Group[i].fitness<Group[j].fitness)
{
temp=Group[i];
Group[i]=Group[j];
Group[j]=temp;
}
}
}
}
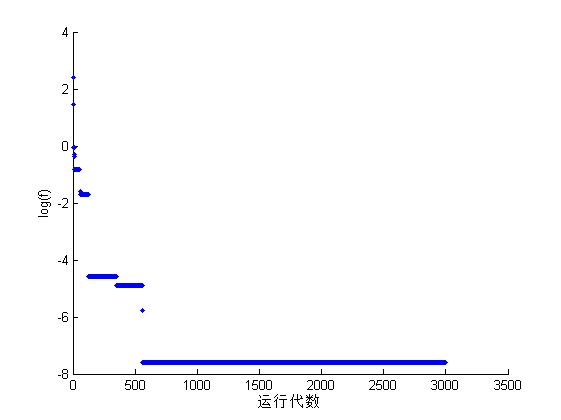
最终结果
我在这里简单介绍了遗传算法,遗传算法是一个研究较多的算法,还有利用遗传算法求解组合优化问题,带约束的优化问题,还有一些遗传算法的理论知识,如模式定理,积木块假设,在这里就不一一列举了,希望我的博文对你的学习有帮助,也欢迎转载,谢谢,有不到位的地方还请指出。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/196989.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
